本文主要是介绍MOT论文阶段性总结(一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
第一周总结
- JRMOT: A Real-Time 3D Multi-Object Tracker and a New Large-Scale Dataset
- 贡献
- 方法:
- A Baseline for 3D Multi-Object Tracking
- 贡献:
- 方法:
- 3D MOT metrics:
- LCD: Learned Cross-Domain Descriptors for 2D-3D Matching
- 贡献:
- 数据:
- 方法:
- Tracking without bells and whistles
- 背景 and 动机:
- 方法:
- 主体 (Tracktor)
- 扩展 (Tracktor++)
JRMOT: A Real-Time 3D Multi-Object Tracker and a New Large-Scale Dataset
贡献
- 利用深度学习融合 2D 和 3D 信息,提出一个事实在线的 3D 的 MOT 系统
- 贡献了一个 2D+3D 的数据集,此方法作为他们 benchmark 的 baseline
- 效果比较不错
方法:
2D 和 3D 融合的多模态 tracking
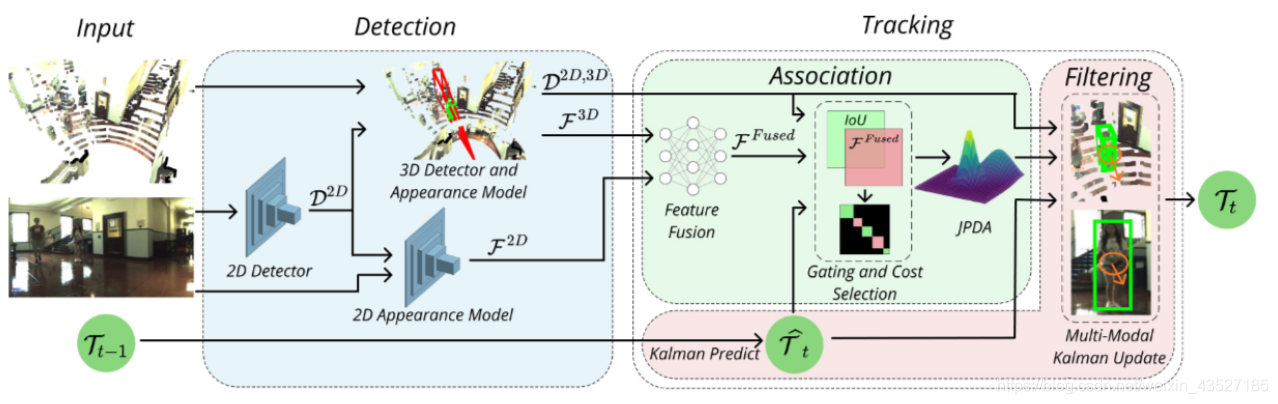
2D detection: Mask R-CNN
2D appearance: reID 方法,对于人的特征:[Aligned-ReID: Surpassing human-level perfor- mance in person re-identification];对于车的特征:[Vehicle re-identification with the space-time prior]
3D detection and appearance: F-pointnet,截取 2D 的 detection 结果的锥形点云进行 3D 的 detection,作者认为 F-pointnet 之所以能检测出物体,说明学到了形状信息,特征就选取倒 数第二层的 feature 作为 appearance
Feature fusion: 将 2D 和 3D 的特征 concat 起来,利用 triplet loss 和 semi-hard negative mining 对 FC layers 进行训练。(截止目前,该模块还未开源)
Data association: 构造 appearance 和 3D IoU 两个 cost matrix,通过一种 entropy measure 的方 法来选择我需要哪个 cost matrix,对每一个 track 的 gating 范围内的 detection 进行 JPDA 式 的关联
Filter: 没细看,也是传统方法
A Baseline for 3D Multi-Object Tracking
贡献:
- 简单但精准的 3D MOT baseline,并且很实时
- 提出一个新的 3D MOT 的评价标准
- KITTI benchmark 上准且快(已不是 sota) 方法:纯点云的 3D tracking
方法:
纯LiDAR(或者Pseudo-LiDAR)的 3D tracking
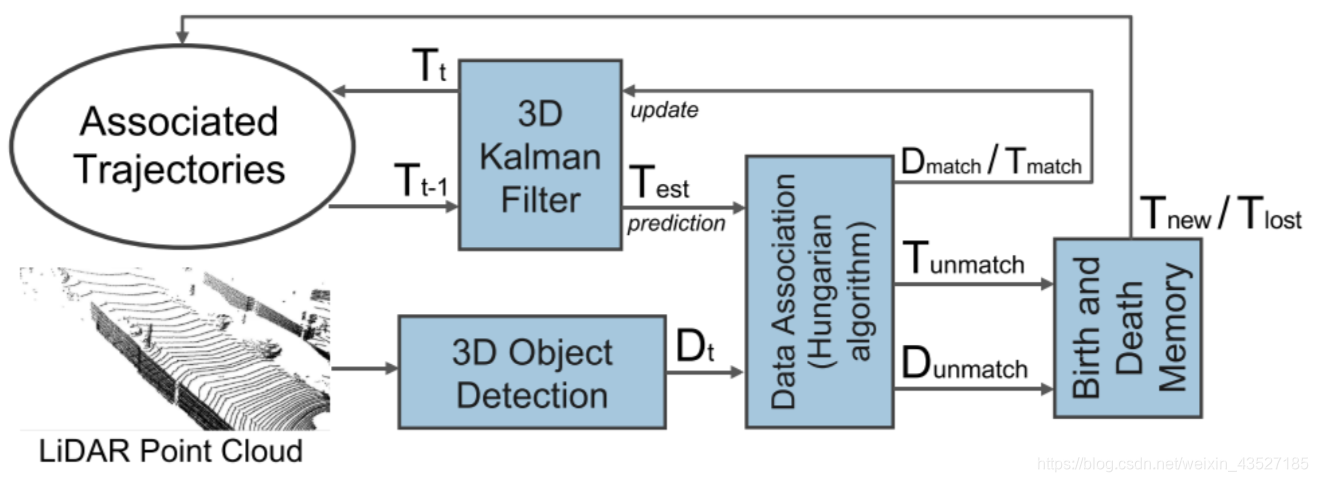
3D detection: PointRCNN输出bounding box和检测结果
Filter-based prediction: 卡尔曼滤波预测 track
Data association: Hungarian algorithm 进行 track 和 detection 的关联
Filter-based update: 对预测的跟踪状态进行更新
3D MOT metrics:
-
将传统 2D IoU->3D IoU 就成了新的 3D MOT 的评价标准
-
发现 MOTA 评价指标和 recall 成线性关系,想刷榜只要调一个合适的阈值就能达到高的 MOTA,因此提出 AMOTA,既然有了 AMOTA,那也不差顺便提个 AMOTP 了,相当于在 recall 维度上取一个平均值,由于 MOTA 永远小于等于当前的 recall,所以 AMOTA 最大值 肯定不会超过 50% (详细解释可以见原文),所以又提出带尺度缩放的 sMOTA 和 sAMOTA
LCD: Learned Cross-Domain Descriptors for 2D-3D Matching
贡献:
- 利用 2D 和 3D 的 auto encoder 学习一个 cross-domain 的通用 feature
- 贡献了一个数据集
- 利用新提的 feature 进行了 2D 图片匹配,3D 点云匹配,2D-3D 场景识别的任务,表现都很好
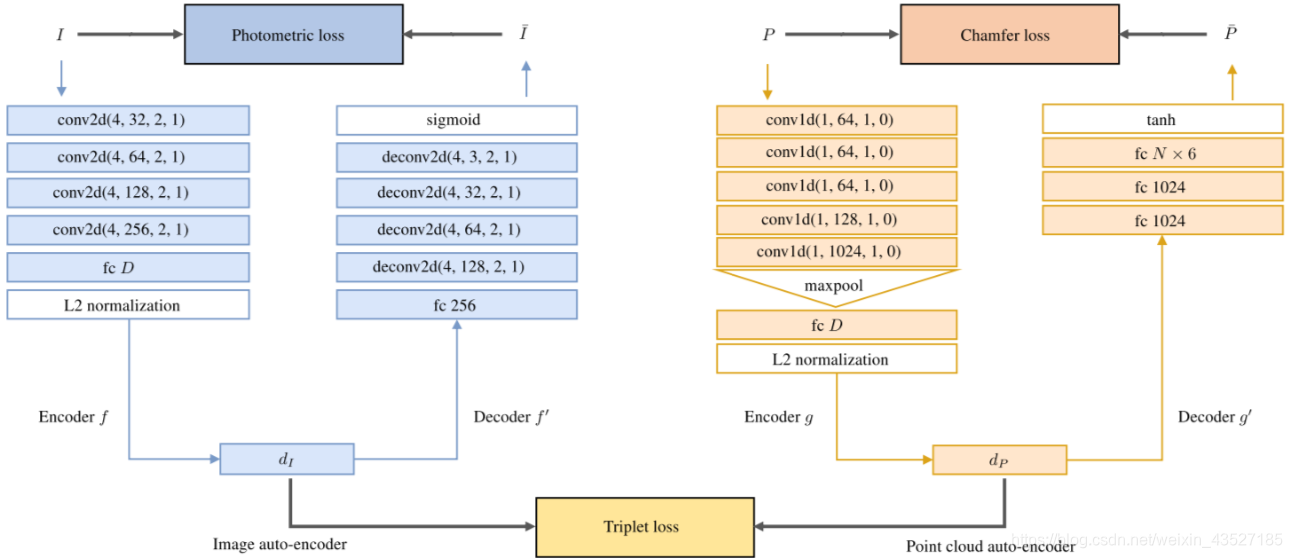
数据:
RGB 图片,RGBD 点云
方法:
如图所示。个人觉得是一个很有前景的方向,对如何joint利用2D和3D的feature提供一个解决思路。相似类型的工作有一篇 [2D3D- MatchNet: Learning to match keypoints across 2D image and 3D point cloud]
附: 与作者联系了解到点云如果不提供 RGB 信息效果不好,并且做过图片和 LiDAR 形式的点云实验,效果是 promising 的,可以尝试。
Tracking without bells and whistles
背景 and 动机:
MOT Tracking 发展缓慢,经过两年发展效果提了才两个点。作者发现通过仅仅利用物体检测算法,如 Faster rcnn,就可以达到 state of the art 的效果, 打破了普通的 data association 和 filter 那一套老框架。
方法:
2D MOT,仅用detector实现的tracking

主体 (Tracktor)
Bounding box regression:
- 蓝色箭头所示,通过将 t-1 帧的 boundingbox b t − 1 k \mathbf{b}_{t-1}^{k} bt−1k 进行回归,得到第 t 帧 新的位置 b t k \mathbf{b}_{t}^{k} btk 。对应了FasterRCNN在当前帧的 featuremap 上进行 RoIPooling 操作,但是用的 是前一帧的 bbox。作者提出这种做法的一个假设就是:两帧之间的运动不是很明显, 特别是在高帧率的视频上。这个 identify 就自动的从之前的结果上迁移过来了,从而有 效的得到了新的轨迹。这种操作可以对所有的视频帧进行重复处理。
- 在 bbox 回归以后,作者的跟踪器考虑两种情况来 kill 一个轨迹——一个物体在视频帧中消失了,或者被其他物体被遮挡了,即:如果新的 classification score 小于某一阈值;不同物体之间的遮挡,可以通过采用 NMS 来处理。
Bounding Box Initialization:
为了处理新出现的物体,物体检测器提供了整个帧的检测结果 D t \mathcal{D}_{t} Dt,红色箭头部分(包含第 一帧的初始化)。但是,从 D t \mathcal{D}_{t} Dt 开始的检测,当且仅当 IoU 与任何已有的 active tracks b t k \mathbf{b}_{t}^{k} btk 小于某一阈值。即,考虑一个物体为新的 id,如果我们无法用任何已有的 track来描述该物体。
Bounding Box Initialization:
为了处理新出现的物体,物体检测器提供了整个帧的检测结果 D t \mathcal{D}_{t} Dt,红色箭头部分(包含第 一帧的初始化)。但是,从 D t \mathcal{D}_{t} Dt 开始的检测,当且仅当 IoU 与任何已有的 active tracks b t k \mathbf{b}_{t}^{k} btk 小于某一阈值。即,我们考虑一个物体为新的 id,如果我们无法用任何已有的 trajectory 来描述该物体。
扩展 (Tracktor++)
运动补偿和 reID:
相机运动会造成第一步 bounding box 回归不准,所以要进行运动补偿; 为防止跟踪丢帧(不是 dead 的轨迹却 kill 掉了),利用 short-term reID 的方式(借助 Siamese Network 来进行 appearance feature 的匹配)来改善效果。为了达到这个目标,作者将kill的目标,存储固定帧数的样本。然后将这些样本和新检测的目标进行重识别。
这篇关于MOT论文阶段性总结(一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





