本文主要是介绍mips的旁路_mips的旁路_NonTrivialMIPS,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前一段时间我和几个同学参加了名为“龙芯杯”的比赛,这个比赛是自己设计一个CPU,在其上设计SoC,运行操作系统等… 是一个系统类的比赛。我主要负责写CPU除Cache外的部分,我们最终设计了一个有十级流水的双发射顺序执行的MIPS32处理器。在龙芯的实验板上达到了123MHz的主频,同时还具有较高的IPC。代码现在已经在GitHub上开源。
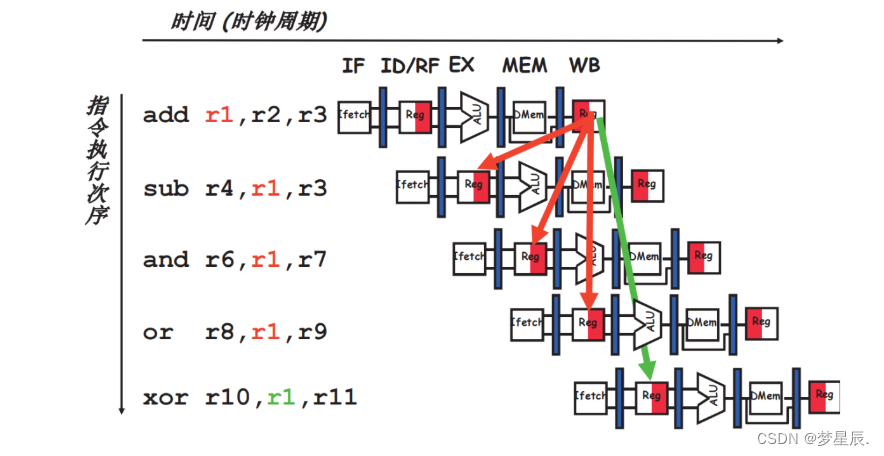
我来说说这个流水线的设计,除去各种数据旁路,流水线的架构大约如下图
这十级流水基本上是从标准的五级流水扩展而来,其中有3级的取指,2级的发射,3级的访存。其实我们最开始计划的是双发射乱序处理器,并且之前在组成原理课上有一部分顺序双发射的经验,当时有一个很麻烦的地方就是取指阶段,这里需要根据到底发射一条指令还是两条指令控制PC的增加,但是在决定下一个PC值时所需要的指令还没有取到,这就需要一部分预测和旁路,导致取指阶段很复杂并且容易写错。
这次我基本上重写了整个CPU,在取指阶段增加了一个FIFO,把取到的指令放入FIFO。之后在发射的时候从FIFO读取指令。这样一定程度上将取指和之后的执行等阶段进行了解耦。取指有3级流水基本上是由于指令Cache的需要。由于分支要在较后才能解析,CPU必然需要一个分支预测器,我实现的是2bit的分支预测。假设分支预测完全正确的情况下,可以保证放入FIFO的指令流就是执行所需要的指令流(当然这里也处理了延迟槽)。同时,为了支持双发射,我们的指令Cache一次可以取出8字节的数据,如果其后的8字节仍然在同一个Cache行内,也会一并取出。这是为了在预测到分支指令的之后能够尽早将延迟槽放入FIFO而不需要进行一次多余的取指。也就是,我们的FIFO在一个周期最多可以放入3条指令。
在之后发射阶段,为了频率的提高,我们将读操作数单独作为一个流水段。虽然这样会造成分支预测失败的损失增大进而减小IPC,但是和频率的提升相比这部分的损失还是比较小的。双发射基本上是对称的,只要不存在数据冲突和结构冲突(例如两条除法指令或者两条访存指令)都可以同时发射。当然,为了设计简便,我额外增加了一个限制,也就是分支指令和延迟槽必须一起发射。发射之后的读操作数和执行就没有太多技术含量,和通常的五级流水线相同。我们的异常处理和CP0的读写都是在执行之后的一个阶段,也就是访存的第一个阶段进行的。
在这里有一个很严重的问题就是,由于数据Cache的流水太常,导致访存相关(即访存后立即使用数据)的暂停很高,这极大影响了性能。为了缓解这个问题,我们允许部分指令的读操作数和执行延迟到访存阶段进行。这样就可以很大地减小访存暂停。当然不是所有指令都能做到这件事,首先这需要满足一些条件。其一就是这类指令不能是访存指令,其二是这类指令不能在执行阶段出现异常(取指的TLB miss还是可以的,这在它执行前就可以判断)。当然,这两个条件其实不是很严格,很大一部分程序访存后基本上是跟着一些ALU指令或者分支指令。在增加这个优化之后,整个处理器的IPC大约有了15%的提升,同时频率仍然保持。其实我们或许还可以进一步优化,对于非分支指令还可以将其延迟到访存的第二个阶段读操作数,这样就完全不会有访存相关。至于分支指令,我们必须要能够在分支预测失败时撤销其后的指令,流水线上能够影响处理器状态的第一个阶段就是访存的第一个阶段,因此分支指令最迟必须要在访存第二个阶段执行完成。不过我并没有实现这个优化。另外还有一个较小的优化,对于存储指令的数据,可以在执行阶段再读取。
除了执行操作系统所需要的指令以外,我们还做了一定的扩展,例如实现了一个32位的FPU以及一个硬件AES加速单元同时移植到OpenSSL上。MIPS32在早期版本对单精度浮点的规范非常奇怪,有两条指令叫做ldc1和sdc1,它允许同时两个FPU寄存器和内存交换数据,也就是一次访存的数据宽度是64位。我实现的方法是在发射阶段将其拆开成为两条32位的访存指令,同时不允许中断打断这两条指令。至于AES加速,实际上是在CP2上实现的。只用到了mfc2和mtc2两条指令,AES单元具有自己的寄存器,通过这两条指令和CPU的寄存器进行数据的交互以及控制。
至于操作系统和SoC的内容,这就不是我负责的范围了,具体可以看看我们最后的报告。
其实实现的过程中还有一个乱序的版本,不过最后因为频率没法提升同时访存并没有很好地被实现最终没有使用。
本文遵守
许可协议
这篇关于mips的旁路_mips的旁路_NonTrivialMIPS的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!