本文主要是介绍ALI比GAN的优势在哪里?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文参考:Adversarially Learned Inference,(2017.2)作者:Vincent Dumoulin(MILA, Université de Montréal,)
原文:https://ishmaelbelghazi.github.io/ALI/
生成模型有三种:(1)VAE,(2)GAN,(3)Autoregressive approaches (这个方法我还没有学习过)。这三种方法皆有优缺点:
1、VAE,image samples from VAE-trained models tend to be blurry,即VAE生成的图像较模糊;
2、GAN,GAN-based approaches represent a good compromise: they learn a generative model that produces higher-quality samples than the best VAE techniques without sacrificing sampling speed and also make use of a latent representation in the generation process. However, GANs lack an efficient inference mechanism, which prevents them from reasoning about data at an abstract level.
3、Autoregressive approaches据文中说是生成效果不错,就是计算量太大,处理得太慢。
ALI(Adversarially Learned Inference,对抗性推断学习)模型的目标是将VAE和GAN联系起来,同时具备速度快、质量好,而且能有效推断。
此处的“有效推断”是什么?就是给定x(数据集样本),产生了什么z(隐变量),即得到以下叙述中的概率分布 q(z|x) q ( z | x ) 。GAN是由z产生x,它不管给定x产生什么z,没有从x到z的推断过程。现在ALI采用了VAE的编码器和解码器结构,于是便具有了此项推断功能,同时,它的训练过程与传统VAE不同,采用的是GAN那样的纳什均衡方式的训练方法,因此说:ALI具有VAE的实现架构,又有GAN的训练方法。实现框架提供了推断方法,训练方法提供了高质量的生成过程。具体如图1:
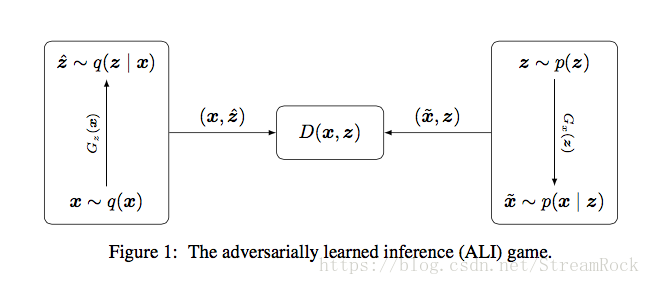
图1 ALI模型
- 图1中左边为Encoder:样本 x x 从经验分布 q(x) q ( x ) 抽样出来,经过Encoder的映射
Gz(x) G z ( x ) 得到条件分布 q(z|x) q ( z | x ) ,从中抽样出 ẑ z ^ ,由此形成一个联合分布 q(x,ẑ) q ( x , z ^ ) ,有 q(x,ẑ)=q(x)q(ẑ|x) q ( x , z ^ ) = q ( x ) q ( z ^ | x ) ; - 图1右边为Decoder:已知一个分布 z∼p(z) z ∼ p ( z ) ,例如: p(z)=N(0,I) p ( z ) = N ( 0 , I ) 标准正态分布。从该分布中抽样出一个样本 z z ,经过Decoder映射 Gx(z) G x ( z ) 得到一个条件分布 p(x|z) p ( x | z ) ,从该分布抽样出 x̂ x ^ ,于是形成一个联合分布 p(x̂,z) p ( x ^ , z ) ,有 p(x̂,z)=p(z)p(x̂|z) p ( x ^ , z ) = p ( z ) p ( x ^ | z ) ;
- 图1中间是一个判别器,它的判别函数为 D(x,z) D ( x , z ) ,它的作用是:分辨输入的联合分布样本来自 q(x,ẑ) q ( x , z ^ ) ,还是来自 p(x̂,z) p ( x ^ , z ) 。
具体的实现可以由以下伪代码来说明:

我们从实现的过程来看,ALI虽然也有Encoder和Decoder,但它们却是独立工作的,这与VAE有着巨大的差别:
1、VAE原理
VAE的 x x 和 x̂ x ^ 是有关系的: x x 经Encoder map得到条件分布 p(z|x) p ( z | x ) ,经抽样得到 ẑ z ^ ,然后再经过Decoder map得到重建 x̂ x ^ ,Loss与原样本与重建样本的距离有关: Loss∼‖x−x̂‖ L o s s ∼ ‖ x − x ^ ‖ 。
2、ALI 的Encoder与Decoder是独立工作的,它们各自生成联合分布,交由判别器判定是否相同分布,期间映射和采样都是独立进行的,这一点从它的Loss构造中可见一斑。ALI的价值函数(Value Function)是直接从GAN中继承过来的:
一般的GAN价值函数:
minGmaxDV(D,G)=Eq(x)[logD(x)] + Ep(z)[1−log(D(G(z)))]=∫q(x)logD(x)dx+∬p(z)p(x|z)[1−logD(x)]dxdz(1) min G max D V ( D , G ) = E q ( x ) [ log D ( x ) ] + E p ( z ) [ 1 − log ( D ( G ( z ) ) ) ] = ∫ q ( x ) log D ( x ) d x + ∬ p ( z ) p ( x | z ) [ 1 − log D ( x ) ] d x d z ( 1 )ALI 的价值函数是将(1)中 D(⋅) D ( ⋅ ) 的边沿分布替换成联合分布,有:
minGmaxDV(D,G)=Eq(x)[logD(x,Gz(x))] + Ep(z)[1−log(D(Gx(z),z))]=∬q(x)q(z|x)logD(x,z)dxdz+∬p(z)p(x|z)[1−logD(x,z)]dxdz(2) min G max D V ( D , G ) = E q ( x ) [ log D ( x , G z ( x ) ) ] + E p ( z ) [ 1 − log ( D ( G x ( z ) , z ) ) ] = ∬ q ( x ) q ( z | x ) log D ( x , z ) d x d z + ∬ p ( z ) p ( x | z ) [ 1 − log D ( x , z ) ] d x d z ( 2 )
匹配了 q(x,z) q ( x , z ) 和 p(x,z) p ( x , z ) ,就意味着匹配了一系列边沿分布和条件分布:
q(x)∼p(x)q(z)=p(z)q(x|z)∼p(x|z)q(z|x)∼p(z|x) q ( x ) ∼ p ( x ) q ( z ) = p ( z ) q ( x | z ) ∼ p ( x | z ) q ( z | x ) ∼ p ( z | x )
由上述关系可以完成相应的推断。
ALI的性能可以由下面一个简单实验来说明:
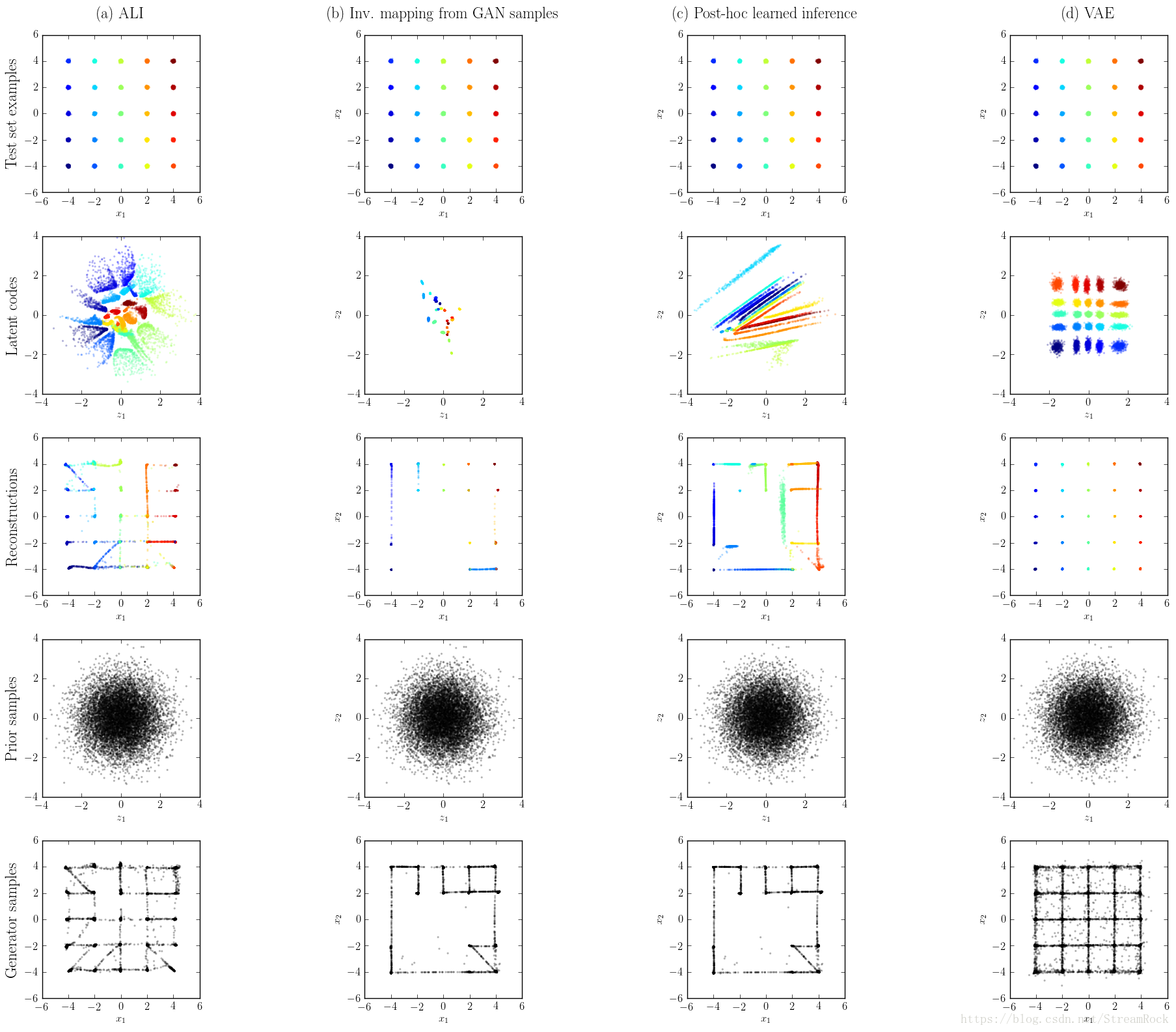
图2 各模型效果对比图
这是一个Toy dataset实验:经验分布是一个2D分布,其密度函数 q(x) q ( x ) 由25个2D高斯混合分布合成,如图中第一行。第二行是给定 x x 生成的隐变量 z z 的分布,它也是2D的。第三行是由隐变量重建样本,第四行是 z z 的先验分布: z∼N(0,I) z ∼ N ( 0 , I ) ,第5行是直接先验分布得到 z z ,并由此生成的重构样本。
由图2,GAN生成的样本模式最少,因而很容易进入模式坍塌;而VAE和ALI生成样本多样性的效果较好;VAE点与点之间的连线明显,这从一个侧面反映出VAE生成图像会较模糊;ALI既能生成多样性样本,点与点之间连线不如VAE明显,是一种较好的方案。
笔者经验:ALI的训练很困难,收敛太慢了。
这篇关于ALI比GAN的优势在哪里?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









