本文主要是介绍操作系统原理 实验二 《内存分配回收Allocation Reclaim》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
提示:实验源码见最下方
目录
一、实验目的
二、实验内容
三、实验方法
四、实验步骤
1.需求分析
2.概要设计
五、实验代码
六、实验结论
七、实验小结
一、实验目的
帮助了解在不同的存储管理方式下,应怎样实现主存空间的分配和回收。
二、实验内容
主存储器空间的分配和回收
在可变分区管理方式下,采用最先适应算法实现主存空间的分配和回收。
三、实验方法
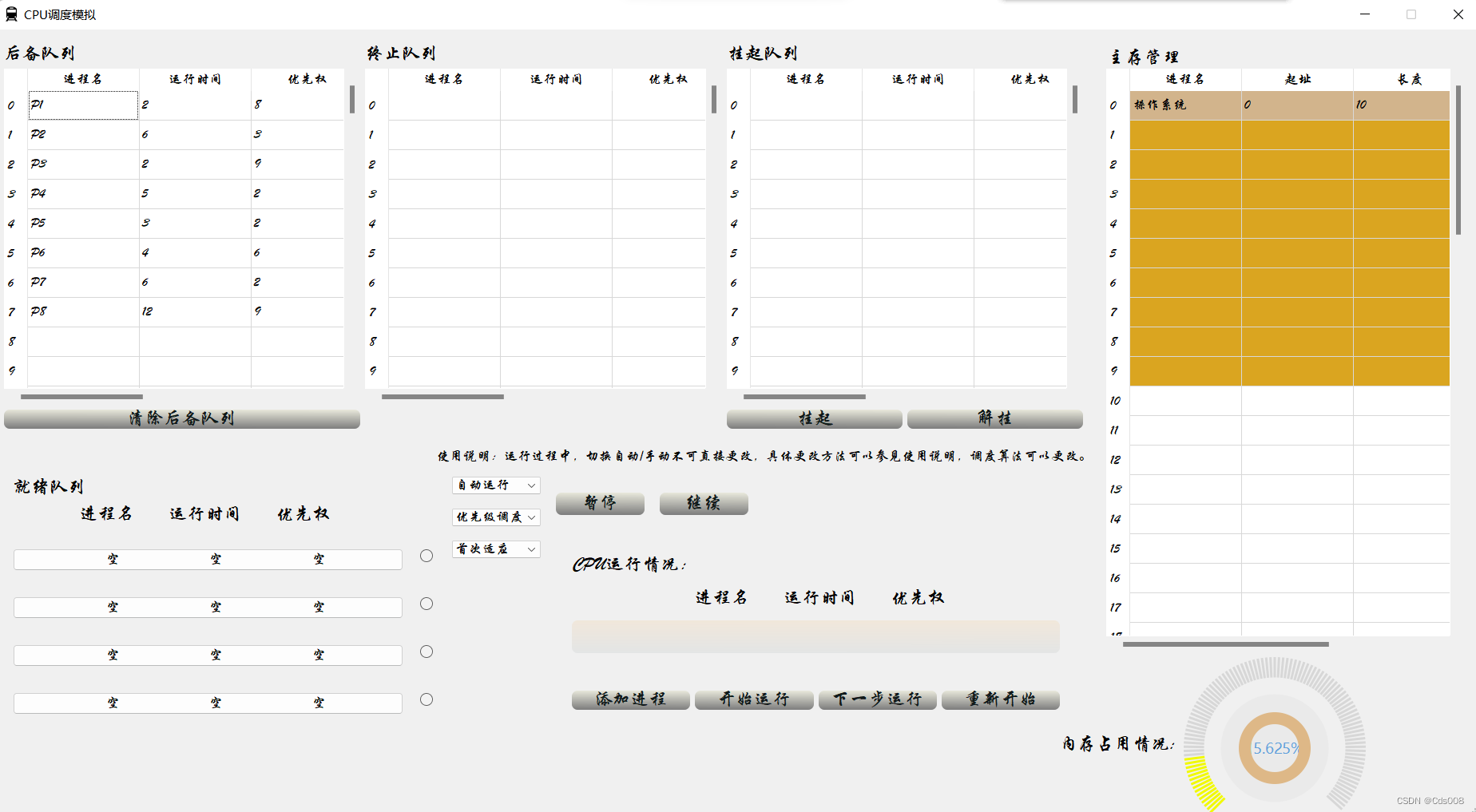
本实验程序基于Qt,实现了内存分配和回收算法的图形化显示。可以直观地看到内存的分配情况。
1、自行假设主存空间大小,预设操作系统所占大小并构造未分分区表;
表目内容:起址、长度、状态(未分/空表目)
2、结合实验一,PCB增加为:
{PID,要求运行时间,优先权,状态,所需主存大小,主存起始位置,PCB指针}
3、采用最先适应算法分配主存空间;
4、进程完成后,回收主存,并与相邻空闲分区合并。
四、实验步骤
1.需求分析
1、自行假设主存空间大小,预设操作系统所占大小并构造未分分区表;
表目内容:起址、长度、状态(未分/空表目)
2、结合实验一,PCB增加为:
{PID,要求运行时间,优先权,状态,所需主存大小,主存起始位置,PCB指针}
3、采用最先适应算法分配主存空间;
4、进程完成后,回收主存,并与相邻空闲分区合并。
2.概要设计
- 构建数据结构:
构建一个MemoryItem类,来存储未分分区表表目的内容。其属性如下:
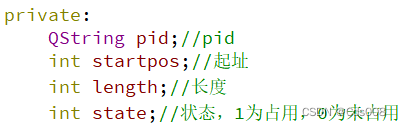
在pcbcontroller类中新增一个MemoryList用来存储表目信息。

在mainwindow界面中新增一个tableview以显示主存信息
新增一个dashboard类显示仪表盘
2.构建后台内存分配和回收的方法


3.新增前端显示主存tableView的方法,并且改写开始运行,下一步运行,挂起等按钮的逻辑。(部分方法):
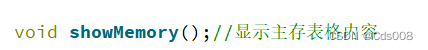
4.设计仪表盘
重绘事件:触发界面重绘;
传入的值的参数更新展示的值,触发事件重绘;
绘制:最外围的线、中心最外层背景、中心文字背景、中心文字
五、实验代码
见文章最下面的链接
六、实验结论
最优适应分配算法的效率并不高(不仅要进行排序,还需要遍历),但是可以节省大空间,保证后来的进程尽量有空间可用;最差适应分配算法的分配效率应该是最高的,但是对空间的浪费比较多,不能保证后来的进程(特别是内存占用较大的进程)的空间分配;而最先适应分配算法应该是处于二者之间。三种算法各有优劣势,需要根据系统的具体分配情况斟酌考虑使用。
七、实验小结
本次实验,通过展示未分分区表和主存32KB空间的占用情况,使得自己在直观上更加理解了三种分配算法的不同(因为事先就决定了新加入的进程颜色要有区别,所以新加入的进程进入了哪块内存空间很明显,然后是未分分区表的数值、记录条数的变化也比较明显);其次是内存合并算法,其实可以分两种方式实现:一是遍历整个未分分区表,相邻记录之间符合条件则进行合并;二是直接在该记录的下标上下相邻记录之间进行判定,符合条件则进行合并,显然前者比较潦撇(代码容易写),后者效率较高。最后是紧缩算法,需要获取总内存剩余空间,然后删除所有未分分区表记录后新加一条记录,这是对未分分区表的操作;紧缩还包含程序自身的内存浮动:将所有在内存中的进程组成集合,按照内存起址排序,然后结合占用空间将它们首尾相接,最后更新各个容器,总之实现起来还比较繁琐,需要详细的事先规划。
(本实验代码开源在https://github.com/cds007/CPU-Schedule-OS 上)
界面展示:
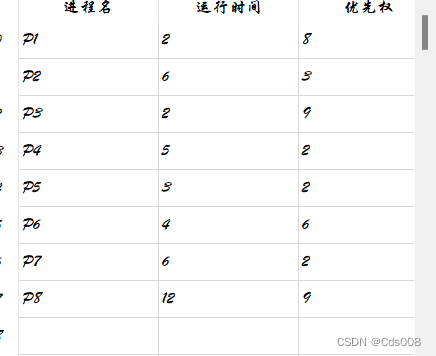
执行数据:
开始运行后的第一次显示:

(本实验代码开源在https://github.com/cds007/CPU-Schedule-OS 上)
声明:部分功能实现原理来自于网络,侵删!
这篇关于操作系统原理 实验二 《内存分配回收Allocation Reclaim》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




