本文主要是介绍Hadoop2.0探讨,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 8. Hadoop 再探讨
- 8.1 Hadoop的优化与发展
- 8.2 HDFS 的FA和Federation(Hadoop2.0新特性)
- 8.2.1 HDFS HA
- 8.2.2 HDFS Federation
- 8.3 YARN
- 8.3.1 MapReduce1.0的缺陷
- 8.3.2 Yarn设计思路
- 8.3.3 Yarn体系结构
- 8.3.4 Yarn工作流程
- 8.3.5 Yarn框架和MapReduce1.0框架对比分析
- 8.3.6 Yarn框架的发展目标
- 8.4 Hadoop生态系统中具有代表性的组件
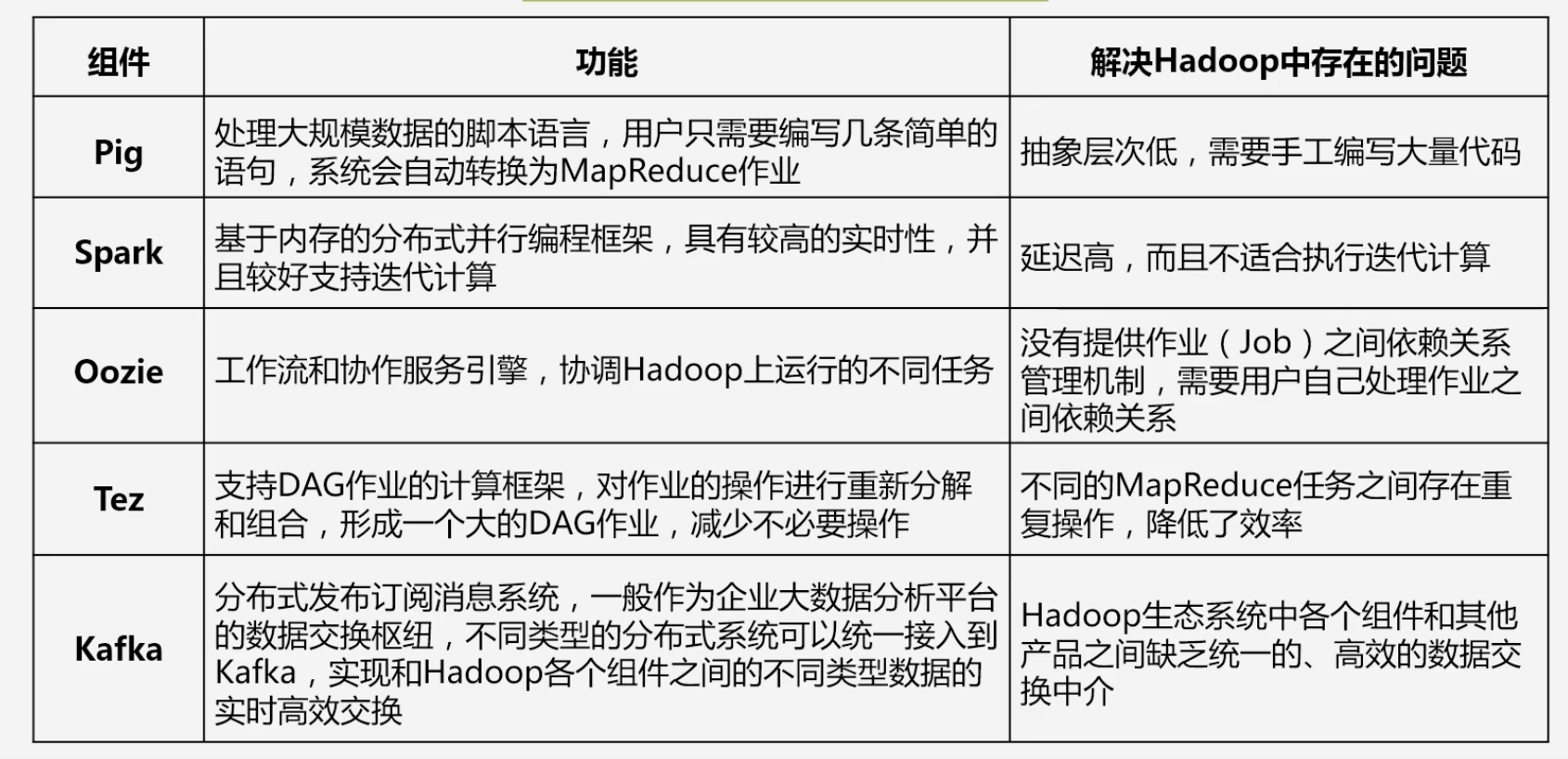
- 8.4.1 Pig
- 8.4.2 Tez
- 8.4.3 Spark和Kafka
8. Hadoop 再探讨
8.1 Hadoop的优化与发展
-
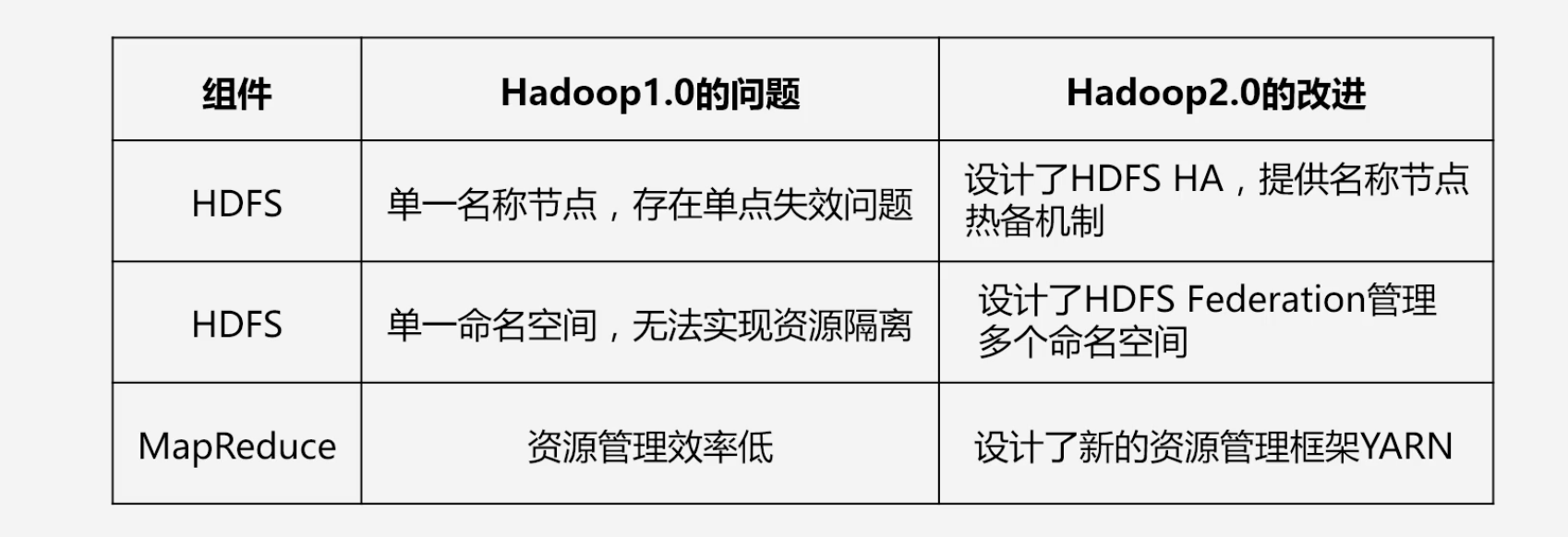
Hadoop1.0的局限和不足
- 抽象层次低,需人工编码:编写一个非常简单的代码都需要人工编写MapReduce代码,进行编译打包运行
- 表达能力有限:现实中的一些问题不是使用Map和Reduce就能完成的
- 开发者需要自己管理作业(Job)之间的依赖关系:多个MapReduce任务之间的前后关系需要人工管理
- 难以看到程序整体逻辑
- 执行迭代操作效率低:每次迭代都需要将结果先写入到HDFS中,下一个MapReduce任务再从HDFS中读取数据
- 资源浪费:整个任务执行过程中Map任务结束之后才能进行Reduce任务,导致Reduce一直处于空闲状态
-
Hadoop2.0的优化与发展
- Hadoop自身两大核心组件,MapReduce和HDFS的架构设计改进
- Hadoop生态系统其他组件的不断丰富,包括Pig、Tez、Spark和Kafka等
-
Hadoop1.0到Hadoop2.0对比
-
不断完善的Hadoop生态系统
8.2 HDFS 的FA和Federation(Hadoop2.0新特性)
8.2.1 HDFS HA
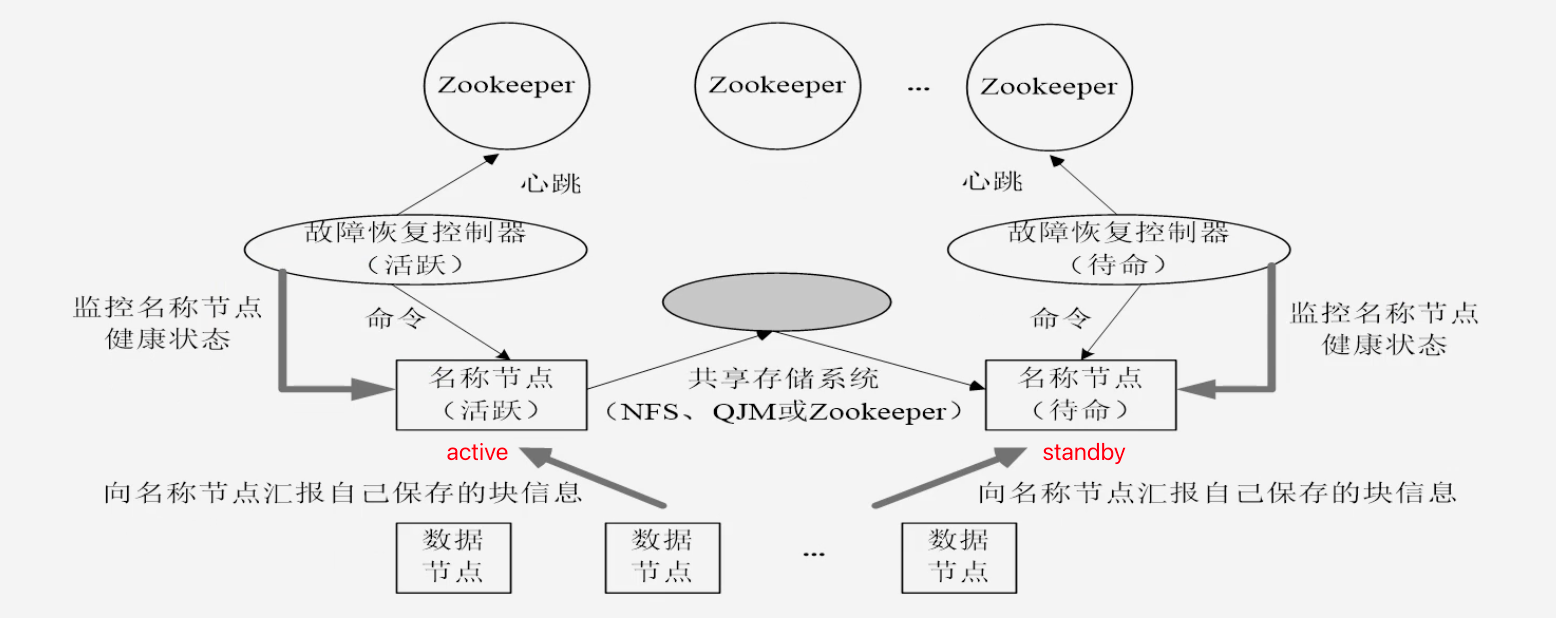
-
整体结构
- 名称节点发生故障,则立即切换到待命节点
- 共享存储系统保证(活跃)名称节点和(待命)名称节点的中保存信息的同步
- 共享存储系统将活跃节点的Editlog不断的同步到待命节点
8.2.2 HDFS Federation
-
HDFS1.0中存在的问题
- 单点故障问题:通过HA解决
- 不可以水平扩展 :纵向扩展如加内存可能导致启动时间过长
- 系统整体性能受限于单个名称节点的吞吐量:一秒钟可以接入多少外部节点还是由外部节点决定的
- 单个名称节点难以提供不同程序之间的隔离性:一个程序消耗的资源非常大,可能导致另外的程序无法运行
- HDFS HA是热备份,提供高可用性、但是无法解决可扩展性、系统性能和隔离性
-
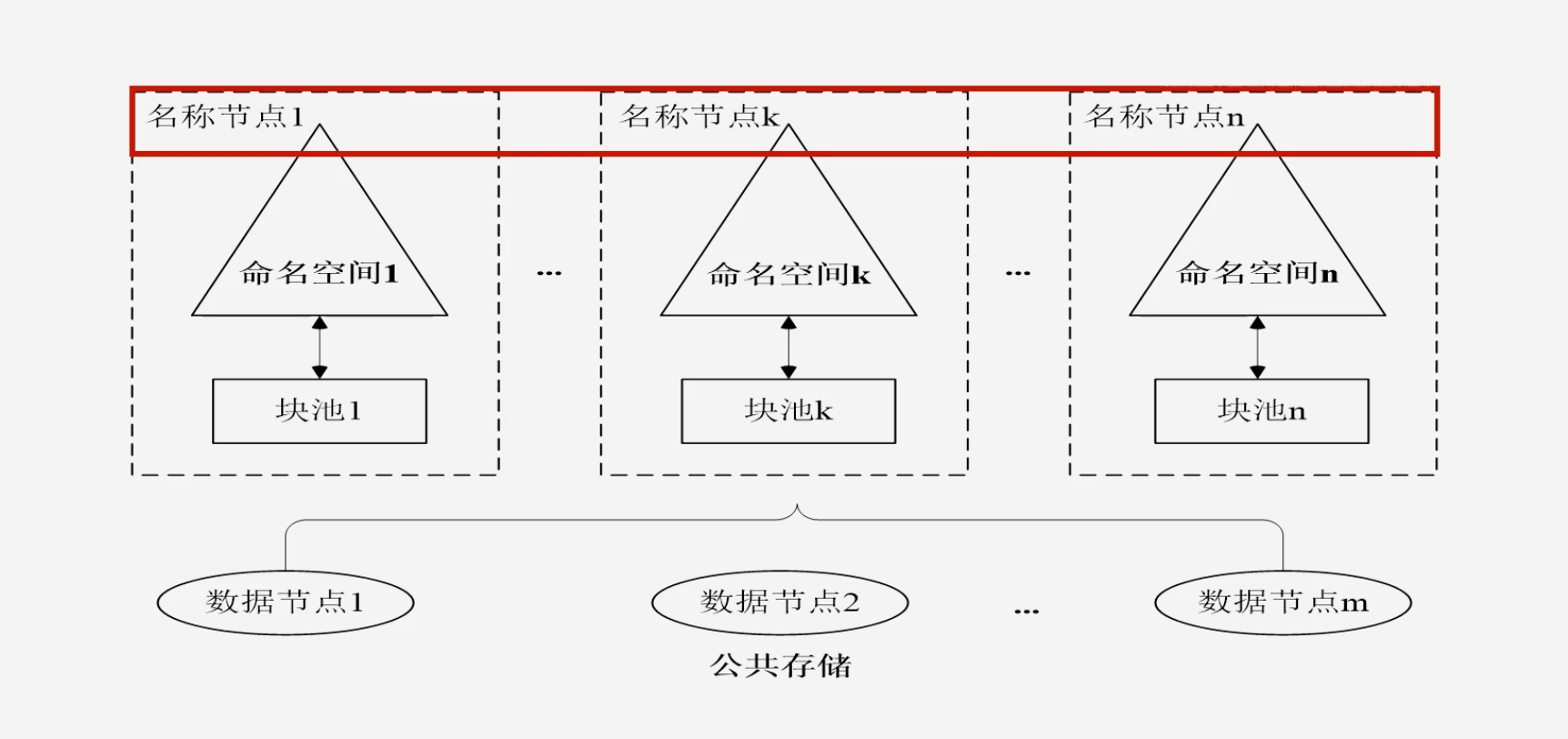
HDFS Federation架构
-
提供多个名称节点,由用户设置,名称节点之间彼此独立
-
Federation提供了向后的兼容性:单名称节点的应用程序可以无缝迁移到多名称节点
-
所有的名称节点共享底层的数据节点
-
通过用户挂载不同的命名空间,使用不同的名称节点,用户可以看到一个全局命名空间挂载表,用户可以看到每个子命名空间
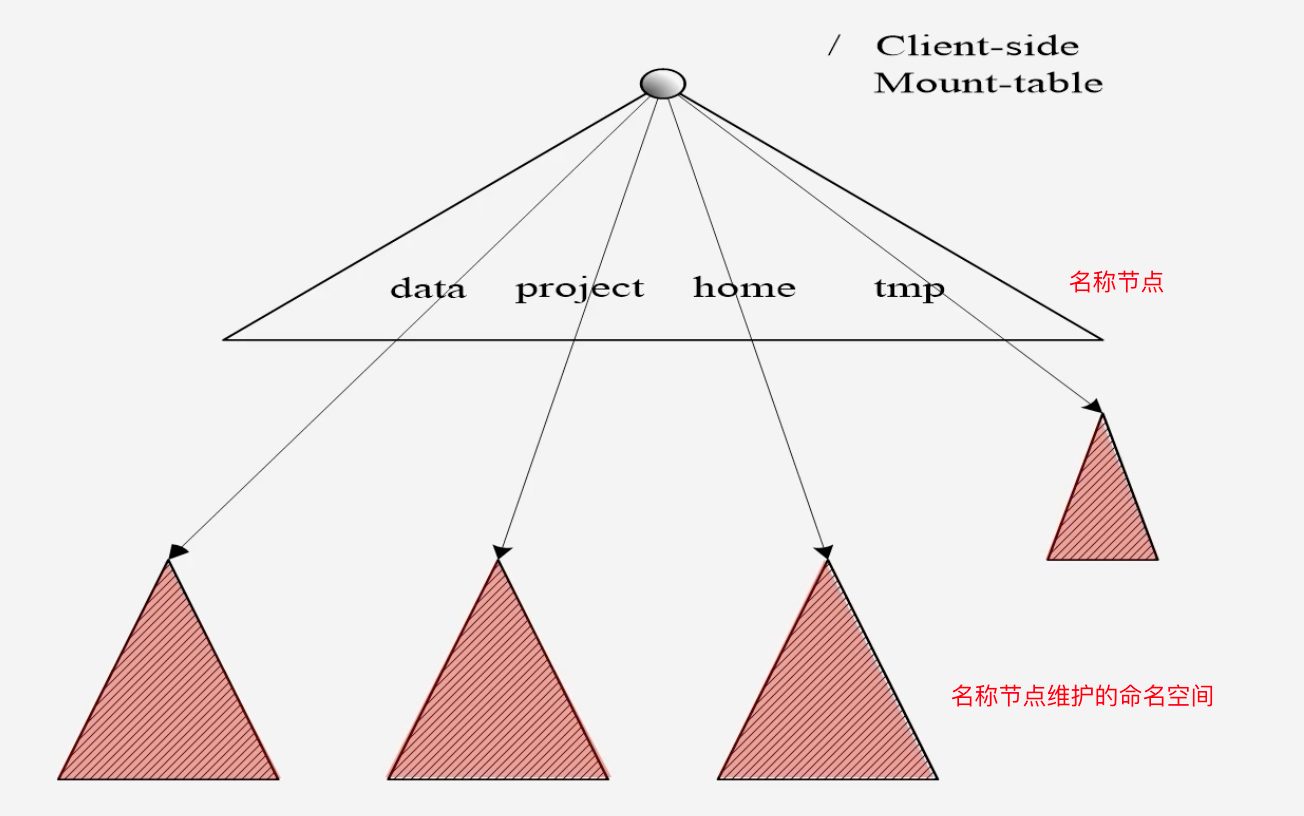
-
-
HDFS Federation设计可解决单名称节点存在的问题
- 集群扩展性问题:多个名称节点,每个名称节点可以独立的管理一个目录,让一个集群可以扩展到更多空间去
- 性能更高效:多个名称节点各自管理数据,而且可以同时提供对外服务
- 良好的隔离性:不同数据分给不同的名称节点去管理,有效的对应用程序进行隔离
8.3 YARN
8.3.1 MapReduce1.0的缺陷
-
缺陷
-
存在单点故障:只有一个JobTracker负责整个作业的管理调度
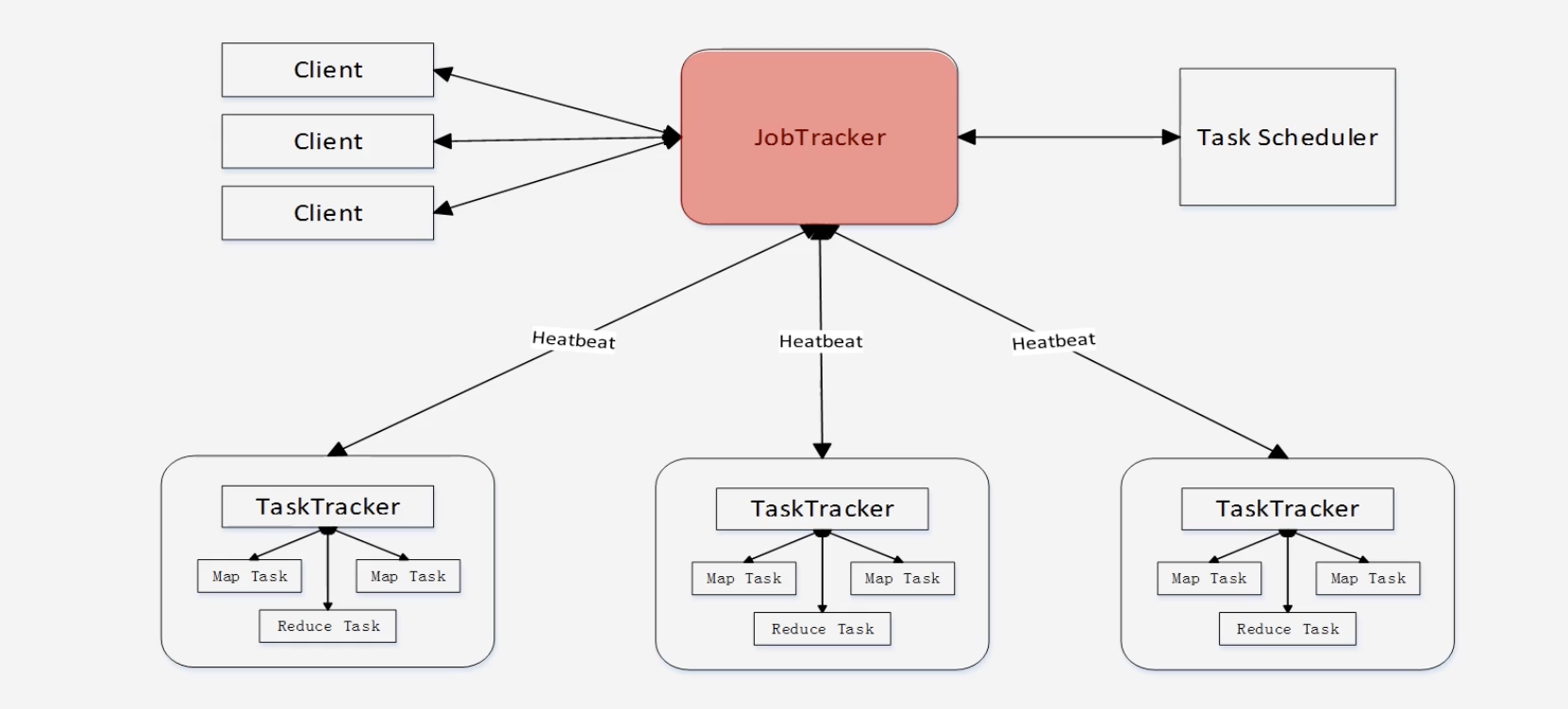
-
JobTracker"大包大揽"导致任务过重:资源管理调度分析、任务管理分配、任务监控以及失败的恢复
-
容易出现内存溢出:只考虑MapReduce的任务数量,不考虑单个MapReduce任务消耗的资源,多个耗内存的任务一起执行,可能会导致内存溢出
-
资源划分不合理:将资源等分为slot,Map的slot和Reduce的slot隔离,Map在运行时,Reduce的slot资源浪费
-
8.3.2 Yarn设计思路
-
将JobTracker三大功能拆分
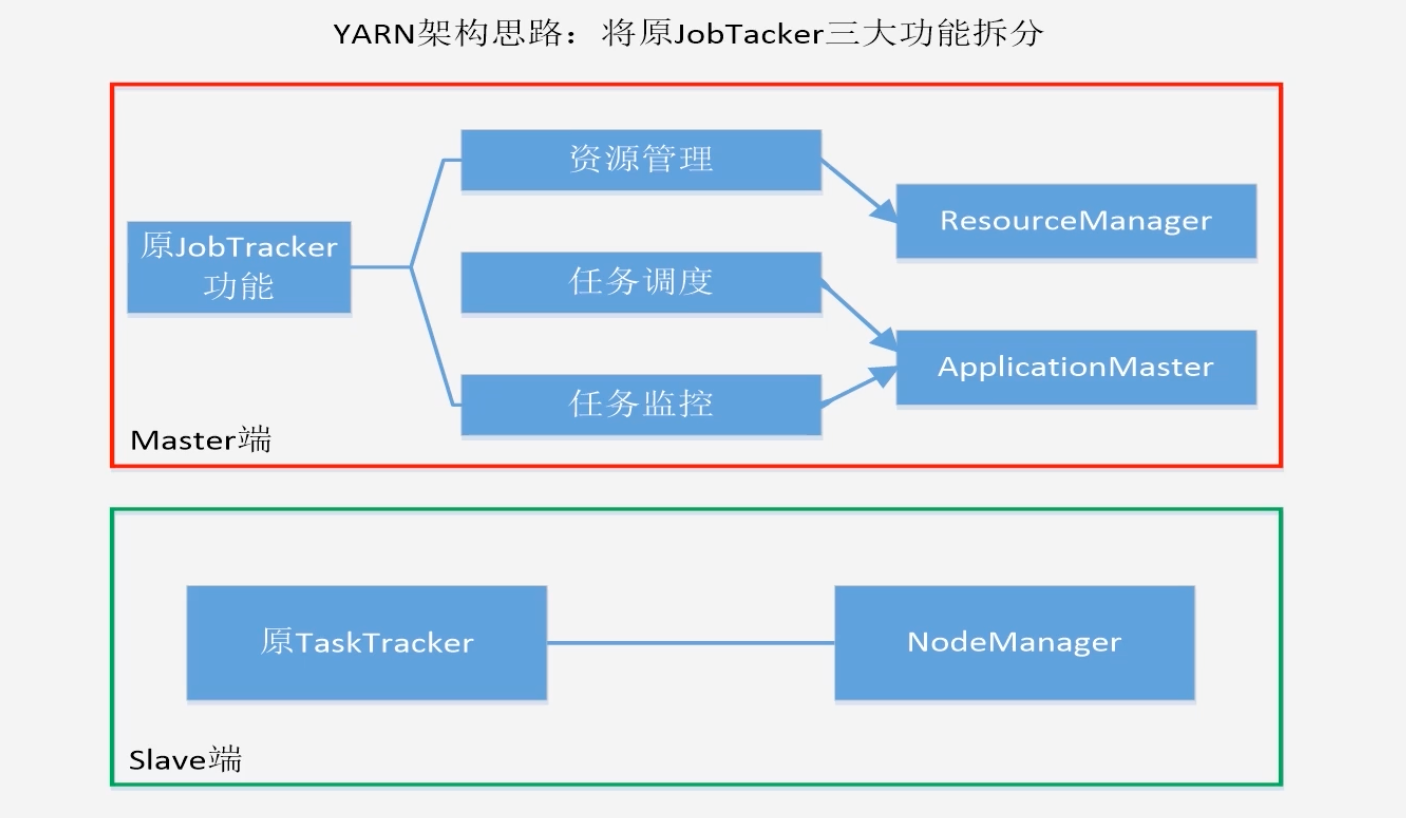
-
MapReduce1.0和Hadoop2.0
- MapReduce1.0既是一个计算框架,也是一个资源调度框架
- Hadoop2.0将MapReduce1.0中的资源管理调度功能单独分离出来,形成了YARN,使得Yarn成为了纯粹的资源管理调度框架
- 而被剥离了资源管理调度功能的MapReduce框架就变成了MapReduce2.0,它是运行在Yarn上的纯粹计算框架,不再负责资源调度管理任务,而是由Yarn提供资源管理调度服务
8.3.3 Yarn体系结构
-
Yarn体系结构
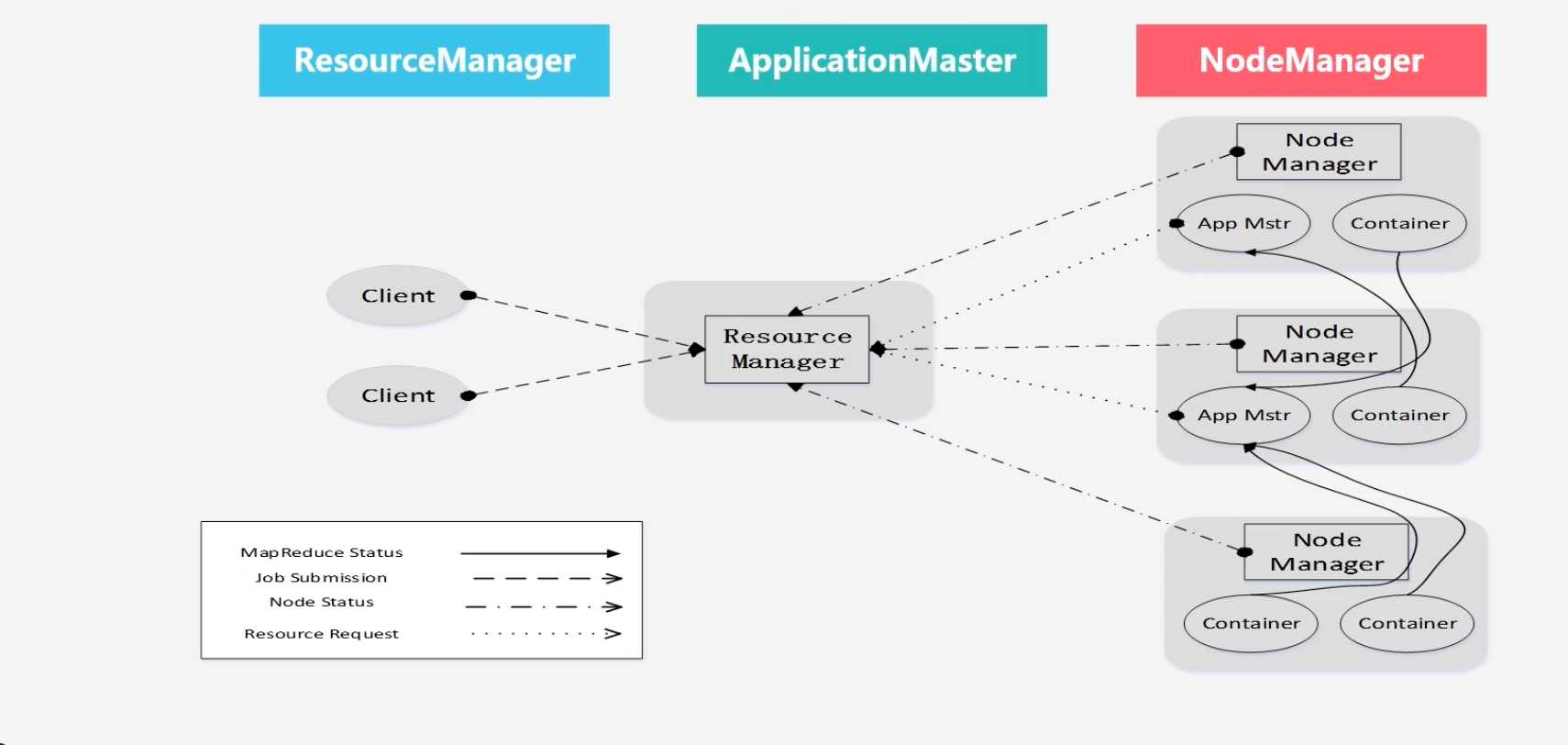
-
Yarn各个组成部分作用
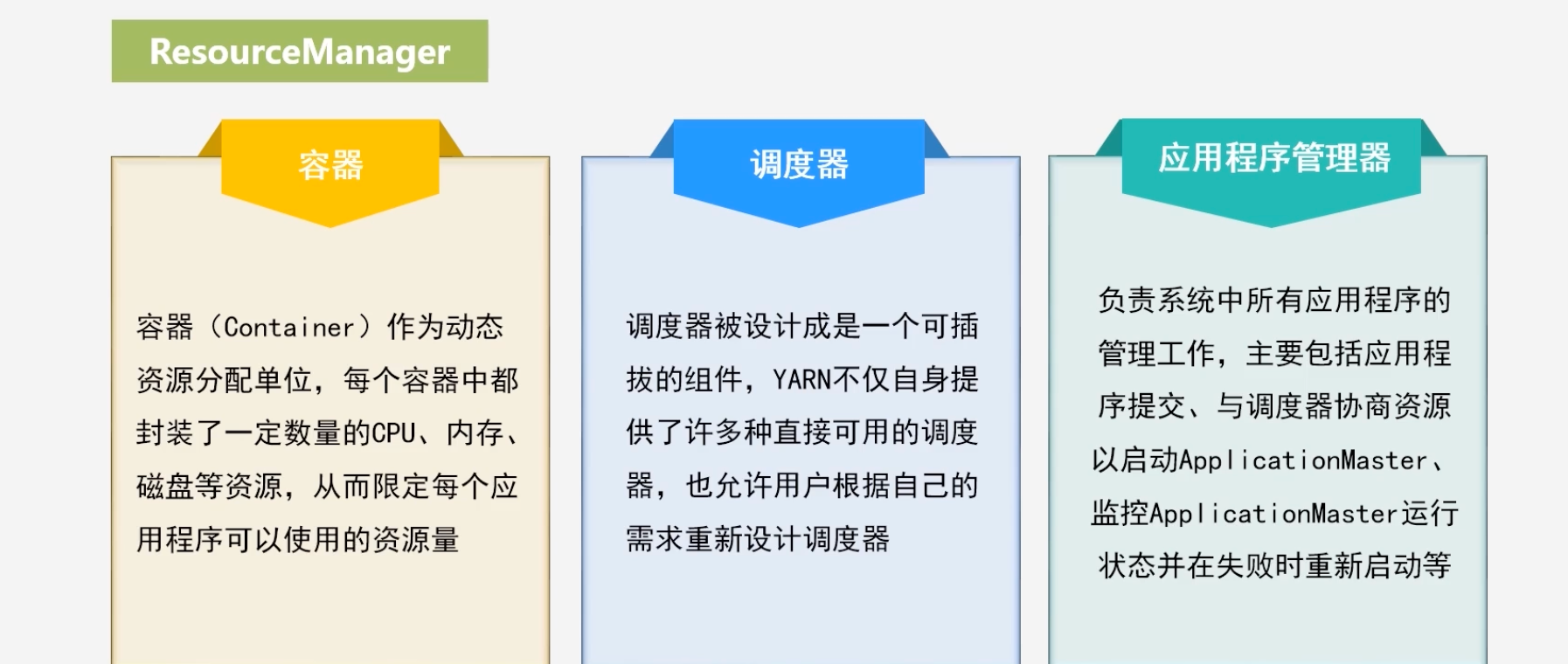
- ResourceManager
- 处理客户端请求
- 启动/监控 ApplicaionMaster
- 监控NodeManager
- 资源分配与调度
- ApplicationMaster
- 为应用程序申请资源,并分配给内部任务
- 任务调度、监控与容错(失败恢复)
- 运行MapReduce所需要的资源(cpu)等由applicationMaster向ResourceManager申请
- NodeManager
- 是单个节点上的资源管理
- 处理来自ResourceManager的命令
- 处理来自ApplicationMaster的命令
- ResourceManager
-
ResourceManager作用、
-
ResourceManager包括了Scheduler(调度器)和Applications Manager(应用程序管理器)

-
将内存资源以容器的形式分配,而不是以slot的形式分配
-
-
ApplicationMaster

-
ApplicationMaster的主要功能
- 当用户作业提交时,ApplicationMater与ResourceManager协商获取资源,ResourceManager会以容器的形式给ApplicationMaster分配资源
- 把获得的资源进一步分配给内部的各个任务(Map任务和Reduce任务),实现资源的“二次分配”
- 与NodeManager保持交互通信进行应用程序的启动、运行、监控和停止,监控申请到的资源的使用情况,对所有任务的执行进度和状态进行监控,并在任务发生失败时执行失败恢复(即重新申请资源重启任务)
- 定时向ResourceManager发送“心跳”信息,报告资源的使用情况和应用的进度信息
- 当作业完成时,ApplicationMaster向ResourceMnager注销容器,执行周期完成
-
NodeManager:驻留在一个Yarn集群中的每一个节点的代理
- 容器生命周期管理:容器具体运行Map任务或者Reduce任务,还可以支持其他的计算框架
- 监控每个容器资源(CPU、内存等)使用情况
- 跟踪节点健康状态
- 以“心跳”的方式与ResourceManager保持通信
- 向ResourceManager汇报作业的资源使用情况和每个容器的运行状态
- 接受ApplicationMaster的启动/停止容器的各种请求
-
NodeManager的主要说明

-
-
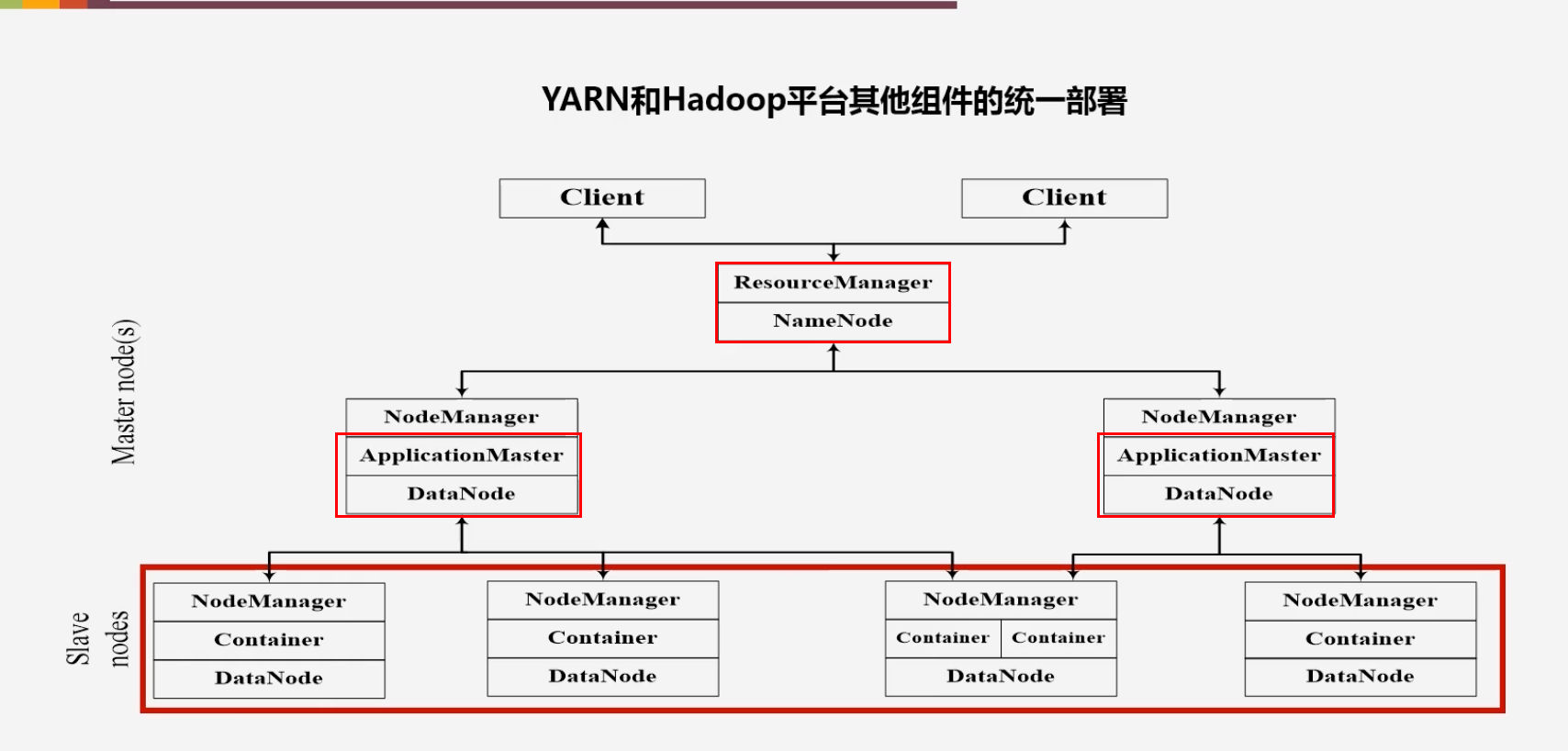
YARN和Hadoop平台其他组件的统一部署
8.3.4 Yarn工作流程
-
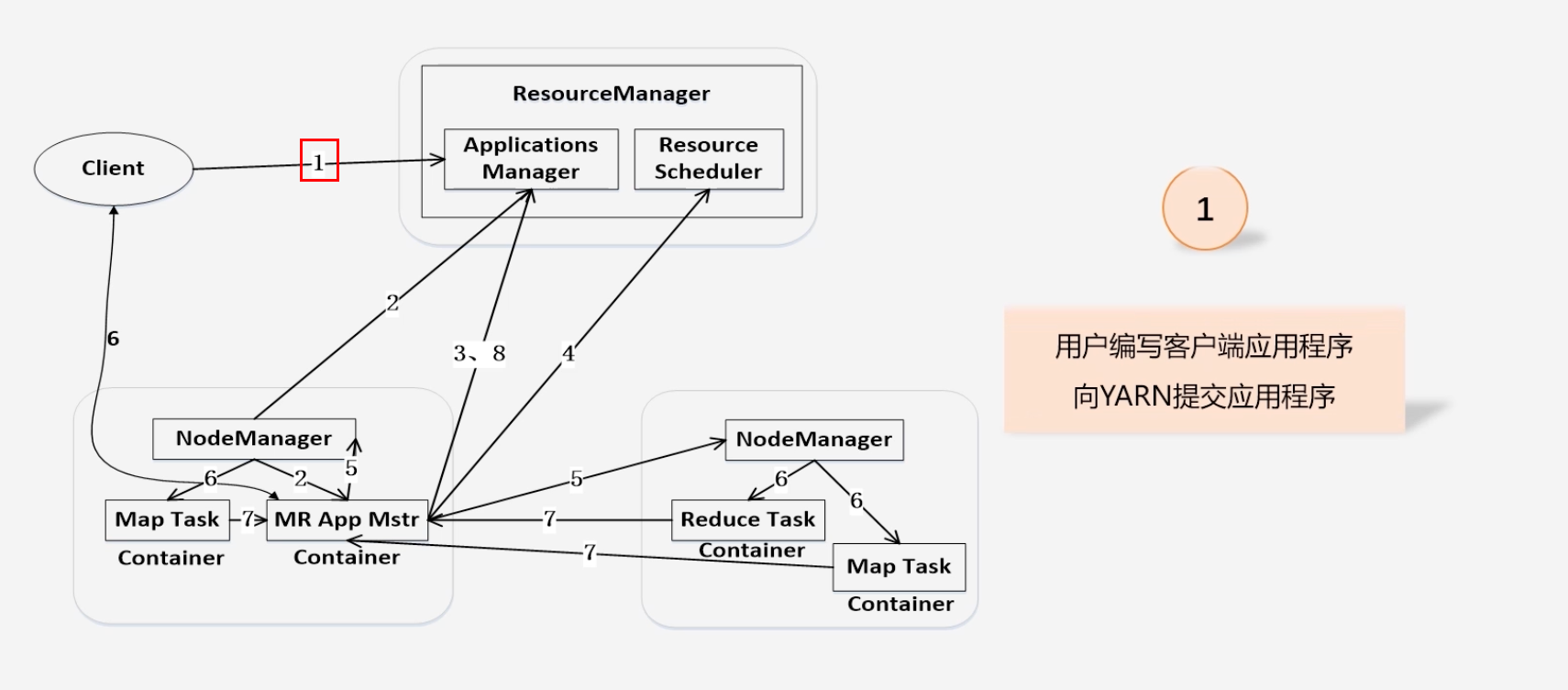
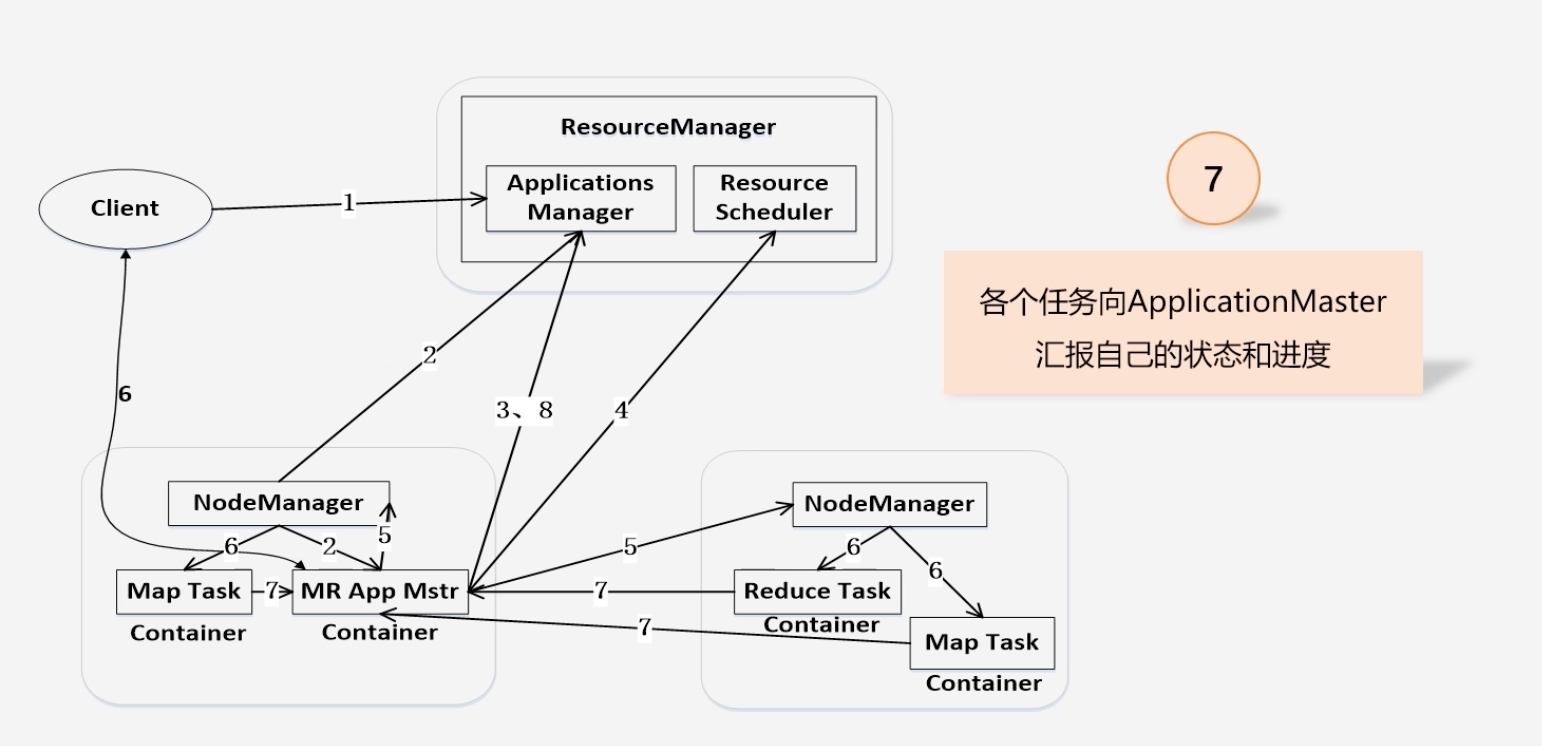
Yarn提交作业之后的全流程执行过程
-
用户编写客户端应用程序,向Yarn提交应用程序,提交内容包括:Applications Master程序、启动Applications Master命令、以及用户程序
-
ResourceManager负责接受和处理来自客户端请求
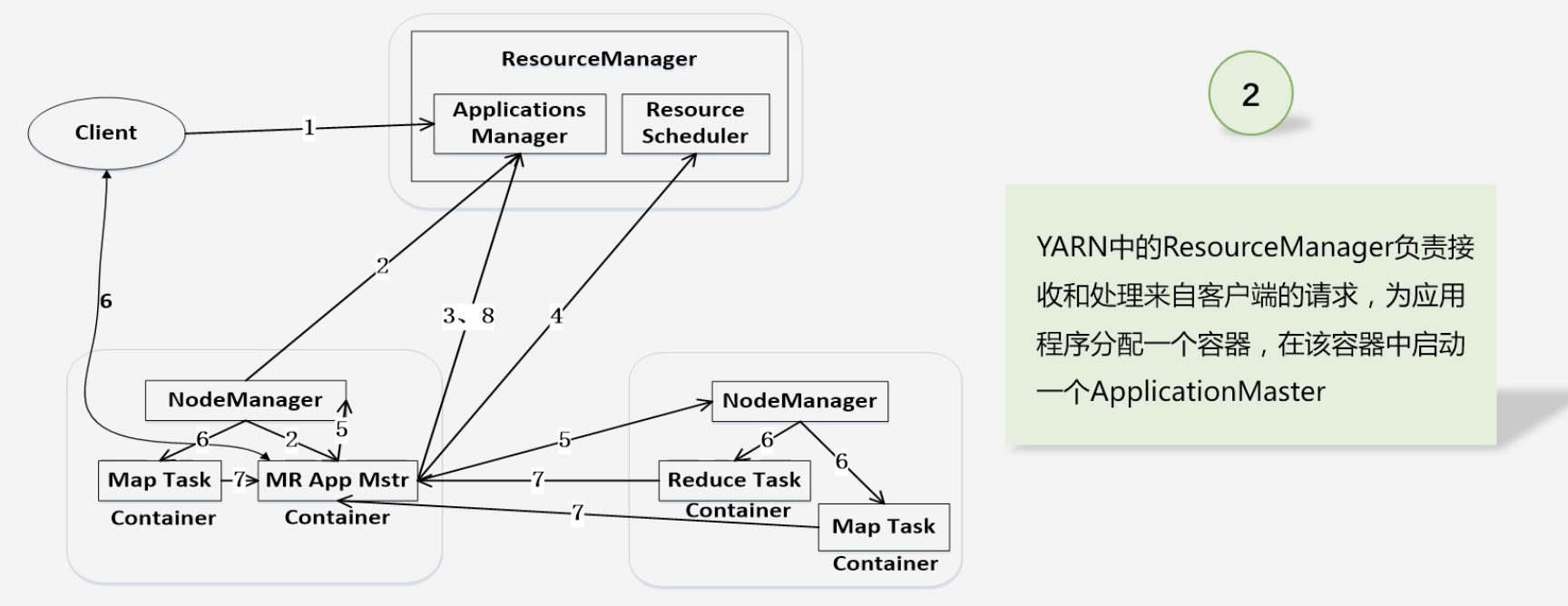
-
ApplicationMaster被创建会首先向ResourceManager注册:为了ResourceManager能够实时监控ApplicationMaster
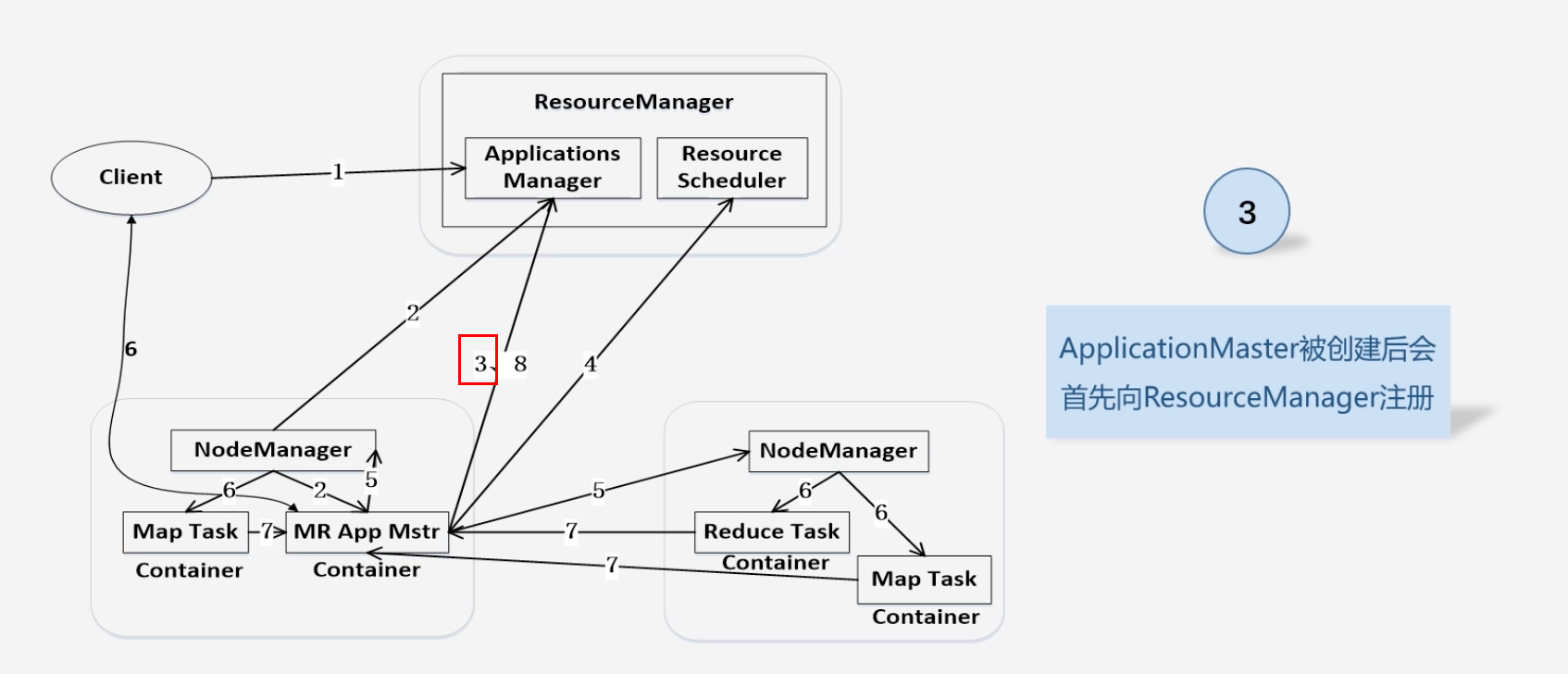
-
ApplicationMaster向ResourceManager申请资源
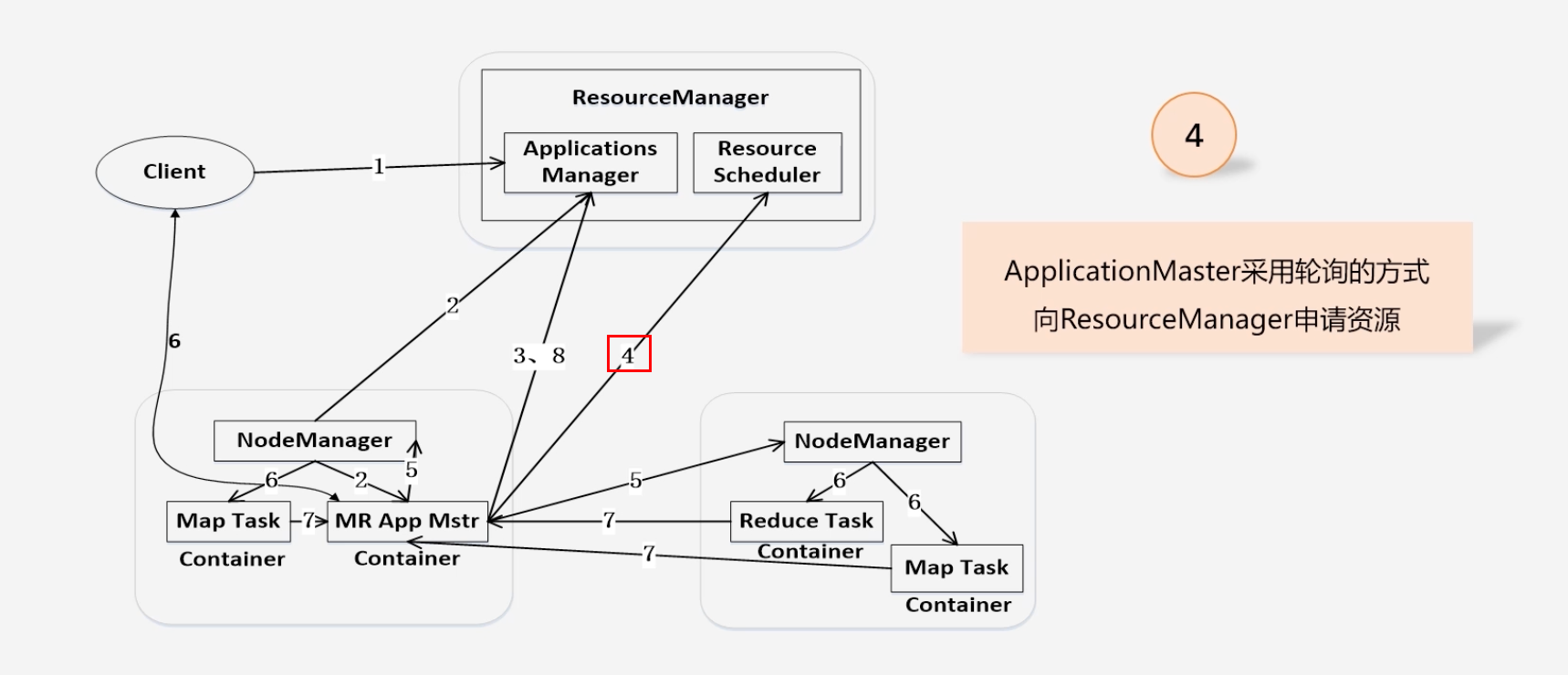
-
ResourceManager以“容器”的形式向ApplicaionMaster分配资源
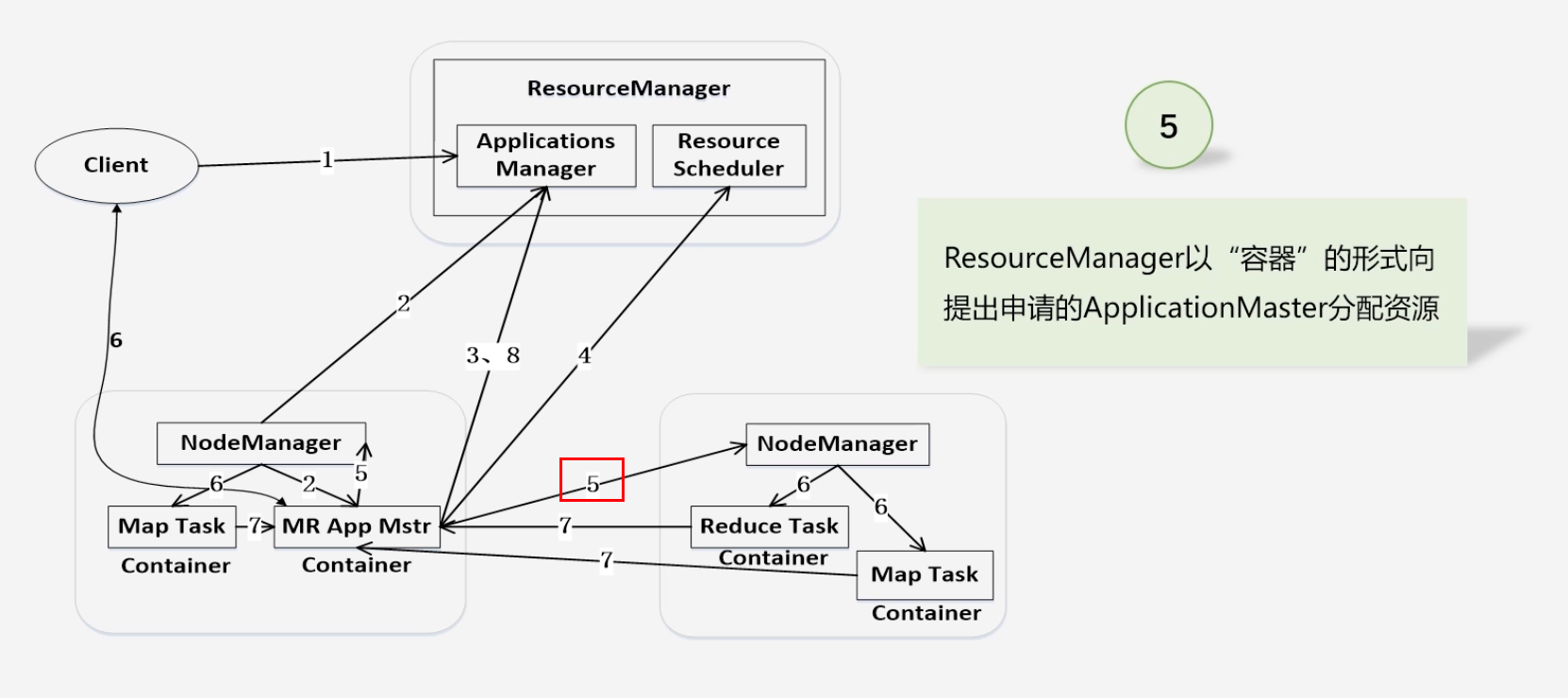
-
资源二次分配,在容器中将资源分配给Map任务和Reduce任务
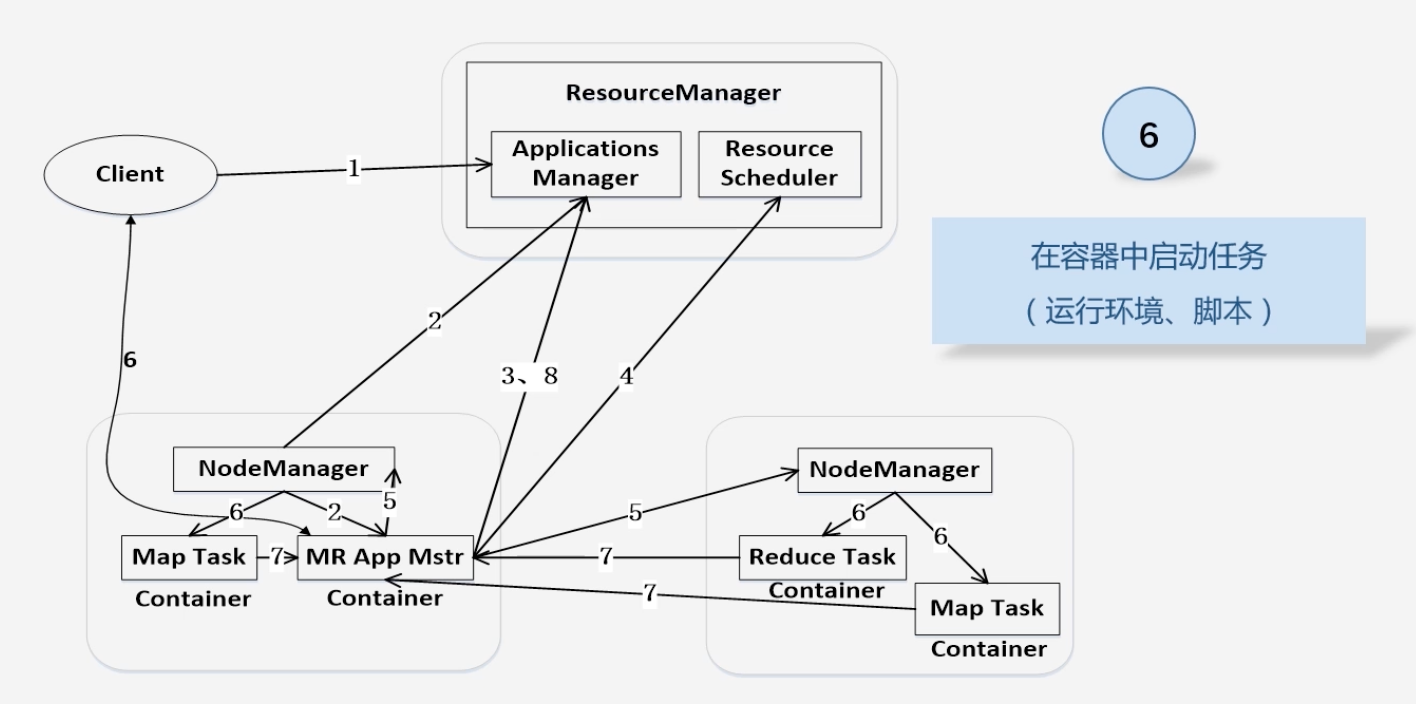
-
各个任务向ApplicationMaster汇报自己的状态和进度
-
-
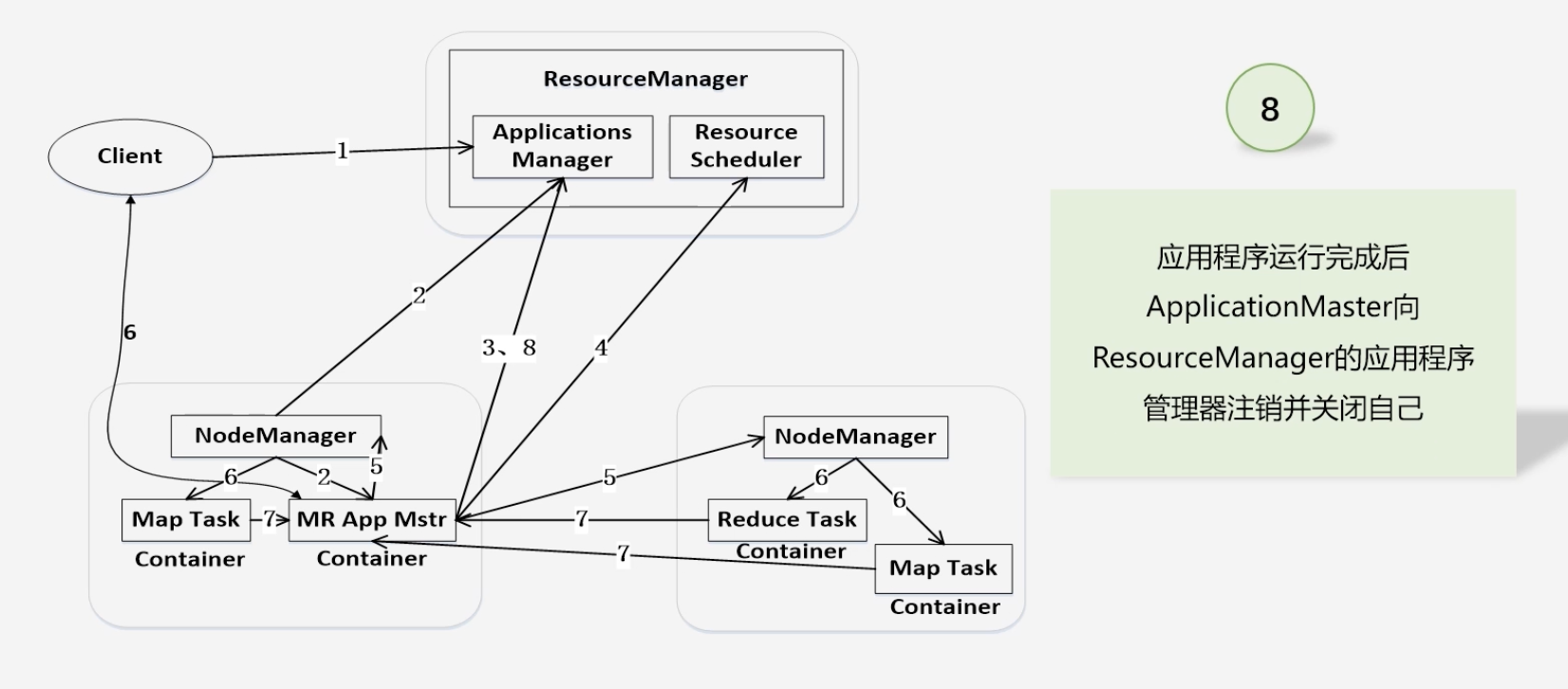
应用承租运行完成,注销关闭ApplicationMaster
8.3.5 Yarn框架和MapReduce1.0框架对比分析
-
大部分API以及接口是兼容的

-
Yarn相对于MapReduce1.0的优势
- 大大减少了承担中心服务功能ResourceManager的资源消耗
- ApplicationMaster来完成需要大量资源消耗的任务调度和监控
- 多个作业对应多个ApplicationMaster,实现了监控分布化
- MapReduce1.0既是一个计算框架,又是一个资源管理调度框架,但是,只能支持MapReduce编程模型
- Yarn是一个纯粹的资源调度管理框架,在它上面可以运行包括MapReduce在内的不同类型的计算框架,只要编程实现相应的ApplicationMaster.
- Yarn中的资源管理比MapReduce1.0更高效,以容器为单位,而不是以slot为单位
8.3.6 Yarn框架的发展目标
-
目标:在一个Yarn上运行多个计算框架

-
为什么要实现“一个集群多个框架”?

-
为了避免不同类型的应用之间互相干扰,企业需要把内部的服务器拆分成多个集群,分别安装运行不同的计算框架,“即一个框架一个集群”
- 但是这样导致集群资源利用率低
- 数据无法共享
- 维护代价高
-
Yarn的实现优势

-
Yarn上部署各种计算框架

-
8.4 Hadoop生态系统中具有代表性的组件
8.4.1 Pig
-
Pig简要介绍


-
Pig提供的相关操作
- 过滤,分组,连接,排序等
-
Pig的优势

-
Pig能做什么?
-
加载数据,表达转换数据,存储最终结果

-
企业将数据收集通过Pig进行数据加工:对收集过来的数据进行抽取、转换、加载,之后再放入数据仓库(Hive)

-
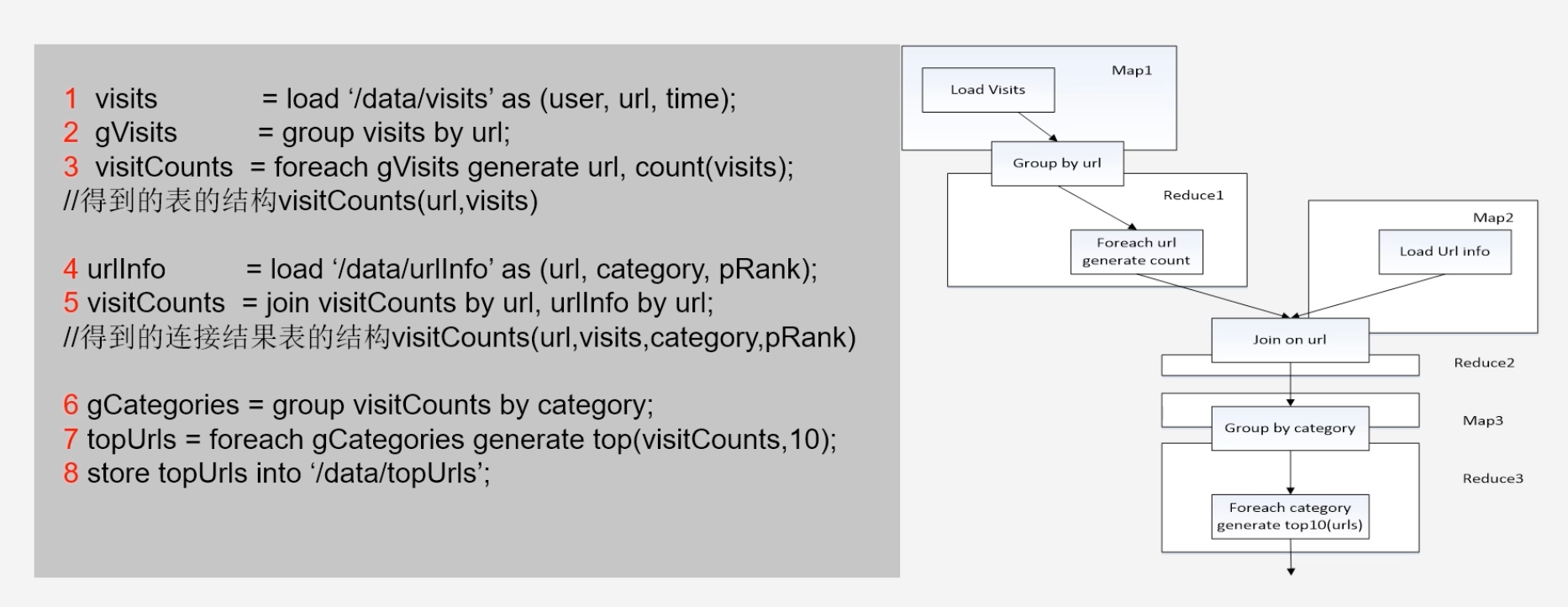
Pig Latin的应用程序实例

-
将执行代码转换为流程图,使用MapReduce解决
-
-
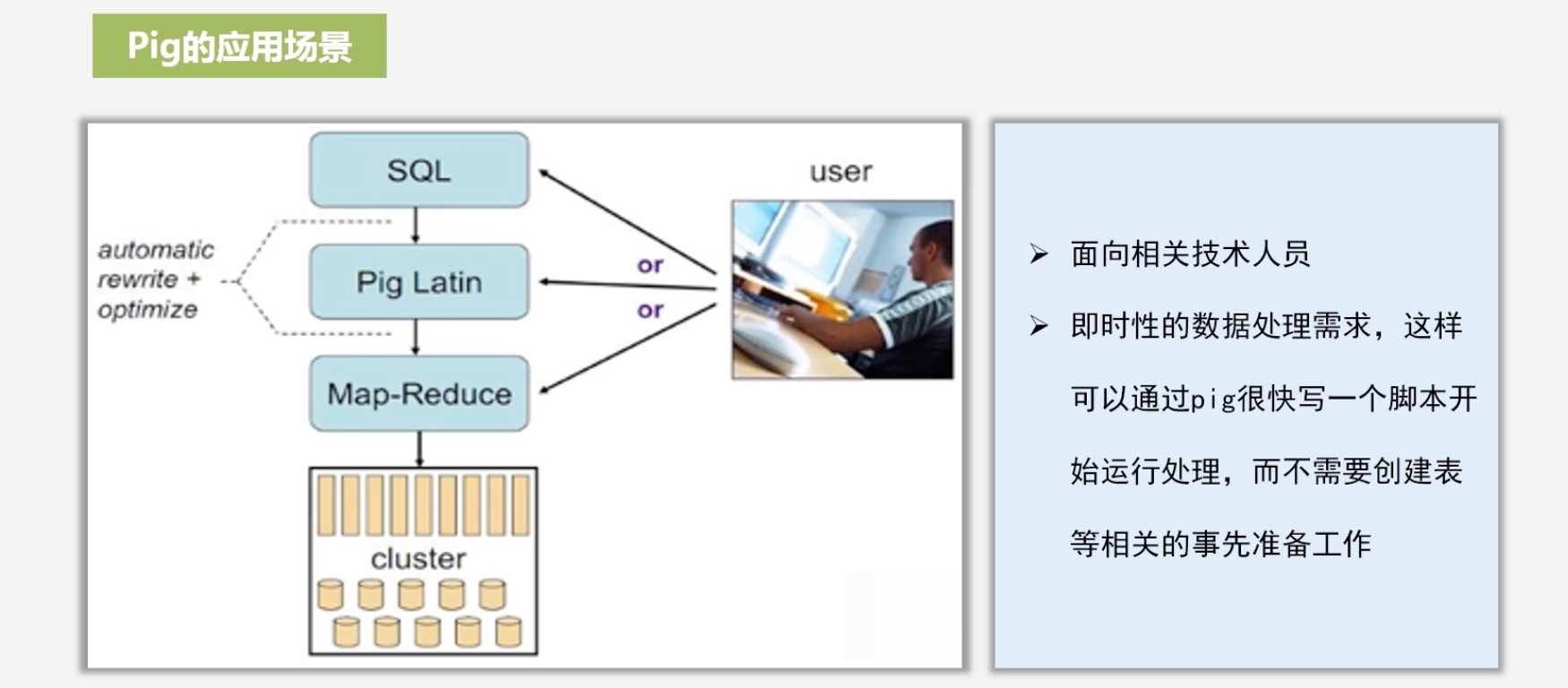
Pig的应用场景
-
Pig的主要用户

8.4.2 Tez
-
Tez框架简要介绍
-
Tez将Map和Reduce拆分成更细粒度的字任务
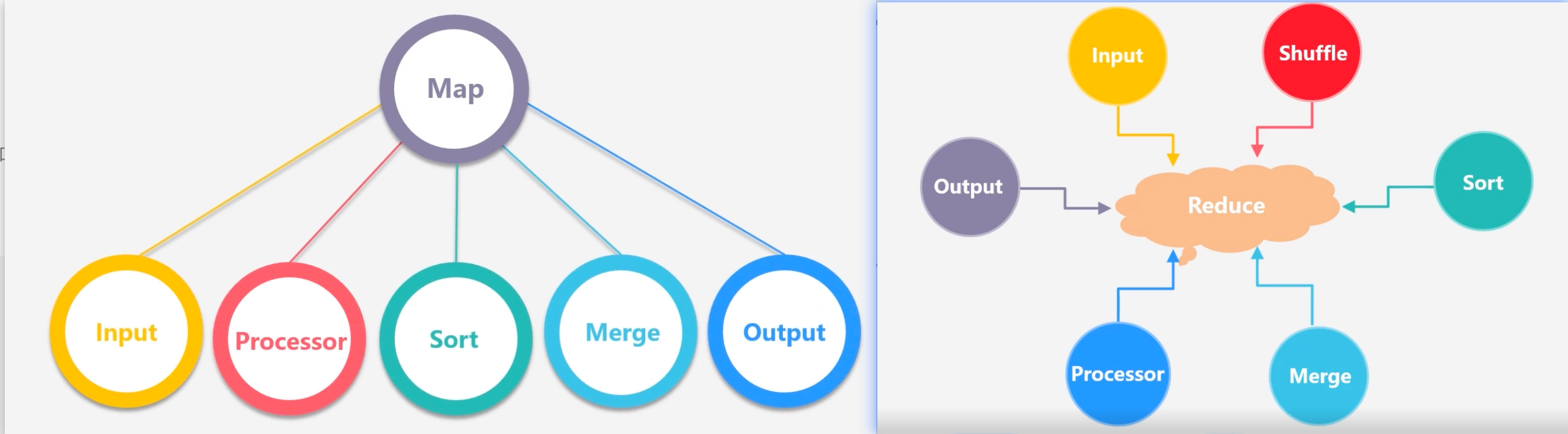
- 分解后的元操作可以任意灵活组合,产生新的操作
- 经过一些控制程序组装后,可以形成一个大的DAG作业
- 通过DAG作业的方式运行MapReduce作业,提供程序运行的整体处理逻辑
- Hortonworks把Tez应用到数据仓库Hive的优化中,使得性能提升了约100倍
-
HiveQL在MapReduce和Tez中的执行情况对比
- 在MapReduce中三次写入HDFS的行为降低性能
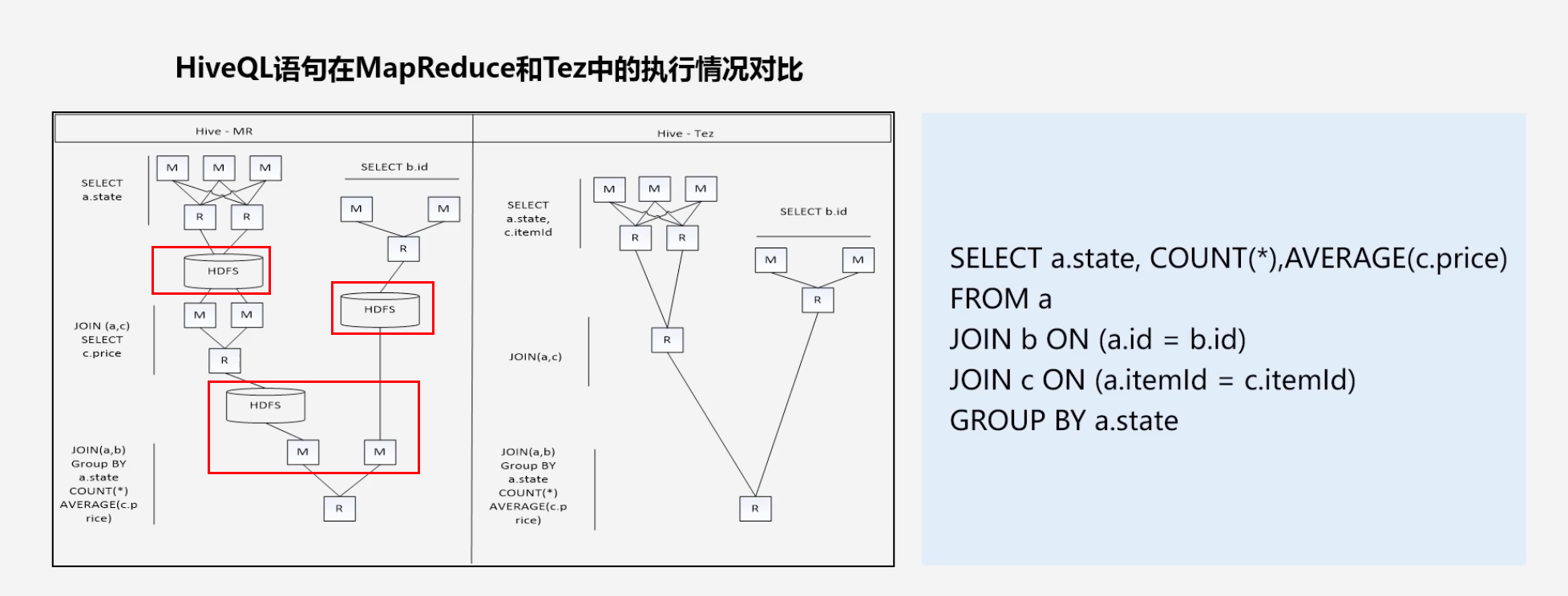
- Tez的优化主要体现在
- 去除连续两个作业之间的“写入HDFS”
- 去除每个工作流中多余的Map阶段
-
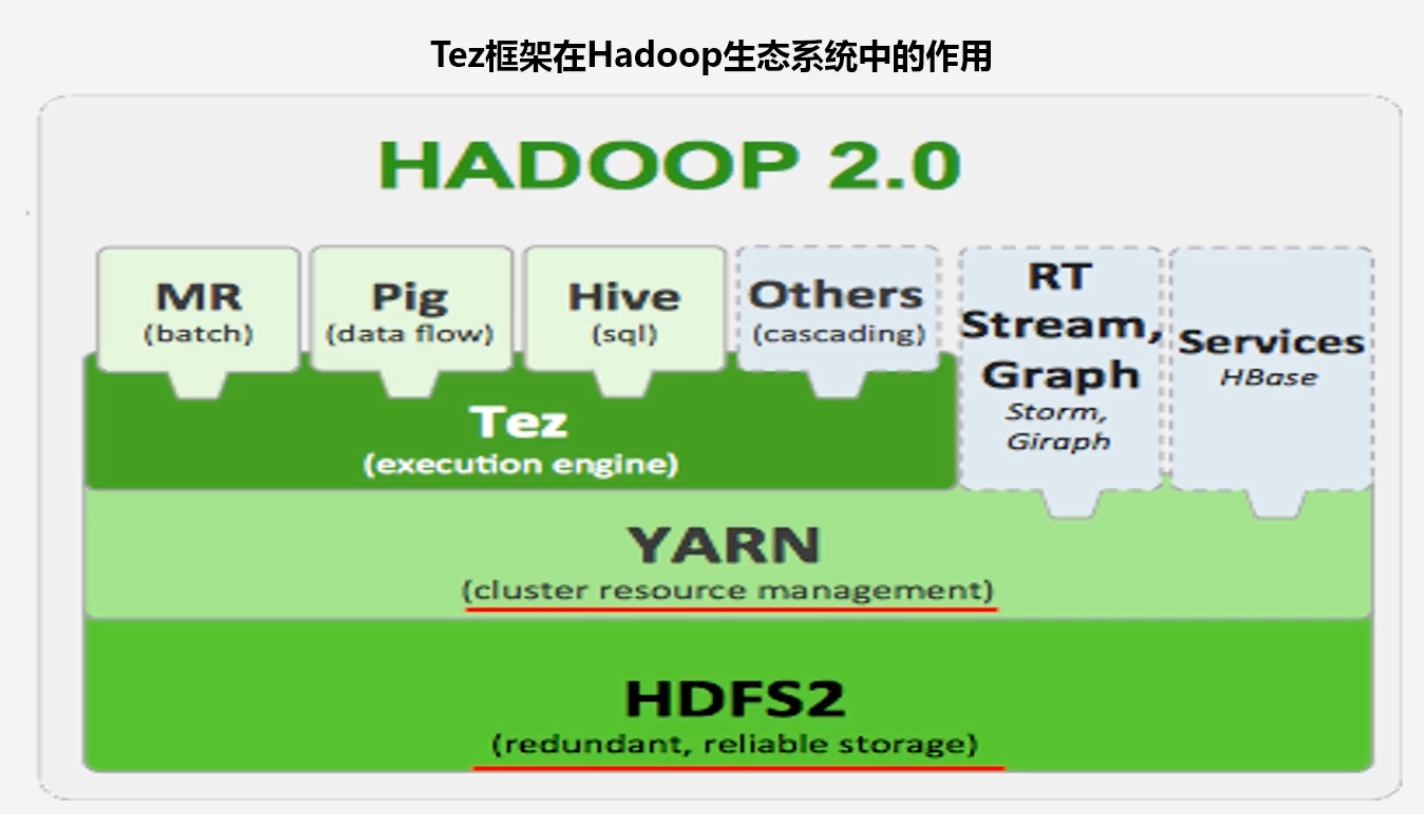
Tez可应用于多个框架

-
Tez在Hadoop生态系统中的作用
-
Tez+Hive与Impala、Dremel、Drill区别

8.4.3 Spark和Kafka
-
Hadoop缺陷

-
Spark的优势
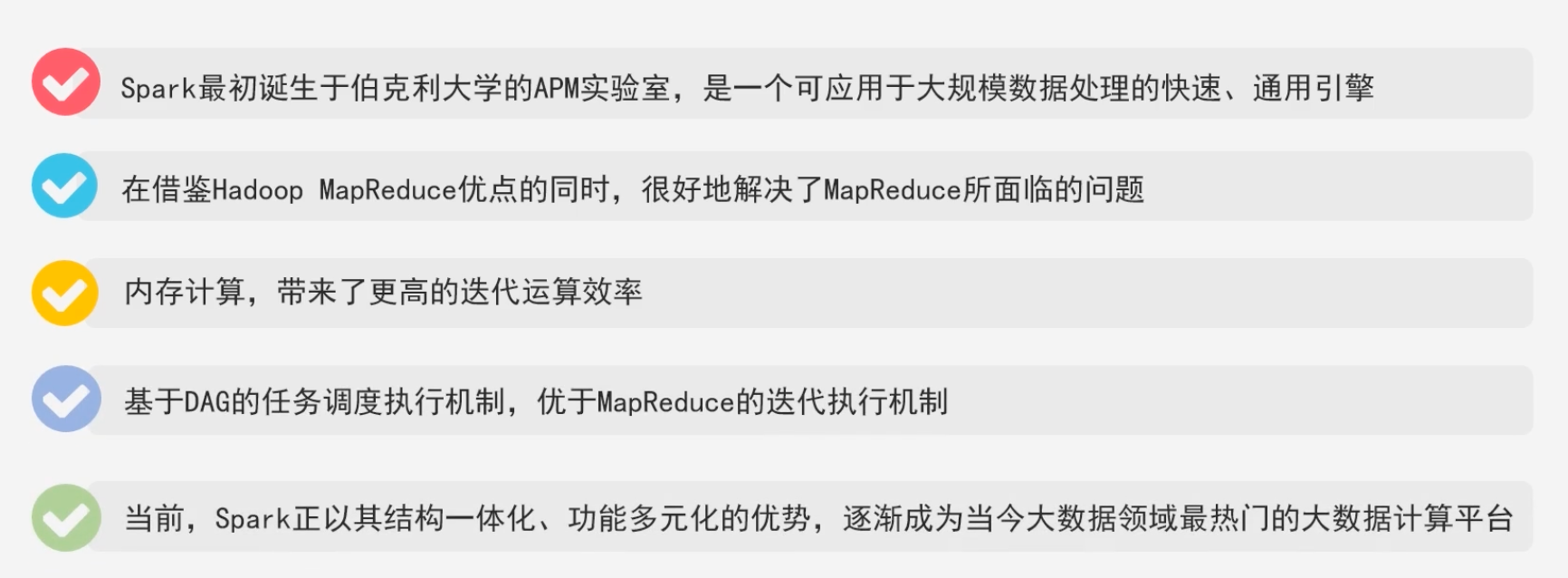
-
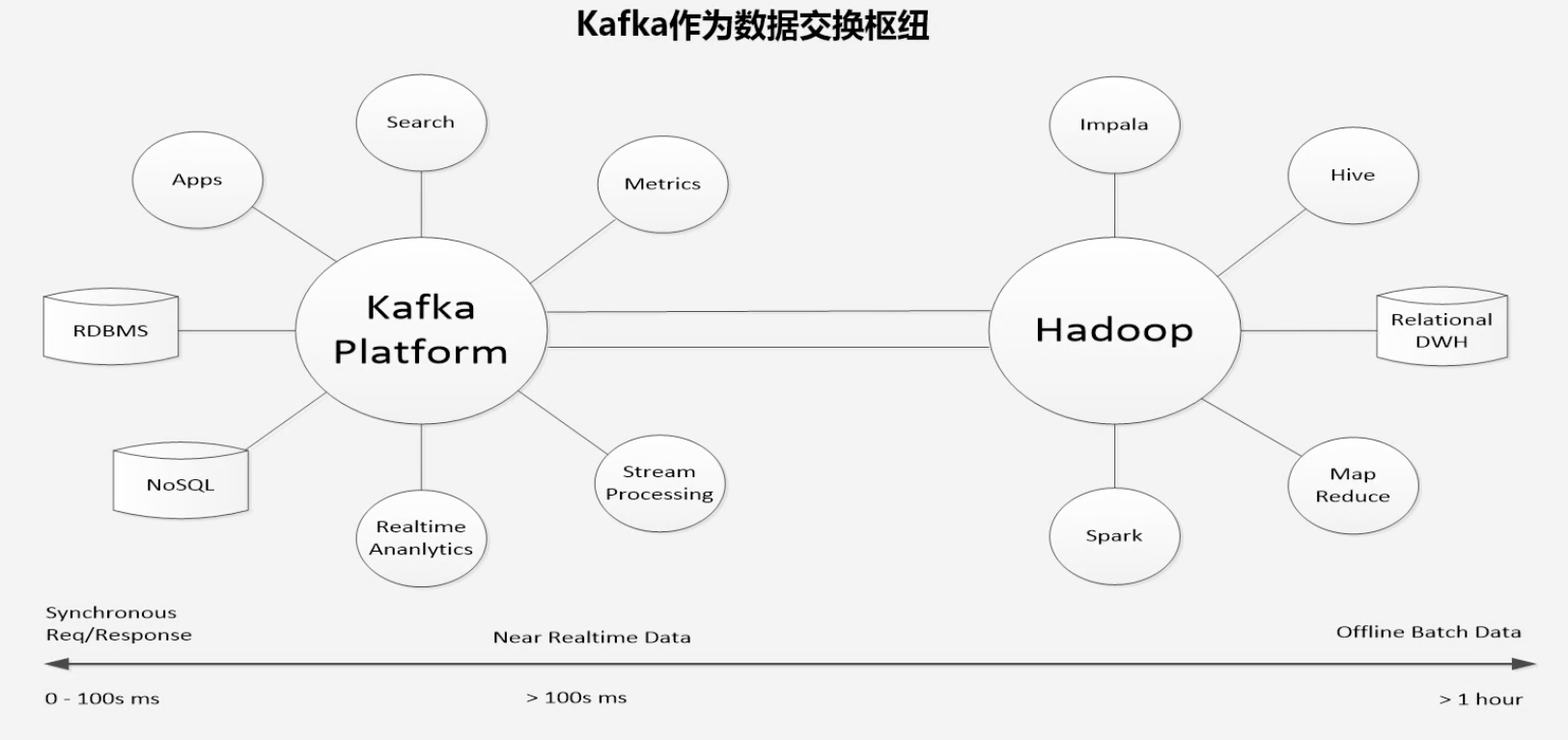
Kafka
- 一种高吞吐量的分布式发布订阅消息系统,用户通过Kafka系统可以发布大量的消息,同时也能实时订阅消费消息
- 可以同时男足在线实时处理和批量离线处理
-
Kafka作用

这篇关于Hadoop2.0探讨的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







