本文主要是介绍数据库管理-第五十四期 春节俩故障(20230128),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据库管理 2023-01-28
- 第五十四期 春节俩故障
- 1 19.13 bug 32076305
- 2 19.15 CSS
- 总结
第五十四期 春节俩故障
虽然春节期间除了年三十的现场值班和远程值班,没啥事的,结果还是处理了俩故障,今天上工,分析一下。
1 19.13 bug 32076305
大年初四刚过12点,正在关机准备睡觉,收到短信告警,X8M那套一体机一个实例出现LMHB进程异常和ORA 29770报错,随即开机检查,发现该节点数据库实例已完成重启,检查告警日志发现以下内容:
<msg time='2023-01-24T23:59:13.065+08:00' org_id='oracle' comp_id='rdbms'
type='UNKNOWN' level='16' host_id='xxxdbadm01.xxx.com'
host_addr='10.110.187.98' pid='313846' con_uid='1'
con_id='1' con_name='CDB$ROOT'>
<txt>LMD0 (ospid: 313601) has not called a wait for 88 secs.
</txt>
</msg>
<msg time='2023-01-24T23:59:15.290+08:00' org_id='oracle' comp_id='rdbms'
msg_id='3469116049' type='INCIDENT_ERROR' level='1'
host_id='xxxdbadm01.xxx.com' host_addr='10.110.187.98' pid='313846'
prob_key='ORA 29770' downstream_comp='LMHB' errid='648350'
detail_path='/u01/app/oracle/diag/rdbms/xxdbaas/xxdbaas1/trace/xxdbaas1_lmhb_313846.trc' con_uid='1' con_id='1'
con_name='CDB$ROOT'>
<txt>Errors in file /u01/app/oracle/diag/rdbms/xxdbaas/xxgdbaas1/trace/xxdbaas1_lmhb_313846.trc (incident=648350) (PDBNAME=CDB$ROOT):
ORA-29770: global enqueue process LMD0 (OSID 313601) is hung for more than 70 seconds
</txt>
<arg name='PDBNAME' value='CDB$ROOT'/>
</msg>
<msg time='2023-01-24T23:59:15.291+08:00' org_id='oracle' comp_id='rdbms'
msg_id='dbgexProcessError:1328:3370026720' type='TRACE' level='16'
host_id='xxxdbadm01.xxx.com' host_addr='10.110.187.98' pid='313846'
con_uid='1' con_id='1' con_name='CDB$ROOT'>
<txt>Incident details in: /u01/app/oracle/diag/rdbms/xxdbaas/xxdbaas1/incident/incdir_648350/xxdbaas1_lmhb_313846_i648350.trc
</txt>
global enqueue process LMD0进程夯死造成了实例重启,还好23:59:13实例中断,23:59:32完成重启,重启只花了19s,没有影响到业务,特别是12点即将开始大一大堆跑批。随即收集日志,半夜开1级非7*24SR,并通知后台熟人看看能不能接单(是谁老读者肯定知道,当然是第二天接到了)。
第二天经过后台排查,匹配到一个BUG:Bug 32076305 - ORA-29770 LMD has no heartbeats - LMD Stack is in kjr_freeable_chunk_free (Doc ID 32076305.8):
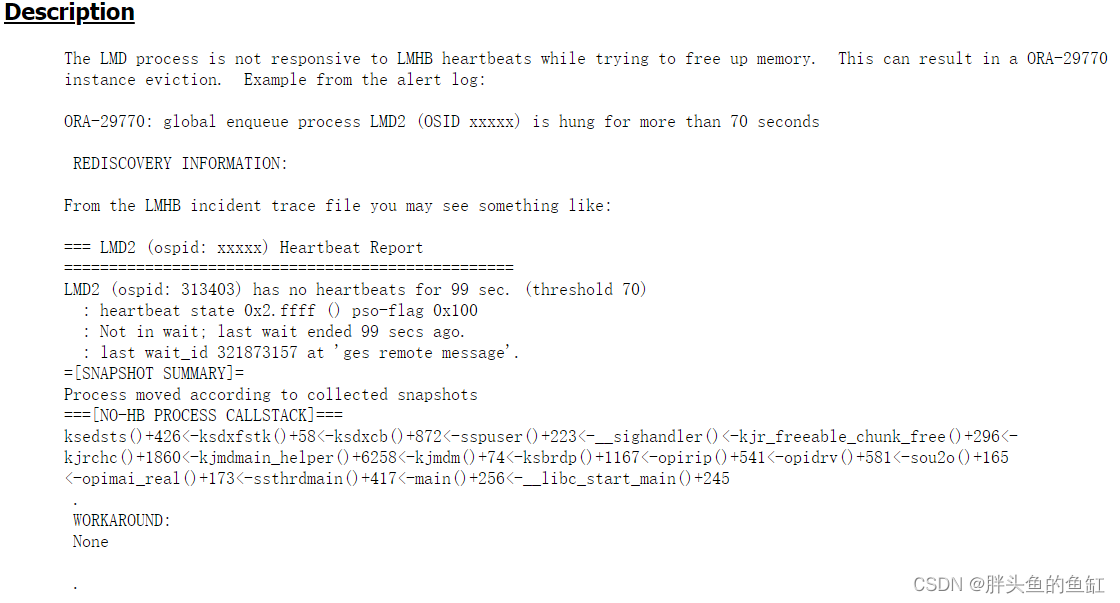
这个bug影响19.4、8、10-13这几个版本,在19.13.2及19.14以后修复,如果各位在生产中遇到了,请及时排查并应用该BUG的补丁。
2 19.15 CSS
这个事情也是25日中午发生,是另外个省一套19.15的双节点RAC,一个节点(节点2)操作系统重启了,我是作为操作系统方面的补充看看数据库的问题。老规矩收日志,重启是11:43-11:44之间发生的:
- 节点2数据库日志
首先数据库日志显示数据库从11:27:59就开始无法响应外部连接请求。数据库于12:04:28开始启动数据库实例,并于12:05:21完成数据库启动 - 节点2CRS日志
从1月19日就出现节点ASM资源失败、CSS无响应的现象,并持续出现私网连接异常超时的报错知道出现故障之前1月25日11:04:18后停止了日志输出。
这里还有个小插曲,12:28:24集群跟随操作系统启动开始启动,12:04:26完成启动,这里用的NTP作为时间同步,大概率是NTP启动晚于GI启动,时间同步后也没有做一次时间同步硬件的操作。 - 节点1CRS日志

节点1是接到节点2的cssdagent和oracssdmonitor异常的通知,需要重启,节点2被驱逐出集群的记录。时间也与客户提供故障时间吻合。加上操作系统、BMC的一些日志也有cssdagent和udev相关的记录,在这里可以确认是因为CSS服务异常引起的故障。
然而当天硬件还发现系统盘中的一块盘也有异常,在操作系统重启后在线更换了。客户那边的DBA资源呢,又说是操作系统侧引起的数据库夯死,数据库是不可能引起操作系统重启的,然而事实是这样的么?我们看看官方文档对CSS服务的解释:

这里最后一句话明确说明了,cssdagent异常的情况下,可能导致集群重启节点。其实做过RAC高可用测试的都知道,不止是这个进程,还有不少进程异常也会导致集群重启节点操作系统。
客户那边DBA做出上面的陈述原因其实也简单,借用以为大佬说的“正常,从单节点到rac知识体系扩大了三五倍”,可能也有人没去看grid家目录的权限情况。还有呢就是,其实也是上期说过的,这种现象也出现在很多大的服务商里面,数据库的问题是数据库的,操作系统是操作系统的,两边交叉出问题的话,就很难去排查。
由于客户没有MOS账号,我这边也只能自己根据数据库日志、操作系统日志进行排查,结合555.1,找到一个匹配的BUG,更符合这次故障的情况:
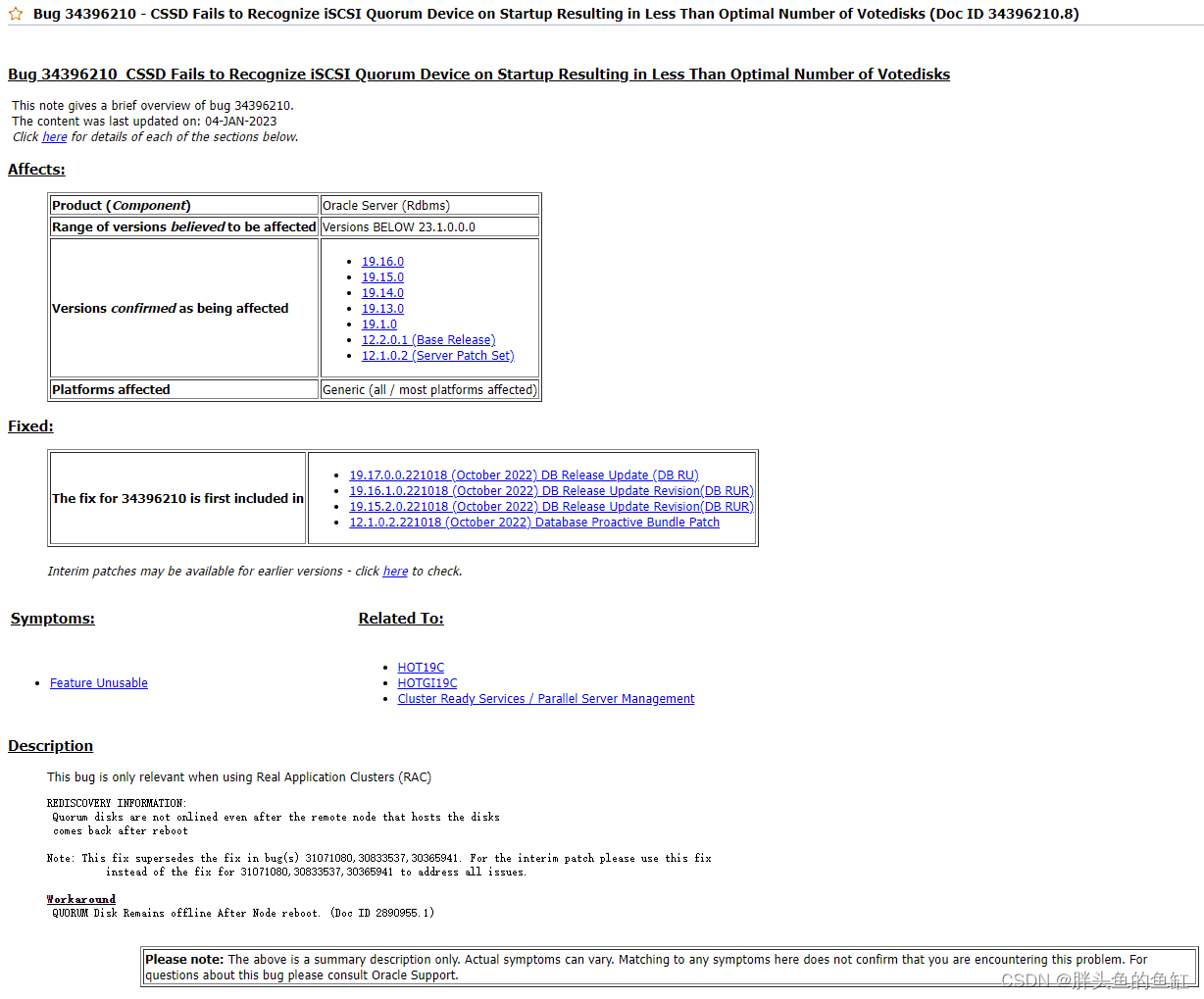
当然这个还需要更进一步的排查。
总结
苦逼的7天班!
老规矩,知道写了些啥。
这篇关于数据库管理-第五十四期 春节俩故障(20230128)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






