本文主要是介绍[开源项目推荐]privateGPT使用体验和修改,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一.跑通简述
- 二.解读ingest.py
- 1.导入库和读取环境变量
- 2.文档加载
- 3.文档处理(调用文件加载函数和文本分割函数)
- 三.injest.py效果演示
- 1.main函数解读
- 2.测试
- 四.修改代码,使之适配多知识库需求
- 1.修改配置文件:constants.py
- 2.设置.env文件
- 3.知识库选择函数
- 4.修改main函数
- 5.效果演示
一.跑通简述
-
链接如下:https://github.com/imartinez/privateGPT/tree/main
-
一开始是看到了gpt4all这个开源模型(苦于没有算力,据说这个能在低配置电脑上跑,就去看了),然后发现privateGPT这个开源项目,然后试了,果真能跑起来
-
跟着项目中的readme来做即可
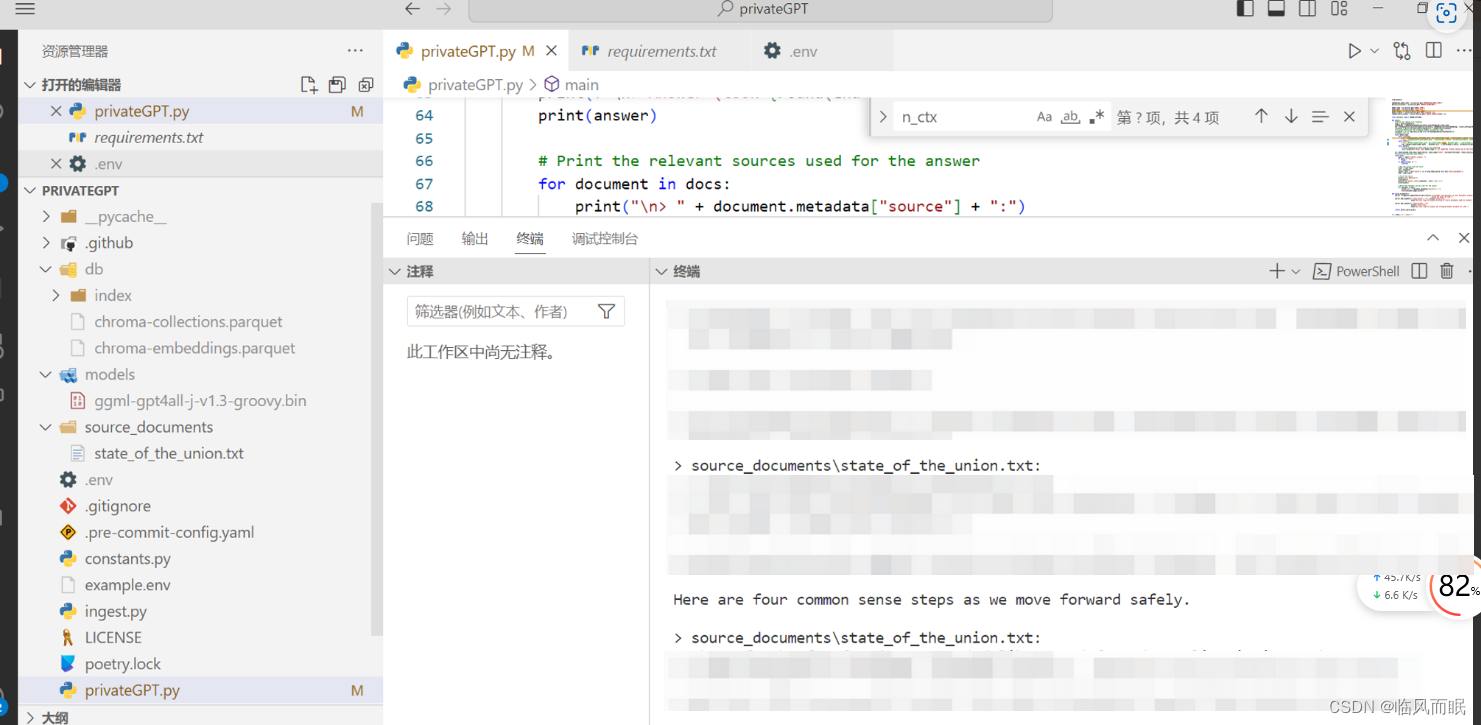
在CLI中输入问题,会显示答案和答案来源 -
其中遇到的一些问题
- 要把gpt4all下载下来,放到models路径下(也可以自己指定,和.env文件里面写的MODEL_PATH一致即可)
- 要把gpt4all下载下来,放到models路径下(也可以自己指定,和.env文件里面写的MODEL_PATH一致即可)
-
在使用ingest.py将本地知识库导入向量数据库的时候
使用了langchain的HuggingFaceEmbeddings,也是可以在.env文件指定embedding模型,如果没有提前预下载好的话,那么会在运行程序的时候自动下载
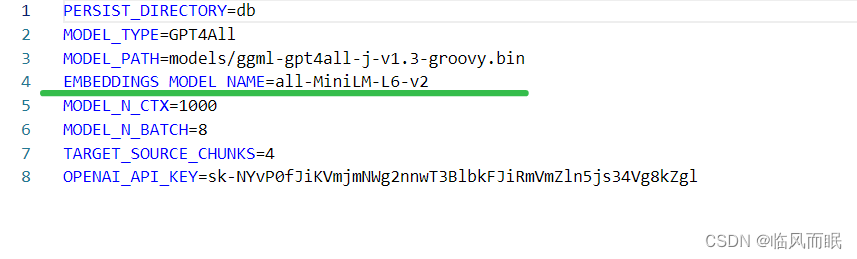
如果遇到和我一样下载失败的情况
可以参考这篇博客,或者使用如下指令
$baseUri = "https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2/resolve/main/"
$outDir = "/data/pretrained_model/all-MiniLM-L6-v2/"
$files = @("pytorch_model.bin", "data_config.json", "config_sentence_transformers.json", "modules.json", "sentence_bert_config.json", "special_tokens_map.json", "tokenizer.json", "tokenizer_config.json", "train_script.py", "vocab.txt")foreach ($file in $files) {$url = $baseUri + $file$outFile = $outDir + $fileInvoke-WebRequest -Uri $url -OutFile $outFileWrite-Host "Downloaded $file"
}
然后就会下载到命令里面指定的路径了
二.解读ingest.py
import os
import glob
from typing import List
from dotenv import load_dotenv
from multiprocessing import Pool
from tqdm import tqdmfrom langchain.document_loaders import (CSVLoader,EverNoteLoader,PyMuPDFLoader,TextLoader,UnstructuredEmailLoader,UnstructuredEPubLoader,UnstructuredHTMLLoader,UnstructuredMarkdownLoader,UnstructuredODTLoader,UnstructuredPowerPointLoader,UnstructuredWordDocumentLoader,
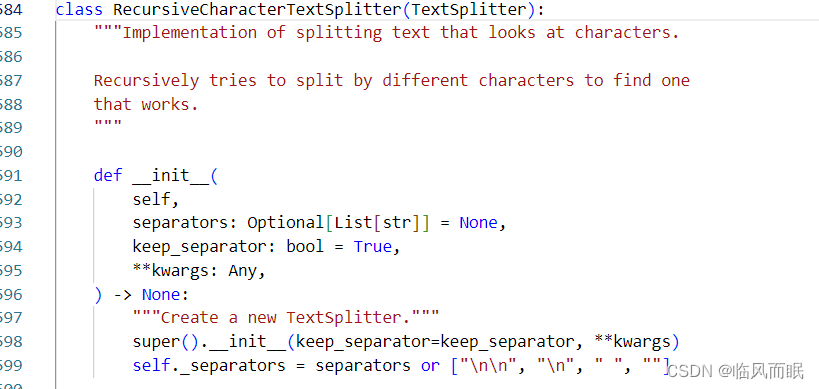
)from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.docstore.document import Document
from constants import CHROMA_SETTINGSload_dotenv()# Load environment variables
persist_directory = os.environ.get('PERSIST_DIRECTORY')
source_directory = os.environ.get('SOURCE_DIRECTORY', 'source_documents')
embeddings_model_name = os.environ.get('EMBEDDINGS_MODEL_NAME')
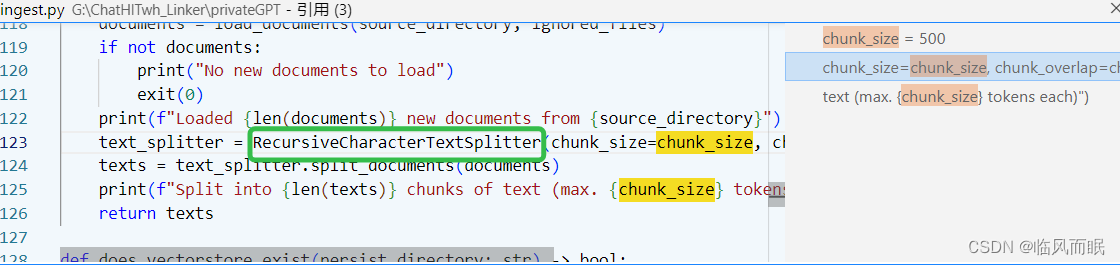
chunk_size = 500
chunk_overlap = 50
-
其中
load_dotenv()挺常用的,用于从.env文件中读取环境变量 -
tqdm用于后面load文件的时候能看到进度条 -
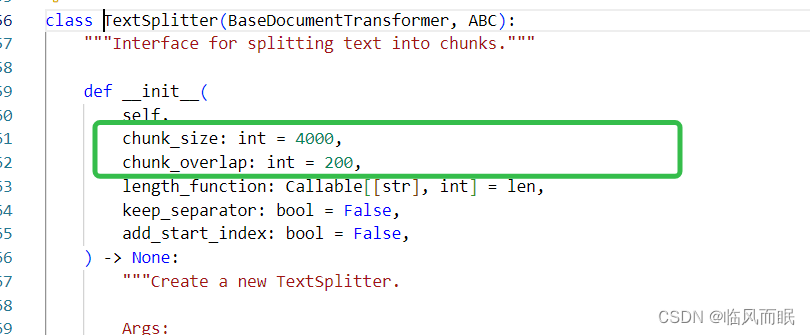
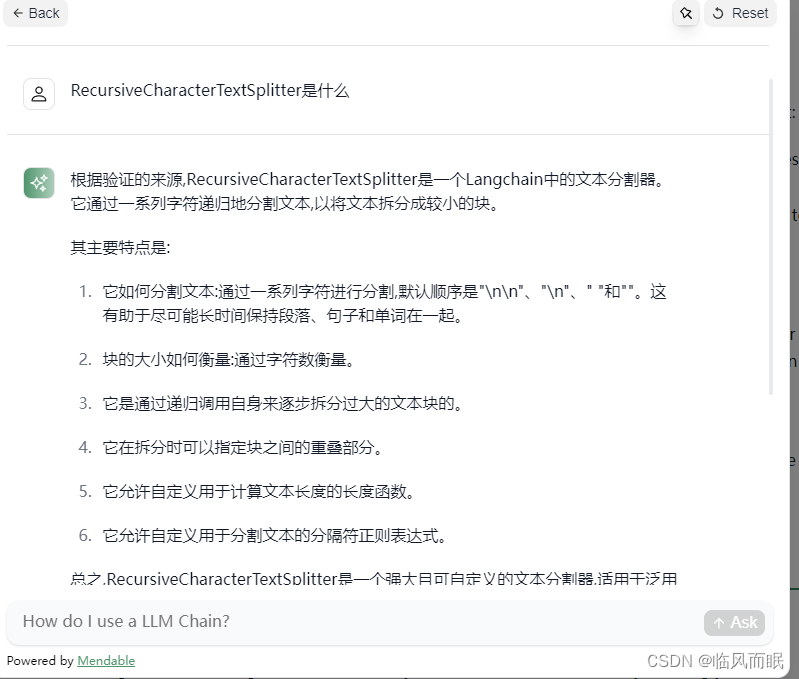
chunk_size和chunk_overlap这有个关于这两个参数的解读博客写的挺好
- chunk_size:这个参数表示文本分割的滑窗长度。它决定了每个分割后的文本块的大小。较大的 chunk_size 值会导致更大的文本块,而较小的值会导致更小的文本块。通常,较大的文本块可以提供更多的上下文信息,但也会增加模型的计算成本和内存需求。
- chunk_overlap:这个参数表示重叠滑窗的长度。它决定了每个分割后的文本块之间的重叠部分。重叠滑窗可以提供文本块之间的上下文关联,使得模型能够更好地理解整个文本。较大的 chunk_overlap 值会导致更多的上下文关联,但也会增加计算成本。
(现在langchain官网支持对文档进行问答了)
-
persist_directory: 从环境中获取持久化目录的路径。 -
source_directory: 从环境中获取源文件目录的路径,如果没有设置则默认为source_documents。
2.文档加载
-
langchain有超级强大且全面的各类文档加载器:https://python.langchain.com/docs/integrations/document_loaders

-
发现一篇很不错的博客:https://blog.csdn.net/weixin_42608414/article/details/131760937
这篇博客也很清楚地介绍了chunk_size和chunk_overlap,这篇博客介绍了使用LangChain框架进行文档加载和切割的方法。还介绍了CharacterTextSplitter和RecursiveCharacterTextSplitter的区别

其中那个MyElmLoader就是继承了Langchain的邮件加载器,改了一些东西 -
单个文档加载函数:
load_single_document-
参数:这个函数接受一个file_path参数,它是要加载文档的文件路径。
-
功能:
- 从文件路径中获取文件扩展名。
- 检查该扩展名是否存在于之前定义的LOADER_MAPPING字典中。
- 如果存在,使用相应的加载器和参数从文件路径加载文档。
- 如果不支持文件扩展名,抛出一个ValueError。
-
返回值:返回一个文档列表
-
-
文档加载函数:
load_documents- 参数:
- source_dir:来源目录的路径,其中包含要加载的所有文档。
- ignored_files:一个默认为空的文件路径列表,指定哪些文件应该被忽略。
- 功能:
- 为所有在LOADER_MAPPING中定义的文件扩展名获取文件路径。
- 使用glob模块的
glob.glob函数,为每个扩展名获取文件路径,并将结果存储在all_files列表中。 - 过滤掉ignored_files中的文件路径,得到filtered_files。
- 使用多进程并行加载每个文件,使用系统的CPU核数作为进程数。为了提高效率,文件是无序加载的。
- 使用
pool.imap_unordered并行地调用load_single_document函数加载每个文件。 - 使用tqdm显示加载进度。
- 将从每个文件加载的所有文档扩展到结果列表中。
- 返回值:这个函数返回所有加载的文档的列表。
- 参数:
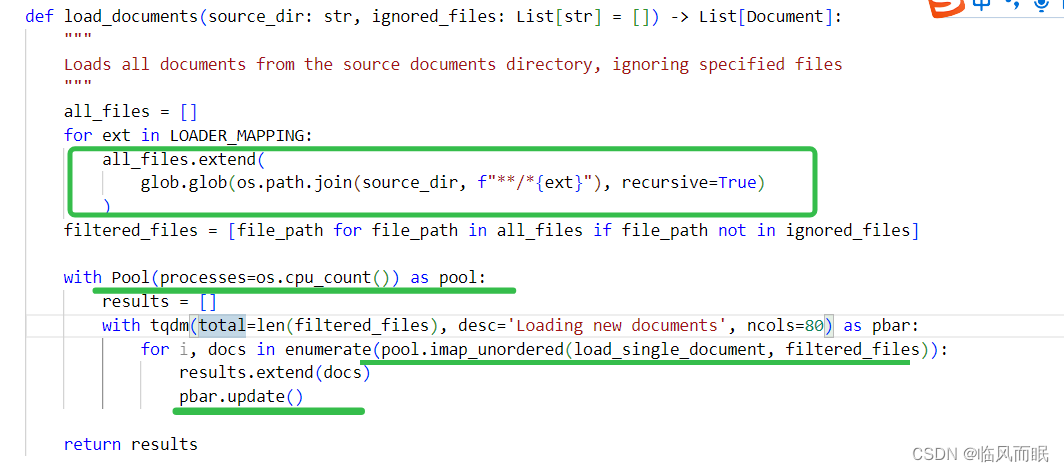
glob.glob用于查找匹配特定模式的文件路径。在这个函数中,我们使用**来匹配任意深度的子目录,*来匹配任意字符,ext 来匹配特定的文件扩展名。os.path.join函数用于将目录路径和文件名组合成完整的文件路径。recursive=True参数用于递归地查找子目录中的文件。最终,glob.glob 返回一个包含所有匹配文件路径的列表。extend是 Python 中的一个列表方法,用于将一个列表中的所有元素添加到另一个列表中。在这个函数中,all_files是一个空列表,glob.glob返回一个包含所有匹配文件路径的列表,extend方法将这个列表中的所有元素添加到all_files列表中。这样,all_files列表就包含了所有匹配文件的路径。Pool是 Python 中的一个类,它提供了一种简单的方式来并行处理大量的任务。它可以创建多个进程来执行函数,并将结果收集到一个列表中。在这个函数中,Pool类用于异步地加载文档,以加快加载速度。processes参数用于指定要创建的进程数,这里使用os.cpu_count()函数来获取系统上的 CPU 数量。imap_unordered方法用于异步地加载每个文档,load_single_document函数被应用于filtered_files列表中的每个文件路径。imap_unordered方法返回一个迭代器,它可以用于获取每个文档的结果。imap_unordered是multiprocessing.Pool类中的一个方法,用于异步地将一个可迭代对象中的元素应用于一个函数。它返回一个迭代器,可以用于获取函数的结果。与imap方法不同,imap_unordered方法不保证返回结果的顺序与输入顺序相同。这个函数中,imap_unordered方法用于异步地加载每个文档,以加快加载速度。load_single_document函数被应用于filtered_files列表中的每个文件路径。imap_unordered方法返回一个迭代器,它可以用于获取每个文档的结果。
3.文档处理(调用文件加载函数和文本分割函数)
process_documents函数加载并处理文档,返回分割后的文本块。而does_vectorstore_exist函数则检查指定的目录中是否存在有效的向量存储。
-
处理文档的函数:
process_documents
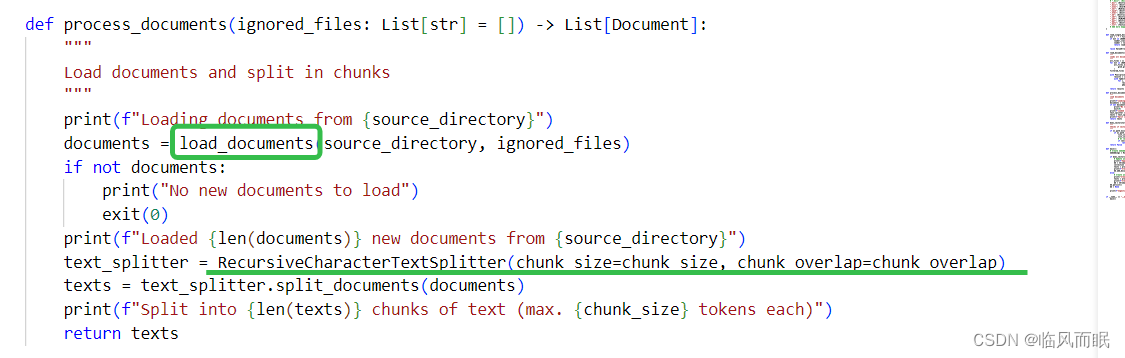
功能:这个函数的主要任务是从指定的
source_directory加载文档,然后将这些文档分割成较小的文本块。-
参数:
ignored_files:默认为空的文件路径列表,这些文件在加载时会被忽略。
-
步骤:
- 输出一个信息,提示从
source_directory开始加载文档。 - 调用
load_documents函数来从source_directory加载文档,并同时考虑需要忽略的文件。 - 如果没有加载到任何新文档,它将输出提示信息并终止程序。
- 输出已加载的新文档的数量。
- 创建一个
RecursiveCharacterTextSplitter对象,该对象负责将文档分割成较小的文本块。这里使用了之前定义的chunk_size和chunk_overlap作为参数。 - 使用
text_splitter的split_documents方法将所有文档分割成文本块。 - 输出文本块的数量以及每个块的最大标记数量。
- 输出一个信息,提示从
-
返回值:函数返回分割后的文本块。
-
-
检查向量存储是否存在的函数:
does_vectorstore_exist
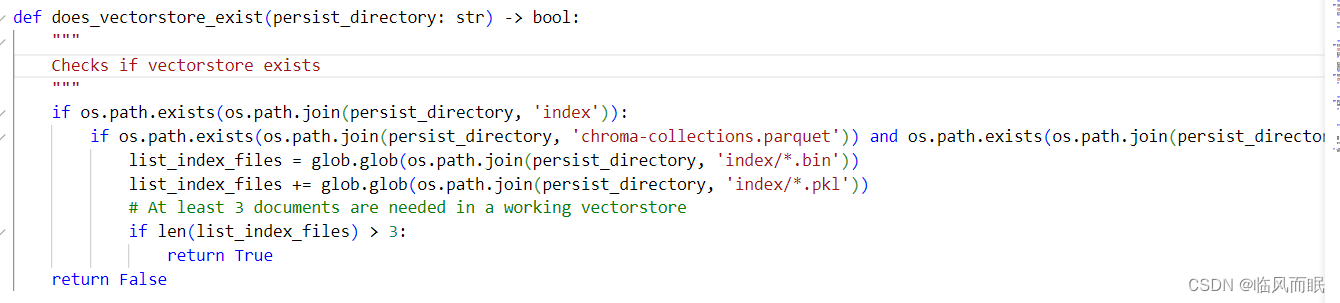
功能:这个函数检查指定目录下是否存在一个有效的向量存储。
-
参数:
persist_directory:一个字符串,表示向量存储可能存在的目录路径。
-
步骤:
- 检查
persist_directory下是否存在名为index的子目录。 - 检查是否存在文件
chroma-collections.parquet和chroma-embeddings.parquet。 - 获取
index目录下所有的.bin和.pkl文件。 - 如果这些文件的数量超过3个,那么假定该向量存储是有效的。
- 检查
-
返回值:如果向量存储存在并且被认为是有效的,则返回
True。否则,返回False。
三.injest.py效果演示
1.main函数解读
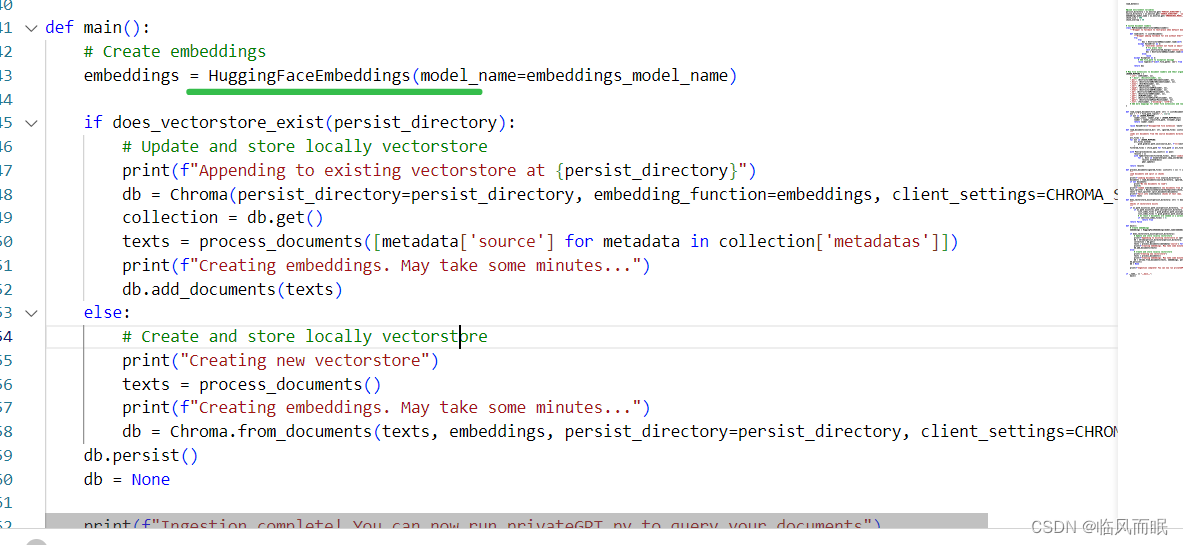
def main():# Create embeddings# 创建嵌入embeddings = HuggingFaceEmbeddings(model_name=embeddings_model_name)# 如果vectorstore存在if does_vectorstore_exist(persist_directory):# Update and store locally vectorstoreprint(f"Appending to existing vectorstore at {persist_directory}")db = Chroma(persist_directory=persist_directory, embedding_function=embeddings, client_settings=CHROMA_SETTINGS)collection = db.get() # get是获取vectorstoretexts = process_documents([metadata['source'] for metadata in collection['metadatas']])print(f"Creating embeddings. May take some minutes...")db.add_documents(texts)else:# 创建并存储本地vectorstoreprint("Creating new vectorstore")texts = process_documents()print(f"Creating embeddings. May take some minutes...")db = Chroma.from_documents(texts, embeddings, persist_directory=persist_directory, client_settings=CHROMA_SETTINGS)db.persist()db = Noneprint(f"Ingestion complete! You can now query your documents")
-
创建嵌入:
使用HuggingFaceEmbeddings类创建一个嵌入对象,其中的模型名称由embeddings_model_name提供。 -
检查向量存储是否存在:
使用does_vectorstore_exist函数检查在persist_directory中是否已存在向量存储。-
如果向量存储存在:输出信息,表示将文档添加到现有的向量存储。
-
创建一个
Chroma对象,用于处理向量存储,这需要向量存储的路径、嵌入函数以及客户端设置。
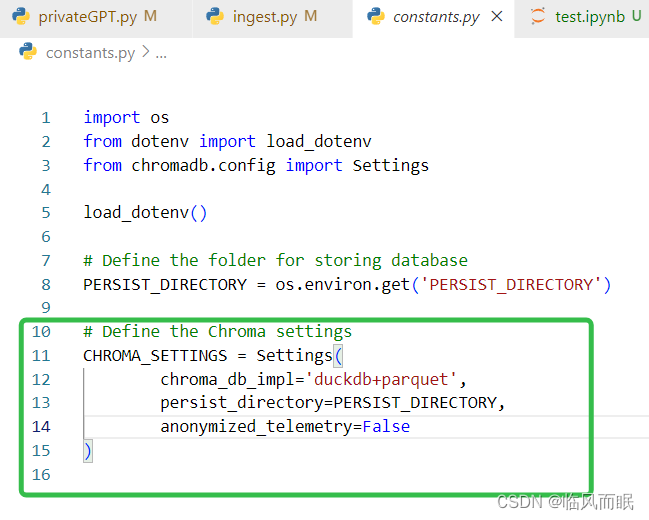
其中的chroma的配置写在constants.py里面
-
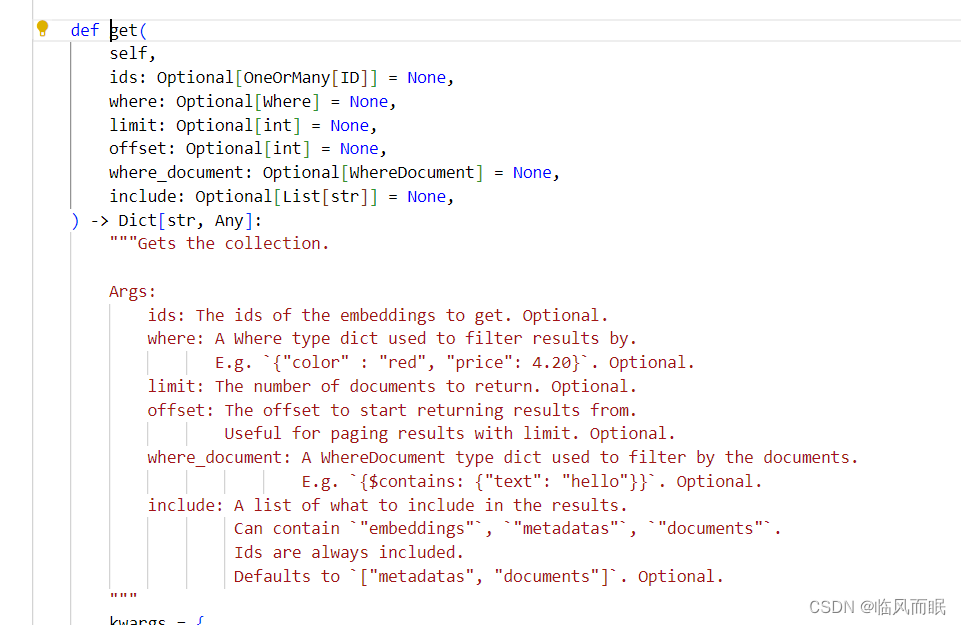
获取向量存储中的当前文档集合。
调用process_documents函数处理那些之前尚未被加入到向量存储中的新文档。
输出信息,告知用户正在创建嵌入,这可能需要一些时间。
使用db.add_documents将处理后的文本块添加到向量存储。
-
-
如果向量存储不存在:
- 输出信息,表示正在创建新的向量存储。
调用process_documents函数处理所有的文档。 - 输出信息,告知用户正在创建嵌入。
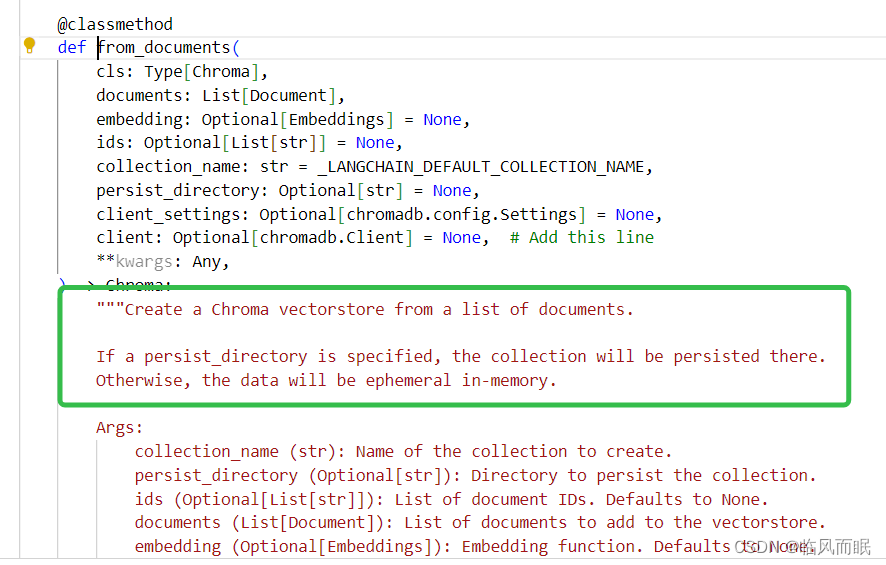
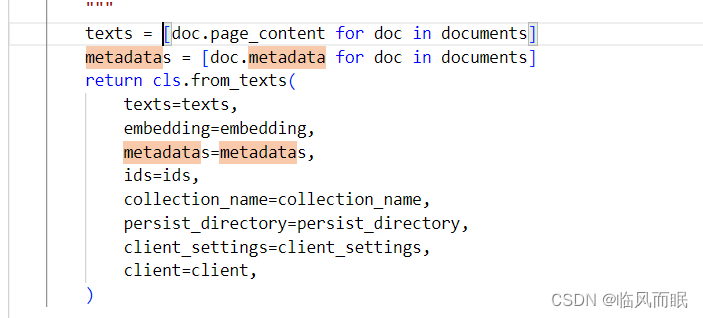
使用Chroma.from_documents从处理后的文本块创建新的向量存储。
- 输出信息,表示正在创建新的向量存储。
-
-
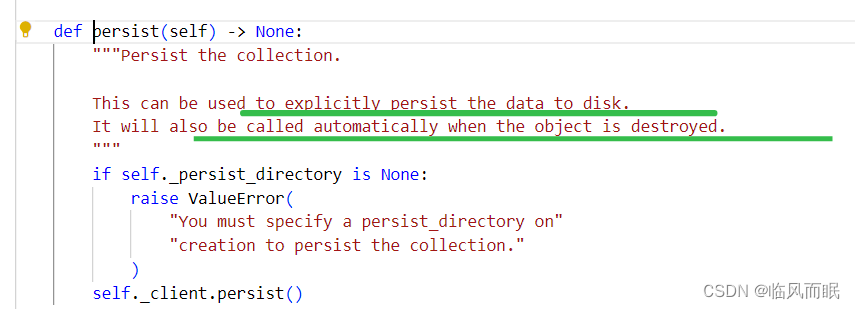
持久化向量存储:
调用db.persist方法将向量存储的更改保存到磁盘。
2.测试

四.修改代码,使之适配多知识库需求
目标是可以设置不同的知识库
- 比如:我的本地知识库集合是一个大文件夹source,里面有小文件a,b,c分别存着不同类型的本地知识文件,然后我想运行ingest.py的时候,选择不同的路径,然后处理对应的本地知识文件,存到对应的VectorStore_of_source里面,里面分别对应a,b,c的向量数据库
1.修改配置文件:constants.py
首先,我们需要一个constants.py文件来存储基本的配置设置。
import os
from dotenv import load_dotenv
from chromadb.config import Settingsload_dotenv()# 分别对应我上面说的VectorStore_of_source和source
BASE_VECTORSTORE_DIRECTORY = os.environ.get('VECTORSTORE_BASE')
BASE_SOURCE_DIRECTORY = os.environ.get('SOURCE_BASE')# 分别对应我刚刚说的两个路径下的a,b,c
PERSIST_SUBDIRECTORIES = os.environ.get('PERSIST_DIRECTORIES').split(',')
SOURCE_SUBDIRECTORIES = os.environ.get('SOURCE_DIRECTORIES').split(',')# 路径合并
PERSIST_DIRECTORIES = [os.path.join(BASE_VECTORSTORE_DIRECTORY, sub_dir) for sub_dir in PERSIST_SUBDIRECTORIES]
SOURCE_DIRECTORIES = [os.path.join(BASE_SOURCE_DIRECTORY, sub_dir) for sub_dir in SOURCE_SUBDIRECTORIES]# 每个路径都有自己的Chroma设置
CHROMA_SETTINGS_LIST = [Settings(chroma_db_impl='duckdb+parquet',persist_directory=dir_path,anonymized_telemetry=False)for dir_path in PERSIST_DIRECTORIES
]2.设置.env文件
创建一个名为.env的文件,并定义以下变量:
还是对应我刚刚说的那几个,知识源的Base(大目录),具体的小目录a,b,c(SOURCE_DIRECTORIES)
向量数据库的Base和下面的a,b,c(PERSIST_DIRECTORIES)

3.知识库选择函数
首先,我们创建一个函数来供用户选择知识库:python
def choose_directory():directories = ["a", "b", "c", "d"]print("Choose a persist directory:")for idx, d in enumerate(directories, 1):print(f"{idx}. {d}")choice = int(input("Enter the number: ")) - 1chosen_directory = directories[choice]persist_directory = os.path.join(PERSIST_DIRECTORY_BASE, chosen_directory)source_directory = os.path.join('source_base_directory', chosen_directory) # Replace 'source_base_directory' with your actual pathreturn persist_directory, source_directory, CHROMA_SETTINGS
可以调用上面的choose_directory函数来获取chosen_persist_directory和chosen_source_directory。这些值随后在main函数中使用。
4.修改main函数
现在,可以在main函数中调用choose_directory来选择存储和源目录,并基于选择的目录对文档进行处理。
def main():chosen_persist_directory, chosen_source_directory, chosen_chroma_settings = choose_directory()
然后把原先的该替换的都用chosen后的变量替换掉
def main():chosen_persist_directory, chosen_source_directory, chosen_chroma_settings = choose_directory()# Create embeddingsembeddings = HuggingFaceEmbeddings(model_name=embeddings_model_name)if does_vectorstore_exist(chosen_persist_directory):# Update and store locally vectorstoreprint(f"Appending to existing vectorstore at {chosen_persist_directory}")db = Chroma(persist_directory=chosen_persist_directory, embedding_function=embeddings, client_settings=chosen_chroma_settings)collection = db.get()texts = process_documents(chosen_source_directory, [metadata['source'] for metadata in collection['metadatas']])print(f"Creating embeddings. May take some minutes...")db.add_documents(texts)else:# Create and store locally vectorstoreprint("Creating new vectorstore")texts = process_documents(chosen_source_directory)print(f"Creating embeddings. May take some minutes...")db = Chroma.from_documents(texts, embeddings, persist_directory=chosen_persist_directory, client_settings=chosen_chroma_settings)db.persist()db = Noneprint(f"Ingestion complete!")
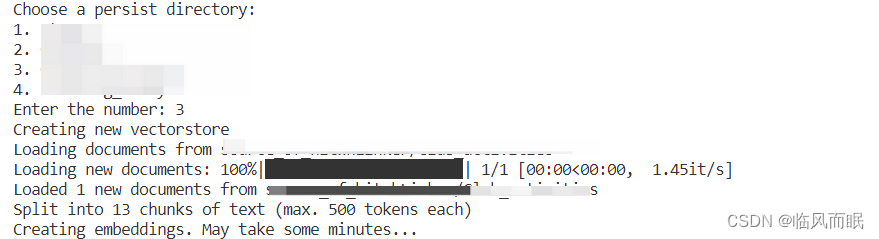
5.效果演示
这篇关于[开源项目推荐]privateGPT使用体验和修改的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






