本文主要是介绍使用Libtorch实现AlexNet,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
引言
定义数据集
定义网络结构
训练以及预测
总结
引言
本文通过C++代码实现了AlexNet算法,使用的是Libtorch框架,版本为1.7.1。另外本专栏的所有算法都有对应的Pytorch版本(AlexNet的Pytorch版本博客链接)且两个版本的代码逻辑基本一致,算法原理本文不做过多阐述。本文针对小白对代码以及相关函数进行讲解,建议配合代码进行阅读,代码中我进行了详细的注释,因此读者可以更加容易理解代码的含义,本文只展示了部分代码,全部代码可以通过GitHub下载。程序需要安装opencv(C++版本)以及Libtorch才能运行哦!!!,我个人是使用的Visual Studio 2017,VS什么版本的不重要,主要是上面两个库得安装好,安装方法不难所以这里就不附上安装教程了。
本文使用0~9的手写数据集(可在Github中下载)进行说明,全部代码主要分为以下几个部分:
1、定义数据集(dataset.h / dataset.cpp)
2、定义网络结构(model.h / model.cpp)
3、定义训练以及预测方法(result.h / result.cpp)
4、主函数(main.cpp)

定义数据集
在Pytorch版本的代码中使用到了torchvision中datasets.ImageFolder函数,而在Libtorch中没有这一函数,所以一般需要自定义数据集的处理方式,目的是将所有的图片以及对应的标签打包成神经网络所需要的输入格式(在AlexNet中需要输入尺寸为(224,224)大小的图片)。在代码中则是需要重写get()和size()方法。
以下为头文件中的部分代码:
# include "dataset.h"void dataSetClc::load_data_from_folder(std::string path, std::string type, std::vector<std::string> &list_images, std::vector<int> &list_labels, int label)
{// 声明变量long long hFile = 0; //句柄struct _finddata_t fileInfo; // _finddata_t为一个结构体std::string pathName;if ((hFile = _findfirst(pathName.assign(path).append("\\*.*").c_str(), &fileInfo)) == -1){return;}do{const char* s = fileInfo.name;const char* t = type.data();if (fileInfo.attrib&_A_SUBDIR) //是子文件夹{//遍历子文件夹中的文件(夹)if (strcmp(s, ".") == 0 || strcmp(s, "..") == 0) //子文件夹目录是.或者..continue;std::string sub_path = path + "\\" + fileInfo.name;label++;load_data_from_folder(sub_path, type, list_images, list_labels, label);}else //判断是不是后缀为type文件{if (strstr(s, t)){std::string image_path = path + "\\" + fileInfo.name;// 将图像路径以及对应标签存进vector容器中list_images.push_back(image_path);list_labels.push_back(label);}}} while (_findnext(hFile, &fileInfo) == 0);
}torch::data::Example<> dataSetClc::get(size_t index)
{std::string image_path = image_paths.at(index); //vector的切片cv::Mat image = cv::imread(image_path); // opencv读取图像cv::resize(image, image, cv::Size(224, 224)); //尺寸统一cv::cvtColor(image,image,cv::COLOR_BGR2RGB); // BGR—>RGBint label = labels.at(index); // 读取类别信息// 将opencv格式的矩阵转化为张量torch::Tensor img_tensor = torch::from_blob(image.data, { image.rows, image.cols, 3 }, torch::kByte).permute({ 2, 0, 1 }); // Channels x Height x Widthtorch::Tensor label_tensor = torch::full({ 1 }, label);return { img_tensor, label_tensor };
}torch::optional<size_t> dataSetClc::size() const
{return image_paths.size();
};介绍一下各个函数的作用:
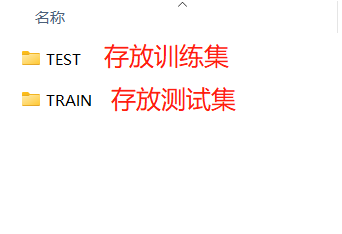
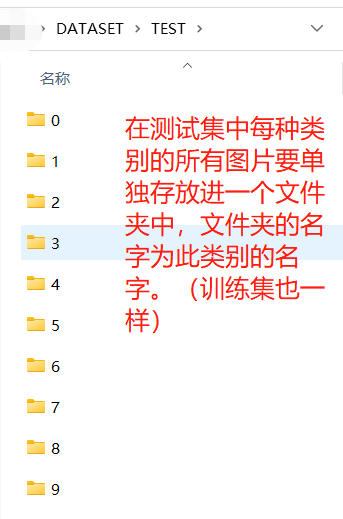
void load_data_from_folder:此函数在构造函数中,所以在实例化类对象时自动执行。主要功能为:读取各个文件夹,并将所有图片的路径与标签保存分别存入image_paths以及labels两个私有成员。此函数对数据集的摆放格式具有一定要求,其要求与python中torchvision中datasets.ImageFolder函数一致。以0~9手写数据集为例,格式参考下图:
介绍上面出场的函数:
_finddata_t为结构体名称其含有几个成员:
_findfirst:找到第一个文件(夹)若没有找到则返回-1
_findnext:找本文件夹下的下一个成员,若没有找到返回-1
fileinfo:以上两者若找到,其信息存储在fileinfo中 (fileinfo.name)torch::data::Example<> get(size_t index):此函数主要功能为:根据index用opencv读取image_paths中的图像并且返回两个张量(像素矩阵,标签)。注意!!pytorch与Libtorch一样,对输入的图像矩阵有要求必须为 [ batch_size , channel , height , width ] ,batch_size这一维度在DataLoader时会自动添加上,而opencv读取到的图片格式为BGR且为 [ height , width , channel ] 格式的图片,为了与Pytorch版本的代码保持一致,这里也转换成RGB且为 [ channel , height , width ] 格式的图片。
介绍上面出场的函数:
// opencv读取图片,格式为BGR
cv::Mat image = cv::imread(image_path);
// 将图片尺寸resize成224*224
cv::resize(image, image, cv::Size(224, 224));
// 将BGR格式转换成RGB
cv::cvtColor(image,image,cv::COLOR_BGR2RGB);
// 将opencv的MAT格式的图片转变为Tensor,permute为[h,w,c] -> [c,h,w]
torch::Tensor img_tensor = torch::from_blob(image.data, { image.rows, image.cols, 3 }, torch::kByte).permute({ 2, 0, 1 });torch::optional<size_t> dataSetClc::size():此函数返回数据集大小(图像数量)。
定义网络结构
此模块的代码逻辑与Python版本的完全一致,具体实现了:1、定义网络结构 2、初始化结构参数。网络结构如下表所示,注意:在Libtorch中定义完网络结构都需要“注册”一下才能被使用。权重初始化函数也与Python版本逻辑一致。
首先是特征提取部分的网络结构,其中每一次卷积后都需要加ReLu激活函数。
| 层名\参数 | 输入通道数 | 输出通道数 | 卷积核大小 | 步长 | 填充数 | 备注 |
| 卷积层 | 3 | 96 | 11 | 4 | 2 | 后接ReLu |
| 最大池化层 | 3 | 2 | 0 | |||
| 卷积层 | 96 | 256 | 5 | 1 | 2 | 后接ReLu |
| 最大池化层 | 3 | 2 | 0 | |||
| 卷积层 | 256 | 384 | 3 | 1 | 1 | 后接ReLu |
| 卷积层 | 384 | 384 | 3 | 1 | 1 | 后接ReLu |
| 卷积层 | 384 | 256 | 3 | 1 | 1 | 后接ReLu |
| 最大池化层 | 3 | 2 | 0 |
然后是线性分类部分的网络结构:
| 层名\参数 | 输入通道数 | 输出通道数 | 备注 |
| Dropout层 | 0.5 | ||
| 全连接层 | 256*6*6 | 2048 | 后接ReLu |
| Dropout层 | 0.5 | ||
| 全连接层 | 2048 | 2048 | 后接ReLu |
| 全连接层 | 2048 | NUM_CLASS |
以下为部分代码
#include "model.h"// 构造函数定义网络结构
AlexNet::AlexNet(int NUM_CLASS, bool init_weight)
{// 特征提取部分的网络结构features = torch::nn::Sequential(torch::nn::Conv2d(torch::nn::Conv2dOptions(3, 96, 11).stride(4).padding(2)), // 定义卷积层torch::nn::ReLU(torch::nn::ReLUOptions(true)), // ReLu激活函数torch::nn::MaxPool2d(torch::nn::MaxPool2dOptions(3).stride(2)), // 定义最大池化层torch::nn::Conv2d(torch::nn::Conv2dOptions(96, 256, 5).stride(1).padding(2)),torch::nn::ReLU(torch::nn::ReLUOptions(true)),torch::nn::MaxPool2d(torch::nn::MaxPool2dOptions(3).stride({2,2})),torch::nn::Conv2d(torch::nn::Conv2dOptions(256, 384, 3).stride(1).padding(1)),torch::nn::ReLU(torch::nn::ReLUOptions(true)),torch::nn::Conv2d(torch::nn::Conv2dOptions(384, 384, 3).stride(1).padding(1)),torch::nn::ReLU(torch::nn::ReLUOptions(true)),torch::nn::Conv2d(torch::nn::Conv2dOptions(384, 256, 3).stride(1).padding(1)),torch::nn::ReLU(torch::nn::ReLUOptions(true)),torch::nn::MaxPool2d(torch::nn::MaxPool2dOptions(3).stride(2)));// 然后是线性分类部分的网络结构classifier = torch::nn::Sequential(torch::nn::Dropout(torch::nn::DropoutOptions().p(0.5)), // 定义Dropout层,随机丢弃神经元torch::nn::Linear(torch::nn::LinearOptions(256*6*6, 2048)), // 定义全连接层torch::nn::ReLU(torch::nn::ReLUOptions(true)),torch::nn::Dropout(torch::nn::DropoutOptions().p(0.5)),torch::nn::Linear(torch::nn::LinearOptions(2048, 2048)),torch::nn::ReLU(torch::nn::ReLUOptions(true)),torch::nn::Linear(torch::nn::LinearOptions(2048, NUM_CLASS)) // NUM_CLASS根据自己的数据集类别总数更改);// 在libtorch中定义的网络都要注册一下features = register_module("features", features);classifier = register_module("classifier", classifier);if (init_weight){define_weight();}
}//前向传播函数
torch::Tensor AlexNet::forward(torch::Tensor x)
{ x = features->forward(x);x = torch::flatten(x, 1);x = classifier->forward(x);return x;
}//初始化权重参数
void AlexNet::define_weight()
{for (auto m : this->modules(false)){if (m->name() == "torch::nn::Conv2dImpl") // 初始化卷积层参数{printf("init the conv2d parameters.\n");auto spConv2d = std::dynamic_pointer_cast<torch::nn::Conv2dImpl>(m);spConv2d->reset_parameters();// Kaiming He 创造的权重初始化方法torch::nn::init::kaiming_normal_(spConv2d->weight, 0.0, torch::kFanOut, torch::kReLU);if (spConv2d->options.bias())torch::nn::init::constant_(spConv2d->bias, 0);}//else if (m->name() == "torch::nn::BatchNorm2dImpl")//{// printf("init the batchnorm2d parameters.\n");// auto spBatchNorm2d = std::dynamic_pointer_cast<torch::nn::BatchNorm2dImpl>(m);// torch::nn::init::constant_(spBatchNorm2d->weight, 1);// torch::nn::init::constant_(spBatchNorm2d->bias, 0);//}else if (m->name() == "torch::nn::LinearImpl") // 初始化全连接层参数{printf("init the Linear parameters.\n");auto spLinear = std::dynamic_pointer_cast<torch::nn::LinearImpl>(m);torch::nn::init::normal_(spLinear->weight,0,0.01);torch::nn::init::constant_(spLinear->bias, 0);}}}介绍一下出场的函数:
// 定义一个网络块,括号内输入网络结构
name = features = torch::nn::Sequential()// in:输入通道数 out:输出通道数 kernel_size:卷积核尺寸,stride(x):步长为x padding(y):填充数为y
// 定义卷积层
torch::nn::Conv2d(torch::nn::Conv2dOptions(in, out, kernel_size).stride(4).padding(2))
//定义最大池化层
torch::nn::MaxPool2d(torch::nn::MaxPool2dOptions(kernel_size).stride(x))
// 定义ReLu激活函数(inplace=True会改变输入数据的值,节省反复申请与释放内存的空间与时间,效率更好)
torch::nn::ReLU(torch::nn::ReLUOptions(true))
// 定义Dropout层,随机丢弃50%神经元
torch::nn::Dropout(torch::nn::DropoutOptions().p(0.5))
// 定义全连接层
torch::nn::Linear(torch::nn::LinearOptions(in, out))训练以及预测
训练以及预测我都将其放置在同一个类内,分别使用void train() 以及 void pred() 这两个函数来实现。首先谈一下训练部分,具体训练步骤如下:
1、定义数据集
与Pytorch版本方式一致,定义dataset(上文定义的dataset类)然后使用dataLoader将其打包。代码如下
// 1、定义数据集
auto train_dataset = dataSetClc("F:\\CCCCCProject\\AlexNet\\Project1\\DATASET\\TRAIN", ".bmp").map(torch::data::transforms::Stack<>()); // 数据集自定义 bmp为后缀名(图片的后缀名也可以为其他比如:JPG,PNG等)
auto test_dataset = dataSetClc("F:\\CCCCCProject\\AlexNet\\Project1\\DATASET\\TEST", ".bmp").map(torch::data::transforms::Stack<>());auto train_dataLoader = torch::data::make_data_loader<torch::data::samplers::RandomSampler>(std::move(train_dataset), 2); // batch_size = 2
auto test_dataLoader = torch::data::make_data_loader<torch::data::samplers::RandomSampler>(std::move(test_dataset), 2);
2、定义网络结构,并设置为CUDA
// 2、定义网络结构 并初始化权重参数
auto device_type = torch::kCUDA
class AlexNet m_Alex(10, true); // AlexNet为上文定义的网络结构
m_Alex.to(device_type);
3、定义损失函数以及优化器
// 3、定义损失函数以及优化器
torch::optim::SGD optimizer(m_Alex.parameters(), torch::optim::SGDOptions(m_learn_rate[0]));
torch::nn::CrossEntropyLoss loss_function;
4、开始训练(设置学习率随迭代次数增加而减小)
// 4、开始训练 (学习率随着迭代增加而减小)
for (int now_iter = 0; now_iter < Iter; now_iter++){if (now_iter == 4) // 在第四次迭代时学习率设置为m_learn_rate[1]{updata_learn_rate(optimizer, m_learn_rate[1]);}if (now_iter == 8){updata_learn_rate(optimizer, m_learn_rate[2]);}m_Alex.train(); int now_epoch = 0;float total_loss = 0.0f;for (auto& batch : *train_dataLoader) // 遍历数据集{now_epoch += 1;auto data = batch.data; // 图像矩阵auto target = batch.target.squeeze(); // 标签data = data.to(torch::kF32).to(device_type).div(255.0); // 将图像转变为张量+标准化( div(255.0) )+ 设置为CUDAtarget = target.to(torch::kInt64).to(device_type); // 标签设置为CUDA// 下面代码可以查看图像尺寸 batch_size * channal * width * height//c10::IntArrayRef tsize = data.sizes();//int a = tsize[0];//int b = tsize[1];//int c = tsize[2];//int d = tsize[3];//std::cout << a << b << c << d << std::endl;// 前向传播torch::Tensor prediction = m_Alex.forward(data);// 计算损失大小torch::Tensor loss = loss_function(prediction, target);total_loss += loss.item<float>();// 将梯度归零有助于梯度下降optimizer.zero_grad(); // 反向传播 计算梯度loss.backward();// 根据梯度更新模型参数optimizer.step();// 打印训练信息if (now_epoch % 5 == 0){printf("Iter [%d/%d], Epoch [%d] Loss: %.4f\n",now_iter,Iter,now_epoch, total_loss / (now_epoch + 1));//std::cout << "Epoch" << i << " Loss=" << total_loss / (i + 1) << std::endl;}}}然后是预测部分,预测部分相对容易一点。主要分为两种情况,一种是使用Python训练转变为C++的模型,另一种是使用C++训练的模型。这里解释一下为什么会分为两种情况,使用Python转变过来文件的不仅包含参数,也包含模型,所以在预测的时候只需要将pt文件导入即可预测,而使用本文训练的C++模型它只包括参数,不包含模型,所以需要先定义模型结构再导入pt文件。
在Github中我会给出转变Python模型的代码,有兴趣的可以自行下载,以下为两种情况的代码:
// 使用Python转换过来的模型文件进行预测
void Result::pred()
{torch::jit::script::Module m_Alex = torch::jit::load("F:/CCCCCProject/AlexNet/Project1/AlexNet.pt", device_type); // 输入预测的图片的路径cv::Mat img = cv::imread(img_root); // opencv读取图片cv::cvtColor(img, img, cv::COLOR_BGR2RGB); // BGR—>RGBcv::resize(img, img, cv::Size(224, 224));// 将opencv读到的图片转成Tensor并且将BGR格式转成RGB格式torch::Tensor img_tensor = torch::from_blob(img.data, { img.rows, img.cols, 3 }, torch::kByte).permute({ 2, 0, 1 }); // Channels x Height x Width img_tensor = torch::unsqueeze(img_tensor,0);img_tensor = img_tensor.to(torch::kF32).to(device_type).div(255.0);// 开始预测std::vector<torch::jit::IValue> inputs;inputs.push_back(img_tensor);m_Alex.eval();auto o = m_Alex.forward(std::move(inputs));at::Tensor result = o.toTensor();// 得到预测的结果 result的size = 1 * 10 的张量std::cout << "网络输出的结果是" << result << std::endl;auto class1 = torch::max(result,1);// 打印预测的类别std::cout << "预测的结果是:" << CLASS_NAME[std::get<1>(class1).item<int>()] << std::endl;
}// 使用C++训练得到的模型文件进行预测
void Result::pred1()
{AlexNet m_Alex(NUM_CLASS, false); //NUM_CLASS为数据集类别总数m_Alex->to(device_type);torch::load(m_Alex, "AlexNet_CPP.pt");cv::Mat img = cv::imread(img_root); // opencv读取图片cv::cvtColor(img, img, cv::COLOR_BGR2RGB); // BGR—>RGBcv::resize(img, img, cv::Size(224, 224));// 将opencv读到的图片转成Tensor并且将BGR格式转成RGB格式torch::Tensor img_tensor = torch::from_blob(img.data, { img.rows, img.cols, 3 }, torch::kByte).permute({ 2, 0, 1 }); // Channels x Height x Width img_tensor = torch::unsqueeze(img_tensor, 0);img_tensor = img_tensor.to(torch::kF32).to(device_type).div(255.0);prediction = m_Alex->forward(img_tensor);std::cout << "网络输出的结果是" << prediction << std::endl;auto class1 = torch::max(prediction, 1);// 打印预测的类别std::cout << "预测的结果是:" << CLASS_NAME[std::get<1>(class1).item<int>()] << std::endl;
}这里附上预测结果:可以看到预测正确

总结
本文中默认使用的数据集为0~9的手写数据集,但是读者也可以使用自己的训练集进行训练以及预测,但是需要对代码进行小小地更改,更改方法以及手写数据集下载链接一并放在了Github中。
这篇关于使用Libtorch实现AlexNet的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




