本文主要是介绍PostgreSQL json /jsonb类型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
说明
JSON 数据类型是用来存储 JSON(JavaScript Object Notation) 数据的。这种数据也可以被存储为text,但是 JSON 数据类型的 优势在于能强制要求每个被存储的值符合 JSON 规则。也有很多 JSON 相关的函 数和操作符可以用于存储在这些数据类型中的数据.
PostgreSQL支持两种 JSON 数据类型:json 和 jsonb。它们几乎接受完全相同的值集合作为输入。两者最大的区别是效率。json数据类型存储输入文本的精准拷贝,处理函数必须在每 次执行时必须重新解析该数据。而jsonb数据被存储在一种分解好的二进制格式中,因为需要做附加的转换,它在输入时要稍慢一些。但是 jsonb在处理时要快很多,因为不需要重新解析。
重点:jsonb支持索引
由于json类型存储的是输入文本的准确拷贝,存储时会空格和JSON 对象内部的键的顺序。如果一个值中的 JSON 对象包含同一个键超过一次,所有的键/值对都会被保留(** 处理函数会把最后的值当作有效值**)。
jsonb不保留空格、不保留对象键的顺序并且不保留重复的对象键。如果在输入中指定了重复的键,只有最后一个值会被保留。
在把文本 JSON 输入转换成jsonb时,JSON的基本类型(RFC 7159[1] )会被映射到原生的 PostgreSQL类型。因此,jsonb数据有一些次要额外约束。比如:jsonb将拒绝除 PostgreSQL numeric数据类型范围之外的数字,而json则不会。
JSON 基本类型和相应的PostgreSQL类型
| JSON 基本类型 | PostgreSQL类型 | 注释 |
|---|---|---|
| string | text | 不允许\u0000,如果数据库编码不是 UTF8,非 ASCII Unicode 转义也是这样 |
| number | numeric | 不允许NaN 和 infinity值 |
| boolean | boolean | 只接受小写true和false拼写 |
| null | (无) | SQL NULL是一个不同的概念 |
json 输入输出语法
-- 简单标量/基本值
-- 基本值可以是数字、带引号的字符串、true、false或者null
SELECT '5'::json;-- 有零个或者更多元素的数组(元素不需要为同一类型)
SELECT '[1, 2, "foo", null]'::json;-- 包含键值对的对象
-- 注意对象键必须总是带引号的字符串
SELECT '{"bar": "baz", "balance": 7.77, "active": false}'::json;-- 数组和对象可以被任意嵌套
SELECT '{"foo": [true, "bar"], "tags": {"a": 1, "b": null}}'::json;-- "->" 通过键获得 JSON 对象域 结果为json对象
select '{"nickname": "goodspeed", "avatar": "avatar_url", "tags": ["python", "golang", "db"]}'::json->'nickname' as nickname;nickname
-------------"goodspeed"
(1 row)-- "->>" 通过键获得 JSON 对象域 结果为text
select '{"nickname": "goodspeed", "avatar": "avatar_url", "tags": ["python", "golang", "db"]}'::json->>'nickname' as nickname;nickname
-----------goodspeed-- "->" 通过键获得 JSON 对象域 结果为json对象
select '{"nickname": "goodspeed", "avatar": "avatar_url", "tags": ["python", "golang", "db"]}'::jsonb->'nickname' as nickname;nickname
-------------"goodspeed"
(1 row)-- "->>" 通过键获得 JSON 对象域 结果为text
select '{"nickname": "goodspeed", "avatar": "avatar_url", "tags": ["python", "golang", "db"]}'::jsonb->>'nickname' as nickname;nickname
-----------goodspeed
(1 row)
json 和 jsonb 的操作符列表
json和jsonb 操作符

额外的jsonb操作符
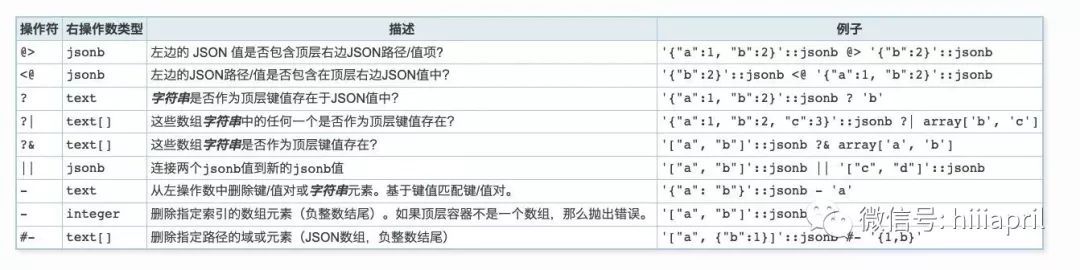
json 查询语法
在使用JSON文档时,推荐 将JSON 文档存储为固定的结构。(该结构是非强制的,但是有一个可预测的结构会使集合的查询更容易。 )设计JSON文档建议:任何更新都在整行上要求一个行级锁。为了减少锁争夺,JSON 文档应该每个表示 一个原子数据(业务规则上的不可拆分,可独立修改的数据)
常用的比较操作符
| 操作符 | 描述 |
|---|---|
| < | 小于 |
| > | 大于 |
| <= | 小于等于 |
| >= | 大于等于 |
| = | 等于 |
| <> or != | 不等于 |
包含和存在(json 数据查询(适用于jsonb)
-> 和 ->> 操作符
使用 ->> 查出的数据为text 使用 -> 查出的数据为json 对象
-- nickname 为 gs 的用户 这里使用 ->> 查出的数据为text,所以匹配项也应该是text
select '{"nickname": "gs", "avatar": "avatar_url", "tags": ["python", "golang", "db"]}'::json->>'nickname' = 'gs';
select '{"nickname": "gs", "avatar": "avatar_url", "tags": ["python", "golang", "db"]}'::jsonb->>'nickname' = 'gs';-- 使用 -> 查询,会抛出错误,这里无论匹配项是text类型的 'gs' 还是 json 类型的 '"gs"'::json都会抛出异常,json 类型不支持 等号(=)操作符
select '{"nickname": "gs", "avatar": "avatar_url", "tags": ["python", "golang", "db"]}'::json->'nickname' = '"gs"';
ERROR: operator does not exist: json = unknownselect '{"nickname": "gs", "avatar": "avatar_url", "tags": ["python", "golang", "db"]}'::json->'nickname' = '"gs"'::json;
ERROR: operator does not exist: json = json-- jsonb 格式是可以查询成功的,这里使用 -> 查出的数据为json 对象,所以匹配项也应该是json 对象
select '{"nickname": "gs", "avatar": "avatar_url", "tags": ["python", "golang", "db"]}'::jsonb->'nickname' = '"gs"';
#> 和 #>> 操作符
使用 #>> 查出的数据为text 使用 #> 查出的数据为json 对象
select '{"nickname": "gs", "avatar": "avatar_url", "tags": ["python", "golang", "db"]}'::json#>'{tags,0}' as tag;tag
----------"python"select '{"nickname": "gs", "avatar": "avatar_url", "tags": ["python", "golang", "db"]}'::json#>>'{tags,0}' as tag;tag
--------pythonselect '{"nickname": "gs", "avatar": "avatar_url", "tags": ["python", "golang", "db"]}'::jsonb#>'{tags,0}' = '"python"';?column?
----------t
select '{"nickname": "gs", "avatar": "avatar_url", "tags": ["python", "golang", "db"]}'::jsonb#>>'{tags,0}' = 'python';?column?
----------tselect '{"nickname": "gs", "avatar": "avatar_url", "tags": ["python", "golang", "db"]}'::json#>>'{tags,0}' = 'python';?column?
----------t
-- 会抛出错误,这里无论匹配项是text类型的 'python' 还是 json 类型的 '"python"'::json都会抛出异常,json 类型不支持 等号(=)操作符
select '{"nickname": "gs", "avatar": "avatar_url", "tags": ["python", "golang", "db"]}'::json#>'{tags,0}' = '"python"';
ERROR: operator does not exist: json = unknown
jsonb 查询语法(不适用于json)
@>操作符
-- nickname 为 nickname 的用户
select '{"nickname": "gs", "avatar": "avatar_url", "tags": ["python", "golang", "db"]}'::jsonb @> '{"nickname": "gs"}'::jsonb;-- 等同于以下查询
-- 这里使用 -> 查出的数据为json 对象,所以匹配项也应该是json 对象
select '{"nickname": "gs", "avatar": "avatar_url", "tags": ["python", "golang", "db"]}'::jsonb->'nickname' = '"gs"';
select '{"nickname": "gs", "avatar": "avatar_url", "tags": ["python", "golang", "db"]}'::jsonb->>'nickname' = 'gs';-- 查询有 python 和 golang 标签的数据
select '{"nickname": "gs", "avatar": "avatar_url", "tags": ["python", "golang", "db"]}'::jsonb @> '{"tags": ["python", "golang"]}';?column?
----------t
?操作符、?|操作符和?&操作符
-- 查询有 avatar 属性的用户
select '{"nickname": "gs", "avatar": "avatar_url", "tags": ["python", "golang", "db"]}'::jsonb ? 'avatar';
-- 查询有 avatar 属性 并且avatar 数据不为空的数据
select '{"nickname": "gs", "avatar": null, "tags": ["python", "golang", "db"]}'::jsonb->>'avatar' is not null;-- 查询 有 avatar 或 tags 的数据
select '{"nickname": "gs", "tags": ["python", "golang", "db"]}'::jsonb ?| array['avatar', 'tags'];?column?
----------t-- 查询 既有 avatar 又有 tags 的用户
select '{"nickname": "gs", "tags": ["python", "golang", "db"]}'::jsonb ?& array['avatar', 'tags'];?column?
----------f-- 查询 tags 中包含 python 标签的数据select '{"nickname": "gs", "avatar": "avatar_url", "tags": ["python", "golang", "db"]}'::jsonb->'tags' ? 'python';?column?
----------t-- 查询数组中包含某一个选项的数据(可以作为字符串之间查询)SELECT ('["52e32db069c3338058490199606381f6", "566e32db069c3338058490199606381"]'::varchar @@ '52e32db069c3338058490199606381f6 566e32db069c3338058490199606381') ;?column?
----------t更新
-- 更新 account content 字段(覆盖式更新)
update account set content = jsonb_set(content, '{}', '{"nickname": "gs", "tags": ["python", "golang", "db"]}', false);-- 修改nickanme为nickanme 的用户标签
update account set content = jsonb_set(content, '{tags}', '["test", "心理"]', true) where content @> '{"nickname": "nickname"}'::jsonb;update account set content = jsonb_set(content, '{tags}', '["test", "心理", "医疗"]', true) where content @> '{"nickname": "nickname"}'::jsonb;-- 更新account content字段中 weixin_mp 的值(如果没有会创建)update account set content = jsonb_set(content, '{weixin_mp}', '"weixin_mp5522bd28-ed4d-11e8-949c-7200014964f0"', true) where id='5522bd28-ed4d-11e8-949c-7200014964f0';-- 更新account 去除content 中weixin 字段(如果没有weixin 字段也不会抛出异常)
update account set content= content - 'weixin' where id='5522bd28-ed4d-11e8-949c-7200014964f0';jsonb相关函数
jsonb_pretty
jsonb_pretty 作为缩进JSON文本返回from_json。
select jsonb_pretty('[{"f1":1,"f2":null},2,null,3]');jsonb_pretty
--------------------[ +{ +"f1": 1, +"f2": null+}, +2, +null, +3 +]
(1 row)
jsonb_set
jsonb_set() 函数参数如下:
jsonb_set(target jsonb, // 需要修改的数据path text[], // 数据路径new_value jsonb, // 新数据create_missing boolean default true)
如果create_missing 是true (缺省是true),并且path指定的路径在target 中不存在,那么target将包含path指定部分, new_value替换部分, 或者new_value添加部分。
-- target 结构
select jsonb_pretty('[{"f1":1,"f2":null},2]');jsonb_pretty
--------------------[ +{ +"f1": 1, +"f2": null+}, +2 +]-- 更新 target 第0 个元素 key 为 f1 的值,如果f1 不存在 忽略
select jsonb_set('[{"f1":1,"f2":null},2,null,3]', '{0,f1}','[2,3,4]', false);jsonb_set
---------------------------------------------[{"f1": [2, 3, 4], "f2": null}, 2, null, 3]-- 更新 target 第0 个元素 key 为 f3 的值,如果f3 不存在 创建
select jsonb_set('[{"f1":1,"f2":null},2]', '{0,f3}','[2,3,4]');jsonb_set
---------------------------------------------[{"f1": 1, "f2": null, "f3": [2, 3, 4]}, 2]-- 更新 target 第0 个元素 key 为 f3 的值,如果f3 不存在 忽略
select jsonb_set('[{"f1":1,"f2":null},2]', '{0,f3}','[2,3,4]', false);jsonb_set
---------------------------------------------[{"f1": 1, "f2": null}, 2]
jsonb 性能分析
使用下面的例子来说明一下json 的查询性能
表结构
-- account 表 id 使用uuid 类型,需要先添加uuid-ossp模块。
CREATE EXTENSION IF NOT EXISTS "uuid-ossp";-- create table
create table account (id UUID NOT NULL PRIMARY KEY default uuid_generate_v1(), content jsonb, created_at timestamptz DEFAULT CURRENT_TIMESTAMP, updated_at timestamptz DEFAULT CURRENT_TIMESTAMP);
插入数据
-- 插入10w条有 nickname avatar tags 为["python", "golang", "c"]的数据
insert into account select uuid_generate_v1(), ('{"nickname": "nn-' || round(random()*2000000) || '", "avatar": "avatar_url", "tags": ["python", "golang", "c"]}')::jsonb from (select * from generate_series(1,100000)) as tmp;-- 插入10w条有 nickname tags 为["python", "golang"]的数据
insert into account select uuid_generate_v1(), ('{"nickname": "nn-' || round(random()*2000000) || '", "tags": ["python", "golang"]}')::jsonb from (select * from generate_series(1,100000)) as tmp;-- 插入10w条有 nickname tags 为["python"]的数据
insert into account select uuid_generate_v1(), ('{"nickname": "nn-' || round(random()*2000000) || '", "tags": ["python"]}')::jsonb from (select * from generate_series(1,100000)) as tmp;测试查询
- EXPLAIN:显示PostgreSQL计划程序为提供的语句生成的执行计划。
- ANALYZE:收集有关数据库中表的内容的统计信息。
-- content 中有avatar key 的数据条数 count(*) 查询不是一个好的测试语句,就算是有索引,也只能起到过滤的作用,如果结果集比较大,查询速度还是会很慢
explain analyze select count(*) from account where content::jsonb ? 'avatar';QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------Finalize Aggregate (cost=29280.40..29280.41 rows=1 width=8) (actual time=170.366..170.366 rows=1 loops=1)-> Gather (cost=29280.19..29280.40 rows=2 width=8) (actual time=170.119..174.451 rows=3 loops=1)Workers Planned: 2Workers Launched: 2-> Partial Aggregate (cost=28280.19..28280.20 rows=1 width=8) (actual time=166.034..166.034 rows=1 loops=3)-> Parallel Seq Scan on account (cost=0.00..28278.83 rows=542 width=0) (actual time=0.022..161.937 rows=33333 loops=3)Filter: (content ? 'avatar'::text)Rows Removed by Filter: 400000Planning Time: 0.048 msExecution Time: 174.486 ms-- content 中没有avatar key 的数据条数
explain analyze select count(*) from account where content::jsonb ? 'avatar' = false;QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------Finalize Aggregate (cost=30631.86..30631.87 rows=1 width=8) (actual time=207.770..207.770 rows=1 loops=1)-> Gather (cost=30631.65..30631.86 rows=2 width=8) (actual time=207.681..212.357 rows=3 loops=1)Workers Planned: 2Workers Launched: 2-> Partial Aggregate (cost=29631.65..29631.66 rows=1 width=8) (actual time=203.565..203.565 rows=1 loops=3)-> Parallel Seq Scan on account (cost=0.00..28278.83 rows=541125 width=0) (actual time=0.050..163.629 rows=400000 loops=3)Filter: (NOT (content ? 'avatar'::text))Rows Removed by Filter: 33333Planning Time: 0.050 msExecution Time: 212.393 ms-- 查询content 中nickname 为nn-194318的数据
explain analyze select * from account where content@>'{"nickname": "nn-194318"}';QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------Gather (cost=1000.00..29408.83 rows=1300 width=100) (actual time=0.159..206.990 rows=1 loops=1)Workers Planned: 2Workers Launched: 2-> Parallel Seq Scan on account (cost=0.00..28278.83 rows=542 width=100) (actual time=130.867..198.081 rows=0 loops=3)Filter: (content @> '{"nickname": "nn-194318"}'::jsonb)Rows Removed by Filter: 433333Planning Time: 0.047 msExecution Time: 207.007 ms-- 对应的查询id 为 'b5b3ed06-7d35-11e9-b3ea-00909e9dab1d' 的数据
explain analyze select * from account where id='b5b3ed06-7d35-11e9-b3ea-00909e9dab1d';QUERY PLAN
------------------------------------------------------------------------------------------------------------------------Index Scan using account_pkey on account (cost=0.43..8.45 rows=1 width=100) (actual time=0.912..0.914 rows=1 loops=1)Index Cond: (id = 'b5b3ed06-7d35-11e9-b3ea-00909e9dab1d'::uuid)Planning Time: 0.348 msExecution Time: 0.931 ms
通过结果可以看到 使用 jsonb 查询和使用主键查询速度差异巨大,通过看查询分析记录可以看到,这两个语句最大的差别在于使用主键的查询用到了索引,而content nickname 的查询没有索引可以使用。 接下来测试一下使用索引时的查询速度。
GIN 索引介绍
JSONB 最常用的是GIN 索引,GIN 索引可以被用来有效地搜索在大量jsonb文档(数据)中出现 的键或者键值对。
GIN(Generalized Inverted Index, 通用倒排索引) 是一个存储对(key, posting list)集合的索引结构,其中key是一个键值,而posting list 是一组出现过key的位置。如(‘hello’, ‘14:2 23:4’)中,表示hello在14:2和23:4这两个位置出现过,在PG中这些位置实际上就是元组的tid(行号,包括数据块ID(32bit),以及item point(16 bit) )。
在表中的每一个属性,在建立索引时,都可能会被解析为多个键值,所以同一个元组的tid可能会出现在多个key的posting list中。
通过这种索引结构可以快速的查找到包含指定关键字的元组,因此GIN索引特别适用于多值类型的元素搜索,比如支持全文搜索,数组中元素的搜索,而PG的GIN索引模块最初也是为了支持全文搜索而开发的。
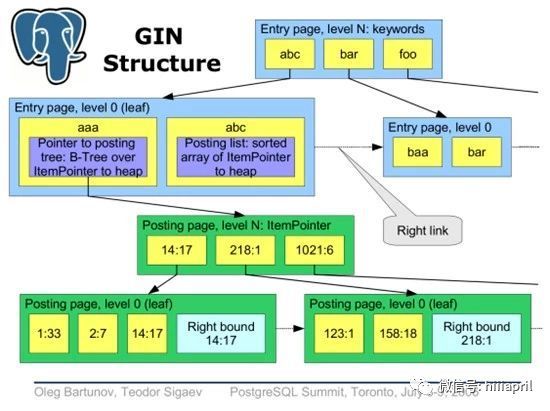
查询优化
创建默认索引
-- 创建简单索引
create index ix_account_content on account USING GIN (content);
使用索引
-- content 中有avatar key 的数据条数
explain analyze select count(*) from account where content::jsonb ? 'avatar';QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------Aggregate (cost=4180.49..4180.50 rows=1 width=8) (actual time=43.462..43.462 rows=1 loops=1)-> Bitmap Heap Scan on account (cost=30.07..4177.24 rows=1300 width=0) (actual time=8.362..36.048 rows=100000 loops=1)Recheck Cond: (content ? 'avatar'::text)Heap Blocks: exact=2032-> Bitmap Index Scan on ix_account_content (cost=0.00..29.75 rows=1300 width=0) (actual time=8.125..8.125 rows=100000 loops=1)Index Cond: (content ? 'avatar'::text)Planning Time: 0.078 msExecution Time: 43.503 ms
和之前没有添加索引时速度提升了3倍。
-- 查询content 中nickname 为nn-194318的数据
explain analyze select * from account where content@>'{"nickname": "nn-194318"}';QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------Bitmap Heap Scan on account (cost=46.08..4193.24 rows=1300 width=100) (actual time=0.097..0.097 rows=1 loops=1)Recheck Cond: (content @> '{"nickname": "nn-194318"}'::jsonb)Heap Blocks: exact=1-> Bitmap Index Scan on ix_account_content (cost=0.00..45.75 rows=1300 width=0) (actual time=0.091..0.091 rows=1 loops=1)Index Cond: (content @> '{"nickname": "nn-194318"}'::jsonb)Planning Time: 0.075 msExecution Time: 0.132 ms
这个查询效率提升更明显,竟然比使用主键还要高效。
使用表达式索引
下面这种查询并不能使用索引:
-- 查询content 中不存在 avatar key 的数据条数
explain analyze select count(*) from account where content::jsonb ? 'avatar' = false;QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------Finalize Aggregate (cost=30631.86..30631.87 rows=1 width=8) (actual time=207.641..207.641 rows=1 loops=1)-> Gather (cost=30631.65..30631.86 rows=2 width=8) (actual time=207.510..211.062 rows=3 loops=1)Workers Planned: 2Workers Launched: 2-> Partial Aggregate (cost=29631.65..29631.66 rows=1 width=8) (actual time=203.739..203.739 rows=1 loops=3)-> Parallel Seq Scan on account (cost=0.00..28278.83 rows=541125 width=0) (actual time=0.024..163.444 rows=400000 loops=3)Filter: (NOT (content ? 'avatar'::text))Rows Removed by Filter: 33333Planning Time: 0.068 msExecution Time: 211.097 ms
该索引也不能被用于下面这样的查询,因为尽管操作符? 是可索引的,但它不能直接被应用于被索引列content:
explain analyze select count(1) from account where content -> 'tags' ? 'c';QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------Finalize Aggregate (cost=30634.57..30634.58 rows=1 width=8) (actual time=184.864..184.864 rows=1 loops=1)-> Gather (cost=30634.35..30634.56 rows=2 width=8) (actual time=184.754..189.652 rows=3 loops=1)Workers Planned: 2Workers Launched: 2-> Partial Aggregate (cost=29634.35..29634.36 rows=1 width=8) (actual time=180.755..180.755 rows=1 loops=3)-> Parallel Seq Scan on account (cost=0.00..29633.00 rows=542 width=0) (actual time=0.022..177.051 rows=33333 loops=3)Filter: ((content -> 'tags'::text) ? 'c'::text)Rows Removed by Filter: 400000Planning Time: 0.074 msExecution Time: 189.716 ms
创建路径索引
-- 创建路径索引
create index ix_account_content_tags on account USING GIN ((content->'tags'));
-- 测试查询性能
explain analyze select count(1) from account where content -> 'tags' ? 'c';QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------Aggregate (cost=4631.74..4631.75 rows=1 width=8) (actual time=49.274..49.275 rows=1 loops=1)-> Bitmap Heap Scan on account (cost=478.07..4628.49 rows=1300 width=0) (actual time=8.655..42.074 rows=100000 loops=1)Recheck Cond: ((content -> 'tags'::text) ? 'c'::text)Heap Blocks: exact=2032-> Bitmap Index Scan on ix_account_content_tags (cost=0.00..477.75 rows=1300 width=0) (actual time=8.417..8.417 rows=100000 loops=1)Index Cond: ((content -> 'tags'::text) ? 'c'::text)Planning Time: 0.216 msExecution Time: 49.309 ms
现在,WHERE 子句content -> 'tags' ? 'c' 将被识别为可索引操作符?在索引表达式content -> 'tags' 上的应用.
也可以利用包含查询的方式,例如:
-- 查寻 "tags" 包含数组元素 "c" 的数据的个数
select count(1) from account where content @> '{"tags": ["c"]}';
content 列上的简单 GIN 索引(默认索引)就能支持索引查询。 但是索引将会存储content列中每一个键 和值的拷贝,表达式索引只存储tags 键下找到的数据。
虽然简单索引的方法更加灵活(因为它支持有关任意键的查询),但定向的表达式索引更小并且搜索速度比简单索引更快。 尽管jsonb_path_ops操作符类只支持用 @>操作符的查询,但它比起默认的操作符类 jsonb_ops有更客观的性能优势。一个 jsonb_path_ops索引通常也比一个相同数据上的 jsonb_ops要小得多,并且搜索的专一性更好,特 别是当查询包含频繁出现在该数据中的键时。因此,其上的搜索操作 通常比使用默认操作符类的搜索表现更好。
总结
- PG 有两种 JSON 数据类型:json 和 jsonb,jsonb 性能优于json,且jsonb 支持索引。
- jsonb 写入时会处理写入数据,写入相对较慢,json会保留原始数据(包括无用的空格)
- jsonb 查询优化时一个好的方式是添加GIN 索引
- 简单索引和路径索引相比更灵活,但是占用空间多
- 路径索引比简单索引更高效,占用空间更小
- 遇到sql转译问题时, 用 ?来转译?. 这样避免无法使用sql在mybatis代码中直接执行搜索
参考文章
参考链接:https://blog.csdn.net/czongxiao/article/details/100013178
这篇关于PostgreSQL json /jsonb类型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





