本文主要是介绍Hadoop起源以及Google三篇论文介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、什么是大数据?
1.1 大数据核心的问题有:
1、海量数据如何存储?2、海量数据如何计算?
1.2 大数据解决了以上两个问题。举两个例子:
1、大型电商网站的商品推荐,海量的历史的售卖数据如何存储?如何从海量的历史售卖数据中计算出盈利最大化的数据推荐给用户?2、天气预报,海量的天气数据如何存储?如何从海量的历史数据中计算预测出未来的天气?
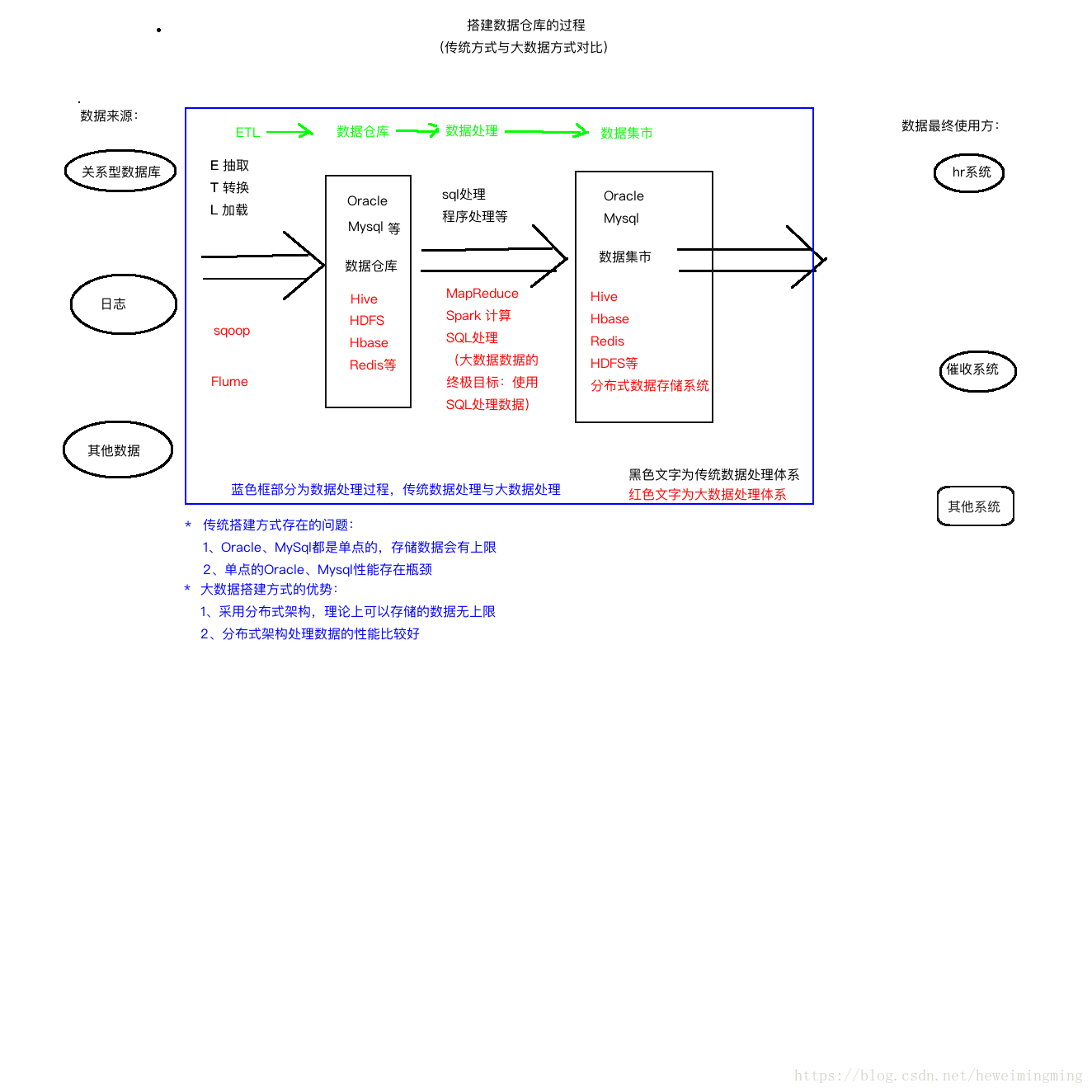
二、传统数据处理过程与大数据体系
随着数据库的增大,传统的数据处理无论是存储数据的能力还是处理数据的能力都瓶颈渐显。而大数据的诞生更好地处理了以上两个问题。传统数据处理体系与大数据体系的区别如下图:
OLTP与OLAP
OLTP:Online Transaction Processing 联机事务处理,针对小数据进行增删改。
如银行转账。
LOAP:Online Analytic Processing 联机分析处理,针对大数据的分布式处理,
通常为 select(分析).数据仓库是一种OLAP的实现。MapReduce、Spark可以看成是数据仓库的一种解决方案
三、Google三篇论文
1、《分布式文件系统》
2、《分布式计算模型》
3、《BigTable》
3.1 分布式文件系统的体系结构
3.1.1 传统的文件系统存在如下问题:
1、硬盘不够大。
2、数据存储单份,比较危险。
而Google提出的GFS(Google File System)思想能解决以上问题。GFS核心的思想是硬盘横向扩展以及数据冗余。
3.1.2 GFS的优点:
* 理论上能存储无限数据,因为硬盘可以横向扩展。
* 容错性,数据冗余多份,多份数据同时损坏的概念几乎为零。
* 存储大数据的性能比传统关系型数据库好。
3.1.3 分布式文件系统HDFS体系结构如下图:
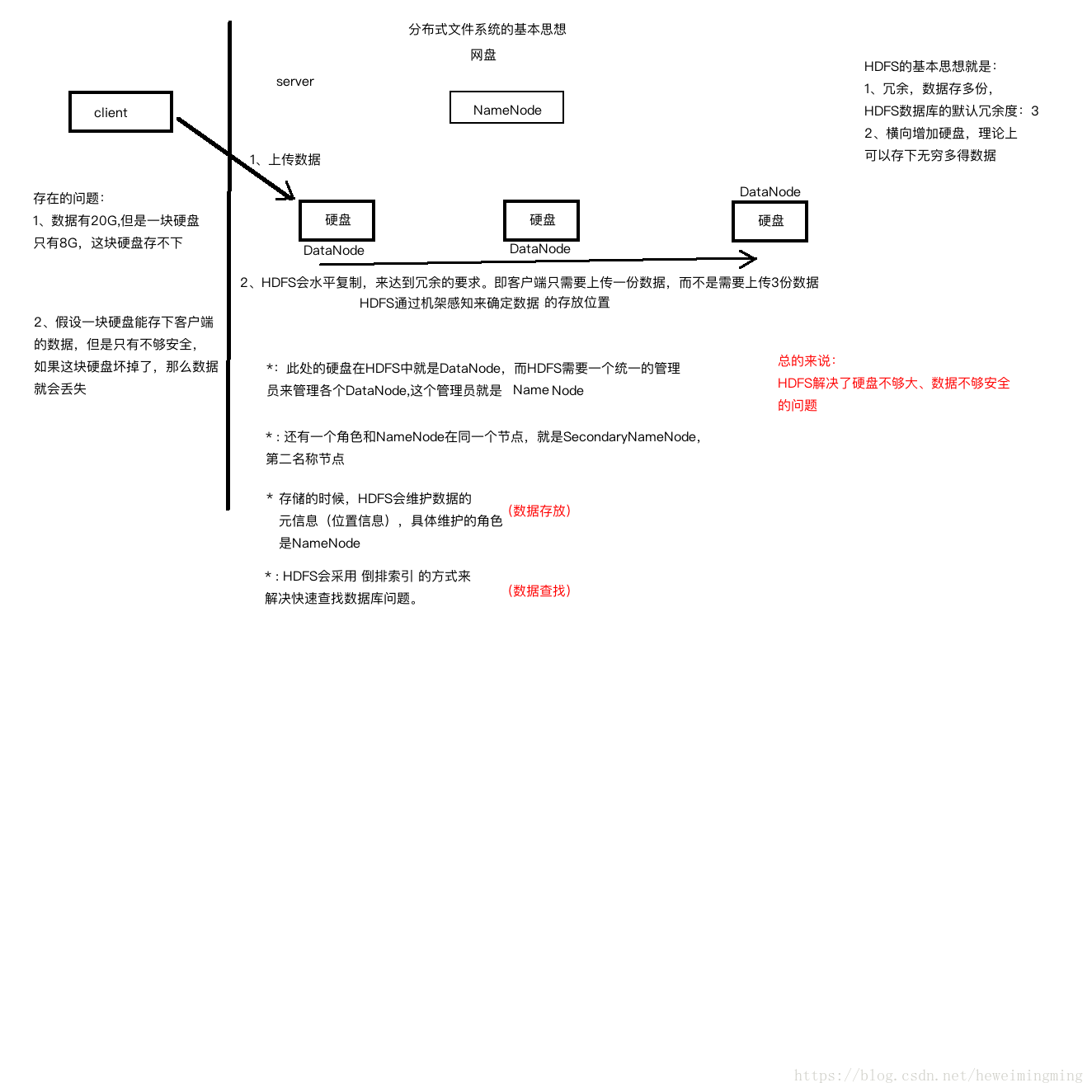
其中上传数据到分布式文件系统的基本过程如下(具体过程后面的文章再讲):
1、客户端上传数据块到其中一个硬盘。
2、分布式文件系统会根据机架感知计算出存储数据库的位置,通过水平复制冗余多份数据。
那么何为机架感知?如下图:
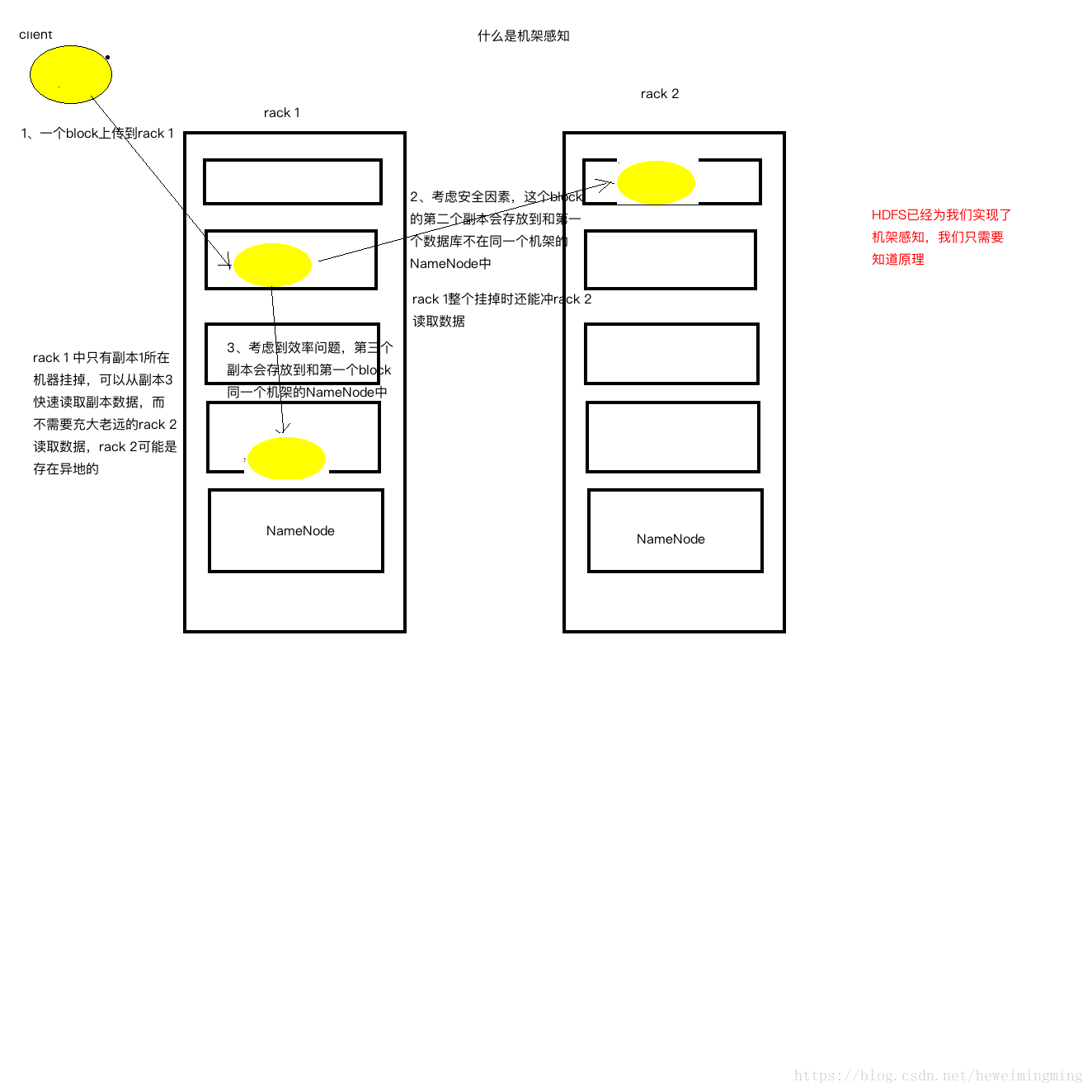
3.1.4 分布式文件系统如何提高查询速度?
(HDFS通过倒排索引存储元数据)
采用倒排索引,倒排索引本质上也是索引,那么什么是索引?
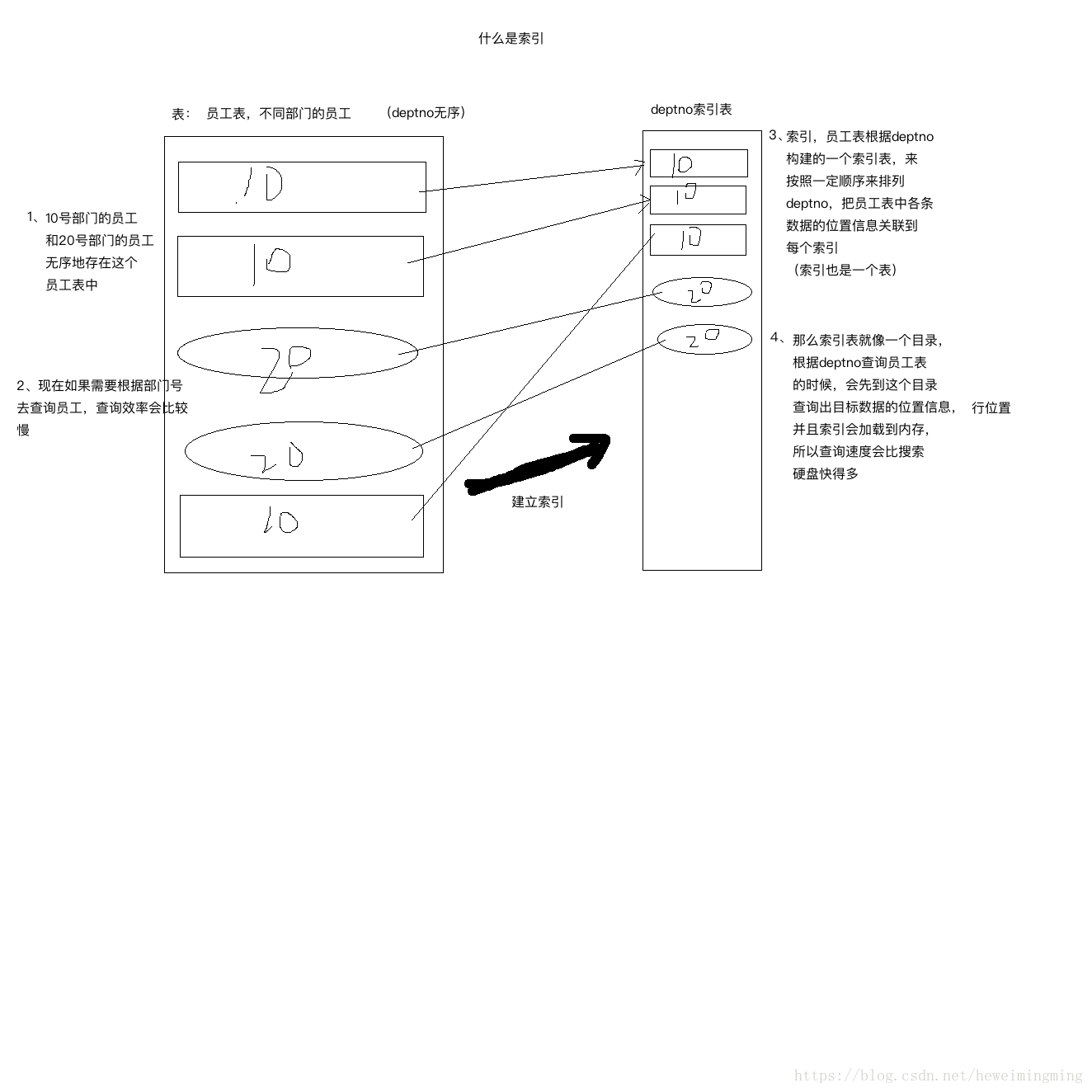
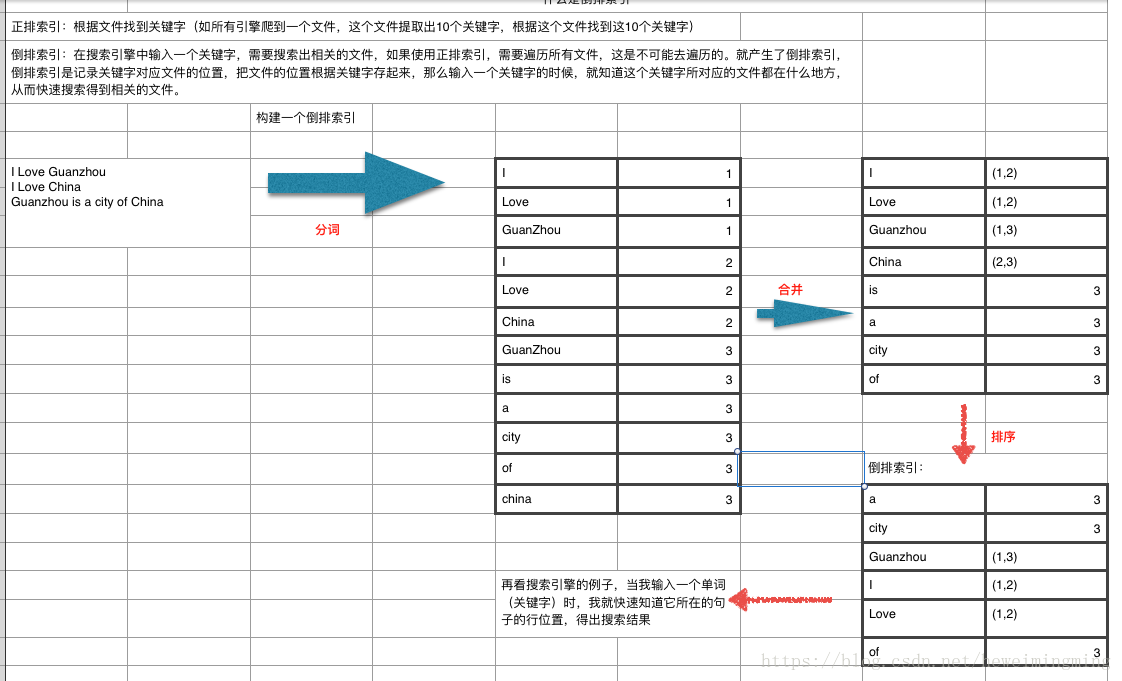
说到倒排索引能联想到正排索引。那么什么是正排索引和倒排索引。通过如下例子来说明:
正排索引:根据文件找到关键字(如所有引擎爬到一个文件,这个文件提取出10个关键字,根据这个文件找到这10个关键字)
倒排索引:在搜索引擎中输入一个关键字,需要搜索出相关的文件,如果使用正排索引,需要遍历所有文件,这是不可能去遍历的(效率太低)。就产生了倒排索引,倒排索引是记录关键字对应文件的位置,把文件的位置根据关键字存起来,那么输入一个关键字的时候,就知道这个关键字所对应的文件都在什么地方,从而快速搜索得到相关的文件。
如下图例子:
3.2分布式计算模型
3.2.1 来源:分布式计算模型来源于PageRank(网页排名)
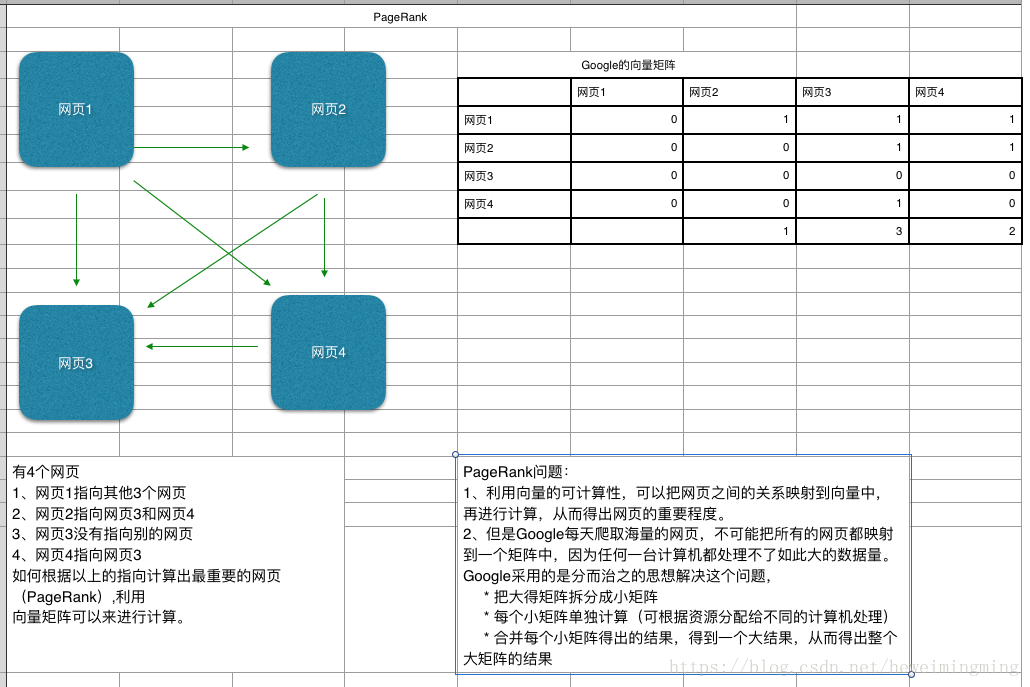
3.2.2 什么是PageRank?
Google每天爬取海量的网页,那么如果按照重要程度来排名网页,应该如何排序?
如下图例子,下图说明的是4个网页之间如何排序,核心思想是把网页之间的关系转换成矩阵,因为矩阵是可以计算的,那么可以计算出各个网页的重要程度,用数据来表示,数字越大表示越重要。但是Google每天爬取的网页数量是非常庞大的,实际上不可能用一个矩阵来计算,因此分布式计算是来解决这个问题的。核心思想是把一个大的矩阵拆分成很多足够小的矩阵,计算每个小得矩阵,再合并各个小矩阵的结果,从而得出大矩阵的结果,而这个过程是在分布式环境中运行的,如下图:
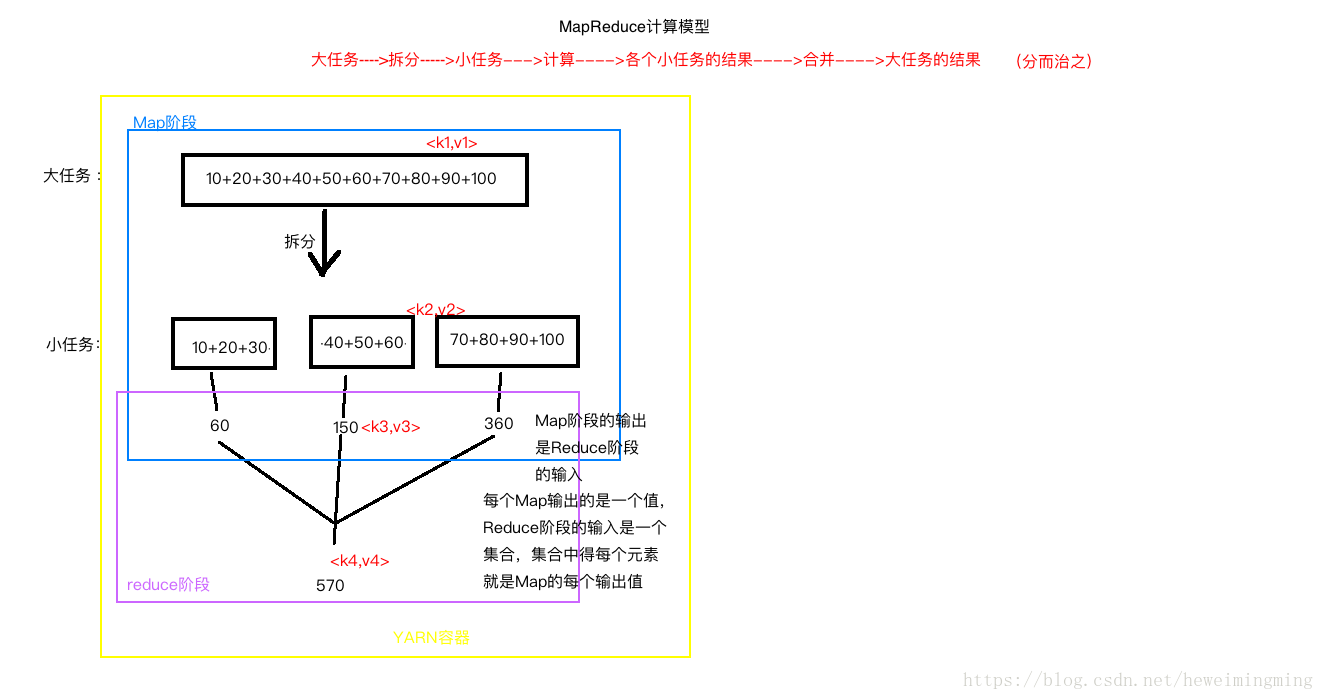
3.2.3 分布式计算框架MapReduce
关于MapReduce,有几点需要注意:
1、Map阶段的输出,是Reduce阶段的输入。每个Map输出的是一个值,Reduce阶段的输入是一个集合,集合中的每个元素就是Map的每个输出值。
2、Map的输入来自HDFS,Reduce也输出倒HDFS。
3、图中分别有4对key-value值。分别是k1 v1,k2 v2,k3 v3 ,k4 v4,分别是Map的输入,Map的输出,reduce的输入,reduce的输出。
4、k2=k3,v2的类型和v3的类型一致
5、MapReduce所有的输入输出类型必须是Hadoop的类型:LongWritable,java中得String对应Hadoop中得Text,java中得null对应hadoop中得NullWritable.
6、MapReduce的输入输出必须实现hadoop的序列化,除了原生类型,也可以是自定义类型,但必须实现hadoop序列化。
7、从hadoop2.x后,MapReduce程序必须运行在Yarn框架中,本地模式除外(本
地模式没有YARN,也没有HDFS,本地模式中的MapReduce就是一个单一的java程序)
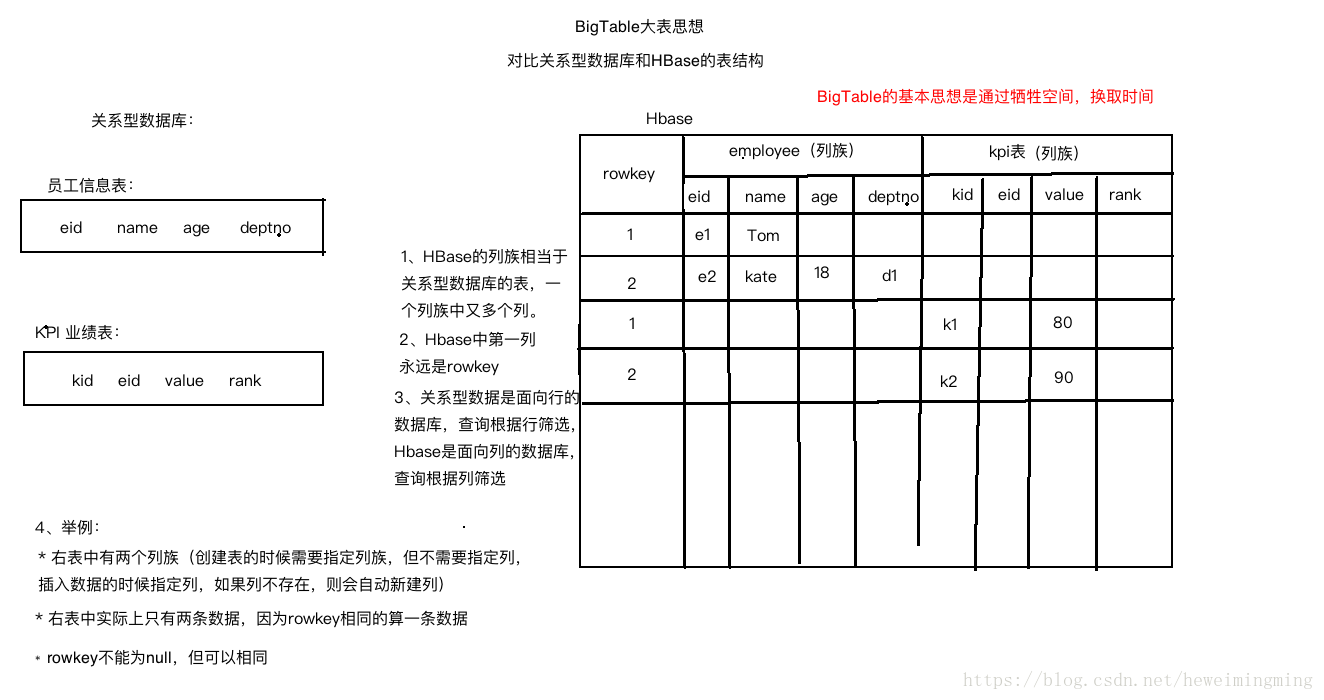
3.3 BigTable
3.3.1 大表的基本思想:把所有数据存入一张表,通过空间换取时间。
3.3.2 HBase是hadoop生态中大表的实现,看下面一个例子,对比数据存在关系型数据库Oracle和存在HBase中
这篇关于Hadoop起源以及Google三篇论文介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







