本文主要是介绍机器学习之加州房价预测(二),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
上一部分介绍了软件的安装与配置,这一部分主要是接下来比较重要的部分。
六、创建测试集与训练集
在这一阶段保留部分数据听起来可能有些奇怪。在我们决定要用哪种算法之前,我们应该去了解整体。这是真的,但是你的大脑是一个惊人的模式检测系统,这意味着它容易过度拟合:如果你查看测试集,你可能会无意中发现一些测试数据中的有趣模式,它引导选择特定类型的机器学习模型。当我们使用测试估计泛化错误时设置,我们的估计将过于乐观,于是我们将启动一个系统,将不会表现和预期一样好,这叫做数据窥探偏差。
创建一个测试集是比较简单的,我们只需要随机选择一些例子,一般是数据集的20%,然后把它们放在一边。
由于测试数据是随机选取,因此每次运行这个程序,测试集数据并不相同。要想使每次测试集产生的均相同,只需给定特定的random_state。这一步主要引用的是Scikit-Learn包,这个包可以将数据集分成许多不同的子集。

设置test_size为0.2,random_state=42。
查看一下测试集的前几行:
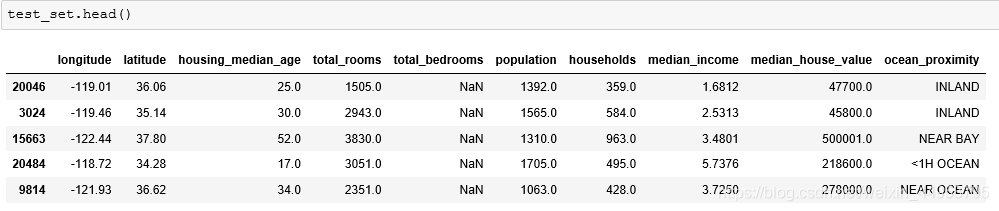
这样我们是采用的随机抽样的方法,但当数据集不够大的时候。采用这种方法有采样偏差的风险。
如果专家告诉你,收入中位数是一个非常重要的参数,那么你需要保证测试集与整个数据集在收入中位数这个特征上的分布一致。
下面的代码通过将中间收入除以1.5(以限制收入类别的数量)并使用ceil(以具有离散类别)进行舍入,然后将大于5的所有类别合并到类别5中来创建收入类别属性。

现在我们可以根据收入类别进行分层抽样了。我们可以用Scikit-Learn里面 的StratifiedShuffleSplit类。
 我们可以通过查看整个数据集的收入类别来看一下是否达到了预期的目的。
我们可以通过查看整个数据集的收入类别来看一下是否达到了预期的目的。
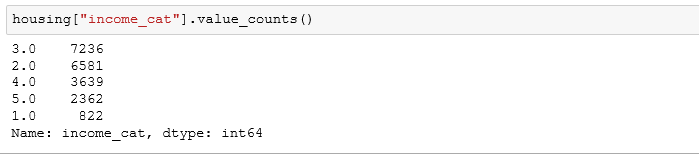
我们花了相当大的时间在测试集的建立上,但这对于机器学习来说是十分有必要的。
七、进一步探索和分析数据
到目前为止,我们只是快速浏览了一下数据,就可以大致了解正在操作的数据类型。现在的目标是更深入一步。
首先,确保你已经把测试设置放在一边,你只是在训练集上进行操作。此外,如果训练集非常大,您可能需要对测试集进行采样,以使操作简单快速。在我们的例子中,这个集合非常小,所以你可以直接在整个集合上工作。让我们创建一个副本,以便您可以在不损害训练集的情况下使用它:

用图形化表示
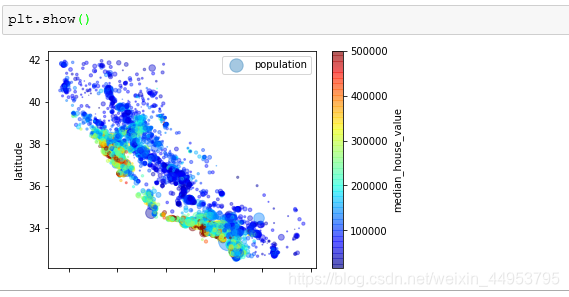
下面我们查看房价与地理位置、人口的关系。可以知道,房价与人口以及位置密切相关;人口密度越高、离海岸越近,价格也越高。
我们通过程序语句来看一下具体的可视化图像。
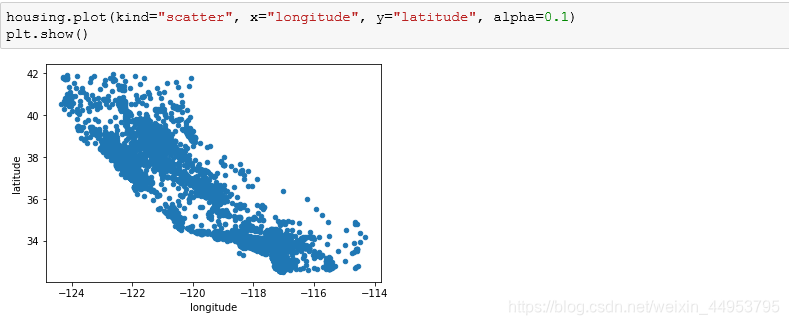
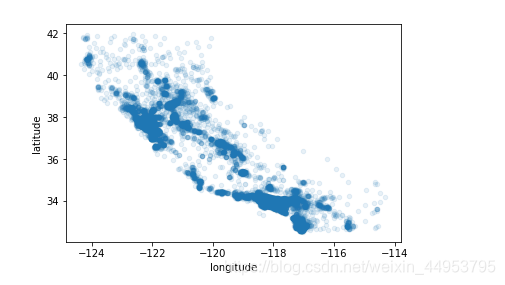
其中的alpha=0.1是将图像中高密度的点更加形象的展示出来。
其实可以做到更好:把房价和地理位置通过地图和不同的颜色展现出来。“s”表示了街区的人口,“c”表示的是价格的不同颜色,“cmap”是颜色地图,从低价到高价。

查看特征间的相关性
因为这个数据集并不是很大,所以我们可以很容易的计算每个特征之间的标准相关性。首先来分析一下相关系数:
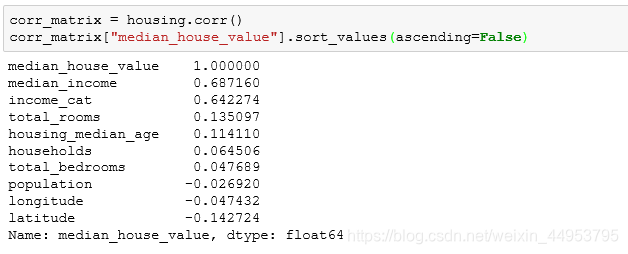
从结果中可以看到,相关系数大小是从-1到+1的,接近1时表示相关性很大,接近-1时表示相关性很小,或者说几乎没有相关性。我们可以看到,房屋价值的中位数趋向于当收入中位数上升时上升。当系数接近-1时,表示有很强的负相关性;你可以看到一个很小的负相关性在纬度和房屋中值之间(即,价格有轻微的趋势你往北走的时候就越低)。最后,接近零的系数意味着线性相关。
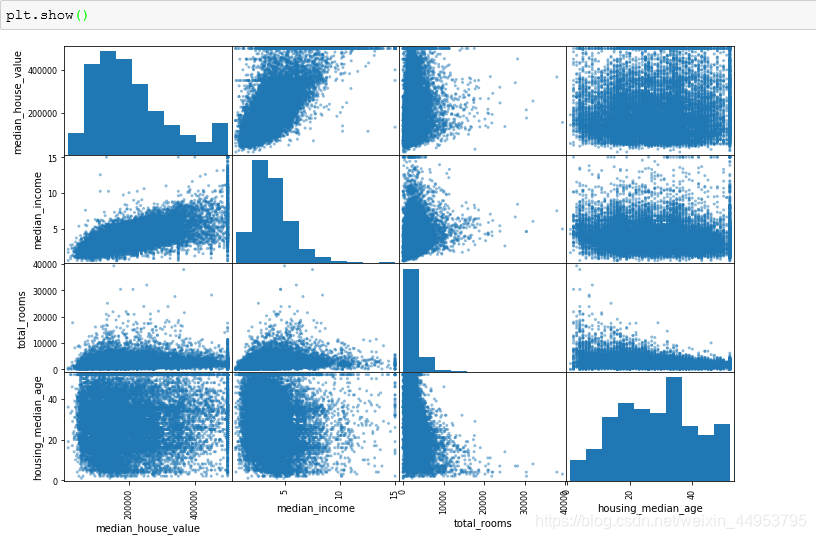
另一种查看相关性的办法就是画图更加直观,采用Pandas的scatter_matrix。如果我们有11中特征,那么我们就会有11*11=121个图。

让我们来看一下房子的价值和平均收入之间的关系:
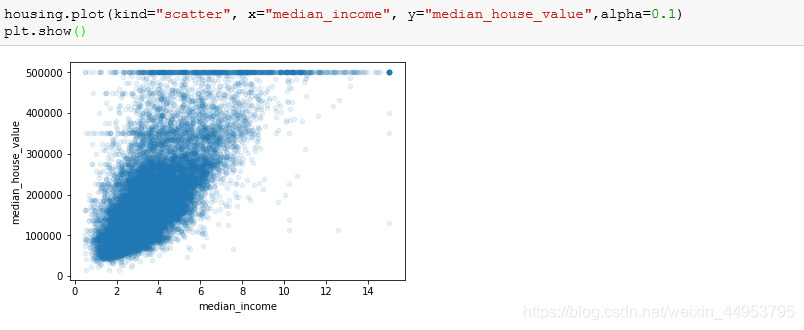
从图中我们可以看出这么几点:1.二者的相关性确实很强,房价随着收入的升高而增加;2.在$50000的地方,有很明显的断层;
除了我们已知的在500000美元处的直线,我们还发现其他位置也存在类似的现象。因此在使用数据时,应该考虑把这些位置的数据去掉。
添加新特征
通过检查scatter matrix和相关系数,我们发现一些属性确实和房价密切相关。我们还可以尝试一些数据组合,看看是否能发现一些新的特征。
我们把rooms per household, bedrooms per room, population per household加入数据特征中,再次查看一下数据的相关矩阵:
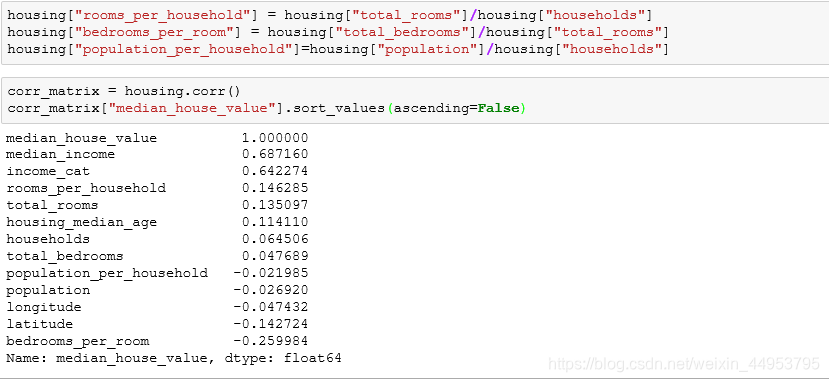
很好,通过观察加入新特征之后的相关性表现,我们发现:
与房间或卧室的总数相比,新的“卧室/房间”属性与房屋中值的相关性更大。显然,卧室/房间比率较低的房子往往更贵。每户家庭的房间数也比一个地区的房间总数更具信息量显然,房子越大,价格就越高。
这篇关于机器学习之加州房价预测(二)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







