本文主要是介绍面试大杀器之:给我说说:volatile,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在我们学习并发时,有一个关键词是任何时候都没有办法绕过去的!没错,volatile。很多人对volatile的认知还停留在概念上,殊不知,你说的这些,都不是面试官希望了解的,概念谁不知道,想知道的是为什么。好的,今天由我给大家带来volatile史上最刨根问底的面试问题,看看你能挺到第几关?
volatile的特性
可见性:对一个volatile变量的读,①总是能看到(任意线程)对这个volatile变量最后的写入。
原子性:对任意单个volatile变量的读/写具有原子性,但类似于volatile++这种复合操作不具有原子性(基于这点,我们通过会认为volatile不具备原子性)。volatile仅仅保证对单个volatile变量 的读/写具有原子性,而锁的互斥执行的特性可以确保对整个临界区代码的执行具有原子性。
64位的long型和double型变量,只要它是volatile变量,对该变量的读/写就具有原子性。
有序性:对volatile修饰的变量的读写操作前后加上各种特定的②内存屏障来禁止③指令重排序来保障有序性。
如果您面试的是一个相当不错的自研公司,你在面试官面前回答这三点时,那么恭喜您,您将迎来一系列狂风暴雨式的追问,此时就是你表现自我的一次机会!
追问:
1、为什么可以总是能看到(任意线程)对这个volatile变量最后的写入?
2、什么是内存屏障?
3、什么是指令重排?为什么要设计指令重排?你能给我简单分析一个因为指令重排这个原因而可能导致的bug吗?
如果,您有幸被追问以上几个问题,并且可以对答如流,那么恭喜你,此轮面试,您将会在面试官的心里打上高分!
想把以上问题解释清楚,是十分考验一个程序猿的综合实力的,并不是几分钟可以说的清楚的。
你问我为什么?那就让我一一道来!
- 为什么可以总是能看到(任意线程)对这个volatile变量最后的写入?
想说清楚这个问题,就不得不请出一个大名鼎鼎的java模型:JMM模型
是的!我没有写错,很多基础不好的同学,会以为我把JVM写成了JMM,其实这个是两个不同的模型。JVM模型,也是大厂的热点问题,但不是今天的主角。接下来有请JMM!!!看图:
ava虚拟机规范中定义了Java内存模型(Java Memory Model,JMM),用于屏蔽掉各
种硬件和操作系统的内存访问差异,以实现让Java程序在各种平台下都能达到一致的并发效果,JMM规范了Java虚拟机与计算机内存是如何协同工作的:规定了一个线程如何和何时可以看到由其他线程修改过后的共享变量的值,以及在必须时如何同步的访问共享变量。JMM描述的是一种抽象的概念,一组规则,通过这组规则控制程序中各个变量在共享数据区域和私有数据区域的访问方式,JMM是围绕原子性、有序性、可见性展开的
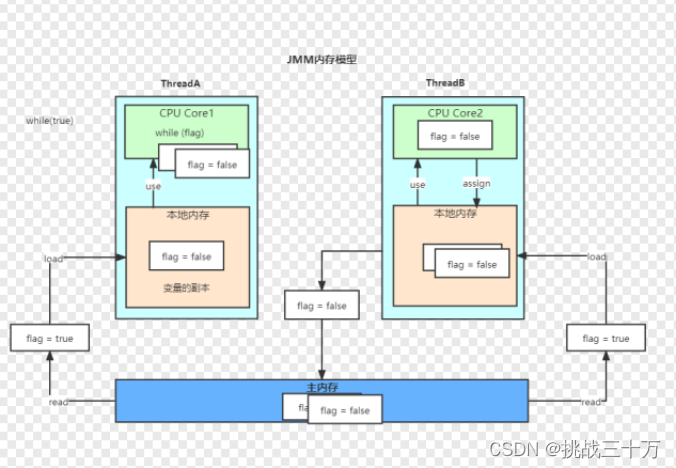
现在给大家分析一下此图:JMM模型最关键的两点:本地内存和主内存,这也是回答的重点。
解析上图:
假设有两条线程ThreadA和ThreadB,未做任何特殊处理时,同时对全局变量布尔:flag进行操作。设置flag的初始值时true。线程A是一个while(flag)循环。线程B把flag,设置成为false。
在这种情况下,很多同学就会分析了,认为while循环执行是有数的,不会一直执行下去,因为线程B一旦抢占了执行,就会把flag的值更改!其实不然,当你在了解jmm模型的时候,便会颠覆你的认知,当不做任何处理时while会进入死循环。原因就是flag初始的时候,初始值会加载进主内存,再由主内存写进本地内存,线程A执行时就会一直读本地内存,尽管线程B抢占了线程,将主内存的flag赋值未false,但是线程A由于执行太快,并不会在执行之前将主内存的值实时更新进线程A的本地内存。导致while会一直执行下去!
JMM与硬件内存架构的关系
Java内存模型与硬件内存架构之间存在差异。硬件内存架构没有区分线程栈和堆。对于硬
件,所有的线程栈和堆都分布在主内存中。部分线程栈和堆可能有时候会出现在CPU缓存中和CPU内部的寄存器中。如下图所示,Java内存模型和计算机硬件内存架构是一个交叉关系:

回到上述问题,如果一开始在 Boolean flag = true 时 ,在此代码添加volatile,关键字,就会排除此场景!
为什么volatile可以做到?接下来仔细看,别眨眼!
volatile在hotspot的实现 字节码解释器实现
JVM中的字节码解释器(bytecodeInterpreter),用C++实现了JVM指令,其优点是实现相对
简单且容易理解,缺点是执行慢。
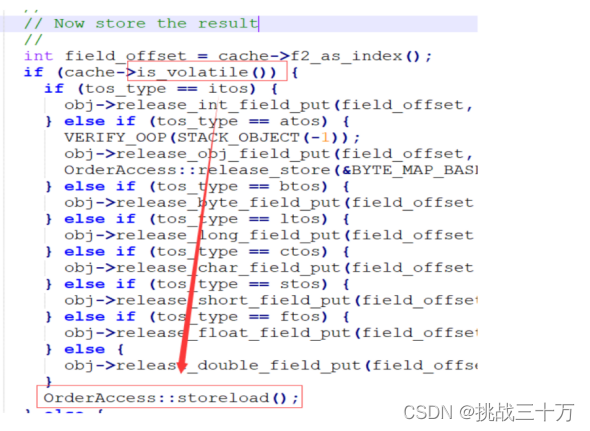
用红框裱起来的,就是volatile的核心原因:storeload;
什么是storeload?
Storeload就是大名鼎鼎的内存屏障!
这就引出了这篇文章的第二个问题:什么是内存屏障?
话说至此,我信心一半的同学已经被这一环套一环的概念劝退了。一个简简单单的Volatile关键字,为什么会引出一大堆乱七八糟的东西,其实这就是学习,知其然还需知其所以然。
我为什么会在这里说这么一大段鸡汤废话呢?因为。。。同学们坐住了,想知道内存屏障,那就让我们看看更底层的汇编语言!!!

这里提供的是两种汇编语言,都是以X86主流的系统为主来进行分析。无论是常见的汇编代码还是Linux的汇编代码。都有我们的一个新朋友:Lock前缀指令
新的问题又来了:lock前缀指令的作用是什么?
1. 确保后续指令执行的原子性。在Pentium及之前的处理器中,带有lock前缀的指令在执
行期间会锁住总线,使得其它处理器暂时无法通过总线访问内存,很显然,这个开销很
大。在新的处理器中,Intel使用缓存锁定来保证指令执行的原子性,缓存锁定将大大降低
lock前缀指令的执行开销。
2. LOCK前缀指令具有类似于内存屏障的功能,禁止该指令与前面和后面的读写指令重排
序。
3. LOCK前缀指令会等待它之前所有的指令完成、并且所有缓冲的写操作写回内存(也就是
将store buffer中的内容写入内存)之后才开始执行,并且根据缓存一致性协议,刷新
store buffer的操作会导致其他cache中的副本失效。
汇编层面volatile的实现
添加下面的jvm参数查看一个可见性Demo的汇编指令
1 ‐XX:+UnlockDiagnosticVMOptions ‐XX:+PrintAssembly ‐Xcomp

验证了可见性使用了lock前缀指令
你以为到这就结束了?NONONO!这才是开始
此时看到的汇编语言是直接与机器打交道的。你任何程序,最后都是机器给你运行的。所以,
从硬件层面看看官方文档怎么说的!
《64-ia-32-architectures-software-developer-vol-3a-part-1-manual.pdf》中有如下描
述:
The 32-bit IA-32 processors support locked atomic operations on locations in system
memory. These operations are typically used to manage shared data structures (such as
semaphores, segment descriptors, system segments, or page tables) in which two or more
processors may try simultaneously to modify the same field or flag. The processor uses three
interdependent mechanisms for carrying out locked atomic operations:
• Guaranteed atomic operations
• Bus locking, using the LOCK# signal and the LOCK instruction prefix
• Cache coherency protocols that ensure that atomic operations can be carried out on
cached data structures (cache lock); this mechanism is present in the Pentium 4, Intel Xeon,
and P6 family processors
翻译:
32位的IA-32处理器支持对系统内存中的位置进行锁定的原子操作。这些操作通常用于管
理共享的数据结构(如信号量、段描述符、系统段或页表),在这些结构中,两个或多个处理器
可能同时试图修改相同的字段或标志。处理器使用三种相互依赖的机制来执行锁定的原子操作:
1、有保证的原子操作
2、总线锁定,使用LOCK#信号和LOCK指令前缀
3、缓存一致性协议,确保原子操作可以在缓存的数据结构上执行(缓存锁);这种机制出
现在Pentium 4、Intel Xeon和P6系列处理器中
好了!懵逼树上懵逼果,懵逼树下你和我。原来LOCK#信号和LOCK指令前缀只是保证原子性的手段之一,而不是唯一。
特别解释一下:在linux系统的汇编语言里,有这么一句话:always use locked add1 since mfence is sometimes expensive 大概意思就是:系统里总是使用lock前缀指令来替换内存屏障。
细心的朋友已经发现了,不对啊,你刚才说内存屏障不是说Storeload 吗?那mfence 又是啥?为啥翻译里,你也称为内存屏障!!!
这就是面试官经常给你刨的坑,也许平时喜欢钻研的同学,也知道内存屏障这个概念,但是往往忽视了,内存屏障,其实有两种!!!
这里要十分注意的一点是:一定分清楚JVM层的内存屏障和硬件层的内存屏障
Lock前缀指令是汇编语言,出现在哪一层???对,没错,是硬件层!!!
新问题:Lock前缀,Lock是不是一种内存屏障???
答案:不是!!!
往下看定义:
JVM层面的内存屏障
在JSR规范中定义了4种内存屏障:
LoadLoad屏障:(指令Load1; LoadLoad; Load2),在Load2及后续读取操作要读取的数
据被访问前,保证Load1要读取的数据被读取完毕。
LoadStore屏障:(指令Load1; LoadStore; Store2),在Store2及后续写入操作被刷出前,
保证Load1要读取的数据被读取完毕。
StoreStore屏障:(指令Store1; StoreStore; Store2),在Store2及后续写入操作执行前,
保证Store1的写入操作对其它处理器可见。
StoreLoad屏障:(指令Store1; StoreLoad; Load2),在Load2及后续所有读取操作执行
前,保证Store1的写入对所有处理器可见。它的开销是四种屏障中最大的。在大多数处理器的
实现中,这个屏障是个万能屏障,兼具其它三种内存屏障的功能
由于x86只有store load可能会重排序,所以只有JSR的StoreLoad屏障对应它的mfence或
lock前缀指令,其他屏障对应空操作
X86是主流,所以我们关注第四种屏障!!
硬件层内存屏障
硬件层提供了一系列的内存屏障 memory barrier / memory fence(Intel的提法)来提供
一致性的能力。拿X86平台来说,有几种主要的内存屏障:
1. lfence,是一种Load Barrier 读屏障
2. sfence, 是一种Store Barrier 写屏障
3. mfence, 是一种全能型的屏障,具备lfence和sfence的能力
4. Lock前缀,Lock不是一种内存屏障,但是它能完成类似内存屏障的功能。Lock会对
CPU总线和高速缓存加锁,可以理解为CPU指令级的一种锁。它后面可以跟ADD, ADC,
AND, BTC, BTR, BTS, CMPXCHG, CMPXCH8B, DEC, INC, NEG, NOT, OR, SBB, SUB,
XOR, XADD, and XCHG等指令。
又蒙了是不是?为啥lock不是一种内存屏障,却能完成类似的功能?他是咋完成的?
那我就再给你们翻译翻译,啥是专业:
对Load Barrier来说,在读指令前插入读屏障,可以让高速缓存中的数据失效,重新从主
内存加载数据;对Store Barrier来说,在写指令之后插入写屏障,能让写入缓存的最新数据写
回到主内存。
Lock前缀实现了对总线和缓存加锁,然后执行后面的指令,最后释放锁
后会把高速缓存中的数据刷新回主内存。在Lock锁住总线的时候,其他CPU的读写请求都会被
阻塞,直到锁释放。
不同硬件实现内存屏障的方式不同,Java内存模型屏蔽了这种底层硬件平台的差异,由
JVM来为不同的平台生成相应的机器码。
此处,我们就可以小做总结。
一、内存屏障有两个能力:
1. 阻止屏障两边的指令重排序
2. 刷新处理器缓存/冲刷处理器缓存
二、Lock前缀指令的作用:
1. 确保后续指令执行的原子性。在Pentium及之前的处理器中,带有lock前缀的指令在执
行期间会锁住总线,使得其它处理器暂时无法通过总线访问内存,很显然,这个开销很
大。在新的处理器中,Intel使用缓存锁定来保证指令执行的原子性,缓存锁定将大大降低
lock前缀指令的执行开销。
2. LOCK前缀指令具有类似于内存屏障的功能,禁止该指令与前面和后面的读写指令重排
序。
3. LOCK前缀指令会等待它之前所有的指令完成、并且所有缓冲的写操作写回内存(也就是
将store buffer中的内容写入内存)之后才开始执行,并且根据缓存一致性协议(后文我会解释),刷新store buffer的操作会导致其他cache中的副本失效。
请注意: 刷新处理器缓存/冲刷处理器缓存
回顾一下,同学们还记得JMM模型吗?最重要的是两块分别是什么?
本地内存、 主内存。
再讲JMM模型时,我举了个例子,到这里我们就可以明白,为什么加了Volatile关键字,就可以保证不会出现死循环了吧,因为Volatile关键字的底层使用了内存屏障,会在编译代码执行的时候,实时刷新本地内存里的缓存结果!!!
再注意:无论是Lock还是内存屏障都有一个功能,防止指令重排!
还记得我们一开始就提出的问题吗?
什么是指令重排?为什么要设计指令重排?你能给我简单分析一个因为指令重排这个原因而可能导致的bug吗?
指令重排:
在执行程序时,为了提高性能,编译器和处理器常常会对指令做重排序。
重排序分3种类型:
编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
指令级并行的重排序。现代处理器采用了指令级并行技术(Instruction-Level Parallelism,ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
内存系统的重排序。由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
这里需要注意的是:指令重排发生的位置:编译器和处理器
一个是硬件层面,一个是软件层面!
关于为什么要这样设计,这里必须说一点,需要大家自己去领悟的:设计语言时,哪怕时代码的编辑,往往都存在取舍的问题。例如:空间换时间,安全换效率,效率换安全 等等。举个例子,多线程明明总是会出现各种问题,为什么多线程却是主流的开发代码。因为很简单,在互联网上,多线程就可以把效率提到最高,用户体验更好,虽然又风险,这个跟用户又有什么关系,规避风险不正是程序猿的工作吗?
因为指令重排这个原因而可能导致的bug
这里就简单的说一下,一说你们就应该反应过来,如果不知道的,去看看设计模式就行了。
在单例设计模式里的懒汉式,在定义被返回的对象时,哪怕用了双重锁,不加volatile,再高并发多线程的情况下,都可能产生空指针,拿不到对象的可怕情况!
很简单,在对象生成的时候,需要最基本的三步操作:
- 开辟一个新的内存
- 初始化
- 赋值
好的,你以为程序一定按照这个顺序执行吗?不一定,指令重排后,可能会产生这样一个顺序:
1 、 3 、 2
好了,你线程1已经赋值了,线程2来的时候发现这个对象有值,直接返回了。这个时候你才初始化,你猜线程2返回的值是什么?没错。是NULL!!!
这个我真不愿抛上代码,最简单的设计模式如果都不知道,你真应该下下功夫了
好了,综上所属,volatile已经解释了。往往面试官的一句简单说说volatile,其内核并不是简单的。想说清楚更是难上加难。希望大家不畏困难,冲冲冲!不怕拦路虎,来一个解决一个!!
总结一下,上述描述中出现的新问题!
没错,又是一个大名鼎鼎的概念:一致性协议
关于这个协议,不是本文的重点,暂时按下不表。
先说另一个概念,就当给下篇文章做个开头吧!
总线窥探(Bus Snooping)
总线窥探(Bus snooping)是缓存中的一致性控制器(snoopy cache)监视或窥探总线事务的一种方案,其目标是在分布式共享内存系统中维护缓存一致性。包含一致性控制器(snooper)的缓存称为snoopy缓存。该方案由Ravishankar和Goodman于1983年提出。
工作原理
当特定数据被多个缓存共享时,处理器修改了共享数据的值,更改必须传播到所有其他具有该数据副本的缓存中。这种更改传播可以防止系统违反缓存一致性。数据变更的通知可以通过总线窥探来完成。所有的窥探者都在监视总线上的每一个事务。如果一个修改共享缓存块的事务出现在总线上,所有的窥探者都会检查他们的缓存是否有共享块的相同副本。如果缓存中有共享块的副本,则相应的窥探者执行一个动作以确保缓存一致性。这个动作可以是刷新缓存块或使缓存块失效。它还涉及到缓存块状态的改变,这取决于缓存一致性协议(cache coherence protocol)。
窥探协议类型
根据管理写操作的本地副本的方式,有两种窥探协议:
Write-invalidate
当处理器写入一个共享缓存块时,其他缓存中的所有共享副本都会通过总线窥探失效。这种方法确保处理器只能读写一个数据的一个副本。其他缓存中的所有其他副本都无效。这是最常用的窥探协议。MSI、MESI、MOSI、MOESI和MESIF协议属于该类型。
Write-update
当处理器写入一个共享缓存块时,其他缓存的所有共享副本都会通过总线窥探更新。这个方法将写数据广播到总线上的所有缓存中。它比write-invalidate协议引起更大的总线流量。这就是为什么这种方法不常见。Dragon和firefly协议属于此类别。
这篇关于面试大杀器之:给我说说:volatile的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







