本文主要是介绍昆仑分布式数据库之ScaleOut介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、分布式数据库的基础核心能力-水平扩容(ScaleOut)
数据库系统架构的演变,如实的反映了信息社会不断发展所带来的数据处理规模不断变大这一基本事实。
如今,分布式数据库产品已成为各行各业信息系统的存储服务中,应用越来越广泛的技术选型。究其原因,是因为其在海量数据存储管理的扩展能力和性价比方面,较单机数据库有着压倒性的优势。
在我们对昆仑分布式数据库的扩容功能正式开始介绍之前,我们首先回顾一下数据库管理系统扩容的常见模式。
数据库的扩容大体上分为如下两种模式:垂直扩容(Vertically Scale Up),水平扩容(Horizontally Scale Up)。
垂直扩容是指对物理资源,如存储容量、计算能力、网络带宽等资源的扩展。
这种扩容方式由单机物力资源的瓶颈触发,以扩充单机物理资源为解决方案,满足数据库系统对物力资源的需求。然而这种扩容方式的缺点也是显而易见的:单机物理资源总有上限,且一般价格非常昂贵。

水平扩容的基本思路是将数据按照一定的规则分布在不同的物理设备上,整个系统对外仍然呈现逻辑上的单一数据库服务。
系统的扩展方式以通过增加物理设备的个数,来提升数据库的整体对外服务能力。这种扩展模式,可以说在理论上实现了无限扩展。

其中,如果扩展的物理节点,包含了存储能力,则称为share-nothing架构,否则称为share-storage架构。
我们熟知的oracle-RAC就是典型的share-storage架构,所有计算节点共用一套存储服务,而昆仑分布式数据库是典型的share-nothing架构。
如果从物理设备扩展引发的读写冲突的角度来审视这两种架构的优劣的话,share-nothing架构下,数据分片存储在多个存储集群中,分片之间没有交集,因而不会产生多点写入冲突的问题,因此线性扩展能力相对于share-storage有优势,但分布式事务处理和分布式查询处理功能以及自动的、应用无感知的水平弹性扩容等核心功能是在这种架构下必须要实现的功能,只有具备了所有这些功能,才是真正的分布式数据库系统。
这也是为什么分库分表中间件和应用层分库分表已经不再适合当前的技术水平要求—这些技术方案没有上述功能,会给应用开发者和DBA带来沉重的负担和工作量,相当于要在应用代码中case by case实现分布式数据库系统的分布式事务处理和分布式查询处理功能,以及DBA手动停服完成扩容,这些沉重的负担给应用系统的稳定性可靠性带来巨大的风险,并且验证影响客户业务开展和终端用户体验。
昆仑分布式数据库在架构选型时,就充分考虑到了上述的种种问题。基于我们自身对分布式事务处理和分布式查询处理功能以及自动水平扩容的等分布式数据库核心功能的丰富的设计和实现经验以及对相关用户需求的深刻理解,以及对线性扩展性的极致追求,我们在昆仑分布式数据库中实现了基于share-nothing架构的业务无感知的水平弹性扩容机制,更好地满足业务快速增长对数据库系统的服务要求。
二、昆仑分布式数据库ScaleOut功能介绍
2.1 存储层水平扩容
昆仑分布式数据库的存储服务逻辑上由多个独立的MySQL集群组成,每个集群称为一个shard。

每个shard是昆仑分布式数据库存储层的独立的容灾服务单元,不同shard之间数据相互独立。因此存储层的扩容,我们只需要增加shard这一独立的容灾存储单元即可。
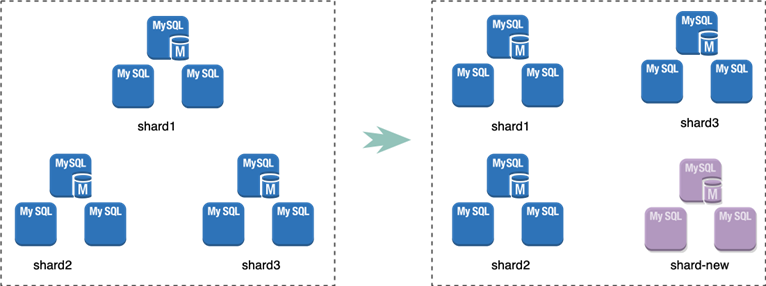
在完成新的shard加入集群后,另一个更重要的需要解决的问题是如何将数据从原有的shard中迁移到新的shard中,从而对数据读写的请求和数据存储的负载,实现存储层整体服务能力的提升。
昆仑分布式数据库基于上述的业务要求,实现了无锁的数据shuffle(搬迁)服务,在实现热数据有效分摊的基础上,可靠的保证了存储服务的连续性,并且对应用系统无感知无侵入。该搬迁服务既可以用于扩容也可以用于缩容。比如为了双十一促销需要临时增加几倍的计算和存储能力,促销结束后释放相关计算和存储资源并还给公有云平台。
在选择迁移哪些数据上,昆仑分布式数据库会根据某些规则选定需要搬迁的表分片(后续撰文介绍),给出待迁移表的集合。其目的是为了能够识别出真正的热点数据,从而更加均衡实现流量分摊以及更加高效的分布式查询。同时在数据 shuffle 的流程设计上,我们也做了无锁化处理,确保一个表在被搬迁的整个过程中持续的可读可写,达到了业务零感知。
整个shuffle过程包括以下几个步骤。假设当前给出的shuffle-set(待迁移的库表) 是从shard2迁移到新shard上。
第一步:需要完成的就是shuffle-set的dump和load操作。
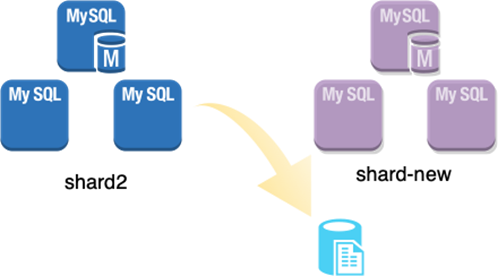
在dump阶段,会保留一个snapshot的点位,即后续开始binlog复制的起始位置。整个dump的过程不会阻塞业务的请求。dump完成后,会并行的将dump的数据文件,load到新的shard中。

在dump和load的过程中,昆仑分布式数据库的集群管控模块cluster_mgr 和节点管控模块node_mgr会协同工作,完成shuffle-set中表的数据搬迁工作。

如上图所示整个过程会划分为三个子任务下发到对应的node_mgr上:
Cluster_mgr下发dump任务到shard2的备机上,对应的node_mgr使用mydumper工具开始并发执行dump任务,待完成任务后,向cluster_mgr应答任务完成。
第一阶段的dump任务完成后,cluster_mgr会向shard-new主机上的 node_mgr下发transfer_task的命令,由shard-new向shard2 拉取对应的dump文件。download完成后,shard-new上的node_mgr向cluster_mgr 应答任务完成。
在完成了transfer_task后,cluster_mgr开始向shard_new下发load_task,任务的执行过程中,node_mgr使用myloader工具,并发的向shard-new中load 数据,完成后向cluster_mgr应答任务成功。
第二步:会建立新shard与源shard之间的数据同步,将源shard 上从snapshot点开始到当前时间shuffle-set的数据变化全部apply 到新的shard上。
数据同步链路的建立,利用MySQL原生的基于binlog的同步机制,通过建立一个只包含shuffle-set同步表的临时同步通道,并利用dump snapshot作为同步的起始点,拉取数据的增量志,并且以并发的方式在shard-new上重放这些日志,直到整个同步延迟在预定的时间范围内(默认3 秒),之后开始进行表切换操作。
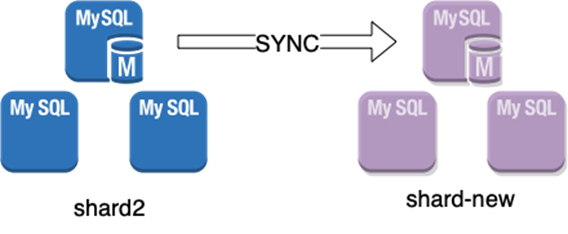
表切换操作,会在源shard上对表进行rename,切断业务的新的请求。随后如果计算节点访问该表会发现表不存在,计算节点会从自己的元数据中找到表的新位置,该新位置由cluster_mgr在后续步骤更新。
完成shard2上的rename操作后,会在shard-new上确认rename操作已经replay,之后整个数据同步channel会被切断。假设表A在shuffle-set中,那么此刻,shard-2上包含一个表A-renamed,同时,shard-new上也包含一个完全相同的表A-renamed。
第三步:通知所有的计算节点shuffle-set表的路由更新。shuffle-set表正式对外服务。
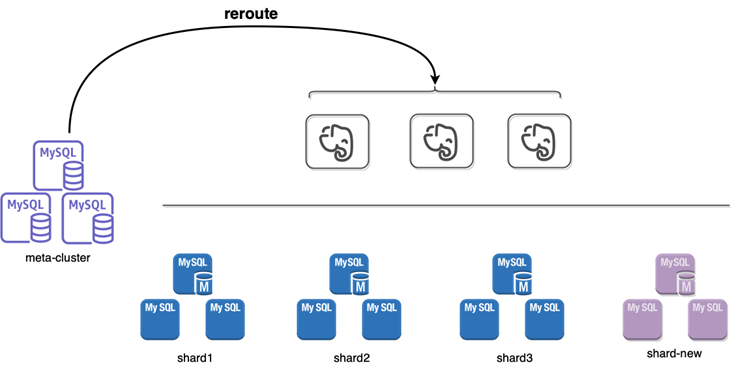
当数据同步的延迟在一个合理的小的范围内的时候,此时会在源shard上对表进行rename操作,切断业务的新的请求。完成rename操作后,整个数据同步链路会被切断。假设表A在shuffle-set中,那么此刻,shard-2上包含一个表A-renamed,同时,shard-new上也包含一个完全想同的表A-renamed(rename 操作也会由源 shard 同步到目标shard)。
2.2 计算层水平扩容
昆仑分布式数据库的计算节点采用无状态服务设计,所有的计算节点不在本地持久化任何与集群相关的数据。
因此,在计算能力扩容的设计和实现上,昆仑分布式数据库有着天然的优势,即快速的部署计算节点服务到集群中,计算节点服务在拉起后,会自动的从元数据集群中同步相关信息,包括路由信息,存储节点相关信息等。

由于所有的元数据处理都是内存操作,因此计算节点从扩容开始到对外服务的时间窗口非常的短暂,可以实现敏捷的计算能力的横向扩展。
2.3 容错与回滚机制
从上面的扩容流程我们可以看到,整个过程包含了多个子任务的,且涉及到了多个物理设备,因此健壮的容错和回滚设计是保证系统高可用的必然要求。
结合上述扩容流程设计,在不同的阶段发生故障的处理方式如下:
如果dump文件失败,则可以进行重试(重试次数默认3次,可配置)。
如果dump的数据文件在物理设备间的传输失败,则可以重试(重试次数默认3次,可配置)。
如果load操作失败,则可以重试(重试次数默认3次,可配置)。
Table catch up即建立新shard与源shard的关于shuffle-set的数据同步通路,重放增量数据改动日志的过程,如果该过程失败,则需要返回错误信息以供分析。之后终止流程,并清理新实例上的shuffle-set相关数据。
进入表切换流程后,原则上在没有发生如网络隔离,物理设备掉电等灾难情况下,表切换必须成功。因此在实现机制上,我们在源shard上执行rename操作前,会强行终止持锁的会话确保rename不会因为锁竞争而失败。
从完成源shard的rename操作后3秒内,如果此时在shard-new上,确实没有完成rename的replay(如出现上述的物理灾难),则需要终止流程,快速的恢复源实例上的已经被rename的包含在shuffle-set中的表,恢复对外服务。
三、规划与展望
随着昆仑分布式数据库版本的不断迭代和发展,关于水平扩容能力的建设会逐渐趋于精细化和智能化,目前相关的特性计划覆盖了如shuffle-set的选择,shuffle流程的优化提效等。
具体如下:
shuffle-set的构建,一方面是为了更好的扩展热点shard,提升整个数据库服务的热点数据管控服务能力,另一方面,灵活有效的shuffle-set也是分布式查询优化得以高效执行的重要手段。因此在后续版本的迭代上,这部分能力也将是我们重点关注的。
快速高效的shuffle有助于数据库整体效能的提升,后续版本会重点关注shuffle 的效率,如尝试实现流水线式的数据shuffle策略等。
KunlunBase项目已开源
【GitHub:】
https://github.com/zettadb
【Gitee:】
https://gitee.com/zettadb
原文链接:
KunlunBase(昆仑数据库)之 ScaleOut 介绍 - Powered by MinDoc![]() http://www.kunlunbase.com:8181/docs/b/b-1dnl0ntg2bt4o
http://www.kunlunbase.com:8181/docs/b/b-1dnl0ntg2bt4o
推荐阅读:
KunlunBase架构介绍 - Powered by MinDoc (kunlunbase.com)![]() http://www.kunlunbase.com:8181/docs/b/b-1dnl0ff08vm42KunlunBase技术优势介绍 - Powered by MinDoc (kunlunbase.com)
http://www.kunlunbase.com:8181/docs/b/b-1dnl0ff08vm42KunlunBase技术优势介绍 - Powered by MinDoc (kunlunbase.com)![]() http://www.kunlunbase.com:8181/docs/b/b-1dnl0hidnehicKunlunBase技术特点介绍 - Powered by MinDoc (kunlunbase.com)
http://www.kunlunbase.com:8181/docs/b/b-1dnl0hidnehicKunlunBase技术特点介绍 - Powered by MinDoc (kunlunbase.com)![]() http://www.kunlunbase.com:8181/docs/b/b-1dnl0gmd9l44gKunlun-Storage vs PostgreSQL OLTP 测试 - Powered by MinDoc (kunlunbase.com)
http://www.kunlunbase.com:8181/docs/b/b-1dnl0gmd9l44gKunlun-Storage vs PostgreSQL OLTP 测试 - Powered by MinDoc (kunlunbase.com)![]() http://www.kunlunbase.com:8181/docs/b/b-1dq86ad4auj8ePostgreSQL vs MySQL TPC-H 测试 - Powered by MinDoc (kunlunbase.com)
http://www.kunlunbase.com:8181/docs/b/b-1dq86ad4auj8ePostgreSQL vs MySQL TPC-H 测试 - Powered by MinDoc (kunlunbase.com)![]() http://www.kunlunbase.com:8181/docs/b/b-1dp6drao3djef
http://www.kunlunbase.com:8181/docs/b/b-1dp6drao3djef
END
这篇关于昆仑分布式数据库之ScaleOut介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




