本文主要是介绍VPP源码阅读---IP报文重组和分片,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、dpdk ip报文重组及分片API及处理逻辑介绍
DPDK的分片和重组实现零拷贝,详细介绍可以参阅DPDK分片与重组用户手则
1.1相关数据结构

1.2 相关API
/*NO.1 创建rte_ip_frag_tbl结构,用来暂存分片的表。其中max_cycles表示分片报文超时时间TTL*frag_cycle = (rte_get_tsc_hz()) + MS_PER_S –1) / MS_PER_S * 10;*是10ms的cycle的一个例子。*/
struct rte_ip_frag_tbl * rte_ip_frag_table_create(uint32_t bucket_num,uint32_t bucket_entries, uint32_t max_entries,uint64_t max_cycles, int socket_id);/*NO.2使用IPV4包的片段处理新的mbuf。传入的mbuf应该有它的l2_len/l3_len字段设置正确。*返回值,1)指向重新组装包的mbuf指针,*。 2)NULL;报文为收全;或者收取报文有错误,无法重组。*. 这里需要注意重组后的ip的checksum字段为0,需要自己更新。*/
struct rte_mbuf *
rte_ipv4_frag_reassemble_packet(struct rte_ip_frag_tbl *tbl,struct rte_ip_frag_death_row *dr, struct rte_mbuf *mb, uint64_t tms,struct ipv4_hdr *ip_hdr);
rte_ip_frag_table_create函数;查了一个官方给的事例其中如下:
1)bucket_num 作了赋值但是也没有使用?
2)函数参数1和参数3都使用max_flow_num,而api中写明 max_flow_num 大于等于参数1*参数2.
frag_cycles = (rte_get_tsc_hz() + MS_PER_S - 1) / MS_PER_S * max_flow_ttl;
bucket_num = max_flow_num + max_flow_num / 4;
frag_tbl = rte_ip_frag_table_create(max_flow_num, bucket_entries, max_flow_num, frag_cycles, socket_id);
1.3 rte_ipv4_frag_reassemble_packet 包处理逻辑。

dpdk ip报文分片API
报文重组就下面一个接口api,也是实现零拷贝,
int32_t
rte_ipv4_fragment_packet(struct rte_mbuf *pkt_in,struct rte_mbuf **pkts_out,uint16_t nb_pkts_out,uint16_t mtu_size,struct rte_mempool *pool_direct,struct rte_mempool *pool_indirect
报文重组后结构如下:

2、VPP ipv4报文伪重组功能说明
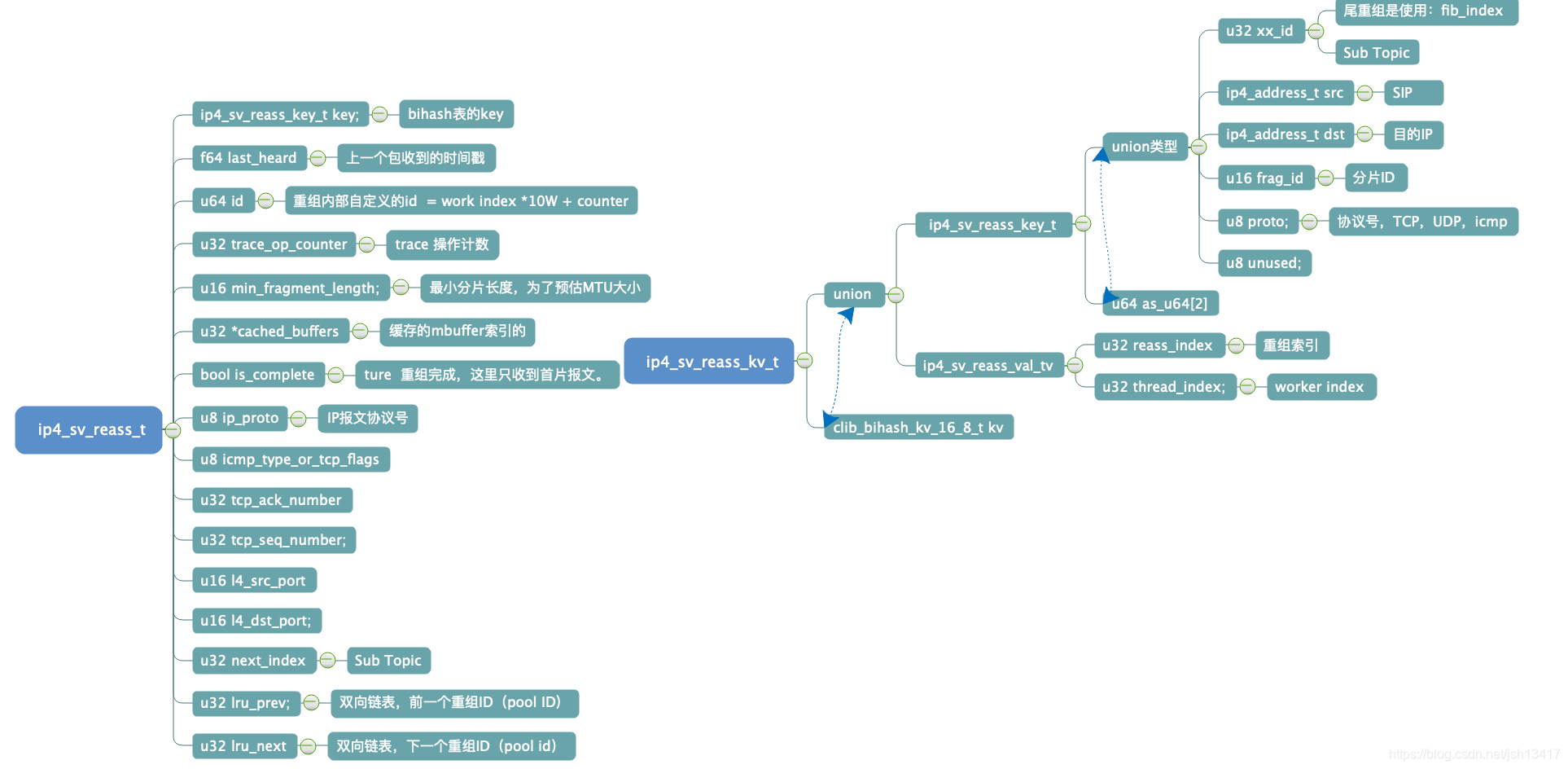
IP数据报被分片之后,所有分片报文的IP报头中的源IP、目的IP、IP标识、上层协议等信息都是一样的(TTL不一定是一样的,因为不同的分片报文可能会经过不同的路由路径达到目的端),不同的地方在于分片标志位和分片偏移量,而接收方正是根据接收到的分片报文的源IP、目的IP、 IP标识、分片标志位、分片偏移量来对接收到的分片报文进行重组。
接收方根据报文的源IP、目的IP、IP标识将接收到的分片报文归为不同原始IP数据报的分片分组;分片标志中的MF位(More Fragment)标识了是否是最后一个分片报文,如果是最后一个分片报文,则根据分片偏移量计算出各个分片报文在原始IP数据报中的位置,重组为分片前的原始IP报文。如果不是最后一个分片报文,则等待最后一个分片报文达到后完成重组。伪重组的意思就是收到的报文如果是首片的报文,记录存储到bihash表key:报文的源IP、目的IP、IP标识,vlaue:首片报文的信息五元组等信息中,报文直接发送出去.等其他分片报文到达时,直接通过key在hash表中查询,得到五元组信息直接使用。而不用真正的缓存下来。而只有当出现乱序情况时,比如首片报文后到达时。
2.1伪重组相关结构体
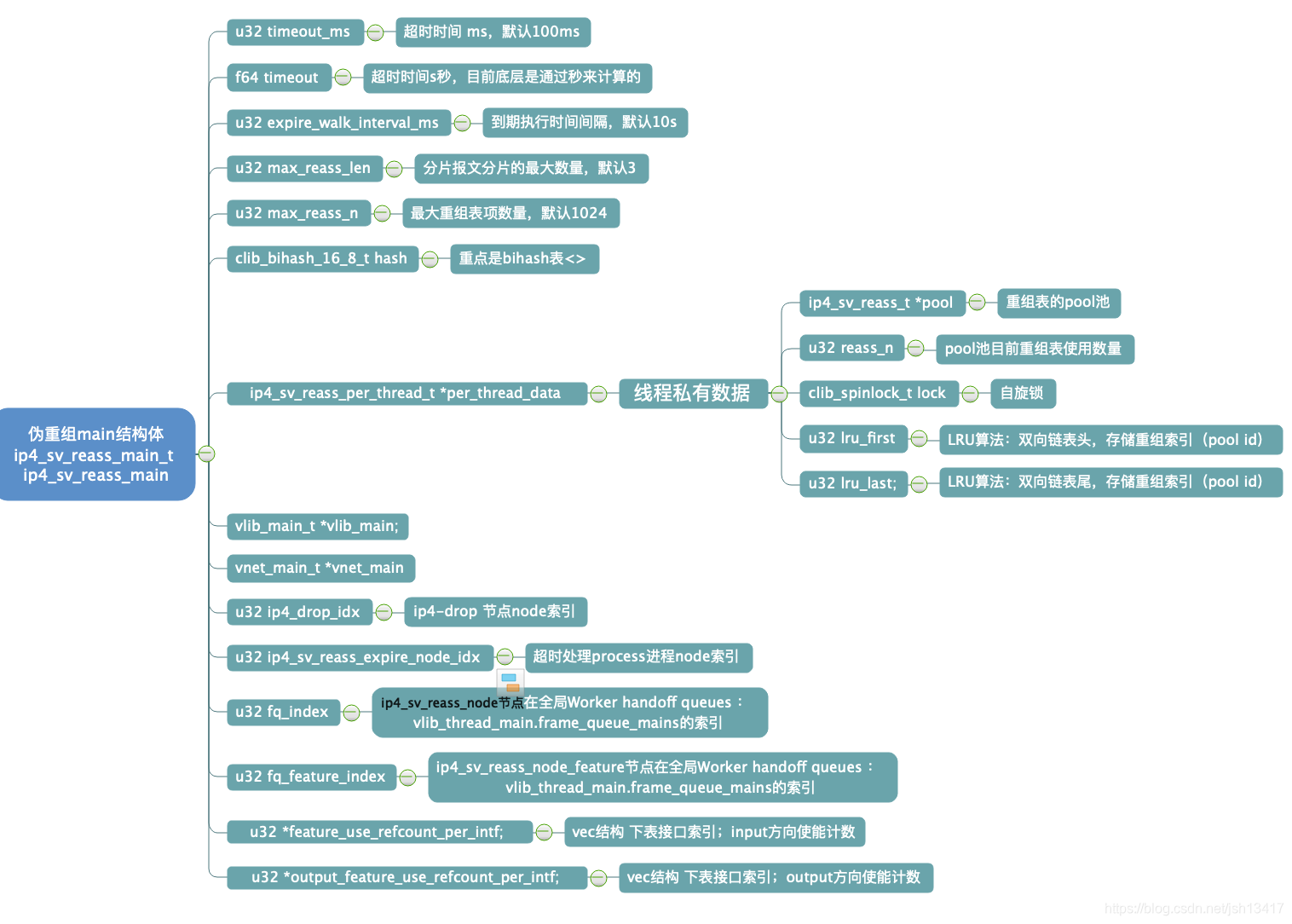
1)伪重组全局结构体ip4_sv_reass_main_t ip4_sv_reass_main;主要是设置报文超时时间、老化执行时间、分片报文最大数量、表项规格等信息,这里每个线程一个pool池的原因应该是为了降低worker核之间的竞争及存在handoff功能的原因。
2、重组表及bihash的kv对
3、重组函数基本逻辑
在重组函数线程私有数据,这里有个自旋锁,个人觉得原因是ip4_sv_reass_walk_expired 定时老化函数存在资源竞争吧。
ip4_sv_reass_per_thread_t *rt = &rm->per_thread_data[thread_index];clib_spinlock_lock (&rt->lock)
在当重组表数量已达到最大数量时,从lru表中取出一个释放,我认为这里不符合lru算法,个人感觉是代码bug,不应是取rt->lru_last的,应该是lru_prev吧。
if (rt->reass_n >= rm->max_reass_n && rm->max_reass_n){reass = pool_elt_at_index (rt->pool, rt->lru_last);ip4_sv_reass_free (vm, rm, rt, reass);}

3、vpp ipv4 报文分片处理
ipv4报文分片处理比较简单,就是根据MTU的长度和vlib_buffer数据最大长度-IP头长度,选择一个最小值来做为分片长度。
max =(clib_min (mtu, vlib_buffer_get_default_data_size (vm)) -sizeof (ip4_header_t)) & ~0x7
下面是分片报文处理的api接口说明及处理逻辑:
/*from_bi:原始报文vlib_buffer索引,* mtu: mtu 长度报文以此长度来分片。*l2unfragmentablesize:二层长度,这里指的是current_data指向到ip头之间的偏移量。*buffer:分片后的vlib_buffer的索引**/
ip_frag_error_t
ip4_frag_do_fragment (vlib_main_t * vm, u32 from_bi, u16 mtu,u16 l2unfragmentablesize, u32 ** buffer)

5、其他基础概念
5.1 MTU、MSS相关概念
MTU(最大传输单元)
MTU前面已经说过了,是链路层中的网络对数据帧的一个限制,依然以以太网为例,MTU为1500个字节。一个IP数据报在以太网中传输,如果它的长度大于该MTU值,就要进行分片传输,使得每片数据报的长度小于MTU。分片传输的IP数据报不一定按序到达,但IP首部中的信息能让这些数据报片按序组装。IP数据报的分片与重组是在网络层进完成的。
MSS(最大分段大小)
MSS是TCP里的一个概念(首部的选项字段中)。MSS是TCP数据包每次能够传输的最大数据分段,TCP报文段的长度大于MSS时,要进行分段传输。TCP协议在建立连接的时候通常要协商双方的MSS值,每一方都有用于通告它期望接收的MSS选项(MSS选项只出现在SYN报文段中,即TCP三次握手的前两次)。MSS的值一般为MTU值减去两个首部大小(需要减去IP数据包包头的大小20Bytes和TCP数据段的包头20Bytes)所以如果用链路层以太网,MSS的值往往为1460。而Internet上标准的MTU(最小的MTU,链路层网络为x2.5时)为576,那么如果不设置,则MSS的默认值就为536个字节。很多时候,MSS的值最好取512的倍数。TCP报文段的分段与重组是在运输层完成的。
5.2 MTU与ip分片
到了这里有一个问题自然就明了了,TCP分段的原因是MSS,IP分片的原因是MTU,由于一直有MSS<=MTU,很明显,分段后的每一段TCP报文段再加上IP首部后的长度不可能超过MTU,因此也就不需要在网络层进行IP分片了。因此TCP报文段很少会发生IP分片的情况。
再来看UDP数据报,由于UDP数据报不会自己进行分段,因此当长度超过了MTU时,会在网络层进行IP分片。同样,ICMP(在网络层中)同样会出现IP分片情况。
总结:UDP不会分段,就由IP来分。TCP会分段,当然就不用IP来分了!
另外,IP数据报分片后,只有第一片带有UDP首部或ICMP首部,其余的分片只有IP头部,到了端点后根据IP头部中的信息再网络层进行重组。而TCP报文段的每个分段中都有TCP首部,到了端点后根据TCP首部的信息在传输层进行重组。IP数据报分片后,只有到达目的地后才进行重组,而不是向其他网络协议,在下一站就要进行重组。
最后一点,对IP分片的数据报来说,即使只丢失一片数据也要重新传整个数据报(既然有重传,说明运输层使用的是具有重传功能的协议,如TCP协议)。这是因为IP层本身没有超时重传机制------由更高层(比如TCP)来负责超时和重传。当来自TCP报文段的某一段(在IP数据报的某一片中)丢失后,TCP在超时后会重发整个TCP报文段,该报文段对应于一份IP数据报(可能有多个IP分片),没有办法只重传数据报中的一个数据分片。
所以之所以却没有限制HTTP报文的大小,是因为在传输层中已经由TCP对HTTP报文做了分段传输,达到目标地址后再对所有TCP段进行重组。
下面看一个HTTP包可知,如果HTTP报文过大,会由TCP自动进行分段,这个过程对于应用层来说是透明的。

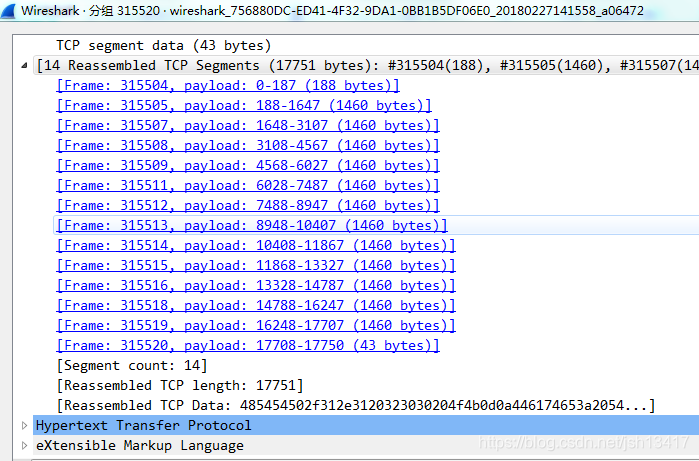
一开始我有个问题就是,根据TCP/IP的传输流可以知道,HTTP响应报文是装到TCP报文的数据区,TCP报文又是装到IP报文的数据区,而最后IP报文是装到以太网帧的数据区中。为什么以太网帧的数据区最大长度为1500字节,而HTTP报文最终是放在以太网帧的数据区中,却没有限制HTTP报文的大小?
首先根据Ethernet II类型以太网帧格式可以得知,Ethernet II类型以太网帧的最小长度为64字节,最大长度为1518字节。(另外还有7字节前导同步吗+1字节帧开始定界符是所有类型的以太网帧格式必要的)
以太网帧格式有四种类型,Ethernet II类型以太网帧格式是我通过WIRESHARK抓包后发现目前网络使用的帧格式类型。
 在WIRESHRAK抓包的时候会发现很多长度为1514的TCP报文,但是这个跟以太网帧的数据区最大长度为1518字节有什么关联吗?而且这个TCP长度为什么是1460而不是1500
在WIRESHRAK抓包的时候会发现很多长度为1514的TCP报文,但是这个跟以太网帧的数据区最大长度为1518字节有什么关联吗?而且这个TCP长度为什么是1460而不是1500

以太网封装IP数据包的最大长度是1500字节,也就是说以太网最大帧长应该是以太网首部加上1500,再加上7字节的前导同步码和1字节的帧开始定界符,具体就是:7字节前导同步吗+1字节帧开始定界符+6字节的目的MAC+6字节的源MAC+2字节的帧类型+1500+4字节的CRC校验。
按照上述,最大帧应该是1526字节,但是实际上我们抓包得到的最大帧是1514字节,为什么不是1526字节呢?原因是当数据帧到达网卡时,在物理层上网卡要先去掉前导同步码和帧开始定界符,然后对帧进行CRC检验,如果帧校验和错,就丢弃此帧。如果校验和正确,就判断帧的目的硬件地址是否符合自己的接收条件(目的地址是自己的物理硬件地址、广播地址、可接收的多播硬件地址等),如果符合,就将帧交“设备驱动程序”做进一步处理。这时我们的抓包软件才能抓到数据,因此,抓包软件抓到的是去掉前导同步码、帧开始分界符、CRC校验之外的数据,其最大值是6+6+2+1500=1514。
再说一下TCP报文内部的结构。
一个完整的数据包格式,是数据帧{IP包{TCP或UDP包{Data}}},如前所述{IP包{TCP或UDP包{Data}}}部分最大是1500字节。那么根据目前的IPv4协议,有如下规定:
IP首部,版本:4 ,包含源、目的IP、首部校验和,TTL等,共计20个字节。TCP首部,包含源、目的端口,一系列指针、标志、校验和等,共计20字节,因此实际可用的数据为1500-20-20=1460字节。
上面就解释了抓包中的1514和1460的来历。简单来说就是1514指的是以太网帧去除掉一些符号位后的最大长度;1460指的是以太网帧的数据区去除掉TCP和IP的首部后所能存储的最大数据长度,即是HTTP的整个请求或者响应报文。
上面内容转载部分
作者:晚歌y
链接:https://www.jianshu.com/p/f9a5b07d99a2
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
这篇关于VPP源码阅读---IP报文重组和分片的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





