本文主要是介绍scrapy框架手动请求发送练习之爬取古诗文网论语全篇,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
scrapy框架手动请求发送 练习代码
- 爬取古诗文网论语全篇
- url: https://so.gushiwen.org/guwen/book_46653FD803893E4F75696240258265D2.aspx
setting配置
# Scrapy settings for handReqPro project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.htmlBOT_NAME = 'handReqPro'SPIDER_MODULES = ['handReqPro.spiders']
NEWSPIDER_MODULE = 'handReqPro.spiders'# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'handReqPro (+http://www.yourdomain.com)'# Obey robots.txt rules
ROBOTSTXT_OBEY = FalseLOG_LEVEL = 'ERROR'# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16# Disable cookies (enabled by default)
#COOKIES_ENABLED = False# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'handReqPro.middlewares.HandreqproSpiderMiddleware': 543,
#}# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'handReqPro.middlewares.HandreqproDownloaderMiddleware': 543,
#}# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {'handReqPro.pipelines.HandreqproPipeline': 300,
}# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'hand.py
import scrapy
from handReqPro.items import HandreqproItemclass HandSpider(scrapy.Spider):name = 'hand'# allowed_domains = ['www.xxx.com']start_urls = ['https://so.gushiwen.org/guwen/bookv_46653FD803893E4F699E8628DEAEE3C0.aspx']page = 2path = '//*[@class="bookvmiddle"]/a[%d]/@href'def parse(self, response):p_list = response.xpath('//p/text()').extract()p_title = response.xpath('//b/text()').extract()item = HandreqproItem()item['title'] = p_titleitem['p'] = p_listyield item# print(1)new_path = format(self.path%self.page)self.page = 3try:new_url = response.xpath(new_path).extract()except BaseException:print('爬取失败!')else:if len(new_url):print(new_url)yield scrapy.Request(url=new_url[0],callback=self.parse)else:print('爬取完毕!')item.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass HandreqproItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()title = scrapy.Field()p = scrapy.Field()pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapterclass HandreqproPipeline:fp = Nonedef open_spider(self, spider):# print('我只会在开始时执行一次')self.fp = open('./论语.docx','w',encoding='utf-8')def close_spider(self, spider):# print('我只会在结束的时候执行一次')self.fp.close()def process_item(self, item, spider):p_str = ''.join(item['p'])# print(p_str)title = item['title']print(title[0])self.fp.write(title[0]+':'+p_str+'\n\n\n')return item效果展示
- 在目录下输入命令
scrapy crawl hand
- 终端出现如下结果
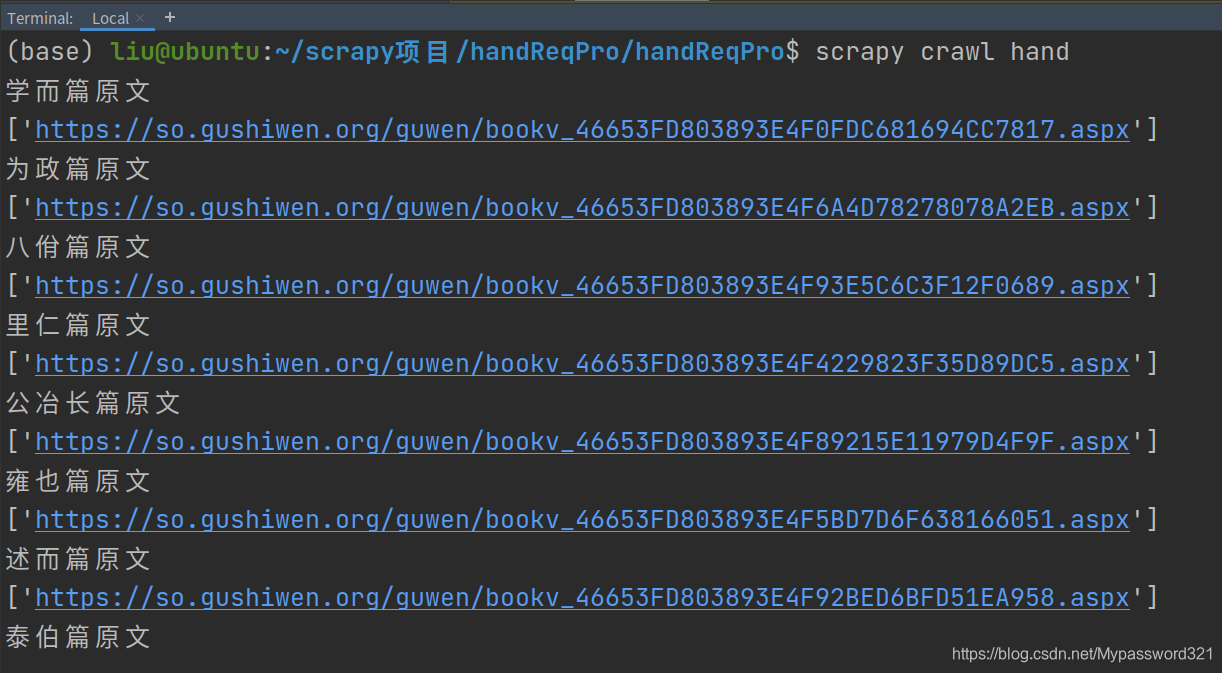
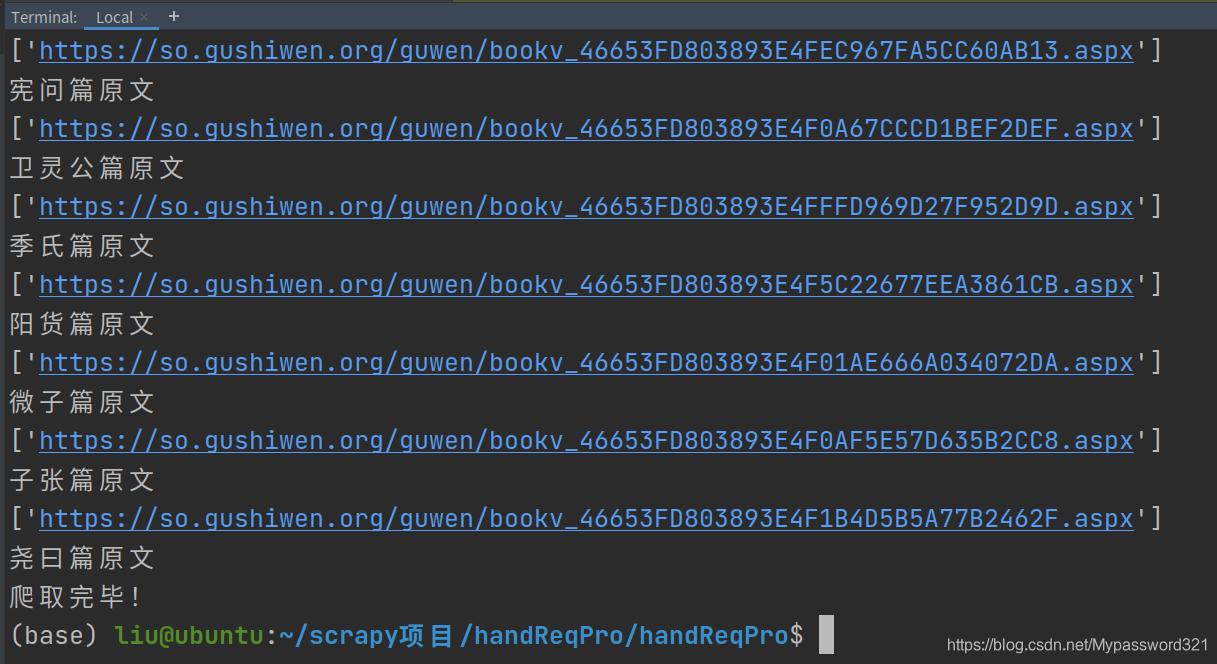
- 看看保存在本地的文件效果
- 保存为word文件

效果还不错
初学爬虫,欢迎交流学习!
这篇关于scrapy框架手动请求发送练习之爬取古诗文网论语全篇的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






