本文主要是介绍python:xlrd、xlwt和xlutils操纵excel表格,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【转自】:https://blog.csdn.net/u013250071/article/details/81911434
一、需要用到的库
1.操作xls格式的表格文件:
读取:xlrd
写入:xlwt
修改(追加写入):xlutils
2.操作xlsx格式的表格文件:
读取/写入:openpyxl
二、实现代码
1.操作xls格式的表格文件
# coding=UTF-8
import xlrd
import xlwt
from xlutils.copy import copydef write_excel_xls(path, sheet_name, value):index = len(value) # 获取需要写入数据的行数workbook = xlwt.Workbook() # 新建一个工作簿sheet = workbook.add_sheet(sheet_name) # 在工作簿中新建一个表格for i in range(0, index):for j in range(0, len(value[i])):sheet.write(i, j, value[i][j]) # 像表格中写入数据(对应的行和列)workbook.save(path) # 保存工作簿print("xls格式表格写入数据成功!")def write_excel_xls_append(path, value):index = len(value) # 获取需要写入数据的行数workbook = xlrd.open_workbook(path) # 打开工作簿sheets = workbook.sheet_names() # 获取工作簿中的所有表格worksheet = workbook.sheet_by_name(sheets[0]) # 获取工作簿中所有表格中的的第一个表格rows_old = worksheet.nrows # 获取表格中已存在的数据的行数new_workbook = copy(workbook) # 将xlrd对象拷贝转化为xlwt对象new_worksheet = new_workbook.get_sheet(0) # 获取转化后工作簿中的第一个表格for i in range(0, index):for j in range(0, len(value[i])):new_worksheet.write(i+rows_old, j, value[i][j]) # 追加写入数据,注意是从i+rows_old行开始写入new_workbook.save(path) # 保存工作簿print("xls格式表格【追加】写入数据成功!")def read_excel_xls(path):workbook = xlrd.open_workbook(path) # 打开工作簿sheets = workbook.sheet_names() # 获取工作簿中的所有表格worksheet = workbook.sheet_by_name(sheets[0]) # 获取工作簿中所有表格中的的第一个表格for i in range(0, worksheet.nrows):for j in range(0, worksheet.ncols):print(worksheet.cell_value(i, j), "\t", end="") # 逐行逐列读取数据print()book_name_xls = 'xls格式测试工作簿.xls'sheet_name_xls = 'xls格式测试表'value_title = [["姓名", "性别", "年龄", "城市", "职业"],]value1 = [["张三", "男", "19", "杭州", "研发工程师"],["李四", "男", "22", "北京", "医生"],["王五", "女", "33", "珠海", "出租车司机"],]value2 = [["Tom", "男", "21", "西安", "测试工程师"],["Jones", "女", "34", "上海", "产品经理"],["Cat", "女", "56", "上海", "教师"],]write_excel_xls(book_name_xls, sheet_name_xls, value_title)
write_excel_xls_append(book_name_xls, value1)
write_excel_xls_append(book_name_xls, value2)
read_excel_xls(book_name_xls)
2.操作xlsx格式的表格文件
# coding=UTF-8
import openpyxldef write_excel_xlsx(path, sheet_name, value):index = len(value)workbook = openpyxl.Workbook()sheet = workbook.activesheet.title = sheet_namefor i in range(0, index):for j in range(0, len(value[i])):sheet.cell(row=i+1, column=j+1, value=str(value[i][j]))workbook.save(path)print("xlsx格式表格写入数据成功!")def read_excel_xlsx(path, sheet_name):workbook = openpyxl.load_workbook(path)# sheet = wb.get_sheet_by_name(sheet_name)这种方式已经弃用,不建议使用sheet = workbook[sheet_name]for row in sheet.rows:for cell in row:print(cell.value, "\t", end="")print()book_name_xlsx = 'xlsx格式测试工作簿.xlsx'sheet_name_xlsx = 'xlsx格式测试表'value3 = [["姓名", "性别", "年龄", "城市", "职业"],["111", "女", "66", "石家庄", "运维工程师"],["222", "男", "55", "南京", "饭店老板"],["333", "女", "27", "苏州", "保安"],]write_excel_xlsx(book_name_xlsx, sheet_name_xlsx, value3)
read_excel_xlsx(book_name_xlsx, sheet_name_xlsx)
三、运行结果
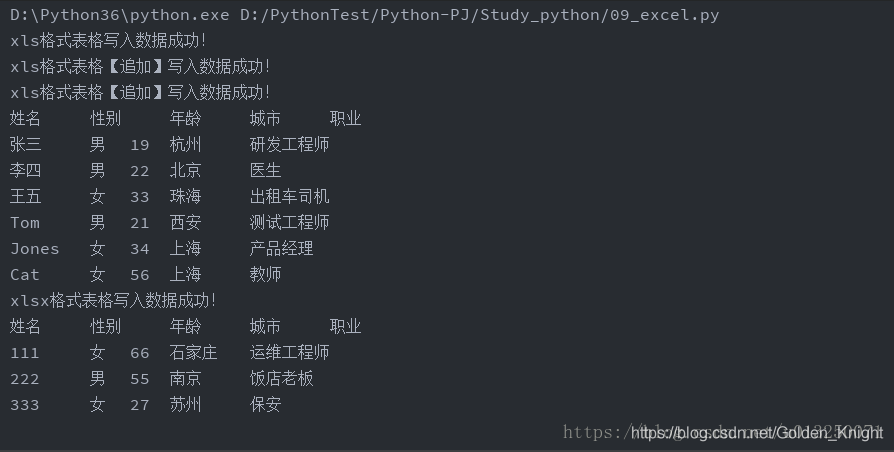
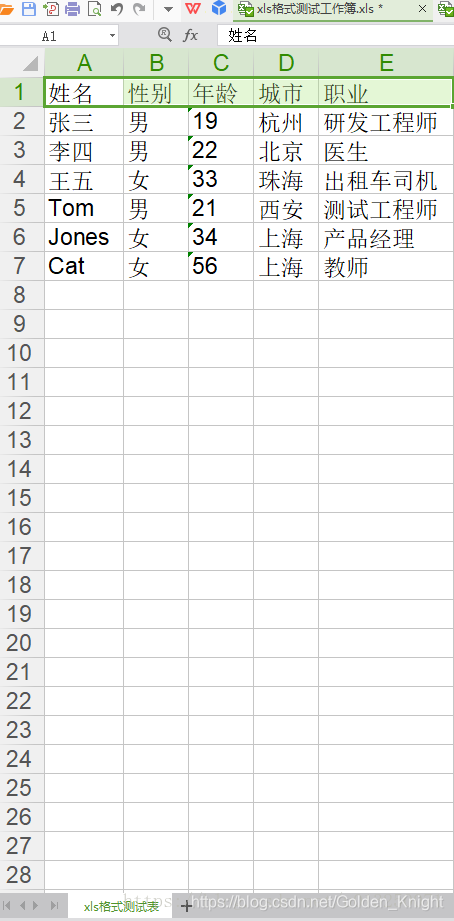
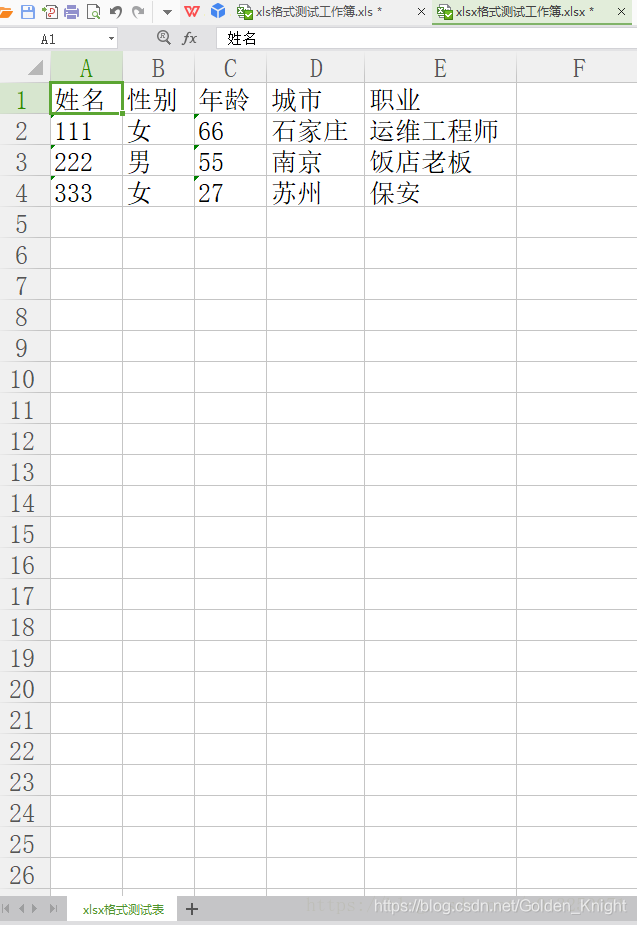
这篇关于python:xlrd、xlwt和xlutils操纵excel表格的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





