本文主要是介绍罗德施瓦兹频谱仪使用笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文主要介绍罗德频谱仪的两个重要参数RBW和VBW,以及测量设置,以帮助初学者理解频谱解析以及频谱仪的具体使用。
一、什么是RBW和VBW,它们对测量得到结果的影响。
在罗德施瓦兹频谱仪的频谱测量中,有两个参数设置用得比较多,一个是RBW,一个是VBW。
1.参数的含义和作用:
RBW是英文Resolution Bandwidth的缩写,中文为分辨率带宽,一般指的是混频后的中频滤波器的带宽,主要作用是用来准确分辨出中频信号。
VBW是英文Video Bandwidth的缩写,中文为视频带宽,一般指的是包络检波器输出电压之后的低通滤波器的带宽,主要作用是用来平滑噪声显示。
2.RBW和VBW参数设置对显示的影响:
频谱仪在工作的过程中,根据设置的SPAN(频跨)来调节内部本振的频率的变化,完成整个SPAN的信号扫描,并根据设置的参数(VBW和RBW)进行实时显示。
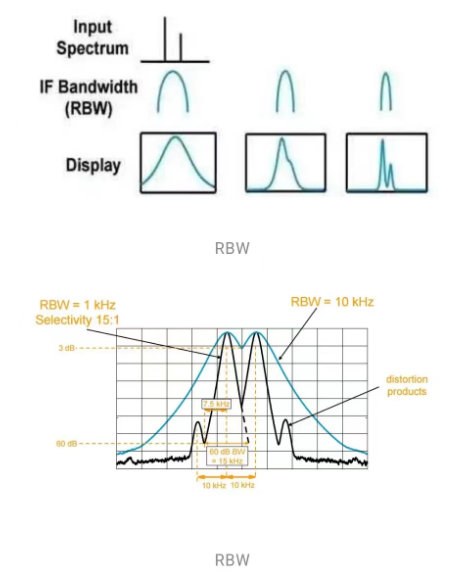
(1)设置RBW
调整RBW的大小对频谱有一定的影响,RBW的值越小,频谱图形越细致,同时底噪也越低,频谱仪的扫描速度越快;RBW的值越大,频谱图形越模糊,底噪越大,频谱仪的扫描速度越慢。即RBW影响底噪和扫描速度,RBW的值与频谱显示的底噪、扫描速度成反比。
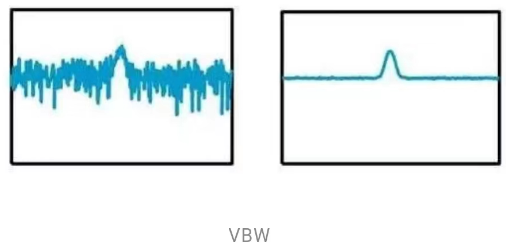
(2)设置VBW
在频谱仪上,VBW有两个设置选项,一个是系统默认的自动,一个是手动。自动模式下,VBW=RBW,即我们改变RBW的值,VBW也会随之变化。在手动模式下,我们可以对VBW进行修改,VBW值设置得越小,频谱的噪声显示就越平滑。即VBW的值与频谱显示的底噪、扫描速度成正比。
3.那么VBW和RBW该如何设置呢?
通常,VBW和RBW的大小关系,跟下面几种信号类型有所不同。
-
正弦信号
-
脉冲信号
-
随机信号
(1)对于正弦信号,一般VBW使用默认缺省值即可,即VBW等于RBW,如果测量的信号过小,可以适当减小VBW平滑噪声,这时VBW是小于RBW。
(2)如果是脉冲信号有些不同,为了过得更精确的测试值,往往需要设置较大的VBW,这时VBW是大于RBW的。
(3)还有一些随机信号,因为随机信号具有随机变化性,频谱每次扫描时的信号也都是随机的,所以,为了显示更加平滑,我们需要设置一个较窄的VBW值,也就是这时VBW的是小于RBW的。比如,VBW和RBW的比值是1:100甚至1:1000。
二、罗德施瓦兹频谱仪的测量设置
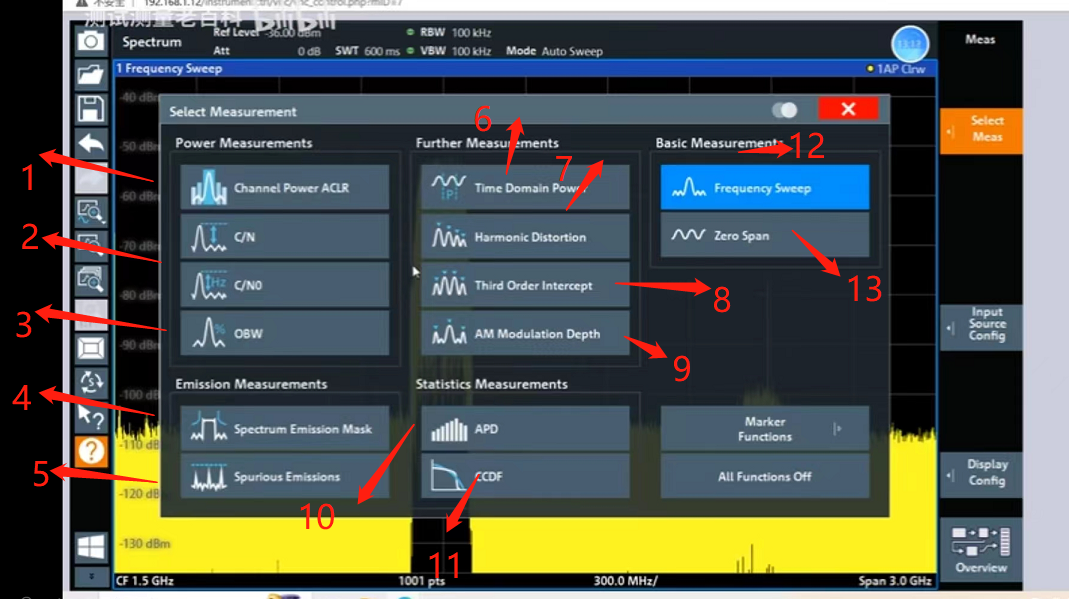
1. Basic Measurements里的两个设置,
(1)Frequency Sweep,即测扫频,
(2)Zero Span,即测零频(设置起始终止频率后者中心频率),
2.Power Measurements的设置:
Channel Power ACLR这个用来测信道功率,
C/N这个用来测信噪比,
C/NO这个用来测交调,
OBW这个用来测占用带宽。
3.Emission Measurements的设置
Spectrum Emission Mask模块(模块化测试),
Spurious Emission这个用来测杂散。
4.Further Measurements的设置
Time Domain Power这个用来测时域信号,
Harmonic Distortion这个用来测谐波,
AM Modulation Depth这个用来测调制深度(模拟调制),
5.Statistics Measurements的设置
APD用来测概率分布
CCDF用来测曲线。
这篇关于罗德施瓦兹频谱仪使用笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




