本文主要是介绍【Linux】自旋锁 以及 读者写者问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
自旋锁 以及 读者写者问题
- 一、自旋锁
- 1、其他常见的各种锁
- 2、自旋锁相关的API函数
- 二、读者写者问题
- 1、读者与写者的关系
- 2、读写锁的API函数
- 3、用伪代码理解读写锁的原理
- 4、读写锁的演示使用
一、自旋锁
1、其他常见的各种锁
-
悲观锁:在每次取数据时,总是担心数据会被其他线程修改,所以会在取数据前先加锁(读锁,写锁,行锁等),当其他线程想要访问数据时,被阻塞挂起。
-
乐观锁:每次取数据时候,总是乐观的认为数据不会被其他线程修改,因此不上锁。但是在更新数据前,会判断当前数据在更新前有没有被修改过。主要采用两种方式:版本号机制和CAS操作。
CAS操作:当需要更新数据时,判断当前内存值和之前取得的值是否相等。如果相等则用新值更新。若不相等则失败,失败则重试,一般是一个自旋的过程,即不断重试。
介绍
-
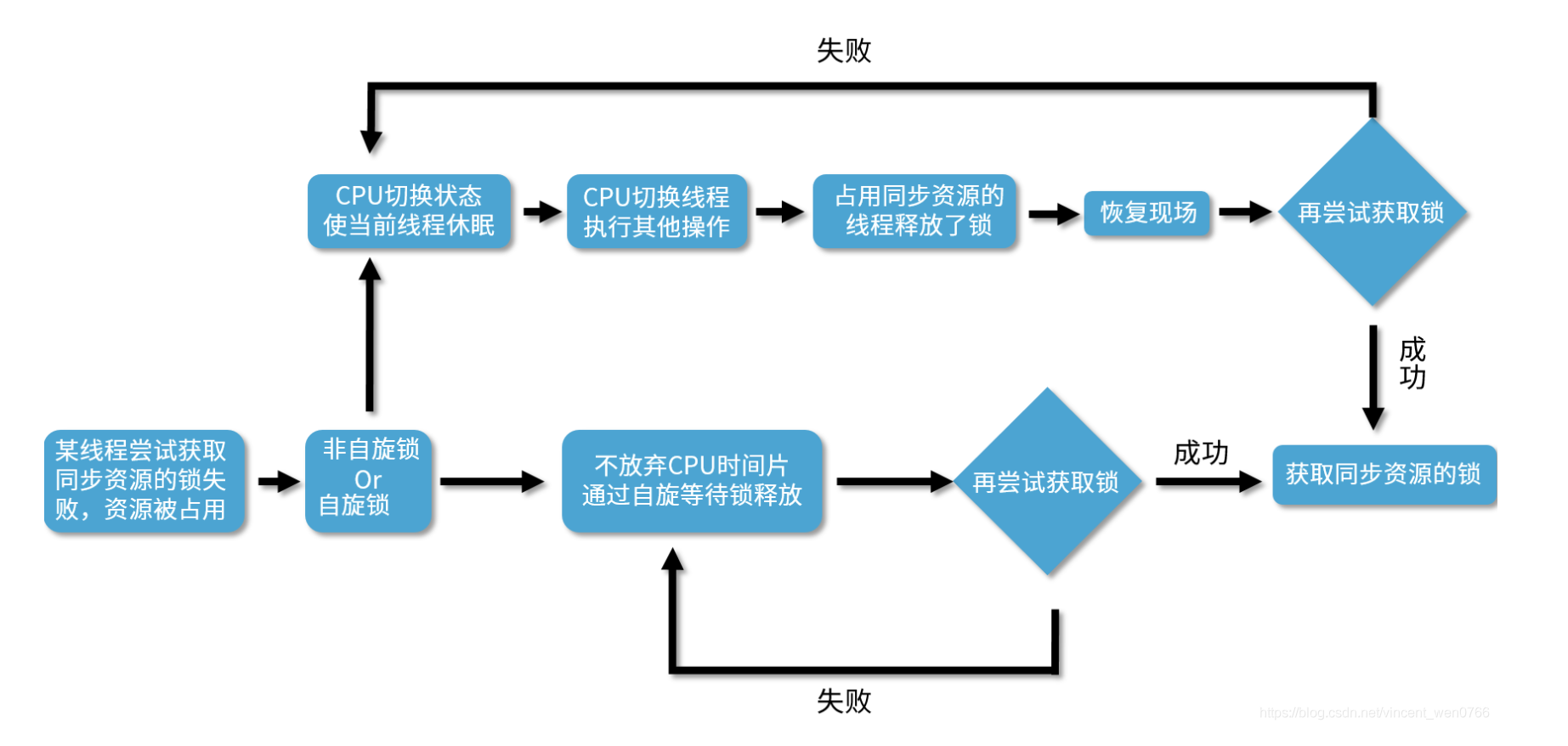
自旋锁与互斥锁比较类似,自旋锁也是为实现保护共享资源而提出一种锁机制。
-
两者在调度机制上略有不同。对于互斥锁,如果资源已经被占用,资源申请者只能进入睡眠状态。但是自旋锁不会引起调用者睡眠,如果自旋锁已经被别的执行单元占用,线程就会一直循环尝试去申请锁。
自旋锁使用场景
- 自旋锁比较适用于锁的使用者在临界区待的时间比较短的情况。
由于自旋锁申请失败不会被挂起,而且在比较短的时间内能够申请到锁,线程一直循环尝试去申请锁的消耗不大,同时也避免了线程调度的开销。
自旋锁的重要的特性
- 被自旋锁保护的临界区代码执行时不能进入休眠。
- 被自旋锁保护的临界区代码执行时是不能被被其他中断中断。
- 被自旋锁保护的临界区代码执行时,内核不能被抢占。
- 在自旋锁忙等期间,因为并没有进入临界区,所以内核抢占还是有效的,因此,等待自旋锁释放的进程有可能被更高优先级的所取代
- 自旋锁存在两个问题:死锁和过多占用cpu资源。
从这几个特性可以归纳出一个共性:被自旋锁保护的临界区代码执行时,它不能因为任何原因放弃处理器。
2、自旋锁相关的API函数
使用自旋锁,必须包含头文件,并链接库-lpthread
#include <pthread.h>
初始化函数
int pthread_spin_init(pthread_spinlock_t *lock, int pshared);
-
功能:初始化自旋锁, 当线程使用该函数初始化一个未初始化或者被destroy过的自旋锁。该函数会为自旋锁申请资源并且初始化自旋锁为unlocked状态。
-
参数 :
pthread_spinlock_t:要初始化自旋锁
pshared取值:- PTHREAD_PROCESS_SHARED:该自旋锁可以在多个进程中的线程之间共享。(可以被其他进程中的线程看到)
- PTHREAD_PROCESS_PRIVATE: 仅初始化本自旋锁的线程所在的进程内的线程才能够使用该自旋锁。
-
返回值
若成功,返回0;否则,返回错误编号
销毁
int pthread_spin_destroy(pthread_spinlock_t *lock);
-
功能:用来销毁指定的自旋锁并释放所有相关联的资源(所谓的资源指的是由
pthread_spin_init自动申请的资源),如果调用该函数时自旋锁正在被使用或者自旋锁未被初始化则结果是未定义的。 -
参数 :
pthread_spinlock_t:要销毁的自旋锁 -
返回值
若成功,返回0;否则,返回错误编号
加锁
int pthread_spin_lock(pthread_spinlock_t *lock);
-
功能:用来获取(锁定)指定的自旋锁. 如果该自旋锁当前没有被其它线程所持有,则调用该函数的线程获得该自旋锁,否则该函数在获得自旋锁之前不会返回。
-
参数 :
pthread_spinlock_t:要加锁的自旋锁 -
返回值
若成功,返回0;否则,返回错误编号
解锁
int pthread_spin_unlock(pthread_spinlock_t *lock);
-
功能:用来解锁指定的自旋锁.。
-
参数 :
pthread_spinlock_t:要加锁的自旋锁 -
返回值
若成功,返回0;否则,返回错误编号
二、读者写者问题
在编写多线程的时候,有一种情况是十分常见的。那就是,有些公共数据修改的机会比较少。相比较改写,它们读的机会反而高的多。通常而言,在读的过程中,往往伴随着查找的操作,中间耗时很长。如果给这种代码段加锁,会极大地降低我们程序的效率。
那么有没有一种方法,可以专门处理这种多读少写的情况呢? 有,那就是读写锁。
1、读者与写者的关系
为了解决我们的问题我们先来分析多线程中两个角色的关系:读者,写者。
- 写者与写者:显然写者与写者之间的关系是互斥的,多个写者之间要用锁来进行保证线程安全。
- 读者与读者:读者与读者都只是访问数据,而不会修改数据,所以多个读者访问数据没有线程安全,读者之间毫无关系。
- 读者与写者:当读者与写者同时访问数据时,明显有线程安全的问题,只有读者读取完了再让写者写,或者写者写完了再让读者读取才是合理的。所以读者与写者之间存在互斥且同步的关系。
2、读写锁的API函数
使用自旋锁,必须包含头文件,并链接库-lpthread
#include <pthread.h>
初始化/销毁函数
int pthread_rwlock_init(pthread_rwlock_t *restrict rwlock, const pthread_rwlockattr_t *restrict attr);int pthread_rwlock_destroy(pthread_rwlock_t *rwlock);
-
功能:初始化/销毁一个读写锁。
-
参数:
pthread_rwlock_t: 读写锁的数据结构;pthread_rwlockattr_t: 读写锁属性的数据结构,一般直接设置为空。
-
返回值
若成功,返回0;否则,返回错误编号
读者加锁
int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock);
当读者要访问数据时要申请先读者锁,拿到读者锁以后才能访问资源。
- 返回值
若成功,返回0;否则,返回错误编号
写者加锁
int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock);
当写者要访问数据时要申请先写者锁,拿到写者锁以后才能访问资源。
- 返回值
若成功,返回0;否则,返回错误编号
解锁
int pthread_rwlock_unlock(pthread_rwlock_t *rwlock);
无论是读者解锁还是写者解锁都要使用此函数。
- 返回值
若成功,返回0;否则,返回错误编号
3、用伪代码理解读写锁的原理
我们想要使用正确的使用读写锁就还要简单理解一下读写锁的原理,而读写锁就是要维护好上面的读者与写者的关系。
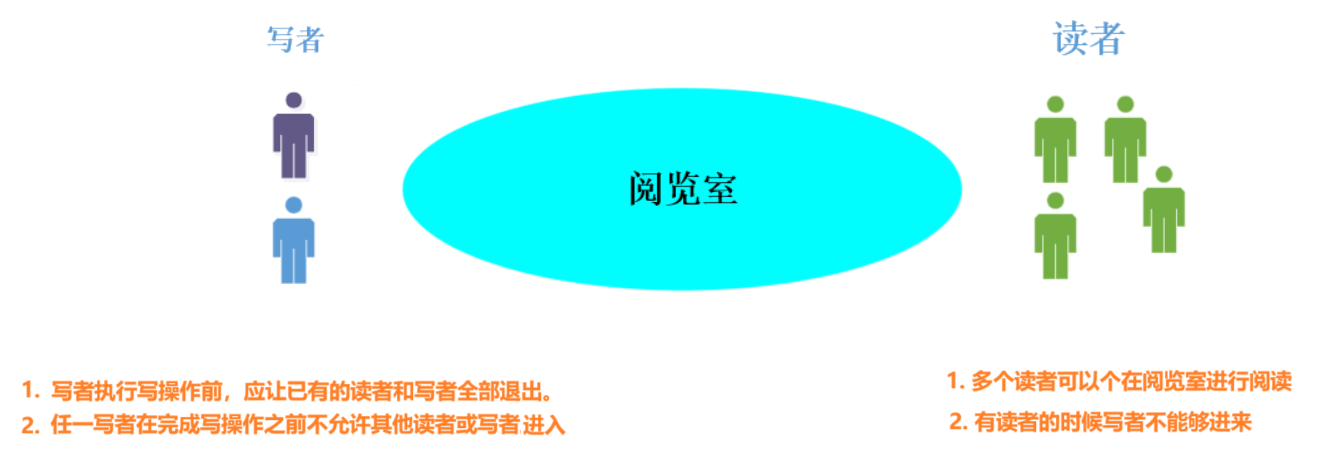
下面是一段伪代码,我们可以用此来理解读写锁的原理。

下面的读者的逻辑:

下面的写者的逻辑:

简单分析:
- 当读者先加锁,则读者拿到阅览室(临界区)的使用权,不影响后来其他读者,只会拦截写者,直到读者解锁。
- 当写者先加锁,后来的写者与读者都不能够进入,直到写者解锁。
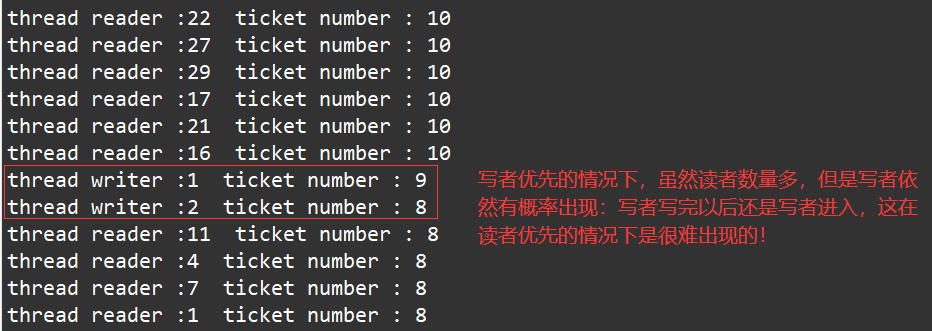
- 实际中由于读者众多,可能会有读者络绎不绝的进入阅览室(临界区),从而导致写者迟迟无法获得阅览室(临界区)的使用权,进而导致写者饥饿问题(又叫读者优先策略)

注意:写独占,读共享,读锁优先级高
- 写者优先策略的实现方式:当写者加锁没有成功,在写者后面来的读者全部都不能够进入阅览室(临界区),等阅览室已经存在的读者全部离开以后,写者先进入阅览室(临界区)进行修改,然后才能让写者后面来的读者进入阅览室(临界区)。
pthread库里面给我们提供了一个函数可以设置读写优先级,使用man查不到这个函数,但是可以在pthread.h头文件中发现,如果我们不设置默认是读者优先。
int pthread_rwlockattr_setkind_np(pthread_rwlockattr_t *attr, int pref);
/*
pref 共有 3 种选择
PTHREAD_RWLOCK_PREFER_READER_NP (默认设置) 读者优先,可能会导致写者饥饿情况PTHREAD_RWLOCK_PREFER_WRITER_NP 写者优先,目前有 BUG,导致表现行为
和PTHREAD_RWLOCK_PREFER_READER_NP 一致PTHREAD_RWLOCK_PREFER_WRITER_NONRECURSIVE_NP 写者优先,但写者不能递归加锁
*/
4、读写锁的演示使用
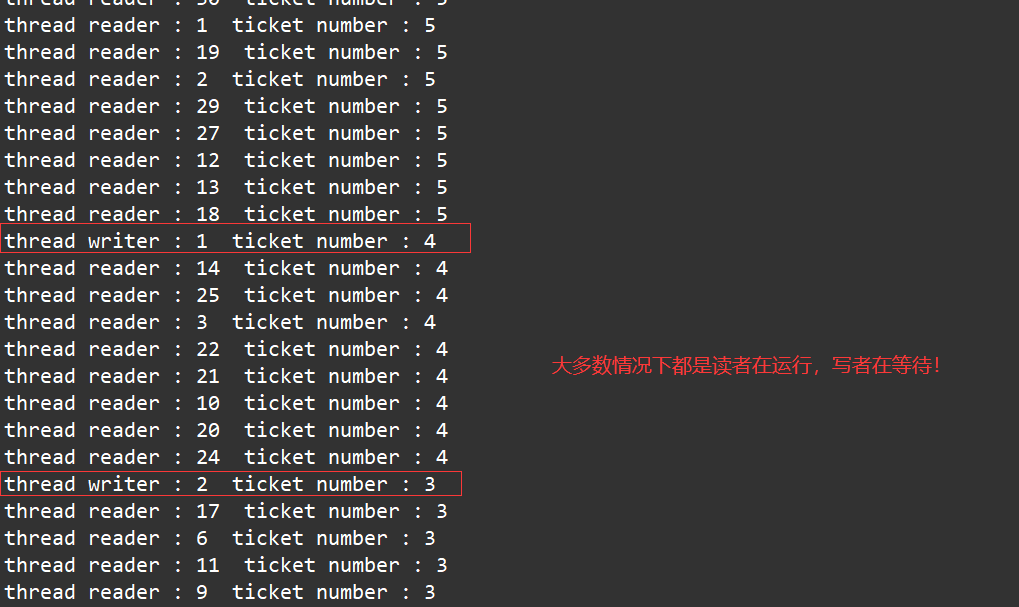
下面的代码,我们让设置了票数等于100,读者负责查询票数,写者负责减少票数,直到票数为0, 读者与写者都退出。
由于读者优先,这个实验的效果可能不明显,这里我们设置读者为30个,写者为2个。
#include <iostream>
#include <sstream>
#include <string>
#include <vector>
#include <pthread.h>
#include <unistd.h>using namespace std;// 线程的属性
struct ThreadAttr
{pthread_t _tid;string _name;
};// 票数
volatile int ticket = 100;
// 读写锁
pthread_rwlock_t rwlock;函数相关的逻辑:
// 读写锁属性初始化
void rwattr_init(pthread_rwlockattr_t* pattr, int flag)
{pthread_rwlockattr_init(pattr);// flag为0表示读者优先,其他表示写着优先if (flag == 0){pthread_rwlockattr_setkind_np(pattr, PTHREAD_RWLOCK_PREFER_READER_NP);}else{pthread_rwlockattr_setkind_np(pattr, PTHREAD_RWLOCK_PREFER_WRITER_NONRECURSIVE_NP);}
}// 读写锁属性的销毁
void rwattr_destroy(pthread_rwlockattr_t* prwlock)
{pthread_rwlockattr_destroy(prwlock);
}// 锁的初始化
void rwlock_init(pthread_rwlock_t* prwlock, int flag = 0)
{pthread_rwlockattr_t rwattr;rwattr_init(&rwattr, flag);pthread_rwlock_init(prwlock, &rwattr);rwattr_destroy(&rwattr);
}// 创建name
const string create_writer_name(size_t i)
{stringstream ssm("thread writer : ", ios::in | ios::out | ios::ate);ssm << i;return ssm.str();
}const string create_reader_name(size_t i)
{stringstream ssm("thread reader : ", ios::in | ios::out | ios::ate);ssm << i;return ssm.str();
}// 读者历程
void* readerRoutine(void* args)
{string* ps = static_cast<string*>(args);// 进行查票while (true){pthread_rwlock_rdlock(&rwlock);if (ticket != 0){cout << *ps << " ticket number : " << ticket << endl;}else{cout << *ps << " done!!!!!" << endl;// 防止死锁pthread_rwlock_unlock(&rwlock);break;}pthread_rwlock_unlock(&rwlock);// 休眠0.1msusleep(100);}
}// 写者历程
void* writerRoutine(void* args)
{string* ps = static_cast<string*>(args);// 进行改票while (true){pthread_rwlock_wrlock(&rwlock);if (ticket != 0){cout << *ps << " ticket number : " << --ticket << endl;}else{cout << *ps << " done!!!!!" << endl;// 防止死锁pthread_rwlock_unlock(&rwlock);break;}pthread_rwlock_unlock(&rwlock);// 休眠0.1msusleep(100);}
}void reader_init(vector<ThreadAttr>& readers)
{int i = 1;for (auto& e : readers){e._name = create_reader_name(i++);pthread_create(&e._tid, nullptr, readerRoutine, &e._name);}
}void writer_init(vector<ThreadAttr>& writers)
{int i = 1;for (auto& e : writers){e._name = create_writer_name(i++);pthread_create(&e._tid, nullptr, writerRoutine, &e._name);}
}void reader_join(const vector<ThreadAttr>& readers)
{for (auto& e : readers){pthread_join(e._tid, nullptr);}
}void writer_join(const vector<ThreadAttr>& writers)
{for (auto& e : writers){pthread_join(e._tid, nullptr);}
}
主函数逻辑:
int main()
{// 初始化锁,并设置读写者优先属性rwlock_init(&rwlock, 0);const int reader_count = 30;const int writer_count = 2;vector<ThreadAttr> readers(reader_count);vector<ThreadAttr> writers(writer_count);reader_init(readers);writer_init(writers);reader_join(readers);writer_join(writers);return 0;
}
在读者优先的情况下运行:
在写者优先的情况下运行:
这篇关于【Linux】自旋锁 以及 读者写者问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







