本文主要是介绍机器学习必修课 - 交叉验证 Cross-Validation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
想象一下你有一个包含5000行数据的数据集。通常情况下,你会将约20%的数据保留作为验证数据集,即1000行。但这会在确定模型得分时引入一些随机性。也就是说,一个模型可能在一组1000行数据上表现良好,即使在另一组1000行数据上表现不准确。
运行环境:Google Colab
数据准备和预处理
!git clone https://github.com/JeffereyWu/Housing-prices-data.git
import pandas as pd
from sklearn.model_selection import train_test_split# Read the data
train_data = pd.read_csv('/content/Housing-prices-data/train.csv', index_col='Id')
test_data = pd.read_csv('/content/Housing-prices-data/test.csv', index_col='Id')
# Remove rows with missing target, separate target from predictors
train_data.dropna(axis=0, subset=['SalePrice'], inplace=True)
y = train_data.SalePrice
train_data.drop(['SalePrice'], axis=1, inplace=True)
- 删除训练数据中带有缺失目标值的行,并将目标值(
SalePrice)分离出来存储在变量y中。
# Select numeric columns only
numeric_cols = [cname for cname in train_data.columns if train_data[cname].dtype in ['int64', 'float64']]
X = train_data[numeric_cols].copy()
X_test = test_data[numeric_cols].copy()
- 从训练数据中选择了仅包含数值型数据的列,存储在变量
numeric_cols中。 - 创建了训练特征数据集
X,其中包含了数值型的特征列。 - 创建了测试特征数据集
X_test,也包含了数值型的特征列。
from sklearn.ensemble import RandomForestRegressor
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputermy_pipeline = Pipeline(steps=[('preprocessor', SimpleImputer()),('model', RandomForestRegressor(n_estimators=50, random_state=0))
])
- 上面的管道将使用
SimpleImputer()来替换数据中的缺失值,然后使用RandomForestRegressor()来训练一个随机森林模型进行预测。我们可以通过n_estimators参数来设置随机森林模型中树的数量,并通过设置random_state参数来确保结果的可重复性。
在交叉验证中,我们对数据的不同子集运行我们的建模过程,以获取模型质量的多个度量值。
例如,我们可以将数据分成5个部分,每个部分占全数据集的20%。在这种情况下,我们称将数据分成了5个“折叠”(fold)。
然后,我们对每个折叠运行一次实验:

- 在实验1中,我们将第一个折叠作为验证(或保留)集,将其他所有部分作为训练数据。这样可以基于一个20%的保留集来度量模型的质量。
- 在实验2中,我们保留第二个折叠的数据(并使用除第二个折叠之外的所有数据来训练模型)。然后,保留集用于获取模型质量的第二个估计值。
我们重复这个过程,每个折叠都曾被用作保留集。综合起来,100%的数据都会在某个时刻被用作保留集,最终我们会得到一个基于数据集中所有行的模型质量度量(即使我们不同时使用所有行)。
from sklearn.model_selection import cross_val_score# Multiply by -1 since sklearn calculates *negative* MAE
scores = -1 * cross_val_score(my_pipeline, X, y,cv=5,scoring='neg_mean_absolute_error')print("Average MAE score:", scores.mean())
- 使用
cross_val_score()函数来获取平均绝对误差(MAE),该值是在五个不同的折叠上求平均得到的。我们通过cv参数来设置折叠的数量。
Average MAE score: 18276.410356164386
定义一个函数用于评估随机森林回归模型在不同树的数量(n_estimators)下的性能。
def get_score(n_estimators):my_pipeline = Pipeline(steps=[('preprocessor', SimpleImputer()),('model', RandomForestRegressor(n_estimators, random_state=0))])scores = -1 * cross_val_score(my_pipeline, X, y,cv=3,scoring='neg_mean_absolute_error')return scores.mean()
results = {i: get_score(i) for i in range(50, 450, 50)}
- 评估随机森林模型在八个不同的树数量下的性能:50、100、150、…、300、350、400。将结果存储在一个字典
results中,其中results[i]表示get_score(i)返回的平均MAE。
import matplotlib.pyplot as plt
%matplotlib inlineplt.plot(list(results.keys()), list(results.values()))
plt.show()
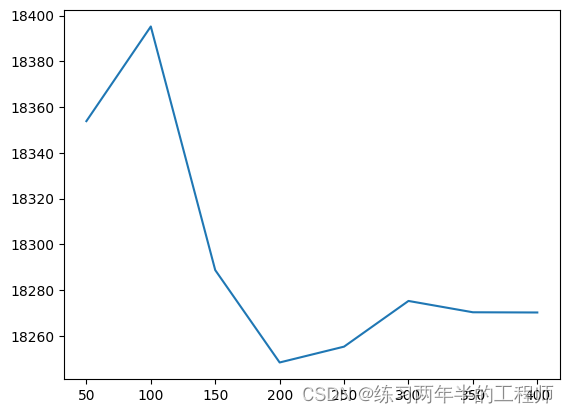
由此可见,n_estimators设为200时,可得到最佳的随机森林模型。
这篇关于机器学习必修课 - 交叉验证 Cross-Validation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





