本文主要是介绍『七夕节』叮!你收到一条小姐姐的告白,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
点击左上方蓝字关注我们


一年一度的七夕节,有人欢喜有狗愁。

在这个狂撒狗粮的节日,怎么能少得了用飞桨搞事呢?这不我来整活了,悄咪咪地把飞桨的颜值担当——依依小姐姐的照片给拿来了,再通过使用语音合成和唇部合成技术,让依依小姐姐对你说出告白~

于是乎一款拯救单身狗的神器诞生了,今年七夕单身狗不用再发愁了。飞桨语音合成套件Parakeet提供的音色克隆的能力以及飞桨对抗网络套件PaddleGAN中唇形合成的技术,轻松实现让暗恋的对象对你说出告白!

技术介绍
语音合成 Parakeet 原理
在训练语音克隆模型时,目标音色作为Speaker Encoder的输入,模型会提取这段语音的说话人特征(音色)作为Speaker Embedding。接着,在训练模型重新合成此类音色的语音时,除了输入的目标文本外,说话人的特征也将成为额外条件加入模型的训练。在预测时,选取一段新的目标音色作为Speaker Encoder的输入,并提取其说话人特征,最终实现输入为一段文本和一段目标语音,模型生成目标音色说出此段文本的语音片段,完美的实现音色克隆~
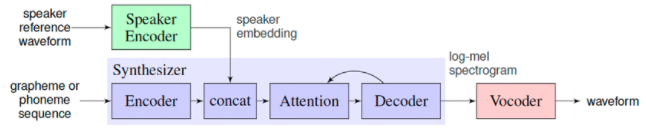
详细的Parakeet原理介绍可以上项目主页:
https://github.com/PaddlePaddle/parakeet
记得Star收藏GET所有语音合成前沿技术!
唇部合成 Wav2lip 原理
PaddleGAN中所提供的唇形合成算法——Wav2lip能够让视频或图片中的人物根据目标音频拟合唇形,将一段话自然地念出来。Wav2lip采用预训练好的唇形同步损失函数,重建损失函数以及脸部逼真度判别器,使得生成器能够产生准确而逼真的唇部运动,实现唇形与语音精准同步,从而改善了视觉质量。Wav2Lip适用于任何人脸、任何语言,对任意视频都能达到很高都准确率,可以无缝地与原始视频融合。
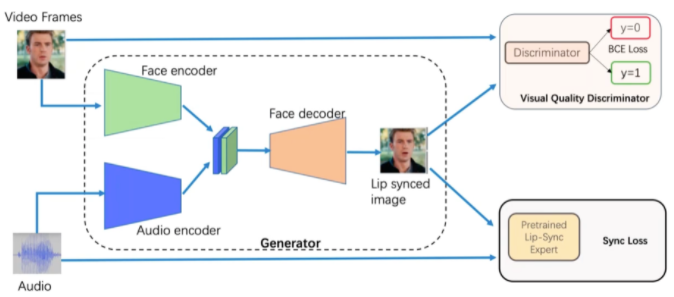
想要了解更多详情?GET更多PaddleGAN的魔法?
赶紧上项目首页,Star后立即体验!
https://github.com/PaddlePaddle/PaddleGAN/blob/develop/README_cn.md
实现流程
环境配置与数据准备
本项目基于飞桨开源框架v2.1.0。本项目使用七夕节专属语音合成数据集:依依小姐姐语音包,并已获得依依小姐姐的授权。

# 加载第99999号寓意天长地久数据集
!unzip -oq /home/aistudio/data/data99999/nltk_data.zip
!unzip -oq /home/aistudio/data/data99999/work.zip下载并安装 Parakeet 包
# 下载 Parakeet 包
!git clone https://gitee.com/paddlepaddle/Parakeet.git -b release/v0.3 work/Parakeet
# 安装 Parakeet 包
!pip install -e work/Parakeet/
# 把必要的路径添加到 sys.path,避免找不到已安装的包
import sys
sys.path.append("/home/aistudio/work/Parakeet")
sys.path.append("/home/aistudio/work/Parakeet/examples/tacotron2_aishell3")import numpy as np
import paddle
from matplotlib import pyplot as plt
from IPython import display as ipd
import soundfile as sf
import librosa.display
from parakeet.utils import display
paddle.set_device("gpu:0")
%matplotlib inline
加载语音克隆模型
from examples.ge2e.audio_processor import SpeakerVerificationPreprocessor
from parakeet.models.lstm_speaker_encoder import LSTMSpeakerEncoder# speaker encoder
p = SpeakerVerificationPreprocessor(sampling_rate=16000, audio_norm_target_dBFS=-30, vad_window_length=30, vad_moving_average_width=8, vad_max_silence_length=6, mel_window_length=25, mel_window_step=10, n_mels=40, partial_n_frames=160, min_pad_coverage=0.75, partial_overlap_ratio=0.5)
speaker_encoder = LSTMSpeakerEncoder(n_mels=40, num_layers=3, hidden_size=256, output_size=256)
speaker_encoder_params_path = "/home/aistudio/work/pretrained/ge2e_ckpt_0.3/step-3000000.pdparams"
speaker_encoder.set_state_dict(paddle.load(speaker_encoder_params_path))
speaker_encoder.eval()# synthesizer
from parakeet.models.tacotron2 import Tacotron2
from examples.tacotron2_aishell3.chinese_g2p import convert_sentence
from examples.tacotron2_aishell3.aishell3 import voc_phones, voc_tonesfrom yacs.config import CfgNode
synthesizer = Tacotron2(vocab_size=68,n_tones=10,d_mels= 80,d_encoder= 512,encoder_conv_layers = 3,encoder_kernel_size= 5,d_prenet= 256,d_attention_rnn= 1024,d_decoder_rnn = 1024,attention_filters = 32,attention_kernel_size = 31,d_attention= 128,d_postnet = 512,postnet_kernel_size = 5,postnet_conv_layers = 5,reduction_factor = 1,p_encoder_dropout = 0.5,p_prenet_dropout= 0.5,p_attention_dropout= 0.1,p_decoder_dropout= 0.1,p_postnet_dropout= 0.5,d_global_condition=256,use_stop_token=False
)
params_path = "/home/aistudio/work/pretrained/tacotron2_aishell3_ckpt_0.3/step-450000.pdparams"
synthesizer.set_state_dict(paddle.load(params_path))
synthesizer.eval()# vocoder
from parakeet.models import ConditionalWaveFlow
vocoder = ConditionalWaveFlow(upsample_factors=[16, 16], n_flows=8, n_layers=8, n_group=16, channels=128, n_mels=80, kernel_size=[3, 3])
params_path = "/home/aistudio/work/pretrained/waveflow_ljspeech_ckpt_0.3/step-2000000.pdparams"
vocoder.set_state_dict(paddle.load(params_path))
vocoder.eval()
提取目标音色的声音特征
如需使用自己的声音,上传音频至'work/ref_audio'目录,合成语音的好坏与选择的音频质量有关。目前支持音频格式为 wav 和 flac ,如有其他格式音频,建议使用软件进行转换。
ref_name = "yiyi.wav"
ref_audio_path = f"/home/aistudio/work/ref_audio/{ref_name}"
ipd.Audio(filename=ref_audio_path)mel_sequences = p.extract_mel_partials(p.preprocess_wav(ref_audio_path))
print("mel_sequences: ", mel_sequences.shape)
with paddle.no_grad():embed = speaker_encoder.embed_utterance(paddle.to_tensor(mel_sequences))
print("embed shape: ", embed.shape)
合成频谱
提取到了参考语音的特征向量之后,给定需要合成的文本,通过 Tacotron2 模型生成频谱。目前只支持汉字以及两个表示停顿的特殊符号,'%' 表示句中较短的停顿,'$' 表示较长的停顿。合成频谱呈现斜率接近 k = 1 时,合成语音的效果较好。
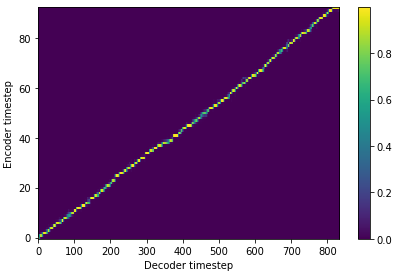
# 替换 sentence 里的内容,书写小姐姐对你的专属七夕告白
sentence = "祝%各位飞桨%开发者们$七夕%情人节%快乐$"phones, tones = convert_sentence(sentence)
print(phones)
print(tones)phones = np.array([voc_phones.lookup(item) for item in phones], dtype=np.int64)
tones = np.array([voc_tones.lookup(item) for item in tones], dtype=np.int64)phones = paddle.to_tensor(phones).unsqueeze(0)
tones = paddle.to_tensor(tones).unsqueeze(0)
utterance_embeds = paddle.unsqueeze(embed, 0)with paddle.no_grad():outputs = synthesizer.infer(phones, tones=tones, global_condition=utterance_embeds)
mel_input = paddle.transpose(outputs["mel_outputs_postnet"], [0, 2, 1])
fig = display.plot_alignment(outputs["alignments"][0].numpy().T)合成最终语音
# 使用 waveflow 声码器,将生成的频谱转换为音频。
!mkdir -p data/syn_audiowith paddle.no_grad():wav = vocoder.infer(mel_input)
wav = wav.numpy()[0]
sf.write(f"/home/aistudio/data/syn_audio/{ref_name}", wav, samplerate=22050)
librosa.display.waveplot(wav)
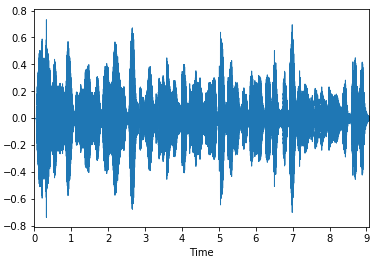
# 下载到本地,对音频进行后期处理
ipd.Audio(wav, rate=22050)
唇形合成

# 下载 PaddleGAN
%cd /home/aistudio/work
!git clone https://gitee.com/PaddlePaddle/PaddleGAN# 安装依赖
%cd /home/aistudio/work/PaddleGAN
!pip install -r requirements.txt
%cd applications/# wav2lip 让照片中的人物对口型,实现唇部合成
!export PYTHONPATH=$PYTHONPATH:/home/aistudio/work/PaddleGAN && python tools/wav2lip.py \--face /home/aistudio/'yiyi.jpg' \--audio /home/aistudio/'voice.mp3' \--outfile /home/aistudio/movie.mp4
效果展示
最后导出的’ movie.mp4’,就是依依小姐姐对你说出的七夕告白。
后期制作配上音乐可以让依依小姐姐唱情歌给你听~
项目链接:
https://aistudio.baidu.com/aistudio/projectdetail/2221888
温馨提示
请使用自己的图片和声音,使用他人的照片和声音请先获得对方的同意后再使用,以免带来不必要的麻烦。相关法律条文可参考最新版《民法典》第一千零一十九条【肖像权消极权能】。
如有飞桨相关技术问题,欢迎在飞桨论坛中提问交流:
http://discuss.paddlepaddle.org.cn/
欢迎加入官方QQ群获取最新活动资讯:793866180。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
·飞桨官网地址·
https://www.paddlepaddle.org.cn/
·飞桨生成对抗网络开发套件·
GitHub:
https://github.com/PaddlePaddle/PaddleGAN/blob/develop/README_cn.md

????长按上方二维码立即star!????
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体,是中国首个自主研发、功能丰富、开源开放的产业级深度学习平台。飞桨企业版针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。
END

这篇关于『七夕节』叮!你收到一条小姐姐的告白的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






