本文主要是介绍Linux服务器登录、环境配置和使用(个人总结版_纯小白版),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、服务器是什么
- 二、服务器如何使用
- 1、安装配套软件
- 2.服务器登陆
- 第一步,新建会话
- 第二步,填IP
- 第三步,填写用户名和密码
- 第四步、连接会话
- 3、服务器操作指令
- 4、环境配置
- (一)安装Anaconda
- Anaconda理解
- 第一步、创建文件夹
- 第二步、下载
- 第三步、Conda常用指令
- 替换镜像源(可选)
- (二)创建环境并配置
- 第一步、创建新环境
- 为什么要创建新环境
- 创建
- 查看已有的环境
- 删除环境
- 激活环境
- 第二步、在新环境中配置pytorch等
- ①概念理解
- ②查看服务器信息
- ③安装GPU版本的pytorch和cunda
- a、CUDA版本的确定
- b、Pytorch版本的确定
- c、确定下载命令
- ④出现的问题及应对方法
- 3、在服务器的某个环境中运行程序
- 总结
前言
提示:这里可以添加本文要记录的大概内容:
学习要用到深度学习,跑代码和数据集的工作量很大,有幸得到实验室分配的服务器使用机会,从一个完全小白的角度总结一下服务器的使用。
提示:以下是本篇文章参考的文献
1、https://blog.csdn.net/zxxxiazai/article/details/102780990
2、https://blog.csdn.net/weixin_45766759/article/details/114677710
一、服务器是什么
就我自己的理解而言,服务器也是一个计算机但配置的功能更为强大,所以它操作系统也有以Linux为内核的系统(最常用:因为维护成本低)和Windows系统等,通常服务器用的都是以Linux为内核的开源系统的Ubuntu(乌邦图)。
二、服务器如何使用
1、安装配套软件
在这直接列出需要用到的一套软件
提示:不止有这些,可以尝试其它的,以下为windows系统可以使用的软件
①Xshell(ge控制服务器,写操作命令)
②Xftp(向服务器传输文件)
以上两个软件的安装:
1、直接百度Xshell,进入官网
2、选择校园/家庭免费专栏
填写邮箱后->勾选两者->查看邮件->点击邮件内的两个链接,分别下载,自定义安装即可,没有需要注意的点
③EasyConnect(挂某个局域网的vpn,比如校园网)
直接在学校官网找到下载的位置,安装好后,使用用户名和密码登陆即可,登陆后自动挂到学校局域网
2.服务器登陆
第一步,新建会话
打开Xshell,点击左上角文件,选择新建
名称自己随意起一个,协议默认SSH,端口号默认22
第二步,填IP
主机处填写服务器IP,这里有两种填写方式
第一种:这个地方直接填写服务器公网IP
第二种:先挂学校VPN,这个地方填写服务器局域网IP
这里要注意你拿到的服务器IP是公网IP和局域网内的IP
如何分辨

其它分辨方法请自行百度
填写完后点击左侧用户身份验证
第三步,填写用户名和密码

这个界面填写拿到的用户名和密码,点击确定即可
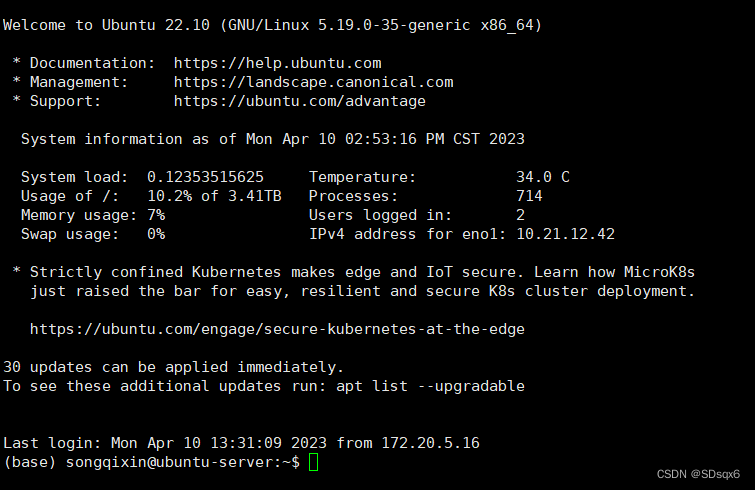
第四步、连接会话
新建完成后,会在会话管理处出现刚才创建的会话
双击该会话之后,会自动连接到服务器,出现以下结果即为成功登陆
3、服务器操作指令
服务器因为不是可视化界面,需要通过指令进行操作比如新建文件、删除文件等,在此列出一些常用的指令
1、文件操作
cd 文件名 #打开文件(cd .. 返回)
ls #列出目前目录文件下所含的子文件
mkdir 文件名 #新建一个文件
rm 文件名 #删除一个文件(rm -rf 子目录下也全部删掉)
2、查看服务器属性操作
nvidia-smi #查看Driver Version:和CUDA Version
nvidia-smi -L #查看服务器显卡型号
4、环境配置
(一)安装Anaconda
Anaconda理解
Anaconda是一个开源的Python发行版本,包含了包括Python、Conda、科学计算库等180多个科学包及其依赖项。因此,安装了Anaconda就不用再单独安装Python。
第一步、创建文件夹
使用的是空服务器,为了后续其他人使用方便,先创建一个home文件夹,在此文件夹下创建单个用户文件夹如user1,在user1下创建workspace文件夹,用以配置环境。
第二步、下载
方式一:
用自己的电脑下载对应版本的安装包(.sh结尾,Linux),一般选最新的即可。
然后打开自己电脑的cmd窗口,用scp命令将安装包拷贝到远程服务器,然后根据提示输入密码即可。
cd ~/文件路径
scp Anaconda3-2019.10-Linux-x86_64.sh username@远程服务器IP:/home/username
方式二:
使用服务器下载安装包并安装
登陆服务器,打开workspace文件,使用**wget**指令直接将anaconda安装包下载到远程服务器:
1.下载安装包
cd /home/username
wget https://repo.anaconda.com/archive/Anaconda3-2023.03-Linux-x86_64.sh
此处,最后为anaconda的版本号,替换即可,推荐使用清华源下载,嘎嘎快
https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-2023.03-Linux-x86_64.sh
2.安装
在当前文件目录中输入:
bash Anaconda3-2023.03-Linux-x86_64.sh
按Enter,继续按加等一会
输入yes接受许可条款

输入yes,自动添加环境变量
3.查看是否安装成功
重新连接服务器,输入指令python,可见python版本为anaconda中的python版本

第三步、Conda常用指令
conda list # 查看这个环境下安装的包和版本
conda install numpy scikit-learn # 安装numpy sklearn包
conda env list # 查看所有的环境
替换镜像源(可选)
为了加快下载速度,通常不从官网下,而从国内的镜像源下载,以清华源为例
添加
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/直接复制到服务器base环境下即可
验证
conda config --set show_channel_urls yes | cat ~/.condarc显示如下结果则证明添加成功

使用
在采用指令下载时,注意去掉后缀,比如-c pytorch
删除
# 删除已添加的源
conda config --remove-key channels
(二)创建环境并配置
第一步、创建新环境
为什么要创建新环境
可以理解为Anaconda为一个大的商场,需要针对不同Projec的要求创建不同的环境来去提供一个个商店(项目)完成具体的任务的平台,Github上的开源项目Readme部分会具体提出项目环境Requirements
示例

创建
conda create -n 环境名称 python=xxx(python版本)
查看已有的环境
conda env list #查看已有的环境
删除环境
conda env remove -n name
激活环境
conda activate 环境名称
此时,进入新环境后,可以进行创建文件夹、安装pytorch等
conda deactivate #返回base环境
第二步、在新环境中配置pytorch等
①概念理解
- Pytorch:一个框架,具有强大的GPU加速的张量计算,包含自动求导系统的深度神经网络,所以在深度学习的时候用PyTorch会比较快。
- CUDA:在进行深度学习的时候,需要用到GPU,CUDA就是一个调用GPU的工具。只有NVidia显卡才能使用CUDA。现有的主流深度学习框架基本都是基于CUDA进行GPU加速的。
- CUDA Toolkit:CUDA运行版本,能够使得使用GPU进行通用计算变得简单和优雅。
- cuDNN:CUDA看作是一个工作台,上面配有很多工具,如锤子、螺丝刀等。cuDNN是基于CUDA的深度学习GPU加速库,有了它才能在GPU上完成深度学习的计算。它就相当于工作的工具,比如它就是个扳手。但是CUDA这个工作台买来的时候,并没有送扳手。想要在CUDA上运行深度神经网络,就要安装cuDNN,就像你想要拧个螺帽就要把扳手买回来。这样才能使GPU进行深度神经网络的工作。
②查看服务器信息
查看服务器CUDA驱动版本
在任一环境的起始界面输入以下命令
nvidia-smi

我的驱动版本是525.89,其能兼容的最高CUDA版本也贴心地写在一旁:12.0
查看服务器型号及其对应的算力
型号查询
nvidia-smi -L #得到服务器型号

我的型号为RTX 3090
算力查询
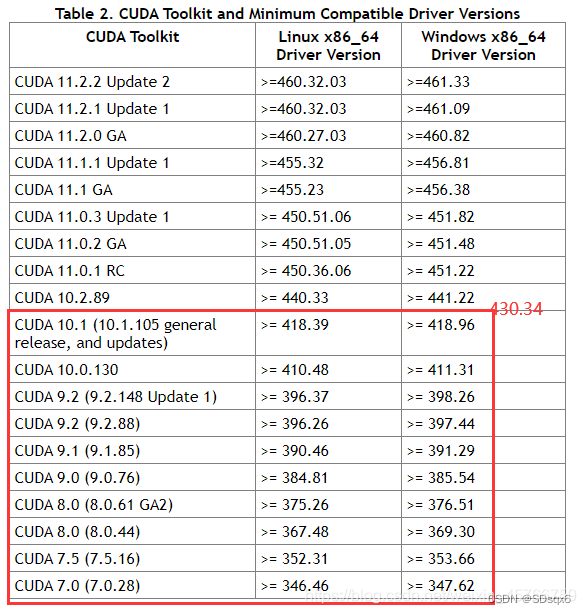
通过如下链接可以查询到NVIDIA显卡对应的算力,如果你的GPU型号不在表中,可能GPU太老,或者算力太低。
https://link.csdn.net/target=https%3A%2F%2Fdeveloper.nvidia.com%2Fcu
da-gpus%23collapseOne
算力对应表
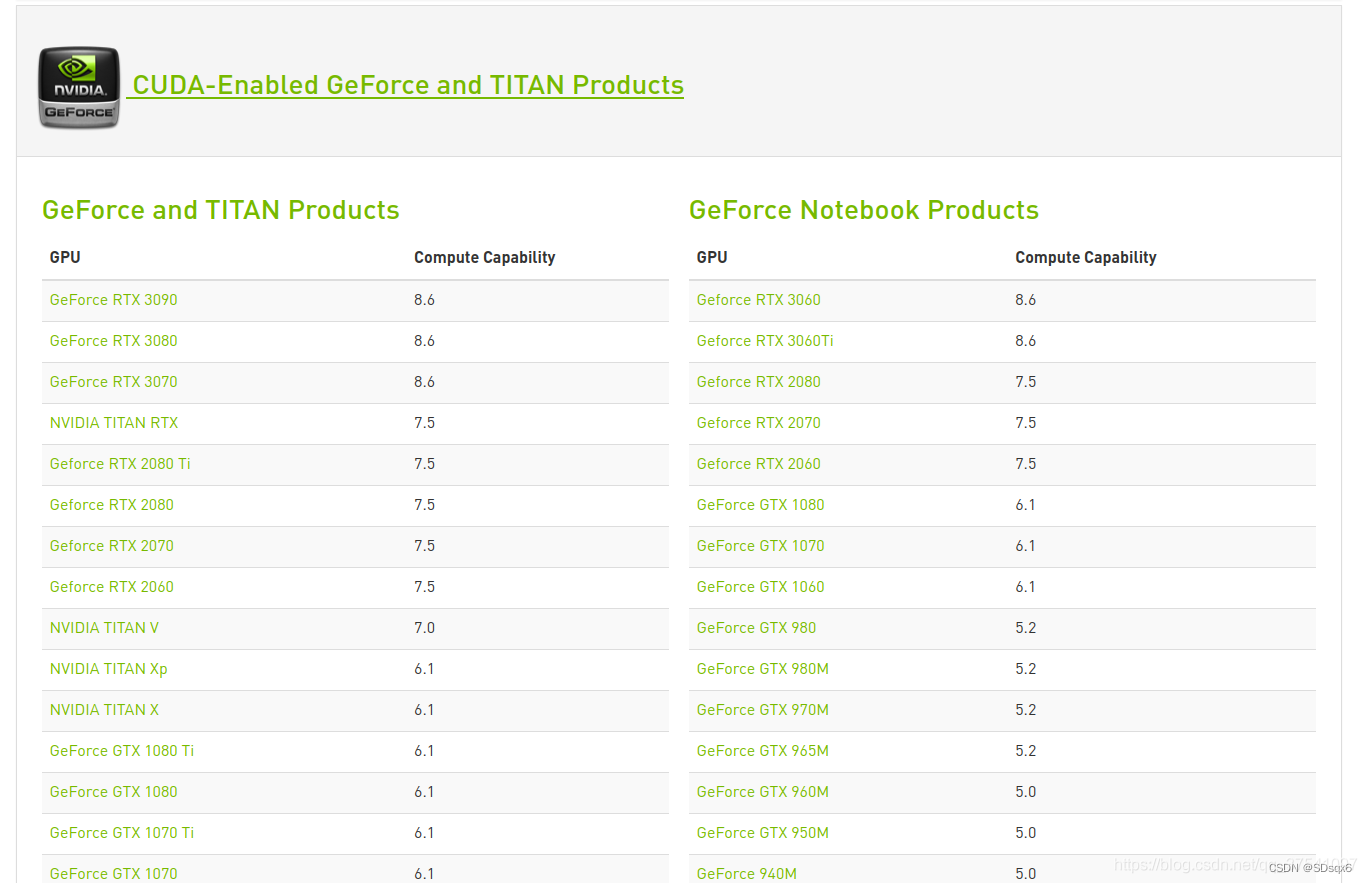
可以看到GTX 3090对应的算力是8.6
3090显卡一般使用CUDA11+,而直接pip安装的pytorch可能是cuda10.2版本的,所以只依靠升级pytorch版本是不行的,还需要安装对应cuda版本的pytorch。
③安装GPU版本的pytorch和cunda
a、CUDA版本的确定
根据GPU驱动版本确定CUDA Toolkit版本,从以下链接可以查看
https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
注意:驱动版本对CUDAToolkit向下兼容的,具体对应关系可以百度一下
此处的CUDA指的就是运行版本CUDA Toolkit
示例
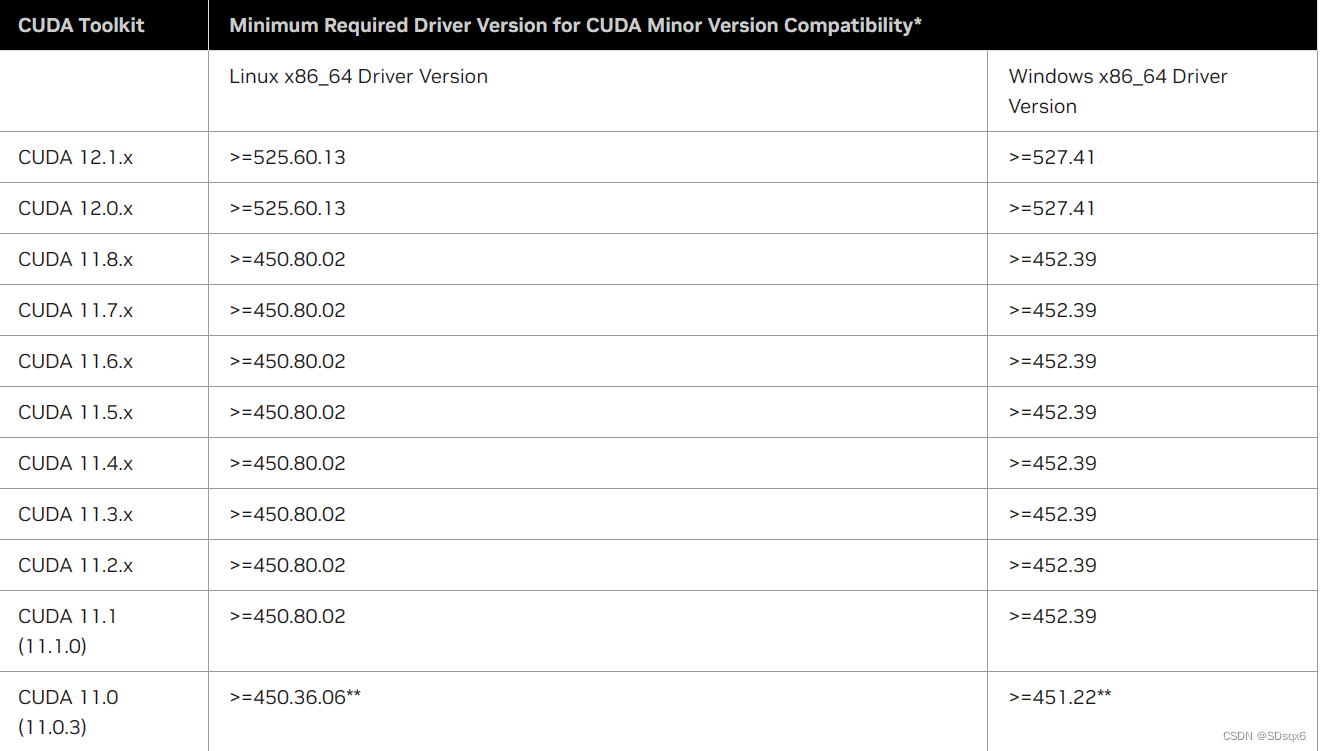
b、Pytorch版本的确定
根据开源项目Requirements确定即可,不同的Pytorch运行的模型准确度会有差异,尽量保持一致。
c、确定下载命令
以pytorch 1.10.0和CUDA 11.3为例
可以打开Pytorch首页,往下滑,看到

通过前五行的组合,最后一行会自动得到安装命令,会同时安装pytorch、torchvision、CudaToolkit
conda
conda install pytorch==1.10.0 torchvision==0.11.0 torchaudio==0.10.0 cudatoolkit=11.3 -c pytorch -c conda-forge
pip
pip3 install torch==1.10.0+cu113 torchvision==0.11.1+cu113 torchaudio==0.10.0+cu113 -f https://download.pytorch.org/whl/cu113/torch_stable.html
通过以上指令会把Pytorch1.10以及需要的CUDA11.3全部安装好(不需要单独安装CUDA)。安装完成后,进入python环境,检查CUDA是否可用,调用torch.cuda.is_available()返回True说明CUDA环境可用。
④出现的问题及应对方法
问题
当使用比较新的显卡(比如NVIDIA GeForce RTX 3090)时,由于显卡的架构比较新,可能旧版本的pytorch库没有支持到。这时候就会出现capability sm_86 is not compatible的问题,同时根据输出可以看到 The current PyTorch install supports CUDA capabilities sm_37 sm_50 sm_60 sm_70 sm_75当前pytorch只能支持上面几种架构。
解决方法
安装高版本的cuda和pytorch,多半是cuda版本较低,使用操作指令直接在workspace文件夹下安装,会自动覆盖之前的版本,不需要提前卸载之前的版本。
3、在服务器的某个环境中运行程序
(一)创建代码文件夹
mkdir Code #在环境下创建存放运行代码的文件夹
(二)使用Xftp传输文件
目录打开至上一步存放代码的文件夹处,将本地.py格式文件传输过来
(三)安装用到的Python—Packages
使用pip install 就可以
(四)运行代码
打开至存放代码的文件夹处
python code名称.py
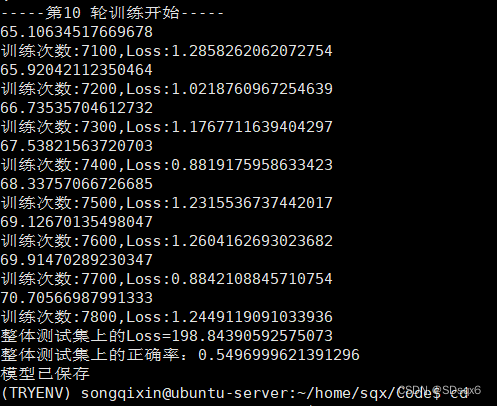
放一下我用服务器GPU训练的结果
总结
以上是我目前使用服务器运行python程序的学习经验,目前仅涉及到了自己python代码的CPU和GPU运行,还没有真正完成深度学习用到的环境配置,以及大体量数据集下载到服务器的部分,争取尽快更新出来。
这篇关于Linux服务器登录、环境配置和使用(个人总结版_纯小白版)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






