本文主要是介绍SQL使用窗口函数计算百分位数,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
百分位数:如果将一组数据从小到大排序,并计算相应的累计百分位,则某一百分位所对应数据的值就称为这一百分位的百分位数。可表示为:一组n个观测值按数值大小排列。如,处于p%位置的值称第p百分位数。
下面给出3种计算方式:
1. PERCENT_RANK() OVER(ORDER BY .....)
返回每行的百分比排序,返回值在0~1之间,使用此函数可以直接得出百分位数,等价于分组内当前行的RANK值-1/分组内总行数-1
2. RANK() OVER(ORDER BY .....) /COUNT(1) OVER()
使用rank()函数可以统计出当前行的排名,配合总数即可算出百分位数,总数使用COUNT(1) OVER() 即可得出
3. COUNT(1) OVER(ORDER BY ..... RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) /COUNT(1) OVER()
手动调整窗口范围,确认当前行的排名,配合总数即可算出百分位数,总数使用COUNT(1) OVER() 即可得出
下面将举例给出具体使用方法
举例场景:计算学生成绩的百分位数
注:本次测试在oracle环境下完成,不过使用到的函数大部分数据库都支持,大家有兴趣的话可以尝试一下其他数据库
创建学生成绩表:
CREATE TABLE TEST.STUDENT_SCORE(name varchar(20), --学生姓名course varchar(20), --科目score NUMBER(5,2) --成绩);写入测试数据:
INSERT INTO TEST.STUDENT_SCORE (name,course,score) VALUES ('张三','政治',90.5);
INSERT INTO TEST.STUDENT_SCORE (name,course,score) VALUES ('李四','政治',79.0);
INSERT INTO TEST.STUDENT_SCORE (name,course,score) VALUES ('王五','政治',85.5);
INSERT INTO TEST.STUDENT_SCORE (name,course,score) VALUES ('赵六','政治',93.0);
INSERT INTO TEST.STUDENT_SCORE (name,course,score) VALUES ('小明','政治',92.5);
INSERT INTO TEST.STUDENT_SCORE (name,course,score) VALUES ('小红','政治',88.0);
INSERT INTO TEST.STUDENT_SCORE (name,course,score) VALUES ('小吕','政治',76.5);
INSERT INTO TEST.STUDENT_SCORE (name,course,score) VALUES ('小高','政治',93.0);INSERT INTO TEST.STUDENT_SCORE (name,course,score) VALUES ('张三','外语',87.0);
INSERT INTO TEST.STUDENT_SCORE (name,course,score) VALUES ('李四','外语',92.0);
INSERT INTO TEST.STUDENT_SCORE (name,course,score) VALUES ('王五','外语',69.5);
INSERT INTO TEST.STUDENT_SCORE (name,course,score) VALUES ('赵六','外语',76.0);
INSERT INTO TEST.STUDENT_SCORE (name,course,score) VALUES ('小高','外语',76.0);INSERT INTO TEST.STUDENT_SCORE (name,course,score) VALUES ('张三','高数',95.0);
INSERT INTO TEST.STUDENT_SCORE (name,course,score) VALUES ('李四','高数',70.5);
INSERT INTO TEST.STUDENT_SCORE (name,course,score) VALUES ('王五','高数',65.0);
INSERT INTO TEST.STUDENT_SCORE (name,course,score) VALUES ('赵六','高数',88.5);INSERT INTO TEST.STUDENT_SCORE (name,course,score) VALUES ('张三','算法',59.5);INSERT INTO TEST.STUDENT_SCORE (name,course,score) VALUES ('张三','数据结构',99.5);
INSERT INTO TEST.STUDENT_SCORE (name,course,score) VALUES ('李四','数据结构',89.0);
INSERT INTO TEST.STUDENT_SCORE (name,course,score) VALUES ('王五','数据结构',69.5);
INSERT INTO TEST.STUDENT_SCORE (name,course,score) VALUES ('赵六','数据结构',90.5);1.使用 PERCENT_RANK() OVER(ORDER BY .....) 计算各个科目的百分位数:
--用法非常简单,此处将百分位数乘100,使百分位数在0~100之间
SELECT
name 姓名,
course 科目,
score 成绩,
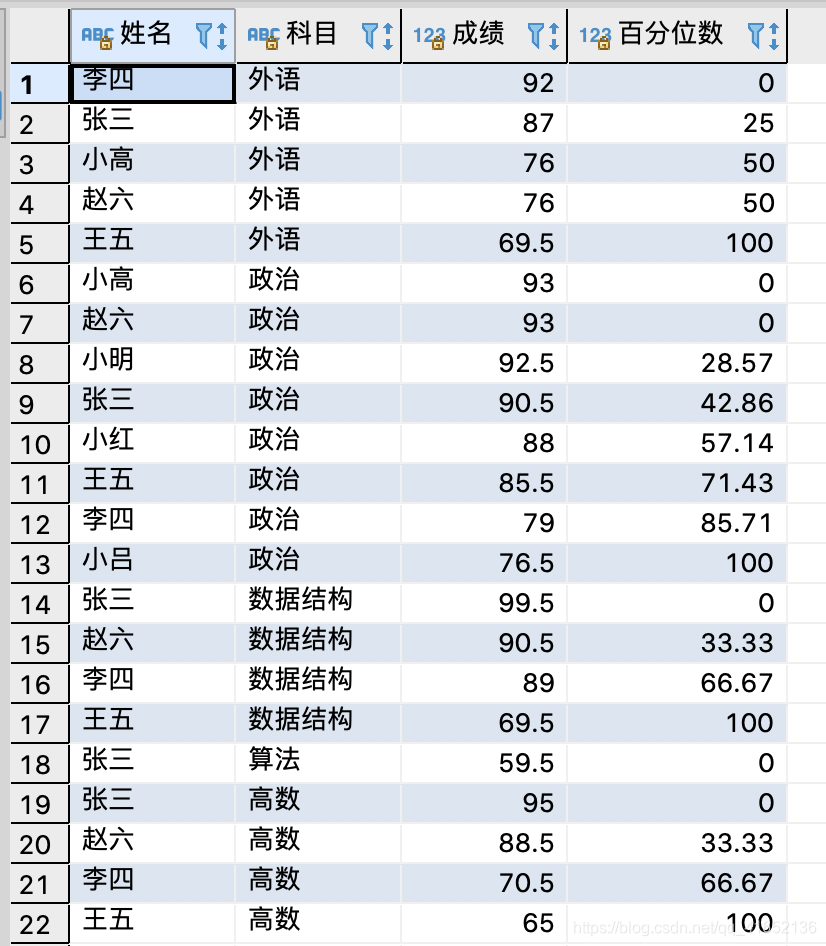
ROUND(PERCENT_RANK() OVER(PARTITION BY COURSE ORDER BY SCORE DESC)*100, 2) 百分位数
FROM TEST.STUDENT_SCORE ;--PARTITION BY COURSE ORDER BY SCORE DESC :按COURSE分区,使用SCORE降序排序结果:
2.使用 RANK() OVER(ORDER BY .....) /COUNT(1) OVER() 计算各个科目的百分位数:
--这种写法使用总人数和排名来计算百分位,复杂一些,但是算法可以自己修改
SELECT
name 姓名,
course 科目,
score 成绩,
score_rank 排名,
students 总人数,
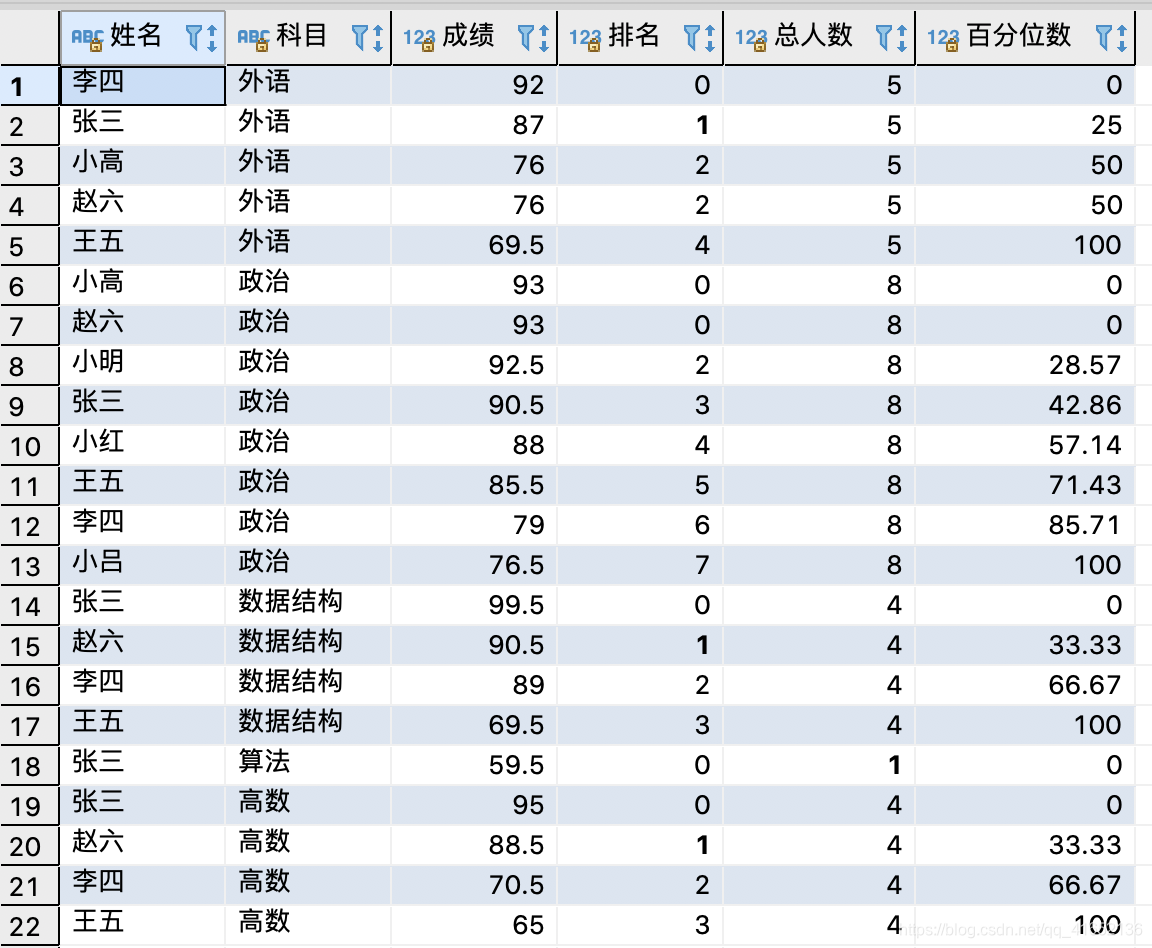
CASE WHEN students > 1 THEN ROUND(score_rank * 100 / (students - 1), 2)ELSE 0END 百分位数
FROM (
SELECT
name,
course,
score,
RANK() over(PARTITION BY course ORDER BY score DESC)-1 score_rank, --当前行的排名
count(1) over(PARTITION BY course) students --当前科目的总人数
FROM TEST.STUDENT_SCORE
);--RANK函数的排名从1开始,所以这里给他减一,便于后续计算结果(排名从0开始):
3.使用COUNT(1) OVER(ORDER BY ..... RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) /COUNT(1) OVER() 计算各个科目的百分位数:
--这种写法更复杂一些,效果与前面的是一样的,可以调整的地方更多一些
SELECT
name 姓名,
course 科目,
score 成绩,
students-score_rank 排名,
students 总人数,
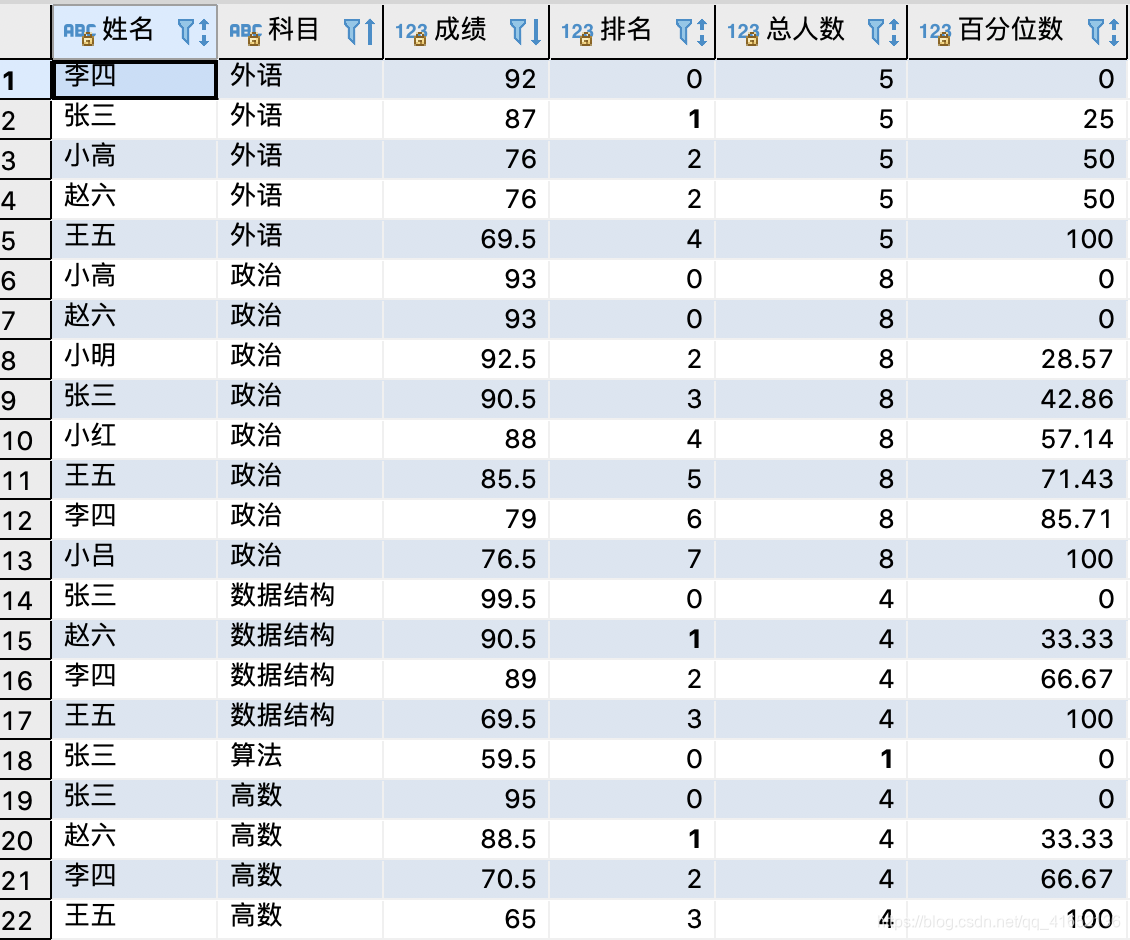
CASE WHEN students > 1 THEN ROUND((students-score_rank) * 100 / (students - 1), 2)ELSE 0END 百分位数
FROM (
SELECT
name,
course,
score,
count(0) over(PARTITION BY course ORDER BY score RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) score_rank, --当前行的排名,倒序
count(0) over(PARTITION BY course) students --当前科目的总人数
FROM TEST.STUDENT_SCORE
);--PARTITION BY course ORDER BY score RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW :按COURSE分区,使用SCORE升序排序,窗口范围从分区第一行到score值与当前行相等的最后一行结果(排名从0开始):
扩展知识:
PARTITION BY :分组子句,表示分析函数的计算范围,不同的组互不相干;
ORDER BY: 排序子句,表示分组后,组内的排序方式;
ROWS|RANGE :窗口子句,是在分组(PARTITION BY)后,组内的子分组(也称窗口),可以选择窗口的范围,需要配合ORDER BY子句使用
注:一般ORDER BY子句后默认的窗口子句为 RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
ROWS|RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW --从第一行到当前行
ROWS|RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING --从当前行到结尾行
ROWS BETWEEN CURRENT ROW AND n FOLLOWING --从当前行到随后的n行
ROWS BETWEEN n PRECEDING AND CURRENT ROW --从前n行到当前行
ROWS BETWEEN n FOLLOWING AND UNBOUNDED FOLLOWING --从下n行到结尾行
ROWS、RANGE的区别:
ROWS是物理窗口,即根据order by 子句排序后,取的前N行及后N行的数据计算(与当前行的值无关,只与排序后的行号相关)
RANGE是逻辑窗口,是指定当前行对应值的范围取值,行数不固定,只要列值在范围内,对应行都包含在内
举例:
SELECT
name 姓名,
course 科目,
score 成绩,
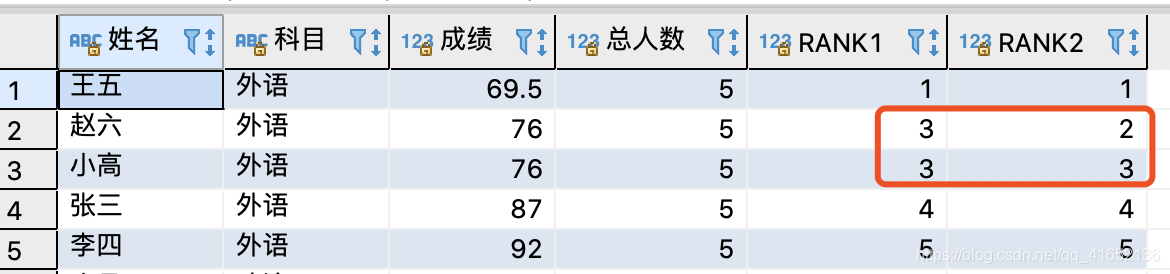
count(0) over(PARTITION BY course) 总人数,
count(0) over(PARTITION BY course ORDER BY score RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) RANK1,
count(0) over(PARTITION BY course ORDER BY score ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) RANK2
FROM TEST.STUDENT_SCORE ;结果:
RANGE 关键字配合 n FOLLOWING 使用时发现的问题:
SELECT
name 姓名,
course 科目,
score 成绩,
count(0) over(PARTITION BY course) 总人数,
count(0) over(PARTITION BY course ORDER BY score RANGE BETWEEN 1 FOLLOWING AND UNBOUNDED FOLLOWING) RANK1,
count(0) over(PARTITION BY course ORDER BY score ROWS BETWEEN 1 FOLLOWING AND UNBOUNDED FOLLOWING) RANK2
FROM TEST.STUDENT_SCORE ;结果:
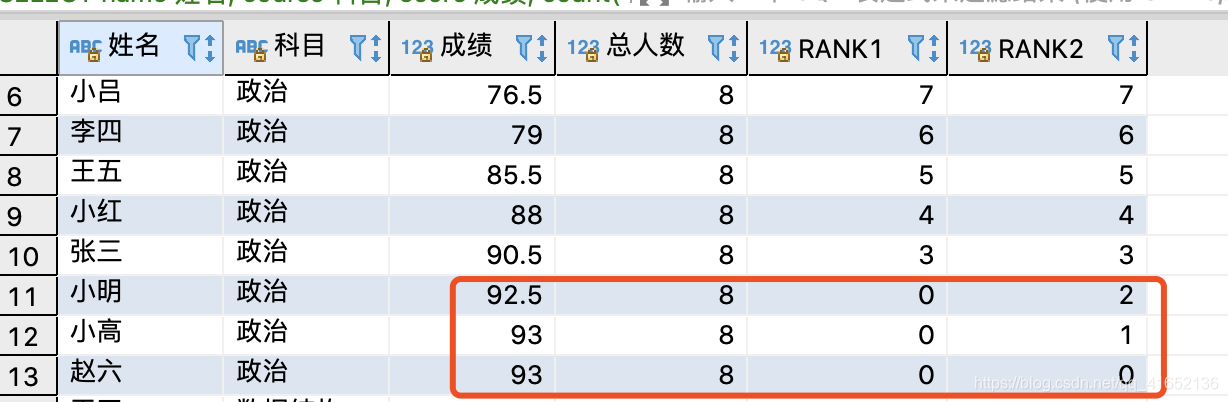
可以看见,使用RANGE BETWEEN 1 FOLLOWING AND UNBOUNDED FOLLOWING来选择窗口范围时,成绩为92.5时,与93的值居然是一样的,oracle、mysql环境都出现了这种情况,具体原因还没搞清楚
这篇关于SQL使用窗口函数计算百分位数的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






