本文主要是介绍ArcGIS: 第二届全国大学生GIS技能大赛(广西师范学院)详解-下午题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
01 题目
02 思路和实操
2.1 流域提取-思路
2.2 流域提取-实操
2.2.1 获取DEM
编辑 2.2.2 水文分析-提取流域基于单出水口
2.3 河网分级-思路
2.4 河网分级-实操
2.4.1 提取河道网络
2.4.2 河网分级 编辑
2.5 子流域提取和处理-思路
2.6 子流域提取和处理-实操
2.6.1 子流域的提取编辑
2.6.2 微子流域的处理
2.7 子流域地形特征统计-思路
2.8 子流域地形特征统计-实操
01 题目
某地区拟对X流域综合治理规划设计,需进行流域分区,并进行流域地形特征分析。现有该区域的地形数据,请按照要求进行数据处理,并制作专题图;同时梳理上述问题及其解决过程,规划出科学合理的GIS应用系统,进行系统功能及界面设计。
数据说明如下:
- terlk_l为等高线数据,terlk_p为高程点数据,elev为高程字段;
- outlet为流域出水口。
(上述BOX数据不清楚,目前没有使用到:
 )
)
具体竞赛要求如下:
- 以outlet为出水口,提取出流域集水区范围。
- 提取出流域范围内汇水面积累积量在2.0km2以上的河道,并对河网进行分级。
- 以提取的河道网络为出水口,对流域进行子流域划分,对于面积<10hm2的微子流域,按照边长最大优先原则对其进行合并处理。
- 以表格形式统计流域中每一个子流域的地形高度特征(最小高度、最大高度、平均高度)。
- 制作专题图,专题图要求以地形特征为背景,体现出流域河流水系和子流域分区特征,并将专题图以jpg图片格式输出。
- 基于问题的解决方案,进行GIS应用系统的功能及界面设计。系统功能模块原则上不要求代码实现,但地图加载、放大、缩小、漫游、全图等功能要求实现。
- 提交文件包括:专题图文件(含数据文件、地图文档),GIS应用系统开发工程文件及技术文档。
- 技术文档应包括解题思路、解题过程、系统设计等内容。技术文档中,请尽可能以附图说明。附图请使用Word图片裁剪工具使附图内容仅为说明区域。
02 思路和实操
我们只解决以下部分:
- 以outlet为出水口,提取出流域集水区范围。
- 提取出流域范围内汇水面积累积量在2.0km2以上的河道,并对河网进行分级。
- 以提取的河道网络为出水口,对流域进行子流域划分,对于面积<10hm2的微子流域,按照边长最大优先原则对其进行合并处理。
- 以表格形式统计流域中每一个子流域的地形高度特征(最小高度、最大高度、平均高度)。
我做完整个流程,我唯一觉得特别不能理解的就是第三小点(子流域提取和处理) ,我不能理解为什么应该以河道网络作为出水口(这里我甚至以为是搞错了,因为我在学习的过程中向来都是以少数的出水口或者河道网络的分叉点作为出水口,而这里以河网的每一个栅格点都作为出水口有一些难以理解,不知道是不是这方面知识的纰漏==>确实有这样处理的),但是如果你不这么处理(不以河道网络每一个栅格点作为出水口而是河网交接处等方式),你虽然也可以得到子流域,但是你无法得到微子流域这么一个处理,因为你只有以河道网络(N多个栅格点)作为出水口,才会出现非常多的子流域,进而进行处理。
2.1 流域提取-思路
此处的大体上和各位想的类似:
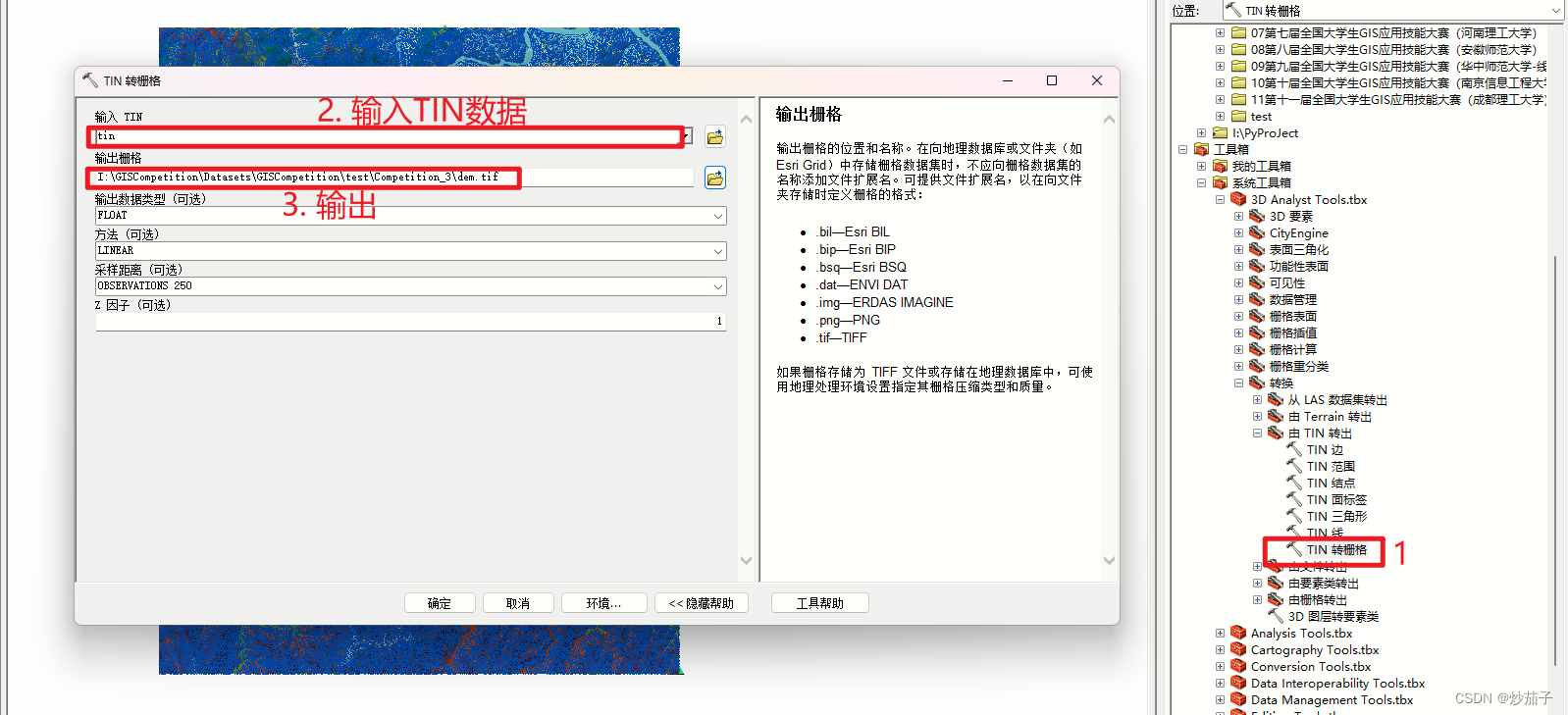
首先,大家应该想到了我们仅仅只有高程线和高程点两个数据,如何得到DEM?想到了就比较简单,毕竟原理也不是很清楚。通过创建TIN工具将高程线和高程点数据转化为TIN数据,然后通过TIN转栅格工具将TIN数据转化为DEM。
接下来就是常规的水文分析进行流域集水区的提取:
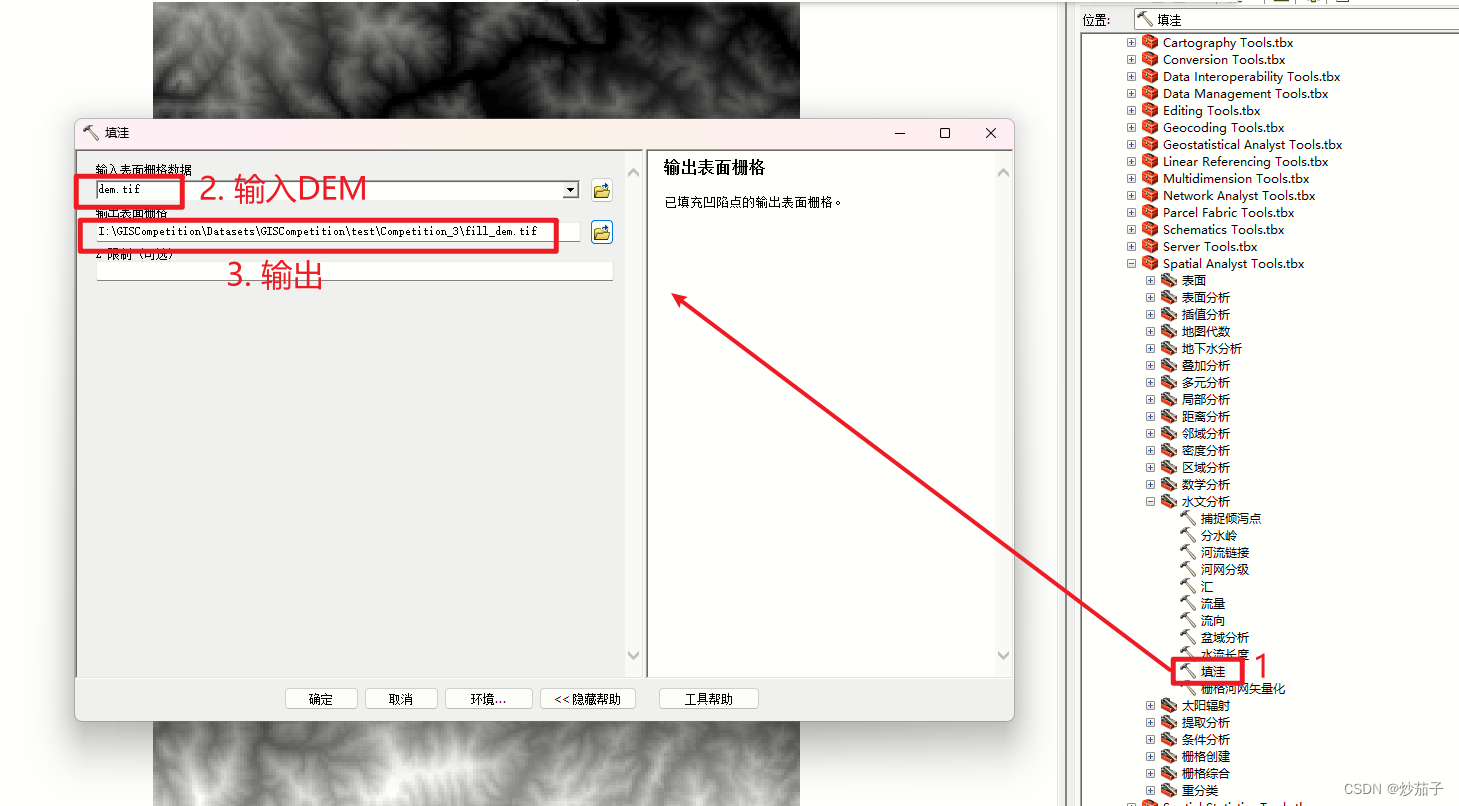
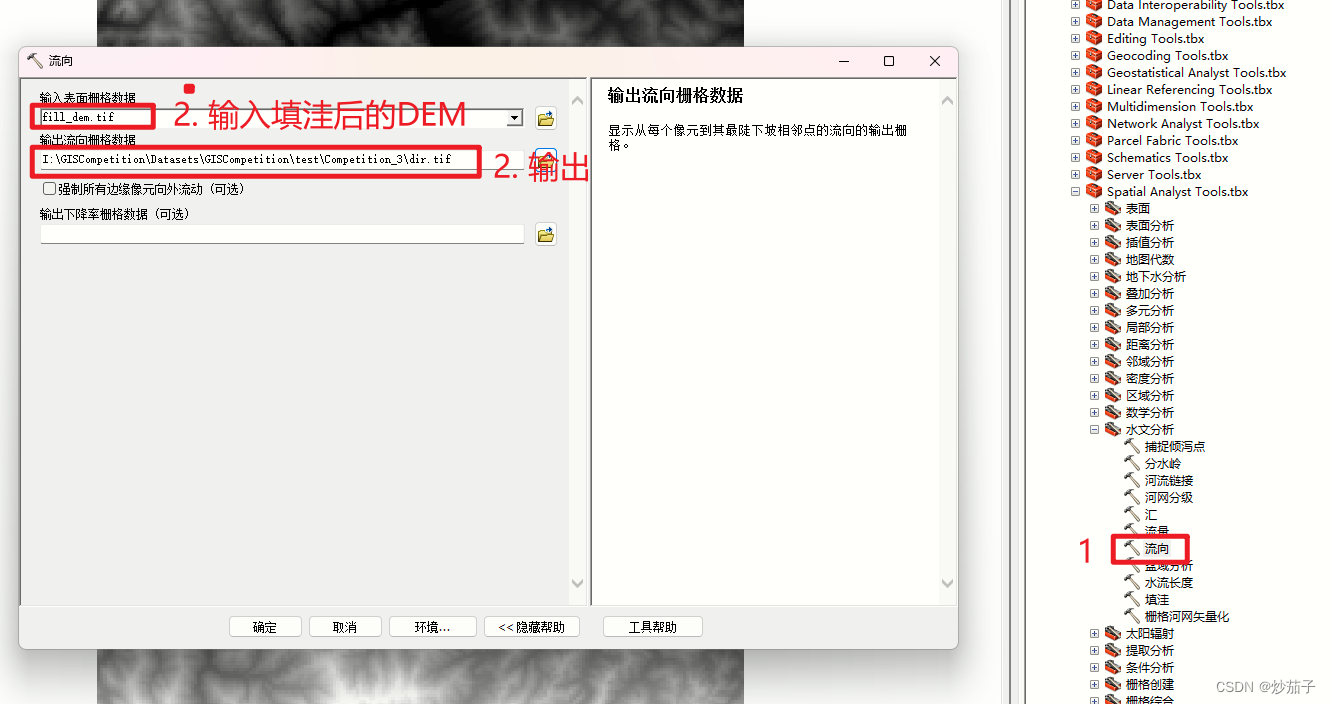
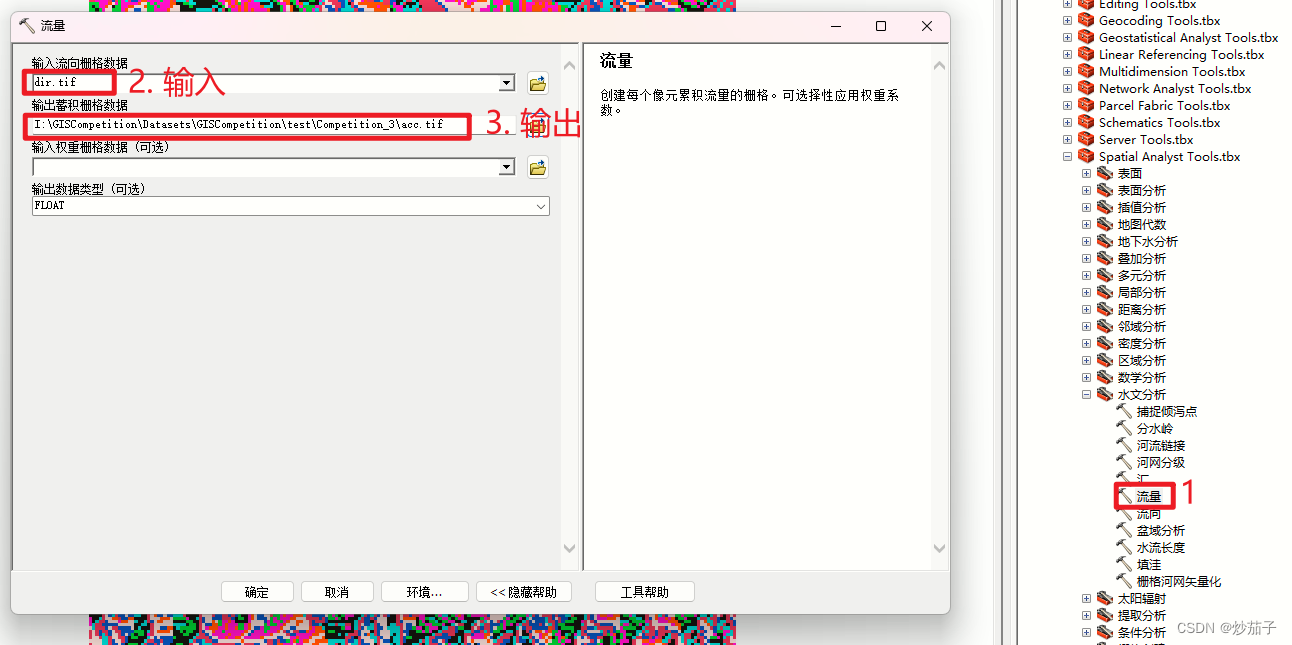
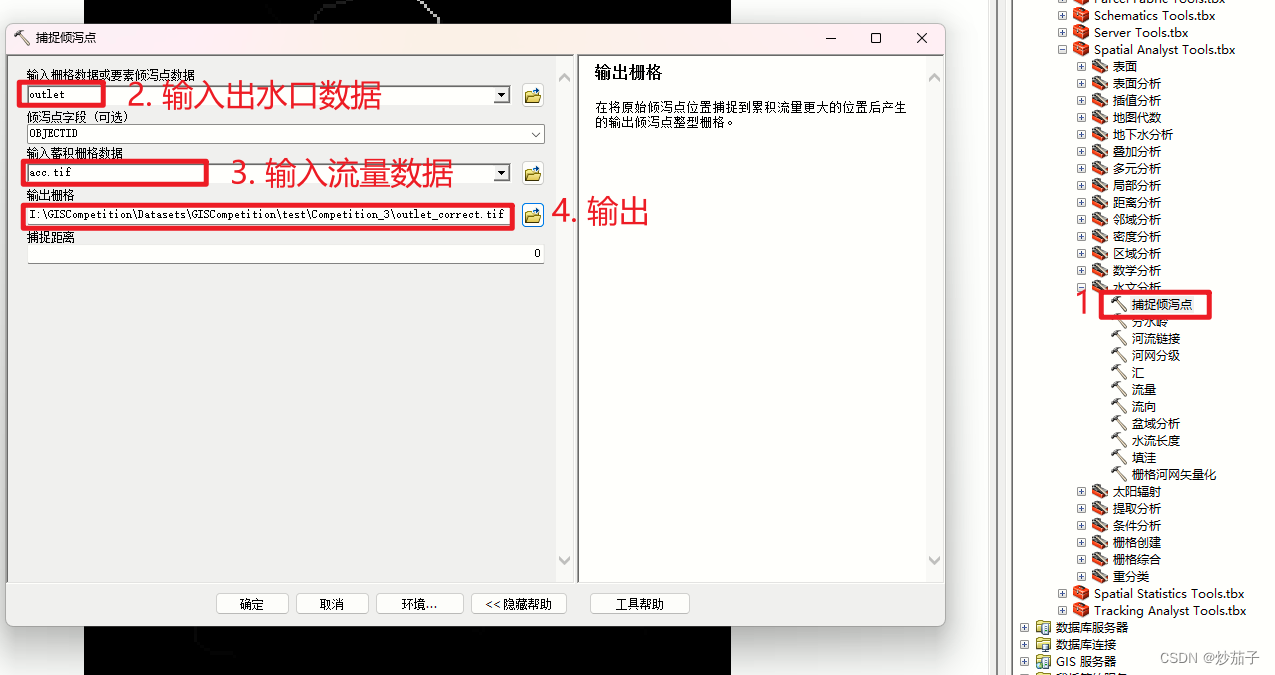
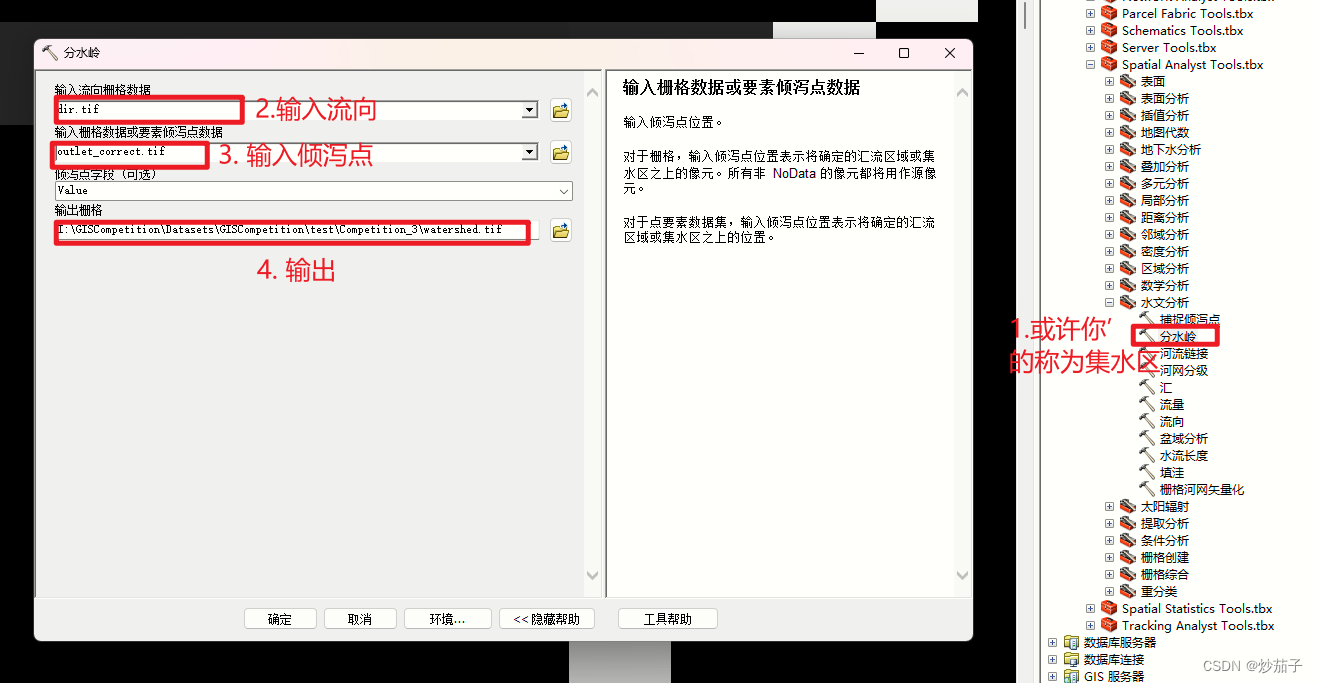
对得到的DEM进行填洼处理 ==> 接着依次进行流向和流量分析 ==> 接着基于outlet数据进行出水口的捕捉得到倾泻点(这里我思考了一会儿,还是应该做一下捕捉倾泻点处理,因为它没有明确说明该出水口是基于当前DEM得到的,所以这个出水口数据可能是当地水文站或者其他DEM或者哪里得到的,可能会存在偏移,我们进行这一步处理只会更准确不会错误,因为我们只是基于当前和outlet数据和DEM得到位置最恰当的出水口)。 ==> 接着使用分水岭工具(高版本可能是集水区工具)进行流域的提取。
2.2 流域提取-实操
2.2.1 获取DEM

 2.2.2 水文分析-提取流域基于单出水口
2.2.2 水文分析-提取流域基于单出水口
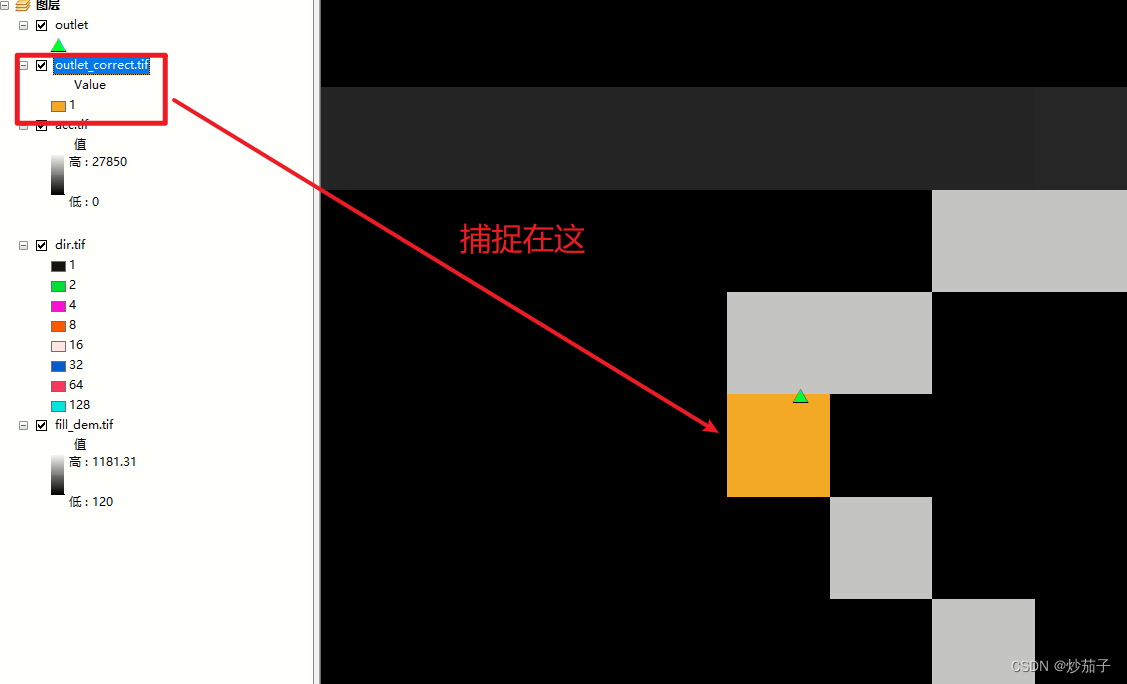
提取的流域(其实这就是基础,以后都是在此基础上进行,它就作为了一个研究区域):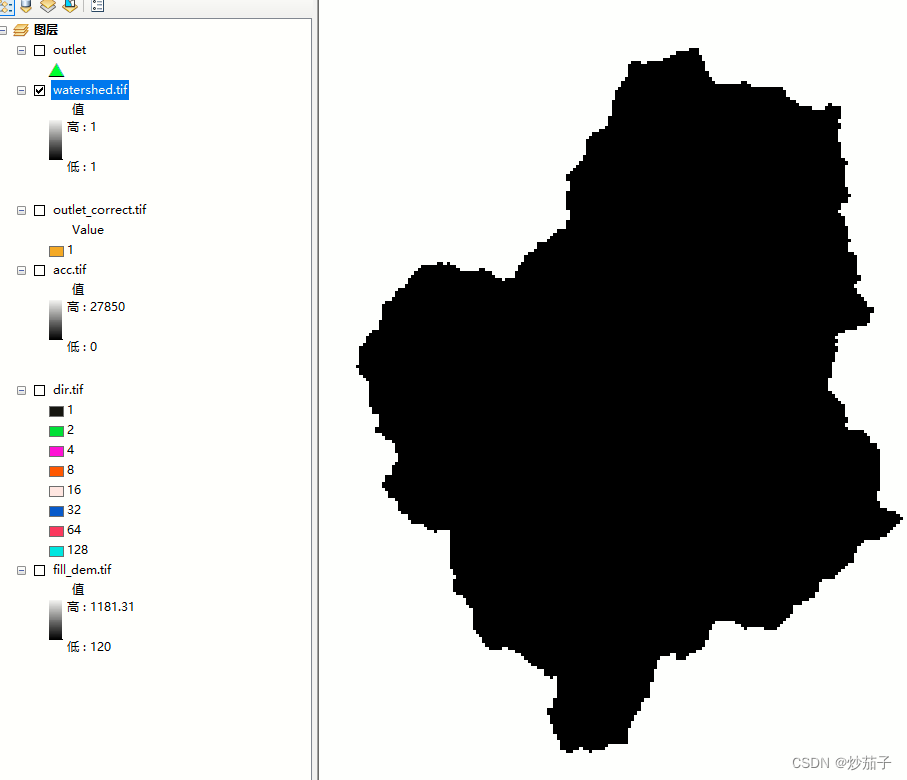
2.3 河网分级-思路
因为我们后续都是在前面提取的大流域下进行处理,所以为了避免频繁的进行掩膜裁剪。
首先进行环境的设置确保范围;
接着就是这里的:汇水面积累积量在2.0KM^2如何理解?我看大部分教程似乎就是直接在流量数据上进行逻辑运算。但是实际上我认为这是错误的(个人意见),这是ArcGIS对于流量的定义: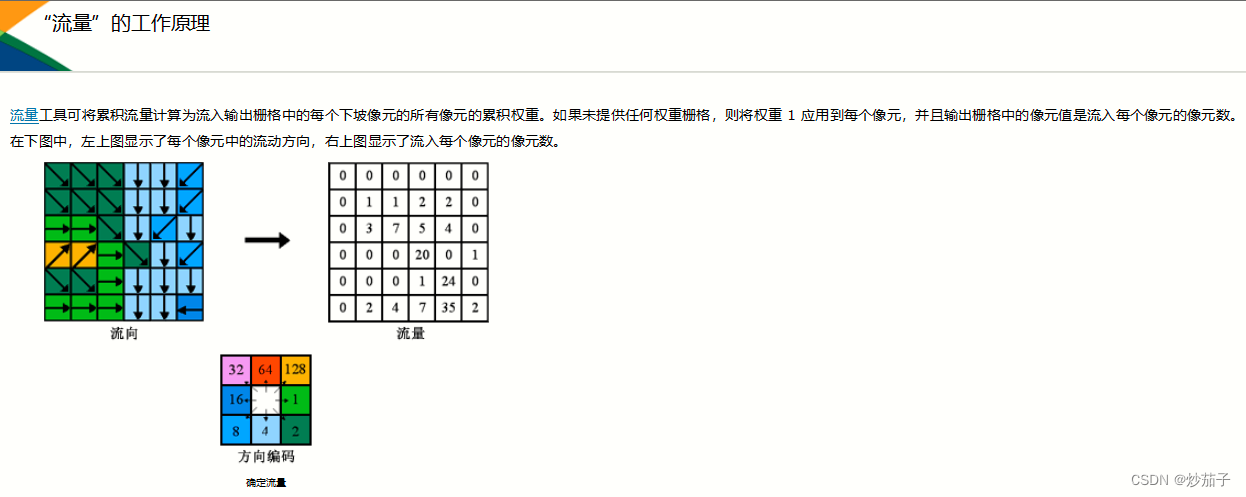
其实从流量数据的数据类型也可以发现如果每一个栅格值直接就是表示汇水面积累积量(对于这里也有一些疑惑,我的理解是一个栅格流向下一个栅格,那么下一个栅格接收上一个栅格的累积量就是栅格的面积(基于像素大小可以得到),不知道汇水面积累积量的理解是否如此?),那么面积不应该刚好是整数才对(你可以发现累积量刚好都是整数),按照ArcGIS的原理那么应该是每一个像元的初始累积量都是单位1,然后如此累计计算。
而且就算流量数据的栅格值表示的就是汇水面积累积量那么也应该是 value > 2000,000而不是2000,这是km^2不是km啊。
然后我们基于像素大小:75meter*75meter可以得到,实际上应该是
value > (2000000 / (75 * 75)). ==> value > 365(约等于)
后续我是这么做的,个人意见。
我们这里进行流量的阈值取定时应该这么干:
Setnull("流量数据" <365, "流量数据")(我多用栅格计算器,大家也可以使用条件函数之类的工具),他表示如果满足条件 <流量数据 < 365>那么将其赋值为NoData,否则赋值为原值(即不处理).
那么为什么不是:
Setnull("流量数据" <365, 1)这就提到了我最前面说的子流域提取,这里最坑。它要求是以提取的河道网络作为出水口,但是如果你的河道网络已经做了原始值的改动,那么最后你的流域的唯一值就只有少数几个(虽然范围形状什么的都一致),那么你无法完成对于面积小于<10hm^2的微子流域的处理。
当然,你这里就算全部为1其实不影响你当前河网分级的任何操作。
2.4 河网分级-实操
因为我们后续都是在前面提取的大流域下进行处理,所以为了避免频繁的进行掩膜裁剪,这里我们设置一下环境:
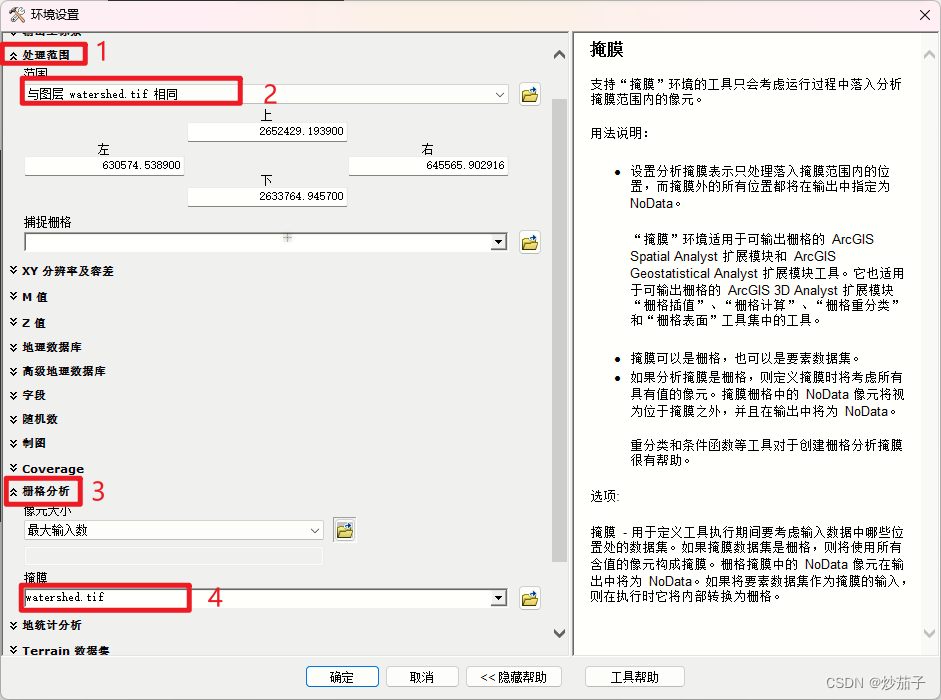
2.4.1 提取河道网络
使用栅格计算器:
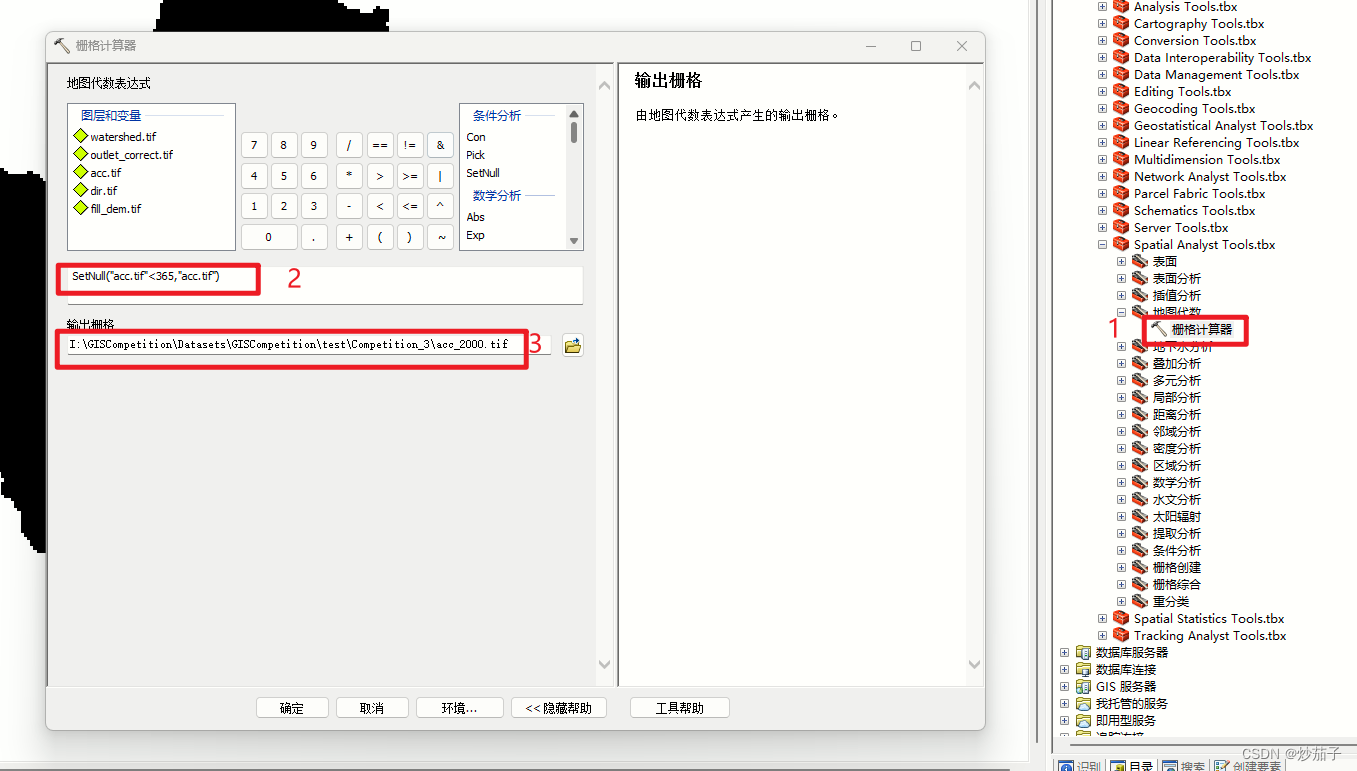
SetNull("acc.tif"<365,"acc.tif")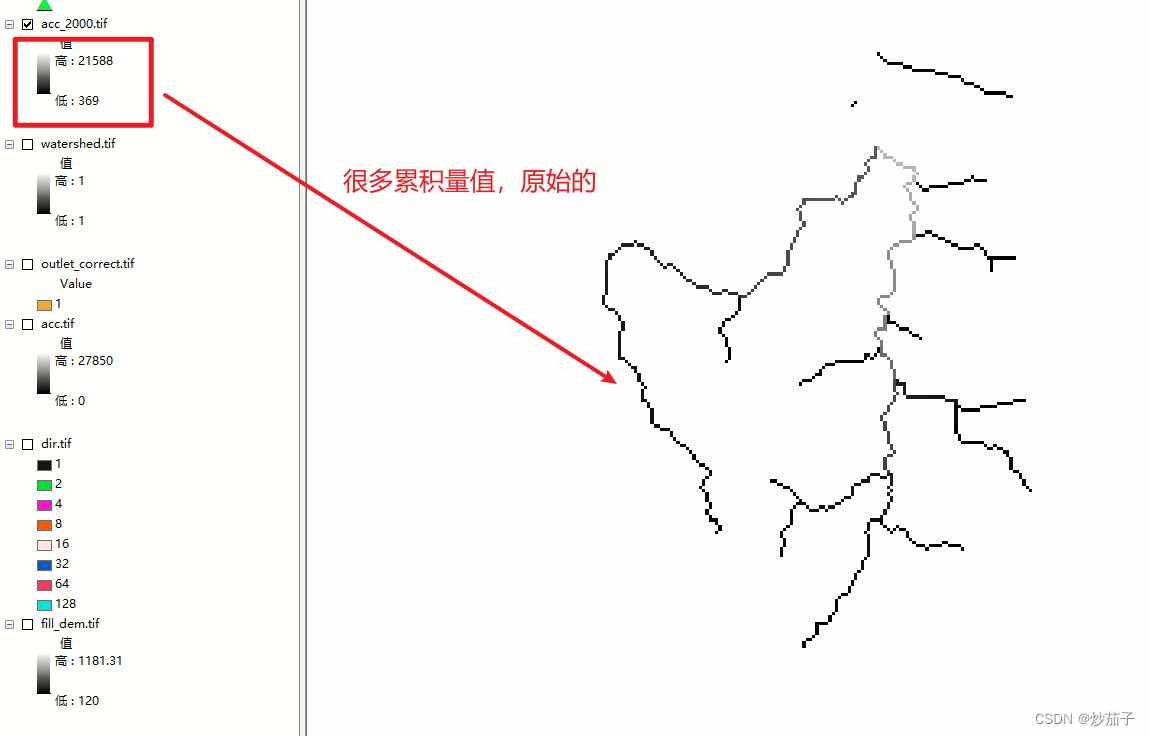
2.4.2 河网分级
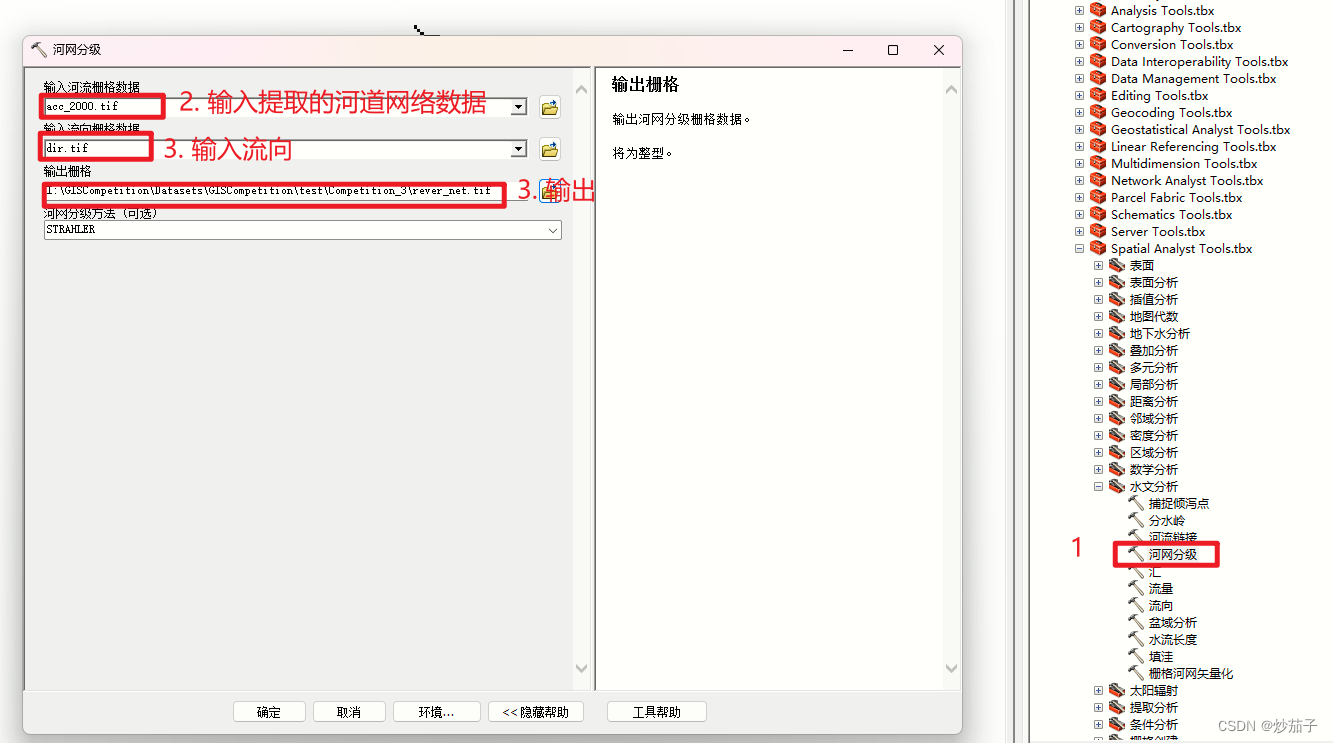
再转一下矢量吧,后面出图会更好调整一些也更好看(虽然我不做):
注意:一般对于河网矢量化我们是不用栅格转线或者栅格转要素这类一般工具,而是使用栅格河网矢量化工具,它与前面的区别就是在于它利用了流向数据更好的解决了在转化为矢量的时候出现细部碎屑(你可以自己试试看看区别就很清楚了),除此之外没有区别,就是栅格转矢量: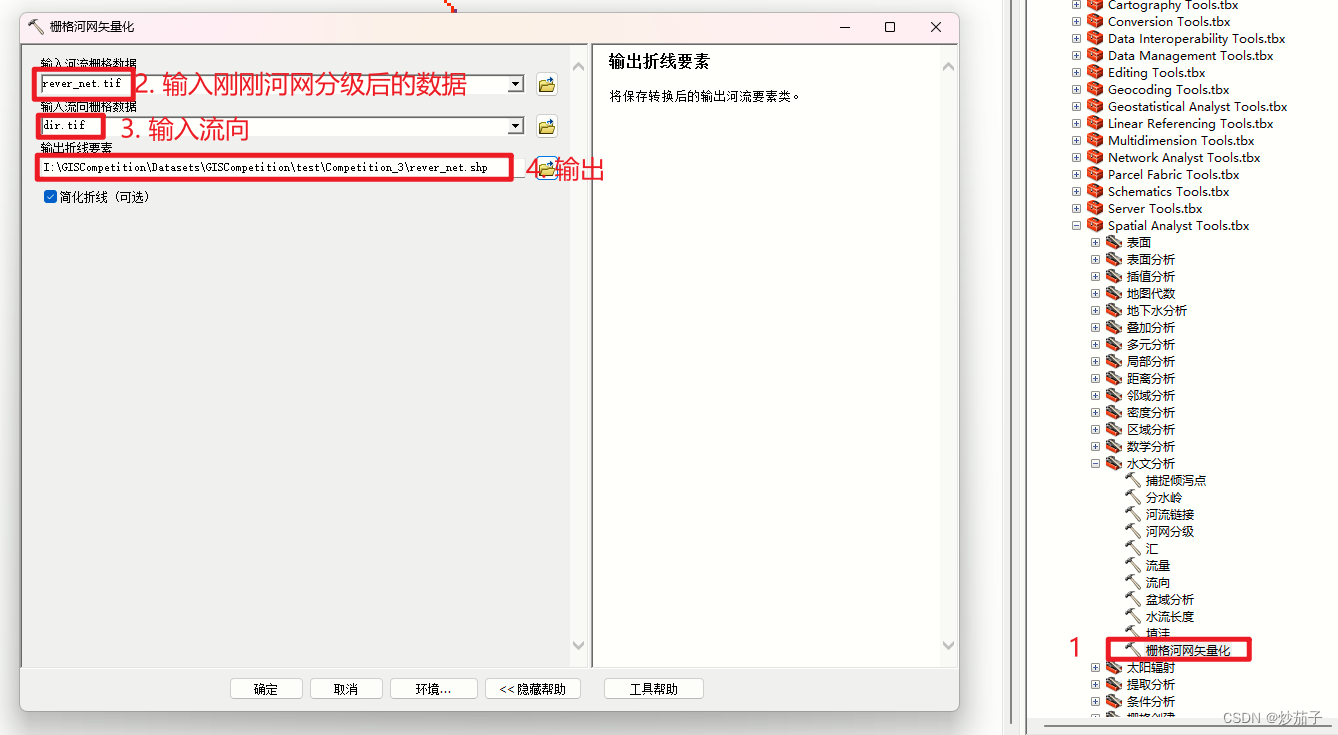
2.5 子流域提取和处理-思路
这一部分终究还是来了,最阿叉了。
2.6 子流域提取和处理-实操
2.6.1 子流域的提取
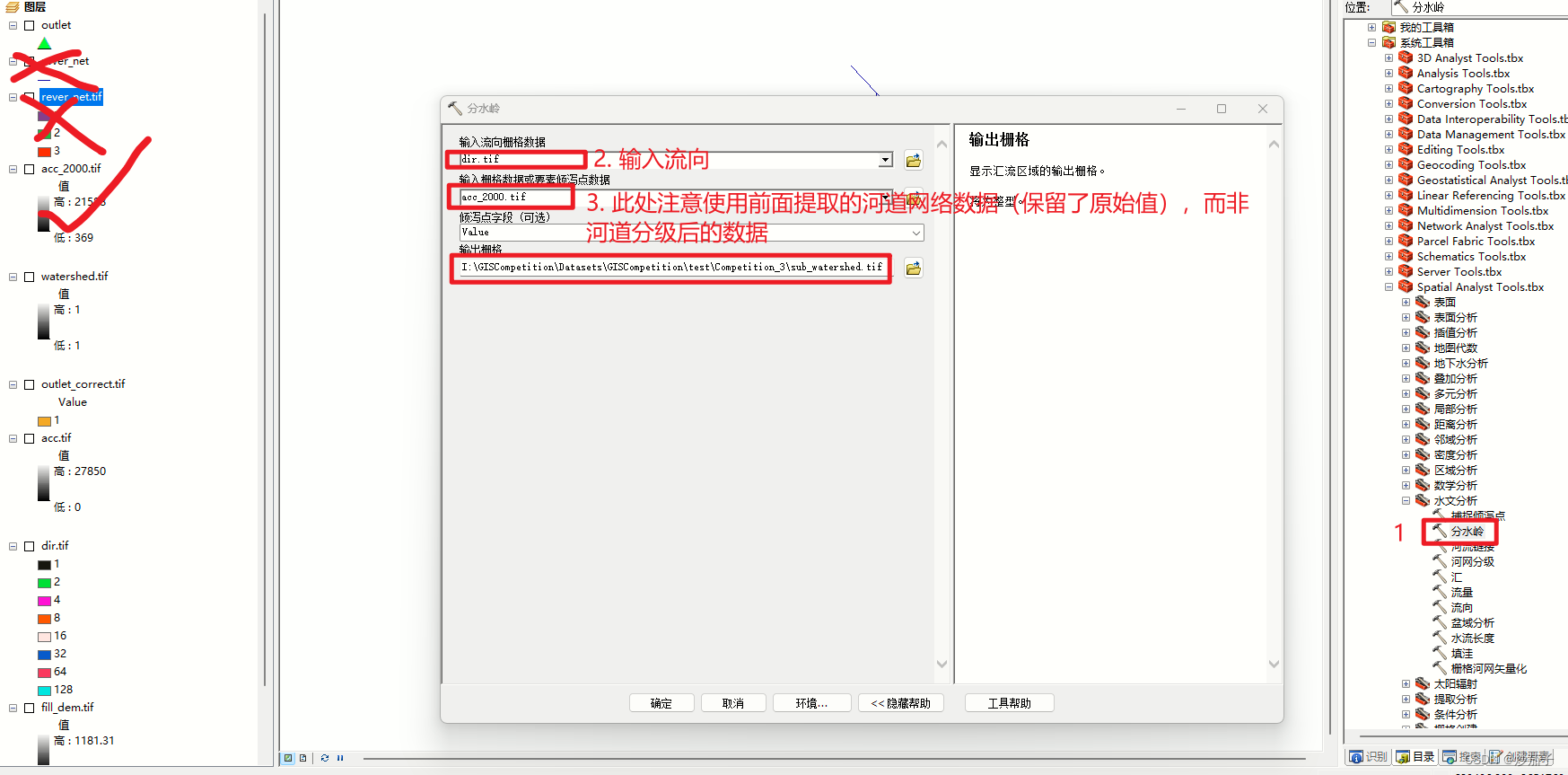
2.6.2 微子流域的处理
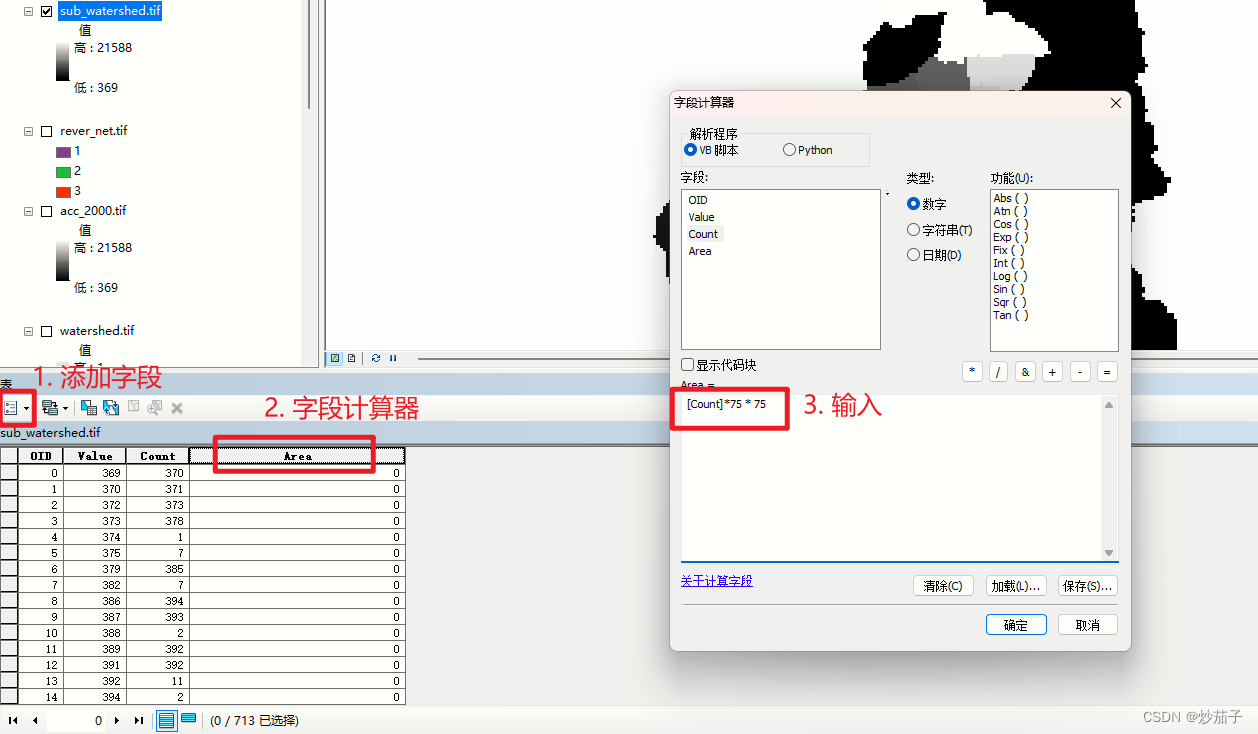
[Count]*75 * 75 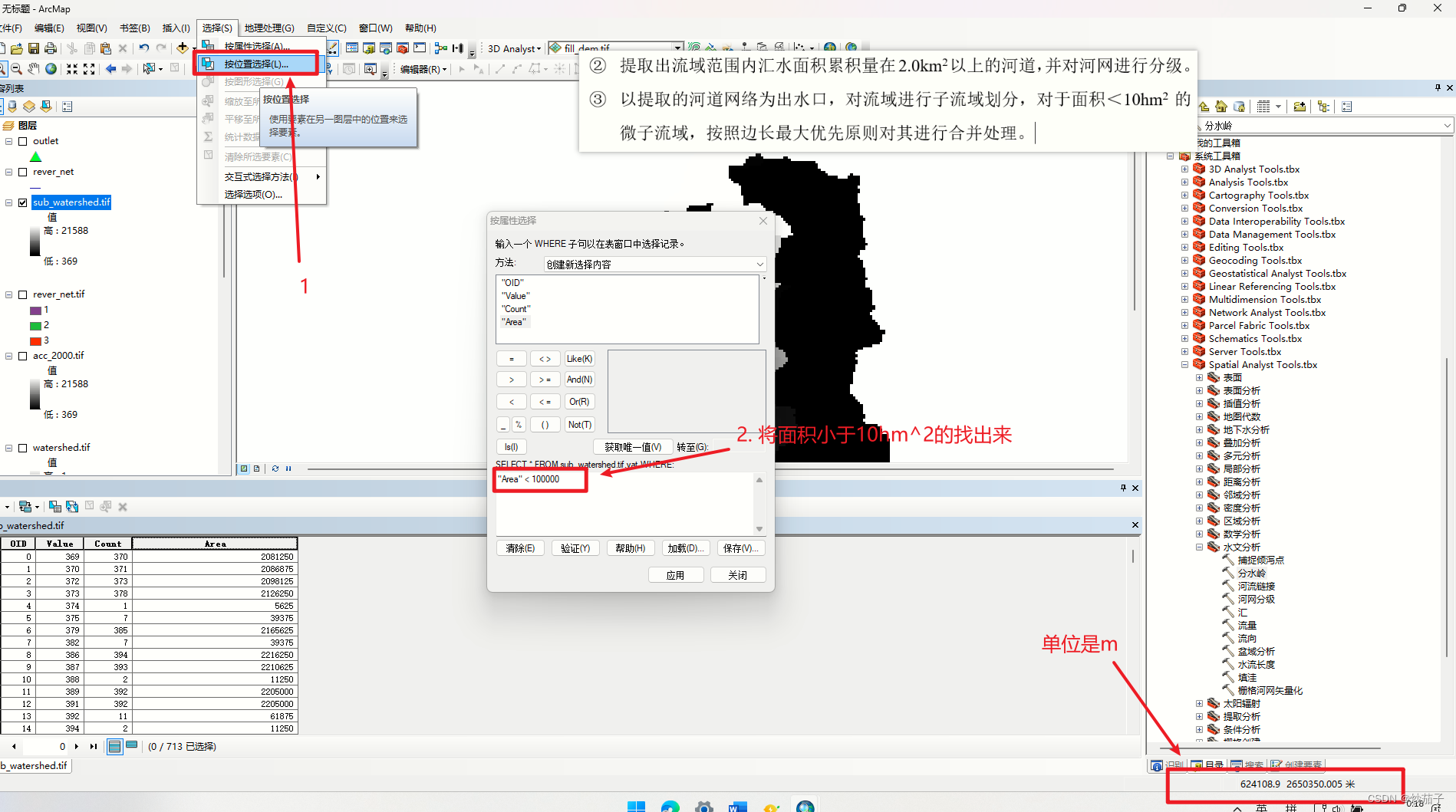
实际上,上面这里我还是存在一定的保留意见,我认为不是每一个像元都是75*75,因为这是投影坐标系(即便是地理坐标系也未必),所以存在变形这是很正常的。所以我们这样计算的面积可能是存在偏差了,所以我的意见是可以先将提取的子流域转矢量(我没试过,要素太多可能会比较卡),然后再在属性表中计算几何得到面积会更准确我个人觉得。
将刚刚提取的像素转化为矢量文件: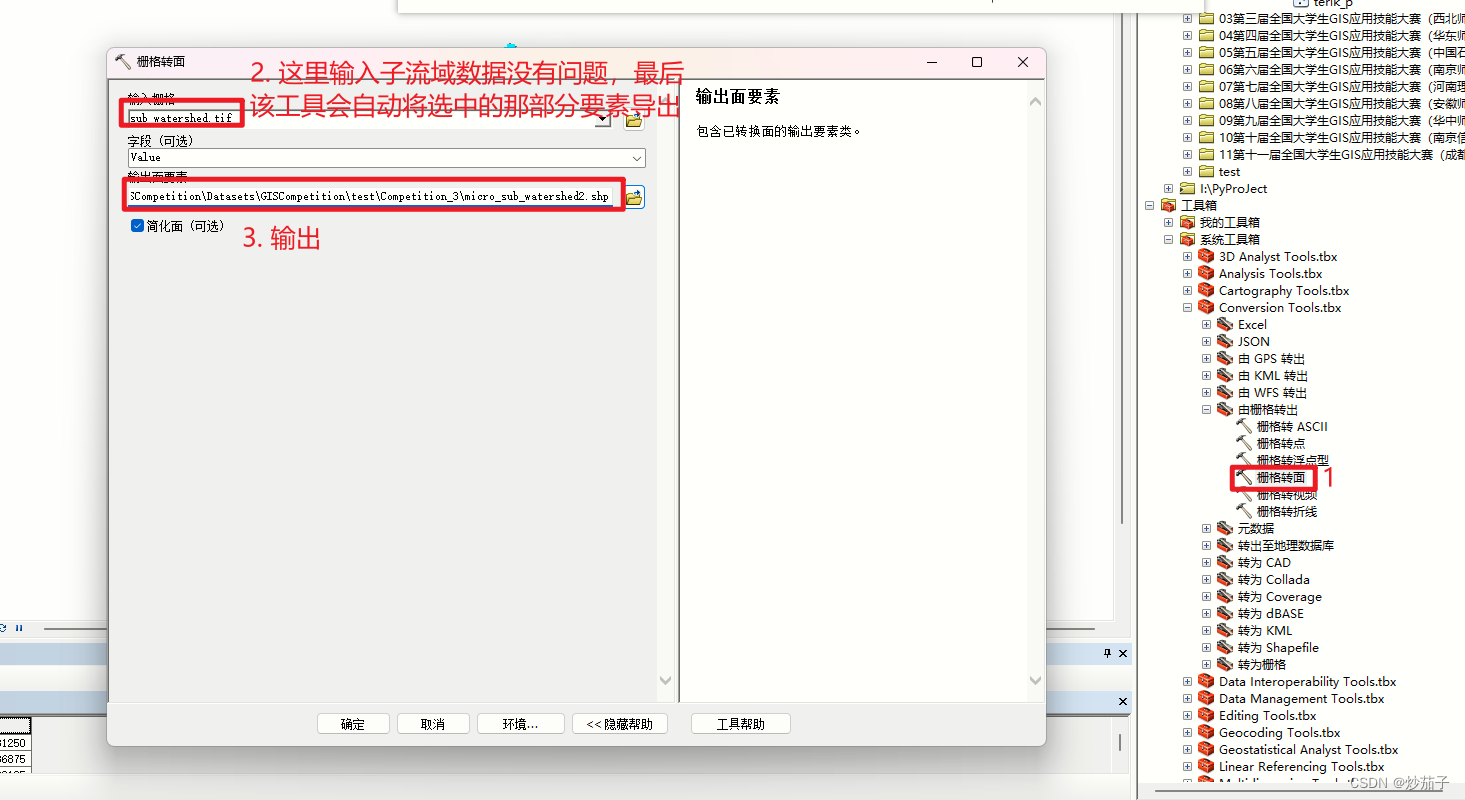
接着它要求按照边长最大优先原则对其进行合并处理,实际上就是保留边长最大的那个要素,其他要素都融合进该要素中(即该要素字段信息保留):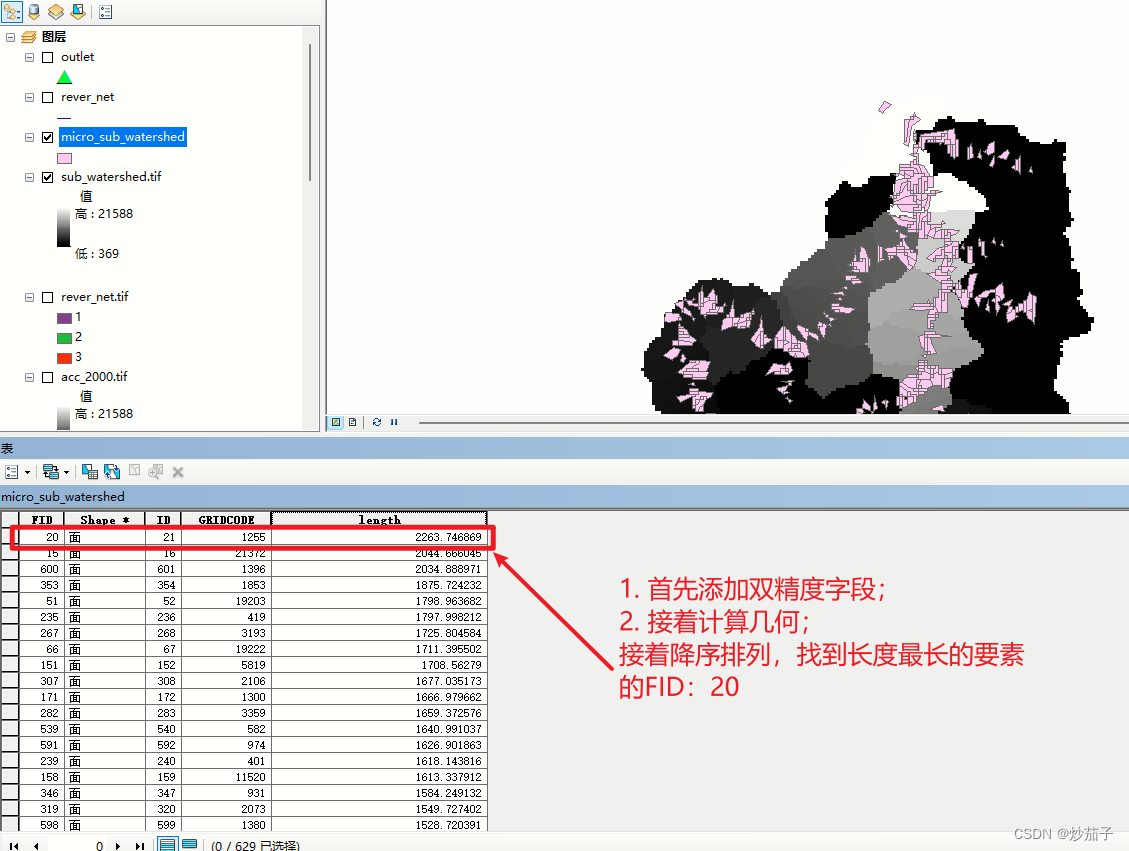
搞错了,记住ID=21!
合并: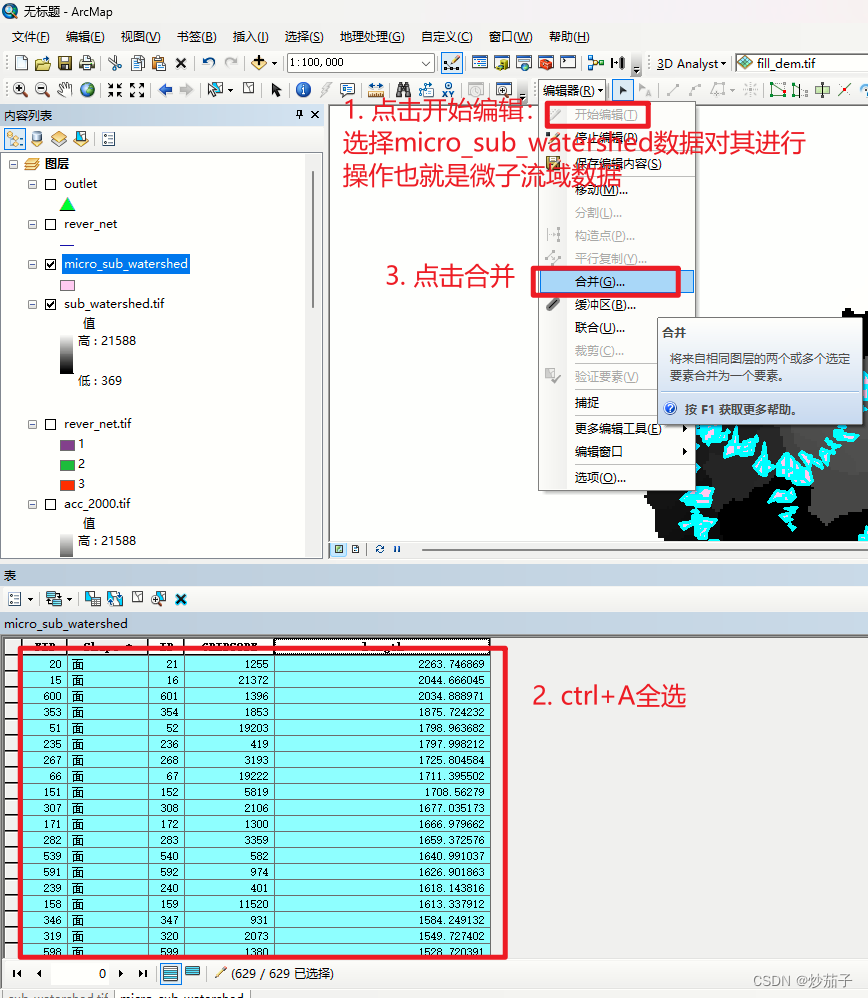
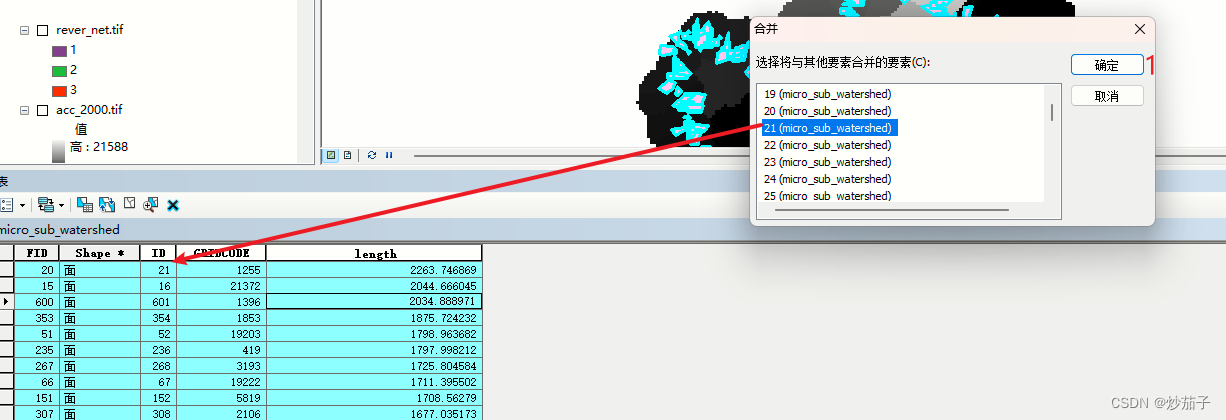
结果: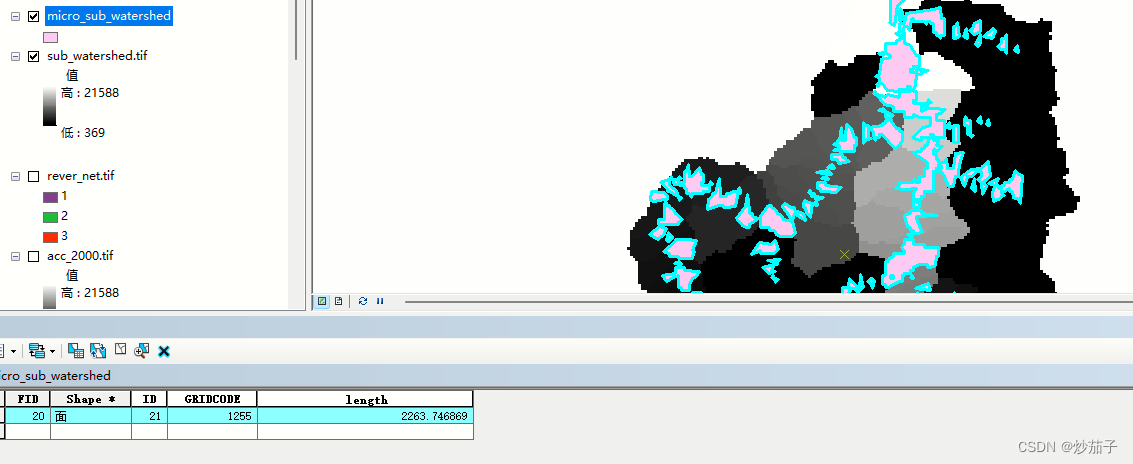
2.7 子流域地形特征统计-思路
这个其实也算简单,如果你可以想到的话。我一般看到这个就是想到了分区统计,因为它需要计算各个区域的一些统计值,另外这里不需要可视化仅仅是以表格形式进行统计,所以工具就十分明确了:以表格显示分区统计。
2.8 子流域地形特征统计-实操
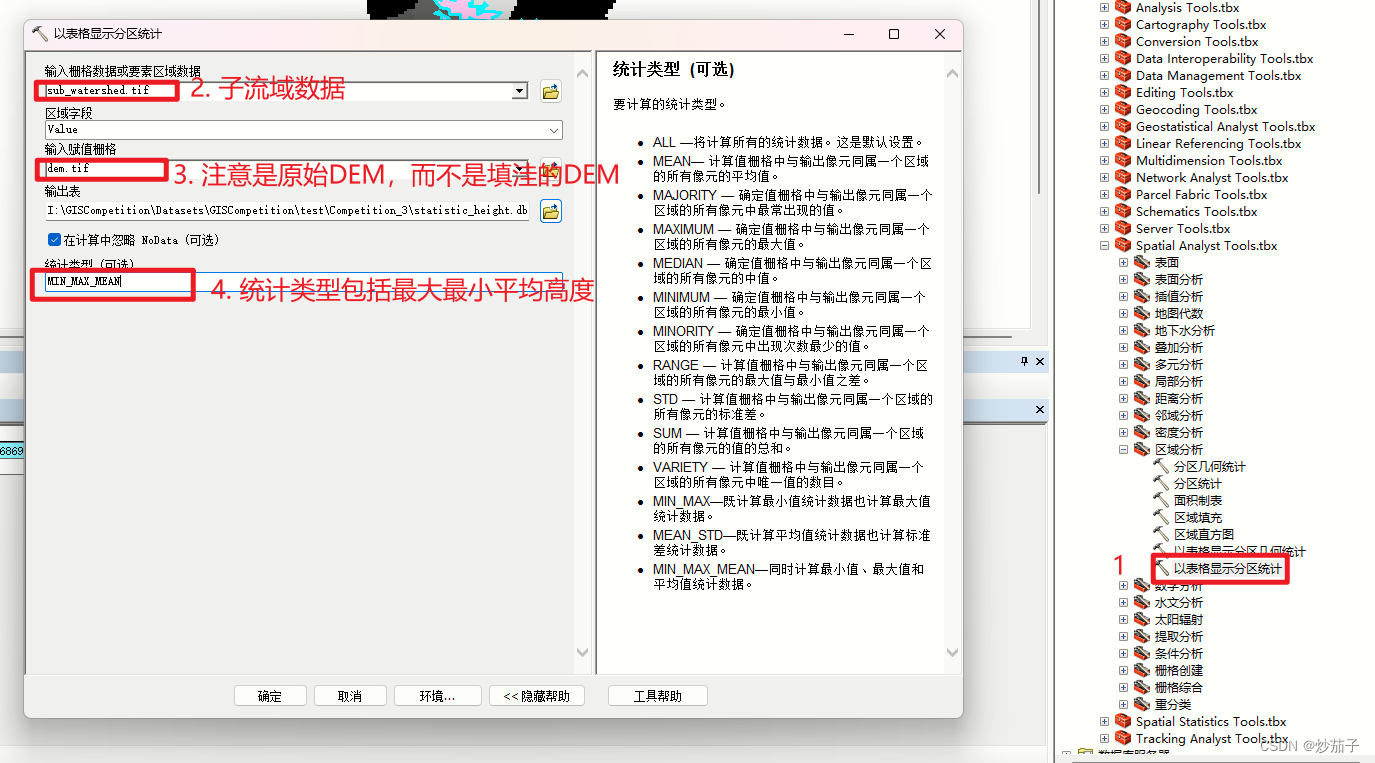
但是这里存在一些问题(似乎无法解决),就是子流域应该是同一地理位置或者说都聚在一块儿(我是这么理解流域的,不知道流域是否可以在这儿一块那儿一块分开),那么这里计算没有考虑到这种情况: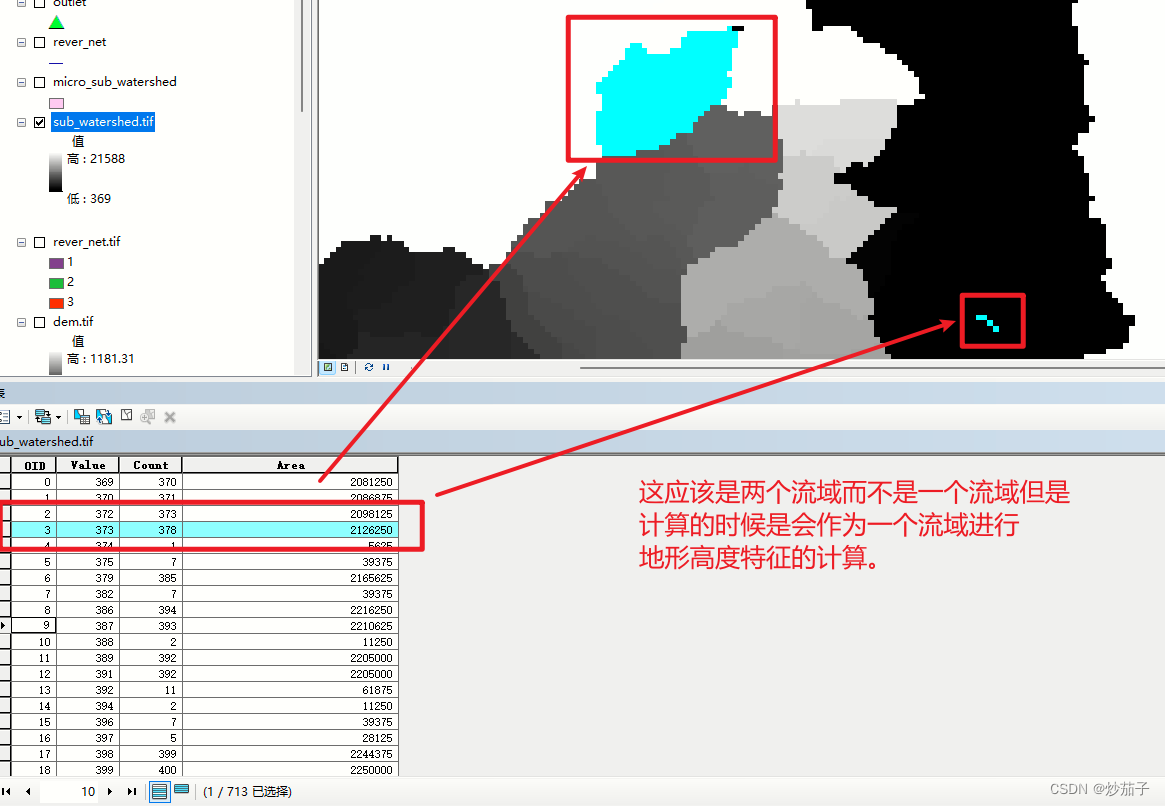
这篇关于ArcGIS: 第二届全国大学生GIS技能大赛(广西师范学院)详解-下午题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







