本文主要是介绍【计算机网络笔记】数据交换之报文交换和分组交换,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 系列文章目录
- 报文交换
- 分组交换
- 存储-转发
- 报文交换 vs 分组交换
- 总结
系列文章目录
什么是计算机网络?
什么是网络协议?
计算机网络的结构
数据交换之电路交换
报文交换
报文:源(应用)发送的信息整体。比如一个文件、一张图片。
报文交换:在传输过程中以报文作为整体,一次性发送到下一个节点,比如路由器。路由器接收到完整的报文之后再发往下一个节点。
报文交换最具有代表性的应用是上世纪5、60年代使用的电报系统。
分组交换
分组:由报文分拆出来的一系列相对较小的数据包再加上头部信息形成
分组交换则是在传输过程中以分组作为整体发送。整个过程需要经过报文的拆分与重组两部分。
- 拆分:源主机把要发送的报文拆分为一个个小的数据包,然后给数据包加上头部信息形成分组
- 重组:分组到了目的主机后,目的主机要获得完整的报文,就需要把各个小的分组所携带的报文的一部分数据合并在一起
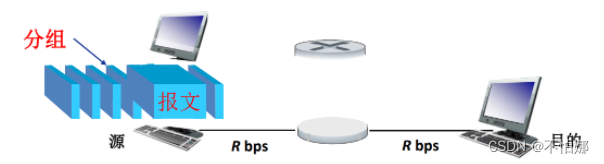
在分组交换网络中,链路的共享并不是事先分配好的,具有很强的随机性,谁发的数据多,对链路的使用率就高。这种方法就称为统计多路复用,它最大的特点是按需共享链路。也就是说,需要发送数据时才去占用电路的带宽,不需要就不占用。
存储-转发
下面再介绍存储-转发(store-and-forward)的概念。
存储-转发就是先把数据分组接收过来,占存一下,然后确定从哪一个链路发出去。
报文交换与分组交换均采用存储-转发交换方式。但它们使用的交换单位不一样。
- 报文交换以完整报文进行“存储-转发”
- 分组交换以较小的分组进行“存储-转发”
这两种交换方式仅仅有这么小的区别,那哪种交换更好呢?下面具体介绍。
报文交换 vs 分组交换
为了评价这两种交换方式的优劣,根据它们的传输延迟(传输时延),利用时间性的问题来进行对比。
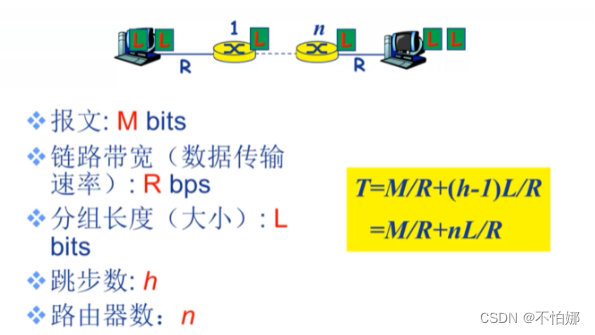
以这样一个场景为例,源主机有一系列分组需要发送,这些分组是由报文拆分而来的。每一个分组的长度是L个bit,发送的时候利用一条链路进行传输,这条链路的带宽是R bps。发送每一个分组的时候是一个比特一个比特地进行发送,从第一个分组的第一个比特发送到第一个分组的最后一个比特发送结束这段时间就称为传输延迟或传输时延。

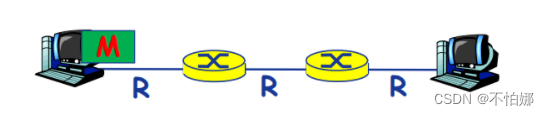
为了说明问题,利用这样的网络场景来进行对比。在这个网络中,两个主机通过两个路由器互连在一起。左侧为源主机,右侧为目的主机。假设我们忽略其他时间开销,只考虑报文或者分组的传输时间,报文的拆分和重组时间也不考虑。
-
如果是报文交换,每次需要把报文完整的发向下一个节点,下一个节点才可以把这个报文再向下一个节点发送。所以在这个网络中,源主机和路由器转发这个报文的时间实际上就是报文传输的传输延迟,也就是M/R
-
如果是分组交换,区别在于要把报文进行拆分。那么作为主机或者路由器在转发每一个分组所产生的的传输延迟就是L/R。
现在给出具体的数据。报文大小是7.5M,划分为5000个分组,每个分组就是1500bit,链路带宽是1.5Mbps。下面我们来分别计算这两种交换方式所需要的时间。

-
按照报文交换方式:源主机在0时刻发送报文,大小是7.5M, 链路带宽是1.5Mbps,那么5s(7.5/1.5)后报文就已经被送到了第一个路由器了。第5s 开始第一个路由器就可以向第二个路由器发送报文。以此类推,再经过5s,报文就到达目的主机了方式。在这个例子中,采用报文交换需要15s的时间能够报文把源主机成功地传输到目的主机。现在我们考虑一个问题,例子中的路由器需要多大的缓存?答案是7.5M的缓存,因为它至少要把报文完整的存储下来后才能向下转发。那么如果报文的大小特别大,那也就意味着中间路由器的缓存也必须相应的特别大。
-
按照分组交换方式:源主机将报文拆分成5000个分组,每个分组的大小是1500bit。源主机0时刻开始发送第一个分组,这个分组只经过1ms就传输到了第一个路由器,那么从1ms开始,第一个路由器向第二个路由器发送第一个分组,同时源主机向第一个路由器发送第二个分组。继续,从2ms开始,第二个路由器向目的主机发送第一个分组,同时第一个路由器向第二个路由器发送第二个分组,同时源主机向第一个路由器发送第三个分组。那么第3ms的时刻,第一个分组到达目的主机,第二个分组到达第二个路由器,第三个分组到达第一个路由器。这个过程一直持续下去,4999ms的这个时刻,4999号分组在第一个路由器(这么理解:第一的分组在第1ms的时刻到达第一个路由器,第二个分组在第2ms的时刻到达第一个路由器,那么第4999ms的时刻,4999号分组就在第一个路由器,那么同时也能推出源主机此时的分组是5000号、第二个路由器的分组是4998号)。再经过3ms,5000号分组也就是最后一个分组到达目的主机。此时是5002ms,也就是说源主机花了5.002s的时间将所有分组发送到目的主机,此时目的主机对分组进行重组就得到了报文。那么我们现在继续考虑路由器缓存的问题,它只需要1500bit的缓存空间就可以工作了,这比报文交换中7.5M的缓存小多了。
在上面这个例子中,采用报文交换使用了15s,采用分组交换使用了5.002s。为什么呢?因为在分组交换中,每个路由器之间可以并行工作,而报文交换中,它们是串行的。所以由于这个主要原因,分组交换技术在现在的计算机网络以及大部分数据网络中广泛使用。
对刚才的场景进行扩展,得出下面关于分组交换中报文交付时间的一般性结论:报文交付时间=报文传输延迟+最后一个分组经过每个路由器的传输延迟之和。
总结
分组交换相较于报文交换有很多优点。比如传输速度快、对路由器的缓存能力要求不高。因此在现代计算机网络中,基本都使用的是分组交换。
这篇关于【计算机网络笔记】数据交换之报文交换和分组交换的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








