本文主要是介绍飞思卡尔MC9S12(X)系列的内存资源分配和.prm文件的结构,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
转发 https://blog.csdn.net/Timbo0/article/details/78010301
一、内存分配
1.资源分布
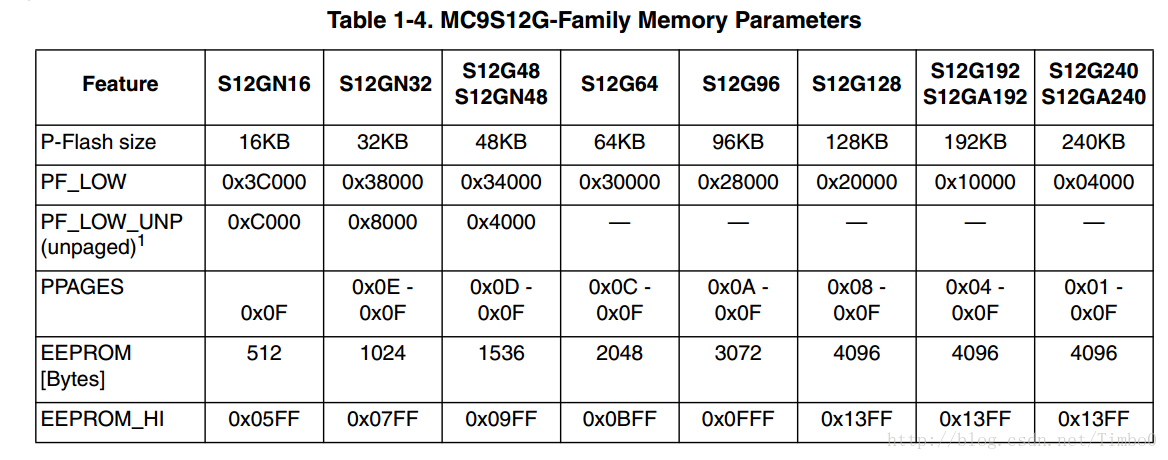
如上图所示,单片机型号最后的数字也就代表了单片机中Flash的大小,S12G128 表示Flash有128K Byte,S12G192 表示Flash有192K Byte。但是S12(X)所使用的内核CPU12(X)的地址总线为16位,寻址范围最大为2^16 =64K Byte,而这64K Byte的寻址空间还包括寄存器、EEPROM(利用Data Flash模拟)、RAM等,因此不是所有的64K Byte都是用来寻址FLASH。所以在S12(X)系列单片机中,很多资源是以分页的形式出现的,其中包括EEPROM、RAM、FLASH。EEPROM的每页大小为1K Byte,RAM的每页大小为4K Byte,FLASH的每页大小为16K Byte。因此G128中EEPROM的页数为4K/1K = 4页,RAM的页数为8K/4K = 2页,Flash的页数为128K/16K = 8页。
2.本地内存地址和全局内存地址之间的关系

在单片普通模式中,复位后,所有内存资源的映射如图二所示,其中从0x0000-0x03FF的1K范围内映射为寄存器区,如I/O端口寄存器等,当然寄存器没有那么多,后面的一部分其实没有使用;
从0x0400-0x3FFF存放着EEPROM、Flash Space、RAM,具体可到该模块去看细化的分配。
从0x4000-0xFFFF的总共48K的空间为Flash区,分为三页。其中第一页和第三页为固定的Flash页(非分页),中间的一页(0x8000-0xBFFF)为窗口区,通过设置PPAGE寄存器,可以映射到其他的分页Flash。
对于RAM和Flash来说,其实固定页和其他的分页资源是统一编址的,不同的是固定页不可以通过寄存器(RPAGE、PPAGE)改变映射,而其他的页必须通过寄存器的设置来选择映射不同的页。
二、.prm文件结构详解
1 .prm 文件组成结构 按所含的信息的不同.prm文件有六个组成部分构成,这里仅讨论和内存空间映射关系紧密的三个部分,其他的不做讨论。
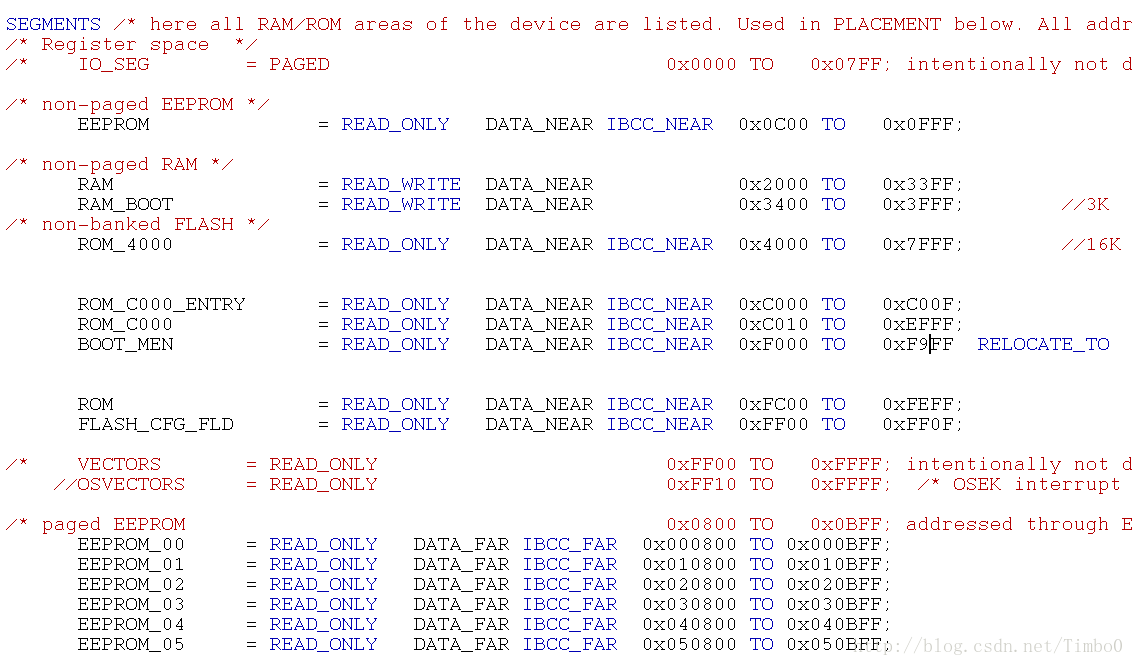

· SEGMENTS ……END 定义和划分芯片所有可用的内存资源,包括程序空间和数据空间。一般我们将程序空间定义成ROM,把数据空间定义成RAM,但这些名字都不是系统保留的关键词,可以由用户随意修改。用户也可以把内存空间按地址和属性随意分割成大小不同的块,每块可以自由命名。例如同样是RAM,可以使用不同的属性,使其有复位后变量清零和不清零之分。
关于内存划分的具体方法在后面详解。
· PLACEMENT…… END 将指派源程序中所定义的各种段,如数据段DATA_SEG、CONST_SEG和代码段CODE_SEG 被具体放置到哪一个内存块中。它是将源程序中的定义描述和实际物理内存挂钩的桥梁。
· STACKSIZE 定义系统堆栈长度,其后给出的长度字节数可以根据实际应用需要进行修改。堆栈的实际定位取决于RAM内存的划分和使用情况。默认的情况下,堆栈放在RAM区域的起始部分。当然,堆栈的定义不只有这种方式,还可以使用STACKTOP关键字。后面将详细讨论。
2 内存划分的具体方式 由SEGMENTS开始到END为止,中间可以添加任意多行内存划分的定义,每一行用分号结尾。定义行的语法型式为: [块名] = [属性1] [属性2] ,„ ,[属性n] [起始地址] TO [结束地址]; 其中:
· “块名”的定义和C语言变量定义相同,是以英文字母开头的一个字符串,用户可以自己任意定义块名。
对于“属性1”,Codewarrior 5.1中可以有三种不同的类型,对于只读的Flash-ROM区属性一定是READ_ONLY,对于可读写的RAM区属性可以是 READ_WRITE,也可以是NO_INIT。它们两者的关键区别是ANSI-C的初始化代码会把定位在READ_WRITE块中的所有全局和静态变量自动清零,而NO_INIT块中的变量将不会被自动清零。当然只是复位时不清零,掉电时还是清零的,但是对于单片机系统,变量在复位时不被自动清零这一特性有时是很关键的,在某些应用中有特殊的用途。
对于“属性2 … 属性n”,根据上面给出的.prm的范例文件可以看出来,可能的形式有:
“DATA_FAR”、“DATA_NEAR”、“IBCC_FAR”、“IBCC_NEAR”四种类型。
其中,“DATA_FAR”和“DATA_NEAR”相对应,当内存区域包含变量或者是常量时(通常是RAM、Flash和EEPROM),必须指明上面两种属性中的一种,由于涉及到内存的分页,可以这样理解:“DATA_FAR”属性指定的内存块为可以保存数据的非固定页,而“DATA_NEAR”属性指定的内存块为可以保存数据的固定页;同理“IBCC_FAR”和“IBCC_NEAR”相对应,当内存区域包含代码时(Flash和EEPROM),必须指明上面两种属性中的一种,“IBCC_FAR”属性指定的内存块为可以保存代码的非固定页,而“IBCC_NEAR”属性指定的内存块为可以保存代码的固定页 讨论到这里,细心的读者已经发现,在上面的.prm文件范例中,RAM的属性有“DATA_FAR”和“DATA_NEAR”两种,Flash的属性中也是四种都有,但是EEPROM中却只有“DATA_FAR”和“IBCC_FAR”两种,RAM、Flash中都有固定页,但是EEPROM中全部是非固定页。
· 起始地址和结束地址决定了一内存块的物理位置,对于固定页,用4位16进制数表示,而对于非固定页,则用6位16进制表示,多出来的两位其实是寄存器EPAGE、RPAGE或PPAGE的值,可见,对于分页的资源,是通过寄存器(EPAGE、RPAGE或PPAGE)和16位的地址总线的组合来进行寻址的。 “TO”是系统保留的关键字,必须大写。
下面,根据上面范例提供的内容,举几个例子:
例1 RAM = READ_WRITE DATA_NEAR 0x2000 TO 0x3FFF;
上面这句话的意思是:分配0x2000-0x3FFF的区域的块名为“RAM”(当然可以定义别的名称),这一区域的物理内存的性质为RAM,属性应该为“READ_WRITE”,并且这一区域中的两页都为固定页,所以为“DATA_NEAR”。
例2 将8K字节RAM的后面4K字节定义成非自动清零的数据保留区,则应如下定义:
SEGMENTS
…….
RAM = READ_WRITE DATA_NEAR 0x2000 TO 0x2FFF; RAM_NO_INIT = NO_INIT DATA_NEAR 0x3000 TO 0x3FFF;
……
END
注意,各部分RAM的分配地址不应该存在重叠的部分,否则会发生错误。
例3 EEPROM_00 = READ_ONLY DATA_FAR IBCC_FAR 0x000800 TO 0x000BFF;
G128单片机中的EEPROM由Data-Flash模拟,所以属性为READ_ONLY。EEPROM全部为非固定页,所以用“DATA_FAR”、“IBCC_FAR”。后面的起始地址和结束地址分别为6位的16进制数,前两位的“00”实质指的是EEPROM分页寄存器EPAGE的值为0x00。
用SEGMENTS只是从单片机的物理内存这一角度对其进行空间划分。源程序本身并不知道物理内存被分割和属性定义的这些细节。它们两者之间必须通过下面的PLACEMENT建立联系。
3 程序段和数据段的放置 PLACEMENT-END内所描述的信息是告诉连接器源程序中所定义的各类段应该被具体放置到哪一个内存块中去。其语法型式为:
[段名1], [段名2],… , [段名n] INTO [内存块名1],[内存块名2],„ ,[内存块名n];
[段名1], [段名2],… , [段名n] DISTRIBUTE_INTO [内存块名1],[内存块名2],„ ,[内存块名n];
· 段名就是在源程序中用“#pragma”声明的数据段、常数段或代码段的名字。如果用缺省名“DEFAULT”,则默认的数据段名为DEFAULT_RAM,代码段和常数段名为DEFAULT_ROM。若程序中定义的段名没有在PLACEMENT中提及,则将被视同为DEFAULT。几个相同性质但不同名字的段可以被放置到同一个内存块中,相互之间用逗号分隔。
· INTO 是系统保留的关键词,在这里为“放入”的意思。
· DISTRIBUTE_INTO 也是系统的保留关键字。Codewarrior 具有内存自动优化的功能,但是在“Small memory”模式中,这种功能不会被启用,只有当16-bit的地址空间不能存放下所有的变量和代码时,才会启用这种功能。
在SEGMENTS-END区域中,当在内存模块的属性中加上
“DATA_FAR”“DATA_NEAR”、“IBCC_FAR”、“IBCC_NEAR”
四种属性中的任何一种时,那么在PLACEMENT-END区域中,就需要指定段名
“DISTRIBUTE”,
“CONST_DISTRIBUTE”,
“DATA_DISTRIBUTE”
(系统默认的,非关键字,用户可以自行更改)所分配的内存空间,这就需要使用“DISTRIBUTE_INTO”关键字。
· 内存块名就是前面介绍的用SEGMENTS划分好的不同的内存块名字。利用这样直观的定位描述文本可以方便灵活的将数据或代码定位到芯片内存任意可能的位置,实现某些特殊目的的应用。
下面的例子,说明了各种段名、PLACEMENT 和SEGMENTS之间的对应关系。
例4
定义非自动清零的数据段
SEGMENTS
……
RAM = READ_WRITE DATA_NEAR 0x2000 TO 0x2FFF; RAM_NO_INIT = NO_INIT DATA_NEAR 0x3000 TO 0x3FFF;
……
END
PLACEMENT
……
DATA_PERSISTENT INTO RAM_NO_INIT;
……
END
//源程序编写:
#pragma DATA_SEG DATA_PERSISTENT //定义复位时非自定清零数据段
byte sysState;
#pragma DATA_SEG DEFAULT
4 堆栈的设置
关于堆栈的设置,Codewarrior提供了两种方式:“STACKSIZE”命令方式和“STACKTOP”命令方式。这两种方式在同一个.prm文件中,不能同时存在。当用户只关心堆栈的大小而不关心堆栈的存放位置时,推荐使用STACKSIZE方式。 系统默认的方式为使用STACKSIZE方式。
STACKSIZE命令方式:
当使用STACKSIZE命令方式时,如果在PLACEMENT-END部分声明了“SSTACK INTO RAM”,这样的话,堆栈区就被放在RAM区域的起始部分,下面的例子说明了这种方式:
例5
SEGMENTS
„„
RAM = READ_WRITE DATA_NEAR 0x2000 TO 0x3FFF;
„„
END
PLACEMENT
„„
SSTACK, PAGED_RAM, DEFAULT_RAM INTO RAM;
„„
END
STACKSIZE 0x100
上面的例子将堆栈区域存放的地址为0x20FF-0x2000,初始的堆栈指针指向栈顶地址0x20FF。
相反,如果在PLACEMENT-END部分没有声明“SSTACK INTO RAM”,则堆栈被分配在RAM区域中已分配空间的后面。请参见例6。
例6
SEGMENTS
„„
RAM = READ_WRITE DATA_NEAR 0x2000 TO 0x3FFF;
„„
END
PLACEMENT
„„
PAGED_RAM, DEFAULT_RAM INTO RAM;
„„
END STACKSIZE 0x100
在这个例子中,如果RAM区域中已经分配的变量占用了4个字节(从0x2000到0x2003),则堆栈放在这四个字节的后面,从0x2103到0x2004,初始的堆栈指针指向0x2103。
STACKYOP命令方式: 当使用STACKTOP命令方式时,如果在PLACEMENT-END部分声明了“SSTACK INTO RAM”,同样,堆栈区就被放在RAM区域的起始部分,初始的栈顶则由STACKTOP指定。若没有相应的声明,则初始的栈顶由STACKTOP指定,而堆栈的大小则根据处理器的不同由编译器自行设定,其大小足够装下处理器的PC寄存器的值。
这篇关于飞思卡尔MC9S12(X)系列的内存资源分配和.prm文件的结构的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






