本文主要是介绍MySQL从库扩展探索,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
[导读]本文主要介绍Booking网站在业务发展过程中碰到MySQL主库挂载几十甚至上百个从库时探索的解决方案:使用Binlog Server。Binlog Server可以解决五十个以上从库时主库网络带宽限制问题,并规避传统的级联复制方案的缺点;同时介绍了使用Binlog Server还可以用于优化异地机房复制和拓扑重组后的主库故障重组。作者探索问题循序渐进的方式以及处理思路值得我们学习。
Booking网站后台有着非常复杂的MySQL主从架构,一台主库带五十个甚至有时带上百个从库并不少见。当从库到达这个数量级之后,一个必须重点关注的问题是主库的网络带宽不能被打满。业界有一个现成的但是有缺陷的的解决方案。我们探索了另外一种能更好适应我们需求的方案:Binlog Server。我们认为Binlog Server可以简化灾难恢复过程,也能使故障后从库迅速升级为新主库变得容易。下面会详细描述。
一个MySQL主库带多个复制的从库的时候,每次对主库的修改都会被每个从库请求复制,提供大量二进制日志服务会导致主库的网络带宽饱和。产生大量二进制日志的修改是很常见的,下面是两个例子:
- 在使用行模式binlog日志复制方式的实例中执行大事务删除操作
- 对一个大表执行在线结构修改操作(online schema change)
在图1的拓扑图中,假设我们在一个MySQL主库上部署100个从库,主库每产生1M字节的修改每秒都会产生100M字节的复制流量。这和千兆网卡的流量上线很接近了,而这在我们的主从复制结构中很常见。
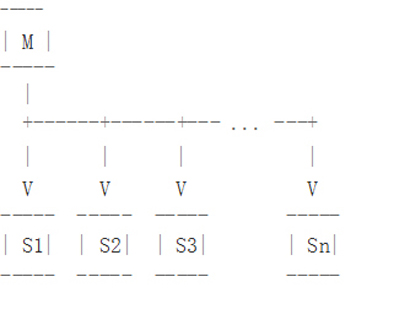
这个问题的传统解决方案是在主库和它的从库之间部署中继主库。在图2的拓扑部署中,与很多从库直接连到主库不同的是我们有几个从主库复制的中继主库,同时每个中继主库有几个下级从库。假设有100个从库和10个中继主库,这种情况下允许在打满网卡流量之前产生10倍于图1架构的二进制日志。
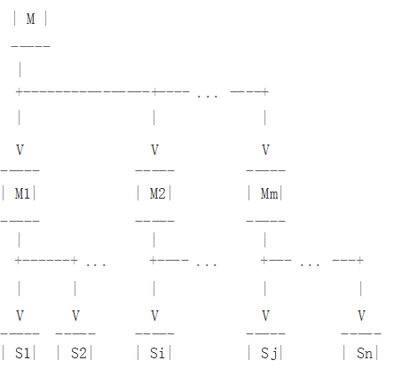
然而,使用中继主库是有风险的:
- 中继主库上的主从复制延迟将影响它的所有从库。
- 如果一个中继主库出现异常,所有该中继主库的从库将停止复制并必须重新初始化,[1] (这会带来很高的维护成本并有可能产生在线故障,译者注)
针对图2第二个问题我们可以做深入研究,一个思路是,如果M1出现故障,可以把它的从库的主库配置指向到其他中继主库,但是没那么简单。
- S1从M1复制的二进制日志依赖于M1
- M1和M2有不同的二进制日志位置(这两个库是不同的数据库,在同一时间二进制日志状态、位置可能不同,译者注)
- 手工推进S1的二进制日志位置到M2是非常难而且可能导致数据不一致。
GTID可以协助我们指向从库,但是它不能解决第一个关于延迟的问题。
实际上我们不需要中继主库的数据,我们只是需要提供Binlog二进制日志服务。同时,如果M1和M2可以提供二进制日志服务并且日志位置是相同的,我们可以很容易地交换各自的从库。根据这两点观察,我们构思了Binlog Server二进制日志服务。
Binlog Server替代图2中的中继主库,每个Binlog Server做如下事情:
- 从主库下载二进制日志
- 与主库使用相同结构(文件名和内容)保存二进制日志到磁盘
- 提供二进制日志给从库就像它们是这些从库的二级主库
当然,如果一个Binlog Server异常了,我们可以很容易地把它的从库指向到其他Binlog Server就可以。更惊喜的是,由于这些Binlog Server没有本地数据的变化,只是给下游提供日志流,相对有数据的中继主库来说,可以很好的解决延迟的问题。
我们与SkySql合作实施了Binlog Server作为一个模块的MaxScale的插件框架。你可以阅读这篇博客上的介绍SkySql MySQL复制,MaxScale和Binlog Server。
另一个案例1:避免远程站点上的深度嵌套复制
Binlog Server还能用于规避远程站点上的深度嵌套复制的问题。
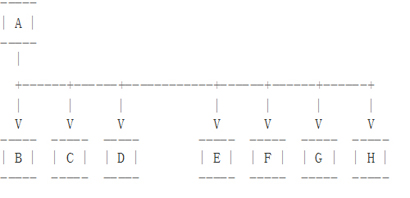
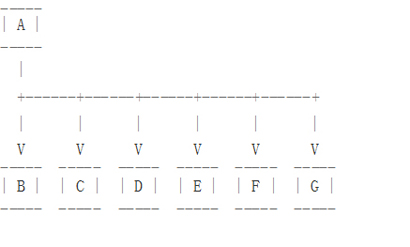
假设有两个不同地域机房,每个机房需要四个数据库服务器,当网络带宽需要特别关注的时候(E、F、G和H在远程站点),图3的拓扑图是一个典型的部署方式。

但是这个拓扑结构会受到上述讨论问题的影响(复制延迟将从E传递至F、G和H,同时E异常之后,F、G、H就会失败)。如果我们用图4的架构就好很多,但是这种架构需要更多的网络带宽,而且一旦主复制节点发生问题,异地机房从库需要重建一套新的主从架构。
在异地机房主从架构中使用Binlog Server,我们可以综合上面两种方案的优势(低带宽使用和中继数据库不产生延迟)。拓扑图如下面图5。
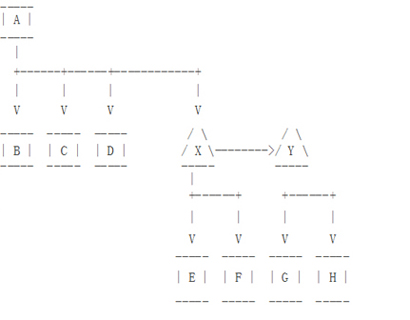
图5中的MySQL主从架构中,Binlog Server (X)看起来是一个单点,但是如果它异常了, 重新启动另外一个Binlog Server是很容易的。而且也可以像图6示例的在异地机房运行两个Binlog Servers。在这个部署中,如果Y异常了,G和H可以指向到X,如果X异常了,E和F可以指向到Y,Y可以指向到A。
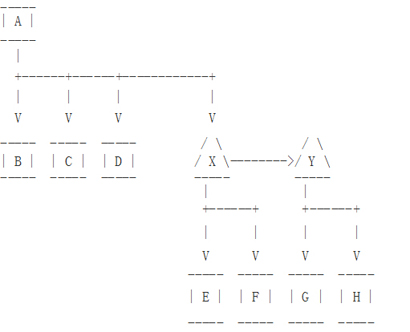
运行Binlog Servers其实不需要更多更好的硬件,在图6中,X、E、Y、G可以安装在同一台硬件服务器上。
最后,这种架构(有1个或2个Binlog Servers)有一个很有意思的属性:如果主站点的主库发生故障,异地机房从库可以收敛到完全一致的状态(只要X服务器的二进制正常)。这使得重组MySQL主从架构变得很容易:
- 任何一个从可以成为新主库
- 新主库的二进制日志位置在发送写之前会标注出来
- 其他的节点成为新主库的从库,在之前提到的二进制日志位置。
另一个案例2:简单的高可用实现
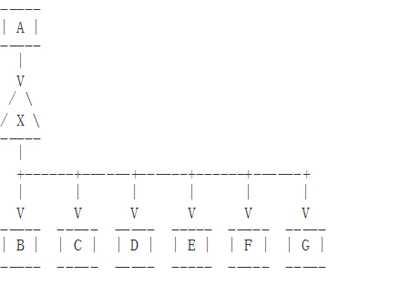
Binlog Server可以用于高可用架构的实现。假如图7主库故障了,我们希望尽快选出新的主库,我们可以部署GTIDS或使用MHA,但是他们都有缺点。
- 如果我们像图8一样在主库和从库之间部署一个Binlog Server。
- 如果X异常,我们能把所有从库指向A
- 如果A异常,所有从库会达到一个一致的状态,使得将从库重组成一个复制树变得很容易(像上面提到的)。
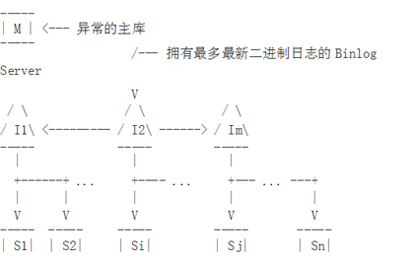
如果我们希望实现高扩展性和高可用性,我们可以部署成图9的主从架构。
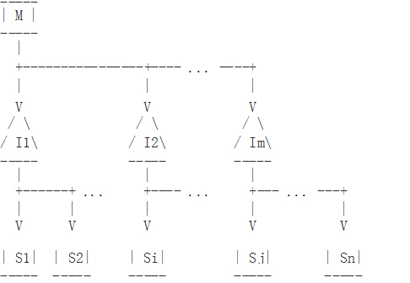
如果一个Binlog Server异常,它的从库将指向到其他Binlog Servers。如果I1失败了:
- 我们找到有跟多二进制日志的Binlog Server (我们假定在这个例子中是I2)
- 我们将其他Binlog Servers 指向到I2像图10一样。
- 当所有的从库都达到一个共同的状态,我们重新组MySQL主从架构。
结论:
我们在我们的MySQL主从架构中引入了一个新的组件:Binlog Server。它使从库水平扩展不会超越网络带宽的的限制,同时也没有传统的级联复制解决方案的缺点。
我们觉得Binlog Server还可以用于解决其他两个问题:远程站点复制和拓扑重组后的主库故障重组。后续我们将带来的Binlog Server的其他使用案例,敬请期待更多细节。
[1] 从库重新初始化的大量工作可以通过GTIDS或通过采用高可用的中继主库(DRBD或Netapp的Snapshot)来避免,但是这两个解决方案分别会带来新的问题。
英文首发网址:http://blog.booking.com/mysql_slave_scaling_and_more.html
译者简介:王林平,搜狗商业广告数据库负责人。主要负责商业广告数据库的维护、优化、架构设计、流程体系建设、自动化运维平台建设等工作,目前比较关注数据库备份恢复、性能优化、运维自动化等几个领域。
审校介绍: 柳阳,数据架构师,就职于平安健康互联网公司
责任编辑:夏梦竹(xiamz@csdn.net,关注数据库领域,欢迎投稿。)
文章来源:《程序员》2月期
版权声明:本文为《程序员》原创文章,未经允许不得转载,订阅2016年《程序员》请点击 http://dingyue.programmer.com.cn
这篇关于MySQL从库扩展探索的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





