本文主要是介绍SQLZOO及经典面试50题刷题记录,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- SQLZOO
- SELECT names
- 1.顯示所有國家名字,其首都和國家名字是相同的。
- 2.“Mexico 墨西哥”的首都是”Mexico City”。
- 3.找出所有首都和其國家名字,而首都要有國家名字中出現
- 4.找出所有首都和其國家名字,而首都是國家名字的延伸。
- 5.“Monaco-Ville"是合併國家名字 “Monaco” 和延伸詞”-Ville". 顯示國家名字,及其延伸詞,如首都是國家名字的延伸。
- SELECT from WORLD Tutorial
- 1.顯示以人口或面積為大國的國家,但不能同時兩者。顯示國家名稱,人口和面積。
- 2.round
- 3.Show the name - but substitute Australasia for Oceania - for countries beginning with N.
- 4.Show the name and the continent - but substitute Eurasia for Europe and Asia; substitute America - for each country in North America or South America or Caribbean. Show countries beginning with A or B
- SELECT from Nobel Tutorial
- 1.Show the 1984 winners and subject ordered by subject and winner name; but list Chemistry and Physics last.
- Nobel Quiz
- 1.顯示有多少年沒有頒發醫學獎。
- 2.選擇代碼以顯示哪一年沒有頒發物理獎,亦沒有頒發化學獎。
- SELECT within SELECT Tutorial
- 1.在每一個州中找出最大面積的國家,列出洲份 continent, 國家名字 name 及面積 area。 (有些國家的記錄中,AREA是NULL,沒有填入資料的。)
- 2.列出洲份名稱,和每個洲份中國家名字按子母順序是排首位的國家名。(即每洲只有列一國)
- 2.找出洲份,當中全部國家都有少於或等於 25000000 人口. 在這些洲份中,列出國家名字name,continent 洲份和population人口。
- 3.有些國家的人口是同洲份的所有其他國的3倍或以上。列出 國家名字name 和 洲份 continent。
- SUM and COUNT
- 1.對於每一個洲份,顯示洲份和至少有1000萬人(10,000,000)口國家的數目。
- 2.列出有至少100百萬(1億)(100,000,000)人口的洲份。
- The nobel table can be used to practice more SUM and COUNT functions.
- 1.對每一個獎項(Subject),列出有多少年曾頒發過。
- 2.列出哪年曾同年有3個物理獎Physics得獎者。
- 3.哪年哪獎項,是同一獎項(subject)頒發給3個人。只列出2000年及之後的資料。
- JOIN
- 1.List every match with the goals scored by each team as shown. This will use "CASE WHEN" which has not been explained in any previous exercises.
- 2.Notice in the query given every goal is listed. If it was a team1 goal then a 1 appears in score1, otherwise there is a 0. You could SUM this column to get a count of the goals scored by team1. Sort your result by mdate, matchid, team1 and team2.
- More JOIN operations
- 1.列出1962年首影的電影及它的第1主角。
- 2.尊·特拉華達'John Travolta'最忙是哪一年? 顯示年份和該年的電影數目。
- 3.列出演員茱莉·安德絲'Julie Andrews'曾參與的電影名稱及其第1主角。
- 4.列出曾與演員亞特·葛芬柯'Art Garfunkel'合作過的演員姓名。
- SQL面试50题
- 1.查询没有学全所有课的学生的学号、姓名
- ★2.查询各科排名前二的记录
- ★3.查询各学生的年龄
- 4.查询所有学生的学号、姓名、选课数、总成绩
- ★5.查询出每门课程的及格人数和不及格人数
- ★6.使用分段[100-85],[85-70],[70-60],[<60]来统计各科成绩,分别统计:各分数段人数,课程号和课程名称
- ★7.行列互换
- 8.查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
- 9.查询学过编号为“0001”的课程并且也学过编号为“0002”的课程的学生的学号、姓名
- ★10.按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
- ★11.查询学生平均成绩及其名次
- ★12.按每门课成绩排名
- ★13.查询每门功成绩最好的前三名学生姓名
- 13.找出语文课中成绩第二高的学生成绩。如果不存在第二高成绩的学生,那么查询应返回 null。
- ★14.查询各学生成绩涨幅
- ★15.行行交换
- ★16.统计每个班每个同学成绩平均分大于80分的人数和人数占比
- ★17.计算新增用户、留存及留存率
- 18.查找前20%的数据
- ★19.正则表达式
- ★20.删除重复的行并保留第一次出现的行
- ★21.行转列
- ★22.查询消费的金额都大于100的用户
SQLZOO
SELECT names
1.顯示所有國家名字,其首都和國家名字是相同的。
SELECT`name`
FROMworld
WHEREname = capital
2.“Mexico 墨西哥”的首都是”Mexico City”。
顯示所有國家名字,其首都是國家名字加上”City”。
SELECT`name`
FROMworld
WHEREcapital = concat(`name`,' City' )
3.找出所有首都和其國家名字,而首都要有國家名字中出現
SELECTcapital,`name`
FROMworld
WHEREcapital LIKE concat('%',`name`,'%' )
4.找出所有首都和其國家名字,而首都是國家名字的延伸。
你應顯示 Mexico City,因它比其國家名字 Mexico 長,你不應顯示 Luxembourg,因它的首都和國家名相是相同的。
SELECT`name`,capital
FROMworld
WHEREcapital LIKE concat( `name`, '%' ) AND (capital != `name`)
或
SELECT`name`,capital
FROMworld
WHEREcapital LIKE concat( `name`,'_%')
5.“Monaco-Ville"是合併國家名字 “Monaco” 和延伸詞”-Ville". 顯示國家名字,及其延伸詞,如首都是國家名字的延伸。
你可以使用SQL函數 REPLACE 或 MID.
SELECT`name`,REPLACE ( capital, `name`, '' ) AS ext
FROMworld
WHEREcapital LIKE concat( `name`, '%' ) AND (capital != `name`)
SELECT from WORLD Tutorial
1.顯示以人口或面積為大國的國家,但不能同時兩者。顯示國家名稱,人口和面積。
SELECT name, population, area FROM world
WHERE (area > 3000000 AND population < 250000000) OR(area < 3000000 AND population > 250000000)
2.round
ROUND(7253.86, 0) -> 7254
ROUND(7253.86, 1) -> 7253.9
ROUND(7253.86,-3) -> 7000
3.Show the name - but substitute Australasia for Oceania - for countries beginning with N.
SELECT name,CASE WHEN continent='Oceania' THEN 'Australasia'ELSE continent END
FROM world
WHERE name LIKE 'N%'
4.Show the name and the continent - but substitute Eurasia for Europe and Asia; substitute America - for each country in North America or South America or Caribbean. Show countries beginning with A or B
SELECT name,CASE WHEN continent='Asia' THEN 'Eurasia'WHEN continent='Europe' THEN 'Eurasia'WHEN continent = 'North America' THEN 'America'WHEN continent = 'South America' THEN 'America'WHEN continent = 'Caribbean' THEN 'America'ELSE continentEND
FROM world
WHERE name LIKE 'A%' OR name LIKE 'B%'
SELECT from Nobel Tutorial
1.Show the 1984 winners and subject ordered by subject and winner name; but list Chemistry and Physics last.
显示1984年获奖者和主题(按主题和获奖者名称排序); 但最后化学和物理排在最后。
The expression subject IN (‘Chemistry’,‘Physics’) can be used as a value - it will be 0 or 1.
SELECT winner, subject
FROM nobel
WHERE yr=1984
ORDER BY subject IN ('Physics','Chemistry'),subject,winner
Nobel Quiz
1.顯示有多少年沒有頒發醫學獎。
SELECT COUNT(DISTINCT yr)
FROM nobel
WHERE yr
NOT IN (SELECT DISTINCT yr FROM nobel WHERE subject = 'Medicine')
2.選擇代碼以顯示哪一年沒有頒發物理獎,亦沒有頒發化學獎。
SELECT yr FROM nobel
WHERE yr
NOT IN(SELECT yr FROM nobelWHERE subject IN ('Chemistry','Physics'))
SELECT within SELECT Tutorial
1.在每一個州中找出最大面積的國家,列出洲份 continent, 國家名字 name 及面積 area。 (有些國家的記錄中,AREA是NULL,沒有填入資料的。)
SELECT continent, name, area FROM world xWHERE area >= ALL(SELECT area FROM world yWHERE y.continent=x.continentAND area>0)
2.列出洲份名稱,和每個洲份中國家名字按子母順序是排首位的國家名。(即每洲只有列一國)
SELECT continent,name
FROM world AS x
WHERE x.name=(SELECT y.name FROM world AS y WHERE y.continent=x.continent ORDER BY name limit 1)
Tips:limit用法
select * from Customer LIMIT 10:检索前10行数据,显示1-10条数据
select * from Customer LIMIT 1,10:检索从第2行开始,累加10条id记录,共显示id为2....11
select * from Customer LIMIT 5,10:检索从第6行开始向前加10条数据,共显示id为6,7....15
select * from Customer LIMIT 6,10:检索从第7行开始向前加10条记录,显示id为7,8...16
有 ORDER BY 时 limit 必须在其之后
2.找出洲份,當中全部國家都有少於或等於 25000000 人口. 在這些洲份中,列出國家名字name,continent 洲份和population人口。
SELECT name,continent,population
FROM world as x
WHERE 25000000 >=ALL(SELECT population FROM world AS y WHERE x.continent = y.continent)
#将250000000放到后不行
3.有些國家的人口是同洲份的所有其他國的3倍或以上。列出 國家名字name 和 洲份 continent。
SELECT name, continent FROM world xWHERE x.population > ALL(SELECT 3*population FROM world y WHERE x.continent = y.continent AND population > 0 AND x.name != y.name);SUM and COUNT
1.對於每一個洲份,顯示洲份和至少有1000萬人(10,000,000)口國家的數目。
SELECT continent,COUNT(name)
FROM world
WHERE population >=10000000
GROUP BY continent
2.列出有至少100百萬(1億)(100,000,000)人口的洲份。
SELECT continent
FROM world
GROUP BY continent
HAVING SUM(population) >= 100000000
The HAVING clause allows use to filter the groups which are displayed.
The WHERE clause filters rows before the aggregation, the HAVING
clause filters after the aggregation. 总结来说就是WHERE用在GROUP BY之前,HAVING用在GROUP BY之后。HAVING后面的条件必须是SUM、COUNT之类的聚合条件。
The nobel table can be used to practice more SUM and COUNT functions.
1.對每一個獎項(Subject),列出有多少年曾頒發過。
SELECT subject,COUNT(DISTINCT(yr))
FROM nobel
GROUP BY subject
2.列出哪年曾同年有3個物理獎Physics得獎者。
SELECT yr
FROM nobel
WHERE subject = 'Physics'
GROUP BY yr
HAVING COUNT(subject)=3
3.哪年哪獎項,是同一獎項(subject)頒發給3個人。只列出2000年及之後的資料。
SELECT yr,subject
FROM nobel
WHERE yr >= 2000
GROUP BY yr,subject
HAVING COUNT(winner) = 3
JOIN
1.List every match with the goals scored by each team as shown. This will use “CASE WHEN” which has not been explained in any previous exercises.

2.Notice in the query given every goal is listed. If it was a team1 goal then a 1 appears in score1, otherwise there is a 0. You could SUM this column to get a count of the goals scored by team1. Sort your result by mdate, matchid, team1 and team2.
SELECT game.mdate,team1,
sum(CASE WHEN teamid = team1 THEN 1 ELSE 0 END) AS score1,team2,
sum(CASE WHEN teamid = team2 THEN 1 ELSE 0 END) AS score2
FROM game LEFT JOIN goal ON(game.id = matchid)
GROUP BY mdate, matchid, team1, team2
之所以用做连接是因为goal表记录的是进球的记录,因此如果双方都没有进球,那么则不会记录,所以需要左连接game来显示所有的比赛记录而不仅仅是进球记录.
More JOIN operations
1.列出1962年首影的電影及它的第1主角。
SELECT m.title, a.name
FROM casting c
JOIN movie m ON (m.id= c.movieid)
JOIN actor a ON (a.id= c.actorid)
WHERE c.ord = 1 AND yr = 1962
2.尊·特拉華達’John Travolta’最忙是哪一年? 顯示年份和該年的電影數目。
SELECT yr, COUNT(title)
FROM movie
JOIN casting ON movie.id=movieid
JOIN actor ON actorid=actor.id
WHERE name='John Travolta'
GROUP BY yr HAVING COUNT(title)=(SELECT MAX(c) FROM (SELECT yr,COUNT(title) AS c FROM movie JOIN casting ON movie.id=movieidJOIN actor ON actorid=actor.idWHERE name='John Travolta'GROUP BY yr) AS t)SELECT yr, COUNT(title)
FROM casting c
JOIN movie m ON (m.id= c.movieid)
JOIN actor a ON (a.id= c.actorid)
WHERE name = 'John Travolta'
GROUP BY yr
ORDER BY COUNT(title) DESC LIMIT 1;3.列出演員茱莉·安德絲’Julie Andrews’曾參與的電影名稱及其第1主角。
是否列了電影 "Little Miss Marker"兩次?
她於1980再參與此電影Little Miss Marker. 原作於1934年,她也有參與。 電影名稱不是獨一的。在子查詢中使用電影編號。
SELECT title, name /* 電影名稱 及 其第1主角*/
FROM casting c
JOIN movie m ON (m.id= c.movieid)
JOIN actor a ON (a.id= c.actorid)
WHERE c.ord = 1 AND c.movieid IN (SELECT movieid /*Julie Andrews 参加过的电影, 需要获取到 movieid */FROM casting c JOIN movie m ON (m.id= c.movieid)JOIN actor a ON (a.id= c.actorid)WHERE name = 'Julie Andrews')4.列出曾與演員亞特·葛芬柯’Art Garfunkel’合作過的演員姓名。
SELECT DISTINCT(name) /* 2. 找到这些电影里的演员且不包含演员AG*/
FROM casting c
JOIN movie m ON (m.id= c.movieid)
JOIN actor a ON (a.id= c.actorid)
WHERE name != 'Art Garfunkel' AND m.id IN ( SELECT movieid /* 1.找到所有 Art Garfunkel 演过的电影*/FROM casting c JOIN movie m ON (m.id= c.movieid)JOIN actor a ON (a.id= c.actorid)WHERE name = 'Art Garfunkel')SQL面试50题
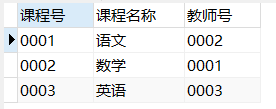
course
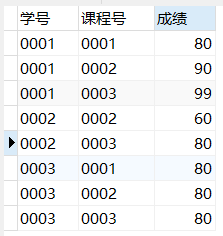
score
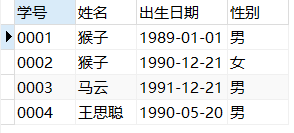
student
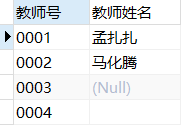
teacher
1.查询没有学全所有课的学生的学号、姓名
SELECT学号,姓名
FROMstudent
WHERE学号 IN (SELECT学号 FROMscore GROUP BY学号
HAVINGCOUNT(课程号) < ( SELECT COUNT(课程号) FROM course ))
★2.查询各科排名前二的记录
SELECT a.课程号,a.成绩,COUNT(DISTINCT(b.成绩))
FROM score a
JOIN score b
ON a.课程号 = b.课程号
AND
a.成绩 <= b.成绩
GROUP BY a.课程号,a.成绩
HAVING COUNT(DISTINCT(b.成绩)) <=2
ORDER BY a.课程号,COUNT(DISTINCT(b.成绩))
思路参考:https://www.jianshu.com/p/fff5d1f71c0f
★3.查询各学生的年龄
SELECT学号,timestampdiff(YEAR,出生日期,now())
FROMstudent
timestampdiff:时间差函数,第一个参数选择单位(年、月、日、分、时、秒),第二个参数传入日期列,第三个函数为当前时间
%k表示显示的是24小时制中的小时
4.查询所有学生的学号、姓名、选课数、总成绩
SELECTst.学号,st.姓名,COUNT( sc.课程号 ),SUM( sc.成绩 )
FROMstudent as stLEFT JOIN score as sc ON sc.学号 = st.学号
GROUP BYst.学号
Note:
- 这里要用左连接,因为题目要求查询所有学生的信息。
- 使用左连接后,分组时必须要用左表的列进行分组,因为可能会有空值

★5.查询出每门课程的及格人数和不及格人数
SELECT课程号,SUM( CASE WHEN 成绩 >= 60 THEN 1 ELSE 0 END ) AS 及格人数,SUM( CASE WHEN 成绩 < 60 THEN 1 ELSE 0 END ) AS 不及格人数
FROMscore
GROUP BY课程号
这类按条件查找问题通常使用CASE WHEN解决,满足条件取1不满足取0,最后用SUM函数求和即可实现计数需求。
★6.使用分段[100-85],[85-70],[70-60],[<60]来统计各科成绩,分别统计:各分数段人数,课程号和课程名称
SELECTc.课程号,c.课程名称,SUM( CASE WHEN s.成绩 BETWEEN 85 AND 100 THEN 1 ELSE 0 END ) AS '[100-85]',SUM( CASE WHEN s.成绩 >= 70 AND s.成绩 < 85 THEN 1 ELSE 0 END ) AS '[85-70]',SUM( CASE WHEN s.成绩 >= 60 AND s.成绩 < 70 THEN 1 ELSE 0 END ) AS '[70-60]',SUM( CASE WHEN s.成绩 < 60 THEN 1 ELSE 0 END ) AS '[<60]'
FROMcourse c
LEFT JOINscore s
ONc.课程号 = s.课程号
GROUP BYc.课程号
★7.行列互换

使用sql实现将该表行转列为下面的表结构

SELECT学号,MAX( CASE 课程号 WHEN '0001' THEN 成绩 ELSE 0 END ) AS '课程号0001',MAX( CASE 课程号 WHEN '0002' THEN 成绩 ELSE 0 END ) AS '课程号0002',MAX( CASE 课程号 WHEN '0003' THEN 成绩 ELSE 0 END ) AS '课程号0003'
FROMscore
GROUP BY学号
思路参考:https://mp.weixin.qq.com/s/6Kll4Q6Xp37i2PiLUh4cMA
8.查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
SELECTst.学号,st.姓名,AVG( sc.成绩 )
FROMstudent stJOIN score sc ON st.学号 = sc.学号
WHEREsc.学号 = ( SELECT 学号 FROM score WHERE 成绩 < 60 GROUP BY 学号 HAVING COUNT(成绩) >= 2 )
GROUP BYsc.学号
9.查询学过编号为“0001”的课程并且也学过编号为“0002”的课程的学生的学号、姓名
方法1:
SELECTst.学号,st.姓名
FROMstudent stJOIN score sc ON st.学号 = sc.学号JOIN course c ON sc.`课程号` = c.课程号
WHEREc.课程号 IN ( 0001, 0002 )
GROUP BYst.学号
HAVINGCOUNT(DISTINCT ( sc.课程号 )) = 2
方法2:
SELECTa.学号,st.姓名
FROM( SELECT 学号,成绩 FROM score WHERE 课程号 = 01 ) AS aINNER JOIN ( SELECT 学号,成绩 FROM score WHERE 课程号 = 02 ) AS b ON a.学号 = b.学号INNER JOIN student st ON st.学号 = a.学号
★10.按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
SELECTsc.学号,MAX( CASE WHEN c.课程名称 = '语文' THEN 成绩 ELSE 0 END ) AS '语文',MAX( CASE WHEN c.课程名称 = '数学' THEN 成绩 ELSE 0 END ) AS '数学',MAX( CASE WHEN c.课程名称 = '英语' THEN 成绩 ELSE 0 END ) AS '英语',AVG( sc.成绩 ) AS 平均成绩
FROMcourse cJOIN score sc ON c.课程号 = sc.课程号
GROUP BYsc.学号
ORDER BY 平均成绩 DESC
★11.查询学生平均成绩及其名次
ROW_NUMBER()
SELECT学号,AVG(成绩),ROW_NUMBER() OVER ( ORDER BY AVG(成绩) DESC ) AS 排名
FROMscore
GROUP BY学号
★12.按每门课成绩排名
SELECT学号,课程号,成绩,ROW_NUMBER() OVER ( PARTITION BY 课程号 ORDER BY 成绩 DESC ) AS 排名
FROMscore
★13.查询每门功成绩最好的前三名学生姓名
SELECTa.课程号,b.姓名,a.成绩,a.ranking
FROM( SELECT 课程号,学号,成绩, row_number () over ( PARTITION BY 课程号 ORDER BY 成绩 DESC ) AS ranking FROM score ) AS aINNER JOIN student b ON a.学号 = b.学号
WHEREa.ranking < 3
ORDER BYa.课程号;
13.找出语文课中成绩第二高的学生成绩。如果不存在第二高成绩的学生,那么查询应返回 null。
思路 :先找出成绩最高的成绩为多少,再在WHERE 语句中查询比最高成绩小的最高成绩,判断空值用ifnull(a,b)。
或降序排列后用limit函数
方法一:
select ifnull(
(select max(distinct 成绩) from 成绩表
where 成绩<(select max(成绩) from 成绩表 where 课程='语文')
and 课程='语文')
,null) as '语文课第二名成绩';
方法二:
select ifnull(
select distinct 成绩
from 成绩表
where 课程='语文'
order by 课程,成绩 desc
limit 1,1,null) as '语文课第二名成绩';
★14.查询各学生成绩涨幅
select m.学生编号,当前成绩-入学成绩 as 成绩涨幅
from
(select 学生编号,成绩 as 当前成绩
from 成绩表
where 结束日期 = '2011-10-02') as m
left join
(select a.学生编号,b.成绩 as 入学成绩
from 学生表 as a
left join 成绩表 as b
on a.学生编号 = b.学生编号
where a.入学日期 = b.起始日期) as n
on m.学生编号 = n.学生编号
order by 成绩涨幅;
思路参考: https://mp.weixin.qq.com/s?__biz=MzAxMTMwNTMxMQ==&mid=2649248505&idx=1&sn=16b240beb0dd489832d4a34bc022418f&chksm=835fdac9b42853df0f774e0a09e40f03e5dd346ebe6ce8c633e2f1e7df9ae53308a380a4e7d4&scene=21#wechat_redirect
★15.行行交换
SELECT (CASE WHEN MOD(座位号,2) != 0 THEN 座位号+1WHEN MOD(座位号,2) = 0 THEN 座位号-1END) AS 新座位号,姓名
FROM 学生表
ORDER BY 新座位号
思路参考: https://mp.weixin.qq.com/s?__biz=MzAxMTMwNTMxMQ==&mid=2649248050&idx=1&sn=e13004e3c0106845b3a3356c6c0e64f4&chksm=835fd902b4285014ba3b386a064d876db9342c980d1641c2f039458842aec9e35f05831f4eda&scene=21#wechat_redirect
如果最后一行是奇数
SELECT (CASE WHEN MOD(座位号,2) != 0 AND 座位号 != a.数量 THEN 座位号+1 WHEN MOD(座位号,2) = 0 AND 座位号 != a.数量 THEN 座位号-1 WHEN 座位号 = a.数量 THEN 座位号END) AS 新座位号,姓名
FROM 学生表,(SELECT COUNT(*) AS 数量 FROM 学生表) AS a
ORDER BY 新座位号
★16.统计每个班每个同学成绩平均分大于80分的人数和人数占比
方法一:
分别创建符合条件的人数统计表和每个班的人数统计表
SELECTa.班级,b.人数 AS 80以上,b.人数 / a.总人数 AS 占比
FROM(SELECTst.班级,COUNT(DISTINCT ( st.学号 )) AS 总人数 FROM学生表 stLEFT JOIN 成绩表 sc ON st.学号 = sc.学号 GROUP BYst.班级 ) AS a
JOIN (SELECTst.班级,COUNT(DISTINCT ( st.学号 )) AS 人数 FROM学生表 stLEFT JOIN 成绩表 sc ON st.学号 = sc.学号 GROUP BYst.班级,st.学号 HAVINGAVG(分数) > 80 ) AS b
ON a.班级 = b.班级
方法二(推荐):
SELECTst.班级,(SUM( CASE WHEN 平均成绩 > 80 THEN 1 ELSE 0 END )) AS 人数,(SUM( CASE WHEN 平均成绩 > 80 THEN 1 ELSE 0 END ))/ COUNT(*) AS 人数占比
FROM( SELECT 学号, AVG(分数) AS 平均成绩 FROM 成绩表 GROUP BY 学号 ) AS a
LEFT JOIN 学生表 st ON a.学号 = st.学号
GROUP BYst.班级
或
SELECTst.班级,COUNT(IF(平均成绩 > 80,TRUE,NULL)) AS 人数,COUNT(IF(平均成绩 > 80,TRUE,NULL))/ COUNT(*) AS 人数占比
FROM( SELECT 学号, AVG(分数) AS 平均成绩 FROM 成绩表 GROUP BY 学号 ) AS a
JOIN 学生表 st ON a.学号 = st.学号
GROUP BYst.班级
★有筛选条件的统计数量问题的万能模板
#SUM和CASE WHEN嵌套
SELECTsum( CASE WHEN <判断表达式> THEN 1 ELSE 0 END ) AS 数量
FROM信息表
#COUNT和IF嵌套
SELECTCOUNT( IF ( <判断表达式>, TRUE, NULL ) ) AS 数量
FROM信息表
★17.计算新增用户、留存及留存率
SELECTDATE( u.reg_time ) AS dt,SUM( DATEDIFF( l.login_time, u.reg_time ) = 1 ) AS 次日留存,SUM( DATEDIFF( l.login_time, u.reg_time ) = 3 ) AS 3日留存,SUM( DATEDIFF( l.login_time, u.reg_time ) = 7 ) AS 7日留存,SUM( DATEDIFF( l.login_time, u.reg_time ) = 1 )/ COUNT( DISTINCT u.user_id ) AS 次日留存率,SUM( DATEDIFF( l.login_time, u.reg_time ) = 3 )/ COUNT( DISTINCT u.user_id ) AS 3日留存率,SUM( DATEDIFF( l.login_time, u.reg_time ) = 7 )/ COUNT( DISTINCT u.user_id ) AS 7日留存率
FROMuser_info uLEFT JOIN login_log l ON u.user_id = l.user_id
GROUP BYDATE(u.reg_time)
思路参考: https://blog.csdn.net/kejiayuan0806/article/details/106410940/?utm_medium=distribute.pc_relevant.none-task-blog-baidujs-7&spm=1001.2101.3001.4242
需要注意的是TIMESTAMPDIFF和DATEDIFF的区别,DATEDIFF只有值的日期部分参与计算,TIMESTAMPDIFF是所有部分参与计算。如果值精确到秒的话,计算不满足24小时则会返回0天。
详见:
https://blog.csdn.net/liguangix/article/details/80243197
18.查找前20%的数据
#创建视图
CREATE VIEW a AS SELECT
*,
ROW_NUMBER() OVER ( ORDER BY 访问量 DESC ) AS ranking
FROMcook;SELECT用户类型,AVG(访问量)
FROMa
WHEREranking > ( SELECT MAX( ranking ) FROM a ) * 0.2
GROUP BY用户类型
思路参考: https://mp.weixin.qq.com/s?__biz=MzAxMTMwNTMxMQ==&mid=2649248425&idx=1&sn=9a74e15e86f04d675bed4cb0854eab20&chksm=835fda99b428538fc76d58b0d083d589c4d70f84f1ae22eeee07707defbabfc2adfb40548ab3&scene=21#wechat_redirect
★19.正则表达式
Leetcode:1517. 查找拥有有效邮箱的用户
MySQL正则表达式
SELECT user_id,name,mail
FROM users
WHERE mail regexp '^[a-zA-Z]+[a-zA-Z0-9_./-]+@leetcode.com$'
regexp为正则表达式- 字符串中间可用 + 号将条件连接起来
- "^"表示开头,“$”表示结尾
看题解中大家都在. 和 - 前加了两个\,但是我没加也通过了,这里可能有坑,先记录一下
★20.删除重复的行并保留第一次出现的行
Leetcode:196. 删除重复的电子邮箱
DELETE p1 FROM person p1,person p2
WHERE p1.id > p2.id AND p1.email = p2.email
在DELETE语句中使用自连接需在DELETE后添加表名(p1)
★21.行转列
Leetcode:1435. 制作会话柱状图
SELECT '[0-5>' bin, SUM(IF(duration<300,1,0)) total FROM Sessions
UNION SELECT '[5-10>' bin, SUM(300<=duration AND duration<600) total FROM Sessions
UNION SELECT '[10-15>' bin, SUM(600<=duration AND duration<900) total FROM Sessions
UNION SELECT '15 or more' bin, SUM(900<=duration) total FROM Sessions
UNION和UNION ALL区别:前者会删除重复的行,后者不会
★22.查询消费的金额都大于100的用户

SELECT t.`user` FROM table t GROUP BY t.`user` HAVING MIN(t.money) >= 100
这篇关于SQLZOO及经典面试50题刷题记录的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





