本文主要是介绍如何截取pdf文件中的几页,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
首先你得有一个 pdf 阅读器,因为我们常用的是wps这款软件,所以我就用 wps 来演示如何截取 pdf 文件中的几页
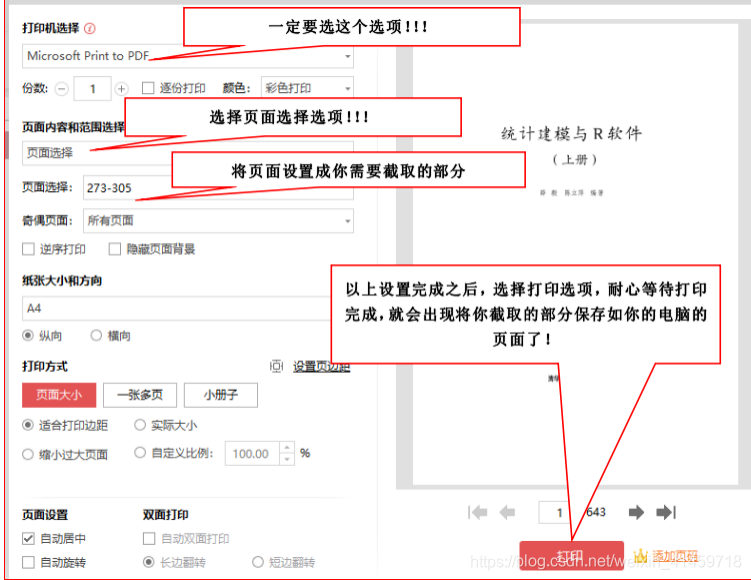
用wps打开你需要截取的pdf文件,然后选择 打印 选项,选择打印选项之后会出现如下界面,按照我图片中所标注的操作就能截取成功
这篇关于如何截取pdf文件中的几页的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!
本文主要是介绍如何截取pdf文件中的几页,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
首先你得有一个 pdf 阅读器,因为我们常用的是wps这款软件,所以我就用 wps 来演示如何截取 pdf 文件中的几页
用wps打开你需要截取的pdf文件,然后选择 打印 选项,选择打印选项之后会出现如下界面,按照我图片中所标注的操作就能截取成功
这篇关于如何截取pdf文件中的几页的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!
http://www.chinasem.cn/article/155816。
23002807@qq.com








