本文主要是介绍pandas df.apply 和df.applymap 使用lambda函数加if else语句的差别(注意事项),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
现在有一个Python程序需要对数据表里数据进行处理,把大于0的值转换为1,小于或等于0的值为0。

打算用pandas 的df.apply()方法加lambda函数对整个数据表进行批量转换,但是在使用的时候发现程序报错:
df.apply(lambda x: 1 if x>0 else 0)
错误信息:
ValueError: (‘The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().’, ‘occurred at index A’)
但是直接作用于列又是正常的:
df['A'].apply(lambda x: 0 if x is None else (1 if x>0 else 0))
后来发现是对整个数据表作用时需要改成df.applymap()函数,df.apply()是应用于pd.Series或列或行。
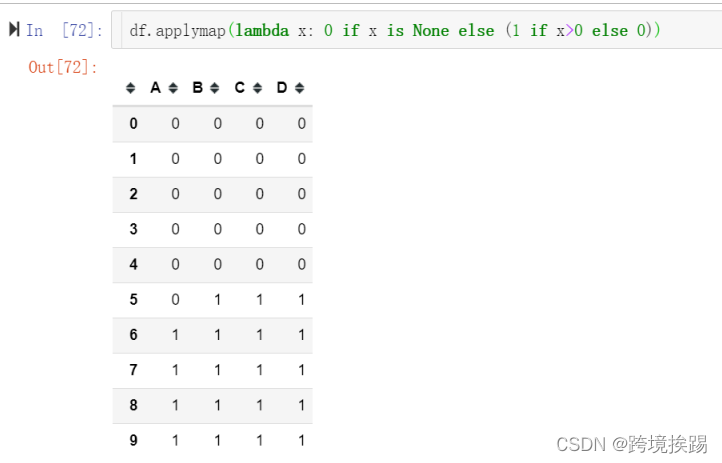
程序改成df.applymap()就可以正常运行了:
df.applymap(lambda x: 1 if x>0 else 0)
程序运行结果:
这篇关于pandas df.apply 和df.applymap 使用lambda函数加if else语句的差别(注意事项)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






