本文主要是介绍聊聊daos高性能分布式存储,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
-
现在大部分应用的IO模型会增加元数据和不对齐的数据碎片比例越来越大,同时传统的存储软件引入的对齐约束和通过大量延迟导致针对这些类型的IO应用越来越差的性能。大容量持久化内存(SCM)和高速硬件结构两者结合的,为重新定义存储规范和高效支持现在的IO密集型应用提供最佳的机会
-
基于SCM需要重新考虑完整的存储栈的设计,为了释放这些新硬件的性能,新的软件栈采用字节粒度无共享的接口,并且它能够支持大规模分布式存储。
DAOS是基于SCM和NVMe的全新的IO架构,通过fabric全局访问对象的地址空间,保证性能的前提下提供一致性、可用性、弹性分布式存储 服务。
传统并行文件系统限制
-
常规的并行文件系统是建立在块设备之上,IO的提交是通过内核的块接口;它们通过IO调度器优化磁盘的
seek操作、合并写等优化手段适配workload特性,然后发送大量数据流给磁盘驱动器来获得更高的带宽。但是随着新硬件3D-XPoint出现提供臂传统存储低几个数量级的低延迟,为机械盘设计的软件栈会成为这些新型存储很大的开销。 -
大部分并行文件系统都会去提供
RDMA的能力,比如从客户端的page cache把数据直接传输到服务端的buffer cache中,然后持久化 服务端的块存储上。由于在块设备IO和网络事件缺乏统一的poll的处理模型,IO的处理严重依赖中断和RPC的多线程并发处理,因此在IO处理过程中上下文的切换无法重新发挥网络低延迟的优势。传统并行文件系统的软件栈中包括cache/distribute lock依旧可以在3D NAND/3D-XPoint存储设备上使用,并且能获得更高的性能。
Daos软件 架构
-
Daos(Distribute Asynchronous Object Storage)是基于非易失内存(NVM)构建的一个开源自定义对象存储.daos提供key-value存储接口和提供non-bloking I/O、数据的多版本、快照等功能。 -
Daos存储系统充分利用了下一代的NVM技术,比如SCM(Storage Class Memory)和NVMe(NVM express).采用kernel bypass技术,端对端的运行在用户态,在执行IO操作期间不需要任何的系统调用。
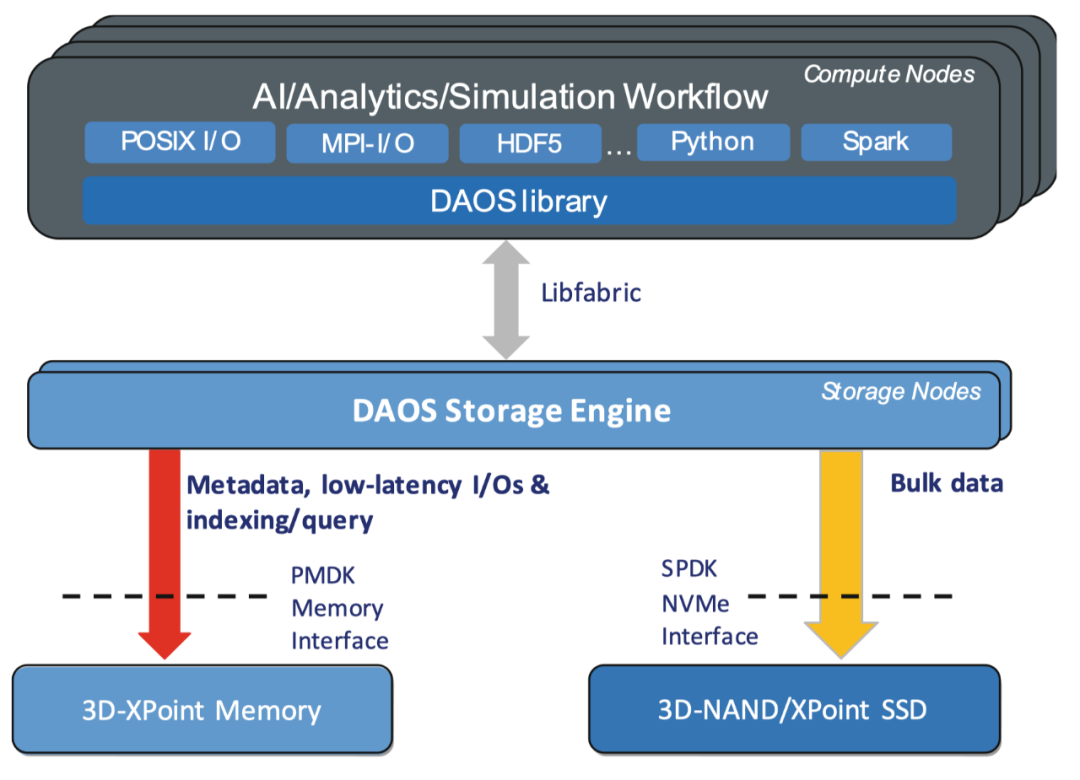
-
如上图所示,
Daos核心分为三个部分,它们分别是SCM和PMDK、NVMe和SPDK、libfabric.SCM和PMDK是第一部分,daos使用SCM来存储所有的元数据,应用的key索引和延迟敏感的小IO.daos在启动时候调用系统调用初始化持久化内存,比如启用DAX文件系统功能后映射持久化内存文件到虚拟内存地址空间。当系统启动运行后,daos可以在用户态通过内存指令访问持久化内存设备。持久化内存设备非常快,但是容量低、成本高,因此用来存储元数据非常合适;针对分布式存储中的数据,daos采用了NVMe设备,通过SPDK技术达到kernel bypass目的,IO的提交都是异步方式提交到SPDK的用户态队列,在SPDK IO完成后,在持久化内存中为这些数据创建索引。libfabric是daos的最后一个部分,它主要负责高性能的网络,比如支持Omni-Path/IB等网络架构。libfabric是一个定义在用户态的库,同时给使用它的应用导出fabric通信服务,它提供基于消息的异步API包括数据传输、网络的poll 等功能。 -
daos基于新硬件和网络技术,运行在用户态的kernel bypass分布式存储,它目前支持SCM和NVMe,不支持机械磁盘。 -
daos是一个基于C/S的模型,daos client是一个linrary可以整合到应用中,它和应用运行在同一个地址空间。daos server是一个多容错的daemon进程,它直接访问SCM和NVMe,所有的metadata和小io存储在SCM中,大IO存储在NVMe中。daos server不依赖于pthread来处理并发的IO请求,而是采用用户级别的线程User Level Thead(ULT)来处理。
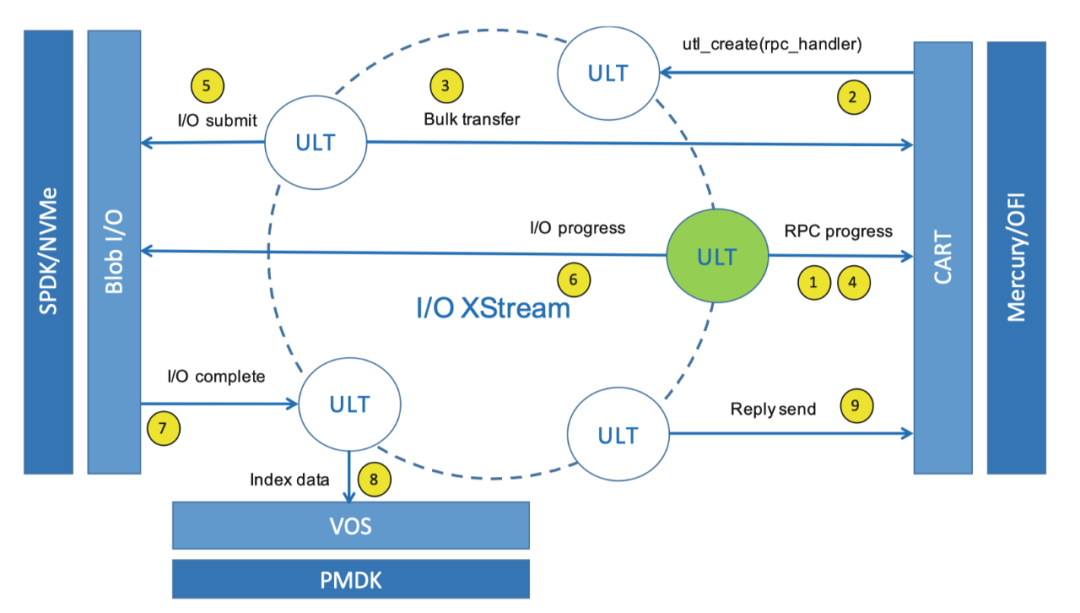
Daos数据存储策略
-
daos存储导出对象的形式提供key0-value或者key-array的api形式提供给用户访问。为了避免扩展性问题和维护元数据(比如对象的layout用来描述对象数据的位置)的开销,daos中的对象是128bit来标识对象的唯一性,同时在128bit中也包含编码用来描述数据的分布和数据保护策略(是副本还是ec)等信息。daos根据存储池配置生成随机数生成对象的layout.这个优点像ceph的crush算法。
-
daos server中的用于元数据存储的SCM直接和内存总线连接,用于数据存储的NVMe直接连接到PCIe.采用内存的load/store指令来访问内存映射的SCM,然后使用SPDK API在用户态访问NVMe。一旦SCM或者是NVMe出现硬件故障,会存在数据或者元数据的丢失,为了保证数据丢失,daos提供replication或者erasure coding方式来保护数据和恢复数据。当启用了数据保护的功能,daos object会被replicate或者chunked 为多个数据分片和数据校验分片,然后存储在不同的存储节点,一旦出现硬件故障或者节点故障,daos object出于降级模式但是依然可以访问,数据恢复是是从其他的副本或者校验数据进行恢复。
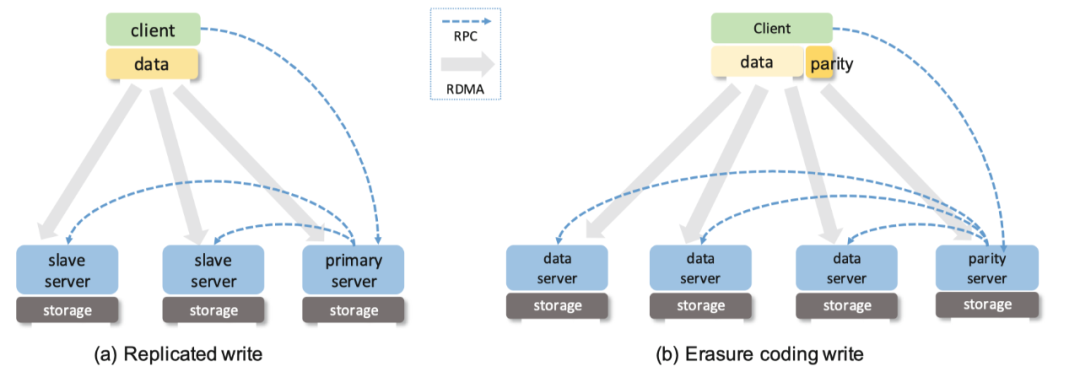
-
replication提供比较高的数据冗余,daos采用了primary-slave协议进行写操作,primary replica负责接受请求进行写,然后primary replica转发请求给slave replica进行分布式事务的处理。primary-slave模型 不同于传统的副本模型。primary replica仅仅转发rpc到slave server.所有的副本节点请求都是通过RDMA方式,从对端的客户端的buffer中直接获取数据。daos采用了两阶段提交协议的变种协议,如果一个副本不能应用变更,则所有的副本则通知更新。如果server处理副本写出现节点失败,daos则会从事务中排除这个节点,然后通过算法选择一个不同正常节点作为替代节点,然后把之前的事务状态赋给这个正常节点。如果这时候失效的节点有恢复正常,它会根据数据恢复协议捕获到事务的状态,同时忽略本地的事务状态。daos中健康检查失效节点时间,它会报告到基于多节点的daos-server的raft的协议服务,server中的raft服务会扫描object id,计算每个对象的layout,然后找出所有受影响的obejcts;把这些受影响的objet id发送给算法算则的应急server.应急节点通过pull方式重其他副本重建这些受影响的数据。 -
Erasure Coding提供更加节省空间和提供空间利用率的数据保护策略。daos client是一个轻量级的库,整个到进程中,因此数据的EC编码是在客户端进行的,那么客户端进程所在节点会消耗更多的cpu资源。daos client计算数据的校验码,创建数据分片和数据校验块RDMA Destriptor,然后发送一个RPC请求给校验组的leader server来协调写操作,这种写操作和副本的写类似,参与ec写操作节点直接从客户端buffer中获取数据,daos ec也是采用二阶段提交协议保证数据在不同节点的原子写入。当写入数据不等于stripe_size,大部分存储系统会通过read/encode/write处理来保证数据分片和数据校验的一致性,这个操作代码非常大(放大问题导致),同时需要一个分布式锁来保证读写的一致性。但是在daos中,为了避免这种开销,采用了Multi-version data module,通过复制部分写数据到 parity server的方式,因此parity server容易通过副本数据计算parity 数据。当在读的过程中,有节点失效,daos会提供降级读,daos client会首先获取所有的数据的stripe信息来重建已经丢失的数据,采用两阶段提交协议,把事务传递给正常的sever节点,然后进行丢失数据的数据重建。 -
daos中有三种失效情况,第一种是服务崩溃,daos通过gossip-like协议SWIM处理;第二种是NVMe失效,daos使用SPDK来polling设备的状态来判断;第三种是存储介质的失败,daos会探测并且保存和验证校验码来保证。当server接受到写请求,server核实校验码或者存储校验码和数据。server端可以根据性能的需求开启或者关闭核实功能。当应用再次回来读数据,如果读数据是和之前写数据是对齐的,server直接返回数据和校验码;否则daos server核实涉及读操作的数据块的校验码,然后计算出读取数据的校验码,然后返回数据和校验码给客户端。如果daos客户端在读的过程中检查到校验码错误,它会开启降级读或者切换其他的副本读或者在客户端进行数据重建(ec模式)。客户端也会报告校验码错误给server。server会通过探测和校验收集所有校验码错误,然后进行vefify和scrubbing,也会报告给客户端。
Daos 数据模型
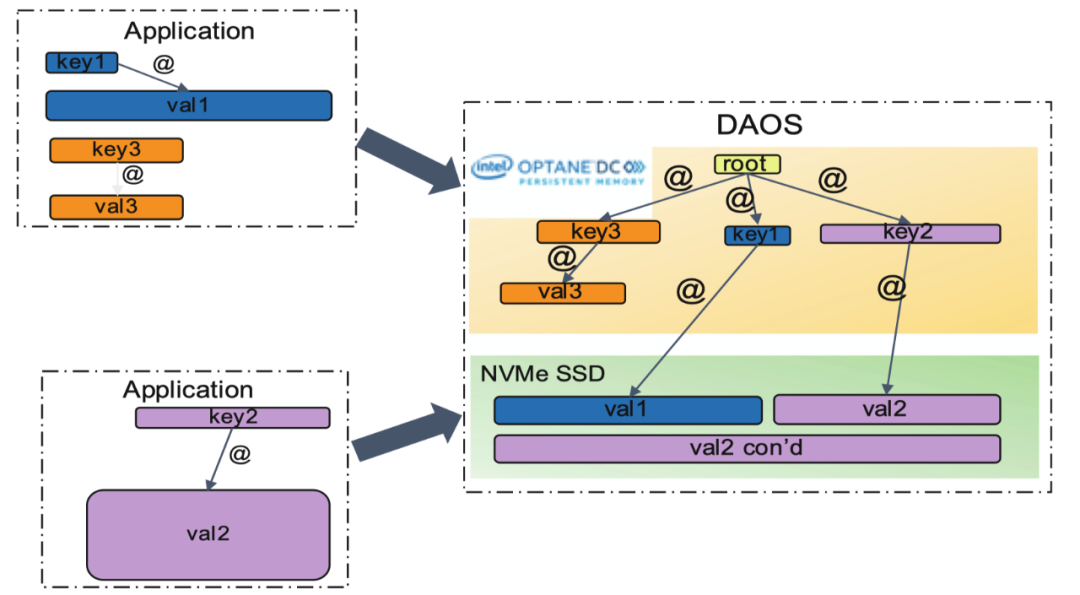

-
daos数据模型包含了两种不同的对象形式,一种是array objects允许应用呈现多维度的数组形式;另外一种是key/value来存储对象数据,这种方式提供kv的接口和multi-level的kv接口。不论是那种形式,数据对象都是有版本的,这允许应用可以轻松的回滚到之前的版本数据。每个object是属于一个域(daos container).每个container都有私有的对象地址空间,事务的处理在poll中的其他container也是相互独立的。
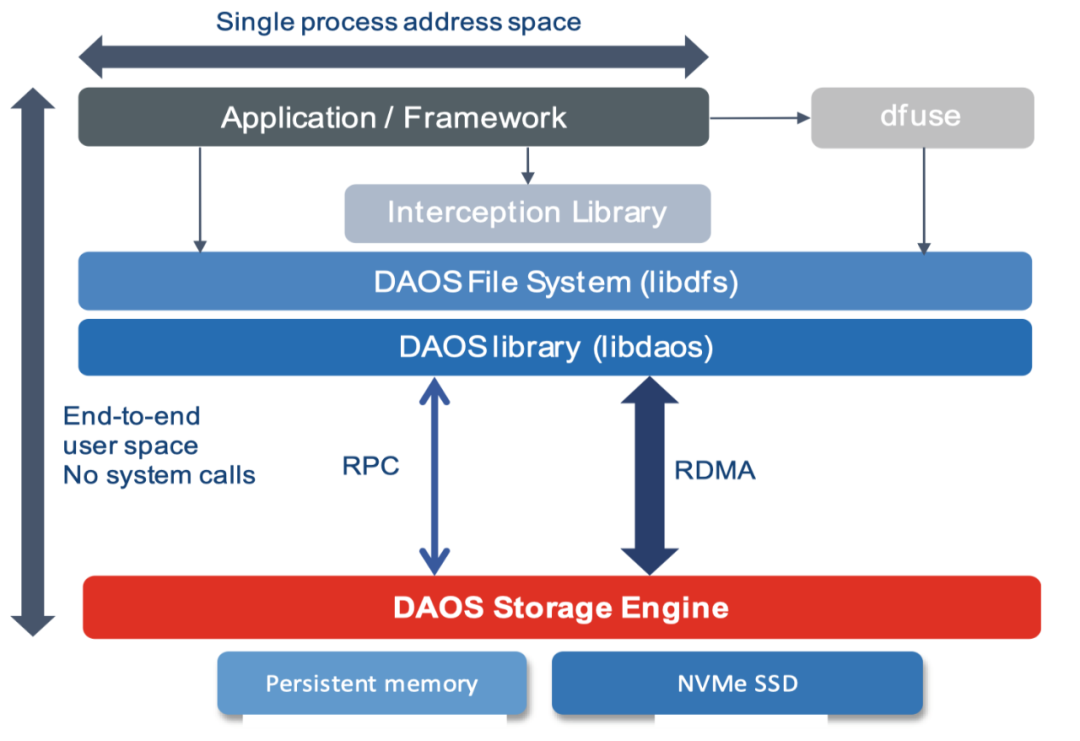
-
daos支持posix语义的访问,posix并不是daos的存储模型的功能,而是在daos后端api构建的库,一个posix文件系统的命名空间是在daos container中.posix api是通过fuse驱动使用daos引擎api(libdaos)和daos文件系统api(libdfs)来访问数据。
这篇关于聊聊daos高性能分布式存储的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






