本文主要是介绍图片不压缩,前端要背锅,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大家好,好久没见,最近有点懒,很久没更新啦。这次要聊的主题是「 图片压缩」。在一般页面里面,使用最多的「静态素材」非图片莫属了,这次轮到对它动手 👊 !
背景
🎨(美术): 这是这次需求的切图 📁 ,你看看有没问题?
🧑💻(前端): 好的。
页面上线 ...
🧑💼(产品): 这图片怎么半天加载不出来 💢 ?
🧑💻(前端): 我看看 🤔 (卑微)。
... 📁(size: 15MB)
🧑💻(前端): 😅。
很多时候,我们从 PS 、蓝湖或摹客等工具导出来的图片,或者是美术直接给到切图,都是未经过压缩的,体积都比较大。这里,就有了可优化的空间。
TinyPng
TinyPNG使用智能的「有损压缩技术」来减少WEBP、JPEG和PNG文件的文件大小。通过选择性地减少图像中的「颜色数量」,使用更少的字节来存储数据。这种效果几乎是看不见的,但在文件大小上有非常大的差别。
使用过TinyPng的都知道,它的压缩效果非常好,体积大幅度降低且显示效果几乎没有区别( 👀 看不出区别)。因此,选择其作为压缩工具,是一个不错的选择。
TinyPng提供两种压缩方法:
通过在官网上进行手动压缩;
通过官方提供的tinify进行压缩;
身为一个程序员 🧑💻 ,是不能接受手动一张张上传压缩这种方法的。因此,选择第二种方法,通过封装一个工具,对项目内的图片自动压缩,彻底释放双手 🤲 。
工具类型
第一步,思考这个工具的「目的」是什么?没错,「压缩图片」。
第二步,思考在哪个「环节」进行压缩?没错,「发布前」。
这样看来,开发一个webpack plugin是一个不错选择,在打包「生产环境」代码的时候,启用该plugin对图片进行处理,完美 🥳 !
但是,这样会面临两个问题 🤔 :
页面迭代,新增了几张图片,重新打包上线时,会导致旧图片被多次压缩;
无法选择哪些图片要被压缩,哪些图片不被压缩;
虽然可以通过「配置」的方式解决上述问题,但每次打包都要特殊配置,略显麻烦,这样看来plugin好像不是最好的选择。
以上两个问题,使用「命令行工具」就能完美解决。在打包「生产环境」代码之前,执行「压缩命令」,通过命令行交互,选择需要压缩的图片。
效果演示
话不多说,先上才艺 💃 !
安装
$ npm i yx-tiny -D使用
$ npx tiny 根据命令行提示输入
流程:输入「文件夹名称-tinyImg」,接着工具会找到当前项目下所有的tinyImg,接着选择一或多个tinyImg,紧接着,工具会找出tinyImg下所有的png、jpe?g和svga,最后选择压缩模式「全量」或「自定义」,选择需要压缩的图片。
从最后的输出结果可以看到,压缩前的资源体积为2.64MB,压缩后体积为1.02MB,足足压缩了1.62MB 👍 !
然后再继续执行一遍命令再次压缩,刚刚压缩过的资源被识别出来,因为没有新增资源,所以输出「目标文件夹内」找不到「可压缩」的资源!
实现思路
总体分为五个过程:
查找:找出所有的图片资源;
分配:均分任务到每个进程;
上传:把原图上传到TinyPng;
下载:从TinyPng中下载压缩好的图片;
写入:用下载的图片覆盖本地图片;
项目地址:yx-tiny
查找
找出所有的图片资源。
packages/tiny/src/index.ts
/*** 递归找出所有图片* @param { string } path* @returns { Array<imageType> }*/
interface IdeepFindImg {(path: string): Array<imageType>
}
let deepFindImg: IdeepFindImg
deepFindImg = (path: string) => {// 读取文件夹的内容const content = fs.readdirSync(path)// 用于保存发现的图片let images: Array<imageType> = []// 遍历该文件夹内容content.forEach(folder => {const filePath = resolve(path, folder)// 获取当前内容的语法信息const info = fs.statSync(filePath)// 当前内容为“文件夹”if (info.isDirectory()) {// 对该文件夹进行递归操作images = [...images, ...deepFindImg(filePath)]} else {const fileNameReg = /\.(jpe?g|png|svga)$/const shouldFormat = fileNameReg.test(filePath)// 判断当前内容的路径是否包含图片格式if (shouldFormat) {// 读取图片内容保存到imagesconst imgData = fs.readFileSync(filePath)images.push({path: filePath,file: imgData})}}})return images
}通过命令行交互后,拿到目标文件夹的路径path,然后获取该path下的所有内容,接着遍历所有内容。首先判断该内容的文件信息:若为“文件夹”,则把该文件夹路径作为path,递归调用deepFindImg;若不为“文件夹”,判断该内容为图片,则读取图片数据,push到images中。最后,返回所有找到的图片。
分配
均分任务到每个进程。
packages/tiny/src/index.ts
// ...
cluster.setupPrimary({exec: resolve(__dirname, 'features/process.js')
})// 若资源数小于则创建一个进程,否则创建多个进程
const works: Array<{work: Worker;tasks: Array<imageType>
}> =[]
if (list.length <= cpuNums) {works.push({work: cluster.fork(),tasks: list})
} else {for (let i = 0; i < cpuNums; ++i) {const work = cluster.fork()works.push({work,tasks: []})}
}// 平均分配任务
let workNum = 0
list.forEach(task = >{if (works.length === 1) {return} else if (workNum >= works.length) {works[0].tasks.push(task)workNum = 1} else {works[workNum].tasks.push(task)workNum += 1}
})// 用于记录进程完成数
let pageNum = works.length// 初始化进度条
// ...works.forEach(({work,tasks
}) = >{// 发送任务到每个进程work.send(tasks)// 接收任务完成work.on('message', (details: Idetail[]) = >{// 更新进度条// ...pageNum--// 所有任务执行完毕if (pageNum === 0) {// 关闭进程cluster.disconnect()}})
})使用cluster,根据「cpu核心数」创建等量的进程,works用于保存已创建的进程,list中保存的是要处理的压缩任务,通过遍历list,把任务依次分给每一个进程。接着遍历works,通过send方法发送进程任务。通过监听message事件,利用pageNum记录进程任务的完成情况,当所有进程任务执行完毕后,则关闭进程。
上传
官方提供的tinify工具有「500张/月」的限额,超过限额后,需要付费。
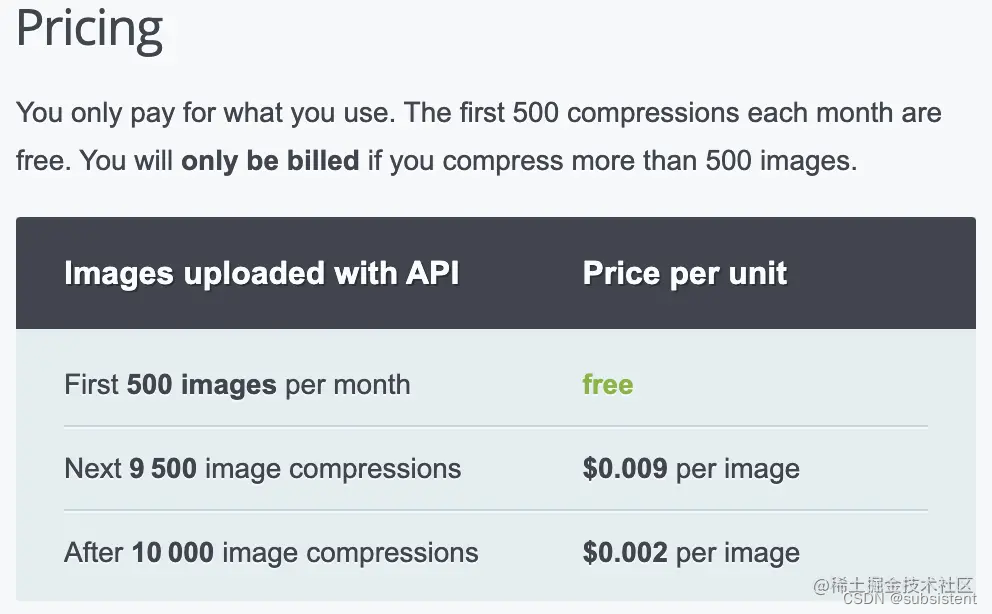
由于家境贫寒,且出于学习的目的,就没有使用tinify,而是通过构造随机IP来直接请求「压缩接口」来达到「破解限额」的目的。大家在真正使用的时候,还是要使用tinyfy来压缩,不要做这种投机取巧的事。
好了,回到正文。
把原图上传到TinyPng。
packages/tiny/src/features/index.ts
/*** 上传函数* @param { Buffer } file 文件buffer数据* @returns { Promise<DataUploadType> }*/
interface Iupload {(file: Buffer): Promise<DataUploadType>
}
export let upload: Iupload
upload = (file: Buffer) => {// 生成随机请求头const header = randomHeader()return new Promise((resolve, reject) => {const req = Https.request(header, res => {res.on('data', data => {try {const resp = JSON.parse(data.toString()) as DataUploadTypeif (resp.error) {reject(resp)} else {resolve(resp)}} catch (err) {reject(err)}})})// 上传图片bufferreq.write(file)req.on('error', err => reject(err))req.end()})
}使用node自带的Https模块,构造请求头,把deepFindImg中返回的图片进行上传。上传成功后,会返回已经压缩好的图片的url链接。
下载
从TinyPng中下载压缩好的图片。
packages/tiny/src/features/index.ts
/*** 下载函数* @param { string } path* @returns { Promise<string> }*/
interface Idownload {(path: string): Promise<string>
}
export let download: Idownload
download = (path: string) => {const header = new Url.URL(path)return new Promise((resolve, reject) => {const req = Https.request(header, res => {let content = ''res.setEncoding('binary')res.on('data', data => (content += data))res.on('end', () => resolve(content))})req.on('error', err => reject(err))req.end()})
}使用node自带的Https模块把upload中返回的图片链接进行下载。下载成功后,返回图片的buffer数据。
写入
把下载好的图片覆盖本地图片。
packages/tiny/src/features/process.ts
/*** 接收进程任务*/
process.on('message', (tasks: imageType[]) => {;(async () => {// 优化 png/jpgconst data = tasks.filter(({ path }: { path: string }) => /\.(jpe?g|png)$/.test(path)).map(ele => {return compressImg({ ...ele, file: Buffer.from(ele.file) })})// 优化 svgaconst svgaData = tasks.filter(({ path }: { path: string }) => /\.(svga)$/.test(path)).map(ele => {return compressSvga(ele.path, Buffer.from(ele.file))})const details = await Promise.all([...data.map(fn => fn()),...svgaData.map(fn => fn())])// 写入await Promise.all(details.map(({ path, file }) =>new Promise((resolve, reject) => {fs.writeFile(path, file, err => {if (err) reject(err)resolve(true)})})))// 发送结果if (process.send) {process.send(details)}})()
})process.on监听每个进程发送的任务,当接收到任务类型为「图片」,使用compressImg方法来处理图片。当任务类型为「svga」,使用compressSvga方法来处理svga。最后把处理好的资源写入到本地覆盖旧资源。
compressImg
packages/tiny/src/features/process.ts
/*** 压缩图片* @param { imageType } 图片资源* @returns { promise<Idetail> }*/
interface IcompressImg {(payload: imageType): () => Promise<Idetail>
}
let compressImg: IcompressImg
compressImg = ({ path, file }: imageType) => {return async () => {const result = {input: 0,output: 0,ratio: 0,path,file,msg: ''}try {// 上传const dataUpload = await upload(file)// 下载const dataDownload = await download(dataUpload.output.url)result.input = dataUpload.input.sizeresult.output = dataUpload.output.sizeresult.ratio = 1 - dataUpload.output.ratioresult.file = Buffer.alloc(dataDownload.length, dataDownload, 'binary')} catch (err) {result.msg = `[${chalk.blue(path)}] ${chalk.red(JSON.stringify(err))}`}return result}
}compressImg返回一个async函数,该函数先调用upload进行图片上传,接着调用download进行下载,最终返回该图片的buffer数据。
compressSvga
packages/tiny/src/features/process.ts
/*** 压缩svga* @param { string } path 路径* @param { buffer } source svga buffer* @returns { promise<Idetail> }*/
interface IcompressSvga {(path: string, source: Buffer): () => Promise<Idetail>
}
let compressSvga: IcompressSvga
compressSvga = (path, source) => {return async () => {const result = {input: 0,output: 0,ratio: 0,path,file: source,msg: ''}try {// 解析svgaconst data = ProtoMovieEntity.decode(pako.inflate(toArrayBuffer(source))) as unknown as IsvgaDataconst { images } = dataconst list = Object.keys(images).map(path => {return compressImg({ path, file: toBuffer(images[path]) })})// 对svga图片进行压缩const detail = await Promise.all(list.map(fn => fn()))detail.forEach(({ path, file }) => {data.images[path] = file})// 压缩bufferconst file = pako.deflate(toArrayBuffer(ProtoMovieEntity.encode(data).finish() as Buffer))result.input = source.lengthresult.output = file.lengthresult.ratio = 1 - file.length / source.lengthresult.file = file} catch (err) {result.msg = `[${chalk.blue(path)}] ${chalk.red(JSON.stringify(err))}`}return result}
}compressSvga的「输入」、「输出」和compressImg保持一致,目的是为了可以使用promise.all同时调用。在compressSvga内部,对svga进行解析成data,获取到svga的图片列表images,接着调用compressImg对images进行压缩,使用压缩后的图片覆盖data.images,最后再把data编码后,写入到本地覆盖原本的svga。
最后
再说一遍,大家真正使用的时候,要使用官方的tinify进行压缩。
参考文章:
protobuf.js
SVGAPlayer-Web-Lite
tinify
祝大家生活愉快,工作顺利!
「 --- The end --- 」
这篇关于图片不压缩,前端要背锅的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







