本文主要是介绍Hazelcast系列(三):hazelcast集成(服务器/客户端),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
系列文章
Hazelcast系列(一):初识hazelcast
Hazelcast系列(二):hazelcast集成(嵌入式)
Hazelcast系列(三):hazelcast集成(服务器/客户端)
Hazelcast系列(四):hazelcast管理中心
Hazelcast系列(五):Auto-Detection发现机制
Hazelcast系列(六):Multicast发现机制
Hazelcast系列(七):TCP-IP发现机制
Hazelcast系列(八):数据结构
目录
前言
环境
服务器
客户端
测试
其他
参考
前言
前面对通过 Hazelcast系列(二):hazelcast集成(嵌入式)已经对 Hazelcast 如何在 Java 中使用,已经有了初步的认识,接下来,咱们研究一下 Hazelcast 集成的另外一种模式:服务器/客户端 。
相较于 嵌入式 的模式,服务器/客户端 模式将 Hazelcast 缓存服务和客户端单独拆分开,方便后期对服务器的单独维护和持续扩展,避免缓存的数据在堆内存中影响到垃圾收集器收集效率和垃圾回收时的应用响应时间。
当前 Hazelcast 服务器版本:4.2.6,客户端版本:5.1.7。
环境
| 名称 | 版本 |
| hazelcast/management-center 管理中心 | 5.3.0 |
| hazelcast/hazelcast 服务端 | 4.2.6 |
| springboot | 2.7.16 |
| hazelcast 客户端 | 5.1.7 |
服务器
服务器端通过 Docker 部署,Docker 的安装和配置可以参照俺的 CentOS 7下安装Docker,部署采用版本 hazelcast/hazelcast:4.2.6。
- 首先拉取 hazelcast 的镜像
docker pull hazelcast/hazelcast:4.2.6- 添加一个配置文件 hazelcast.yaml,配置服务器集群中成员的相关参数,然后放在某个目录下,这里为 /home/hazelcast/config
hazelcast:cluster-name: hazelcast-clusterinstance-name: hzInstance_141network:port:auto-increment: trueport-count: 100port: 5701outbound-ports:- 0join:auto-detection:enabled: falsemulticast:enabled: falsemulticast-group: 224.2.2.3multicast-port: 54327tcp-ip:enabled: truemember-list:- 192.168.119.141说明: cluster-name 集群名称,通过名称隔离同网络下的集群
instance-name 服务器节点名称
network.port.auto-increment 成员节点使用的端口是否允许自动增长
network.port.port-count 使用端口增长的范围,例如这里:5701-5801
network.port.port 默认使用的端口,如果 auto-increment 为false,则必须使用 5701
network.outbound-ports 套接字绑定期间使用的临时端口,可以是值和范围,0为没限制
network.tcp-ip.enabled 采用 tcp/ip 的方式,前面两个发现方式必须设置为 false
network.tcp-ip.member-list 集群中能被发现的成员,可以只配置一个,端口可不设置
- 通过 docker run 命令,启动容器名称为 hazecast-node1 的节点1
docker run -d -p 5701:5701
-e JAVA_OPTS="-Dhazelcast.config=/opt/hazelcast/config_ext/hazelcast.yaml"
-e HZ_NETWORK_PUBLICADDRESS=192.168.119.141:5701
-v /home/hazelcast/config:/opt/hazelcast/config_ext
--name hazecast-node1 hazelcast/hazelcast:4.2.6说明:-e 为添加执行的环境变量
-e JAVA_OPTS="-Dhazelcast.config=/opt/hazelcast/config_ext/hazelcast.yaml" 添加 hazecast 的寻找配置路径
-e HZ_NETWORK_PUBLICADDRESS 添加集群中成员的公共地址,方便私有云映射
-v /home/hazelcast/config:/opt/hazelcast/config_ext 挂载本地 hazelcast.yaml 所在配置 目录到容器中
--name 容器名称,节点名称
另外:192.168.119.141 为虚拟机地址,这里看情况配置对外公共地址
- 接下来,继续通过 docker run 命令,启动容器名称为 hazecast-node2 的节点2
docker run -d -p 5702:5701
-e JAVA_OPTS="Dhazelcast.config=/opt/hazelcast/config_ext/hazelcast.yaml"
-e HZ_NETWORK_PUBLICADDRESS=192.168.119.141:5702
-v /home/hazelcast/config:/opt/hazelcast/config_ext
--name hazecast-node2 hazelcast/hazelcast:4.2.6说明:参数说明参考上面的
hazecast-node2 和 hazecast-node1 对比,对外端口不同
- 服务器端这样差不多就启动了,通过搭建管理中心Hazelcast系列(三):hazelcast管理中心,我们可连接到对应集群查看,当然查看本地日志和获取本地集群数也可以确认

客户端
客户端配置和前面配置 Hazelcast系列(二):hazelcast集成(嵌入式)大同小异,咱们直接开干。
- 创建一个SpringBoot项目,先添加依赖,这里额外添加 spring-boot-starter-web 依赖方便测试
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>com.hazelcast</groupId><artifactId>hazelcast</artifactId></dependency>- 项目 resources 下添加 hazelcast-client.yaml 配置文件,内容如下:
hazelcast-client:cluster-name: hazelcast-clusterinstance-name: hzInstance_clientnetwork:cluster-members:- 192.168.119.141
说明:cluster-name 要连接的集群名称
instance-name 客户端节点名称
network.cluster-members 连接的集群成员,这里可配置一个,但是尽量全部配置
- 对应的 application.yml,内容如下
server:port: 8082
- 添加额外的测试代码
@RestController
@RequestMapping("/data")
public class DataController {@Autowiredprivate HazelcastInstance hazelcastInstance;private ConcurrentMap<String,Long> retrieveMap() {return hazelcastInstance.getMap("map");}@PostMapping("/put")public String put(@RequestParam(value = "key") String key, @RequestParam(value = "value") Long value) {retrieveMap().put(key, value);return "成功";}@GetMapping("/get")public Long get(@RequestParam(value = "key") String key) {Long value = retrieveMap().get(key);return value;}
}- 接下来,直接启动SpringBoot项目,然后去管理平台查看对应的客户端连接情况(本地查看日志亦可)

测试
前面在客户端已经连接上了服务器,并且客户端已经有了测试代码,下面,开测。
- Postman 发送测试数据 key = test,value = 11111
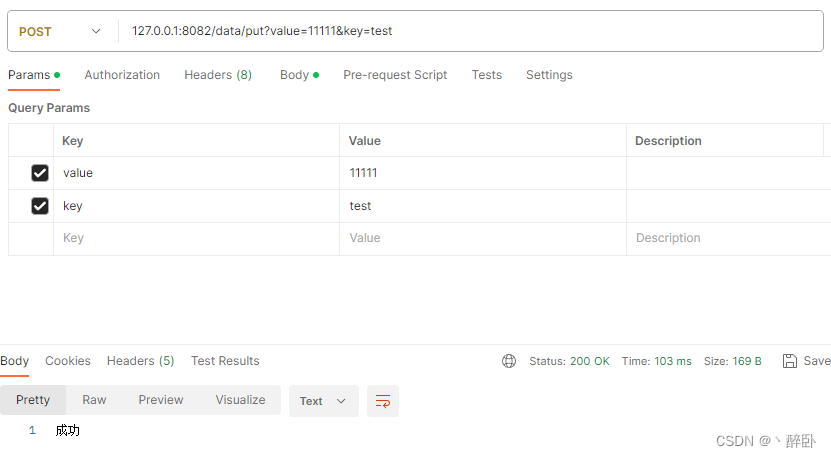
- Postman 获取数据 key = test
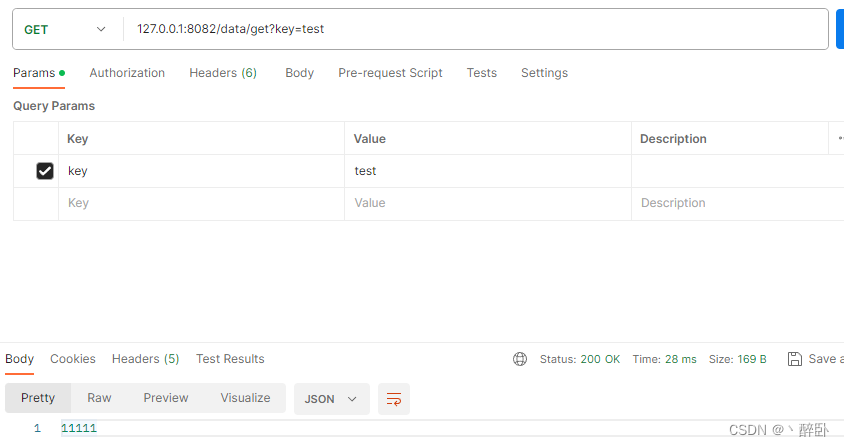
其他
- 服务器端 Docker 启动的时候,-e 添加的 hazelcast 环境变量也可配置在 Hazelcast 中,同理,hazelcast.yaml 的参数也可配置在 -e 环境变量上
- 每个版本的 hazelcast.jar 中,都有完整的或者默认的服务器和客户端参数配置
参考
- Java Client
这篇关于Hazelcast系列(三):hazelcast集成(服务器/客户端)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


