BrainWeb: Simulated Brain Database使用说明
作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/
BrainWeb: Simulated Brain Database
http://brainweb.bic.mni.mcgill.ca/brainweb/
数据集选自McGill大学Montreal神经所大脑成像中心的Brain Web反震脑部MR图像数据库。该数据库包含基于两种解剖模型的模拟脑MRI数据:正常和多发性硬化(MS),并且提供了人工合成三种模态(T1-, T2-, PD-)下的三维脑MR图像。图像中包含不同的扫描厚度、噪声以及偏移场,且该数据库对于所有脑MR图像均提供了标准分割结果。
一、文件命名规则
1.模态 T1,T2,PD
2.协议 icmb
3.脑图像名字:正常
4.切片厚度 1mm,3mm,5mm,7mm,9mm
5.噪声水平 pn0=0%;1%,3%,5%,7%,9%
6.灰度不均匀水平 rf0=0%;20%,40%
二、文件下载格式: .rawb
以正常脑数据库为例,模态= T1,协议= ICBM,幻像名称=正常,切片厚度= 1mm,噪声= 0%,INU = 0%
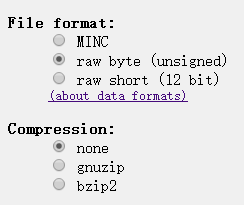
点击下载即可,下载之后格式为.rawb文档,用matlab打开文件及数据。
function g = readrawb(filename, num)
% 函数readrawb(filename, num)中的第一个参数filename是欲读取的rawb文件的文件名,第二个参数num就是第多少张。
fid = fopen(filename);
% 连续读取181*217*181个数据,这时候temp是一个长度为181*217*181的向量。
% 先将rawb中的所有数据传递给temp数组,然后将tempreshape成图片集。
temp = fread(fid, 181 * 217 * 181);
% 所以把它变成了一个181*217行,181列的数组,按照它的代码,这就是181张图片的数据,每一列对应一张图。
% 生成图片集数组。图片集images数组中每一列表示一张图片。
images = reshape(temp, 181 * 217, 181);
% 读取数组中的第num行,得到数组再reshape成图片原来的行数和列数:181*217。
image = images(:, num);
image = reshape(image, 181, 217);
g = image;
fclose(fid);
end function init_image(filename,num)
% 函数init_image(filename,num)中的第一个参数filename是欲读取的rawb文件的文件名,第二个参数num就是第多少张。输出为原始图像,未处理
%例如:init_image('t1_icbm_normal_1mm_pn0_rf0.rawb',90), init_image('phantom_1.0mm_normal_csf.rawb',90)
read=readrawb(filename, num);
% 旋转90°并显示出来
read=imrotate(read, 90);
imshow(uint8(read));
end
在命令行窗口输入
init_image('t1_icbm_normal_1mm_pn0_rf0.rawb',90) 即可获得第90层的脑MR图像。
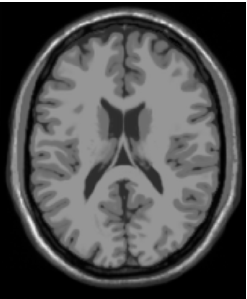
三、离散标签命名规则
0=Background,背景
1=CSF,脑脊液
2=Grey Matter,灰质
3=White Matter,白质
4=Fat,脂肪
5=Muscle/Skin,肌肉/皮肤
6=Skin,皮肤
7=Skull,颅骨
8=Glial Matter,胶质
9=Connective,连接





