本文主要是介绍[Linux]:环境变量与进程地址空间,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
✨✨ 欢迎大家来到贝蒂大讲堂✨✨
🎈🎈养成好习惯,先赞后看哦~🎈🎈
所属专栏:Linux学习
贝蒂的主页:Betty’s blog

1. 环境变量
1.1 概念
**环境变量(environment variables)**一般是指在操作系统中用来指定操作系统运行环境的一些参数,具有全局属性,可以被子继承继承下去。
如:我们在编写C/C++代码的时,在链接的时候,我们并不知道所链接的动态静态库在哪里,但是照样可以链接成功,生成可执行程序,原因就是有相关环境变量帮助编译器进行查找。
1.2 查看环境变量
我们可以通过指令echo $NAME //NAME为待查看的环境变量名称,以下是常见的环境变量
| 环境变量名称 | 表示内容 |
|---|---|
| PATH | 命令的搜索路径 |
| HOME | 用户的主工作目录 |
| SHELL | 当前Shell |
| HOSTNAME | 主机名 |
| TERM | 终端类型 |
| HISTSIZE | 记录历史命令的条数 |
| SSH_TTY | 当前终端文件 |
| USER | 当前用户 |
| 邮箱 | |
| PWD | 当前所处路径 |
| LANG | 编码格式 |
| LOGNAME | 登录用户名 |
比如我们查看环境变量PATH:

那这一连串的地址究竟是指什么呢?在回答这个问题之前,我们首先要思考为什么输入指令时,直接输入指令名称即可如ls,而执行我们自己的可执行程序必须在前面加./表示当前路径呢?如./a.out。
其实答案很简单,系统能够通过指令名称找到其对应的位置,但是我们自己的可执行程序却不可以,必须指明在当前路径下。
现在我们就知道环境变量PATH中的地址具体代表什么了,代表的就是默认查找的路径。

如果我们想让我们的可执行程序也像系统指令一样使用,一种方法就是:将可执行程序拷贝到环境变量PATH的某一路径下。还要一种方法就是:将可执行程序所在的目录导入到环境变量PATH当中。


1.3 相关指令
- 指令
env:显示所有的环境变量。

- 指令
<font style="color:rgb(77, 77, 77);">export</font>:设置一个新的环境变量。

- 指令
set:显示本地定义的shell变量和环境变量。
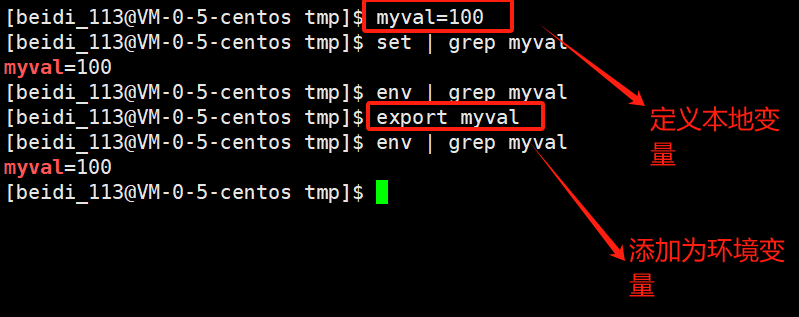
- 指令
unset:取消本地变量与环境变量。
1.4 环境变量的组织方式
每个程序都会有一张环境变量表,环境变量表是一个字符指针数组,每个指针指向一个以\0结尾的环境字符串,最后一个字符指针为空。

2. main函数的三个参数
main函数其实是有参数的,但是我们一般并不是经常使用。以下是main函数的原型:
int main(int argc,char* argv[],char* env[])
- argc:代表命令行有效参数的个数。
- argv : 指向命令行参数。
- env: 指向环境变量。
首先我们通过下面代码来观察一下前两个参数的效果:
#include<stdio.h> int main(int argc,char* argv[])
{ for(int i = 0;i<argc;i++) { printf("argv[%d]->%s\n",i,argv[i]); } return 0;
}

一共有三个有效参数,第一个有效参数为./a.out,第二个有效参数为-a,第三个参数为-b。这三个有效参数都被argv这个指针数组所指向,并且argv最后一个参数指向NULL。
同样我们通过以下代码来探究一下第三个参数:
#include <stdio.h>
int main(int argc, char *argv[], char *env[])
{int i = 0;for(i=0; env[i]; i++){ printf("[%d]->%s\n",i,env[i]);}return 0;
}

运行程序将显示所有的环境变量。
并且我们还可以通过第三方变量envison获取环境变量:
#include <stdio.h>
int main(int argc, char* argv[])
{extern char **environ;//先声明外部变量int i = 0;for(i = 0; environ[i]; i++){printf("%s\n", environ[i]);}return 0;
}
并且我们最后还有介绍一个接口getenv,它能根据名称获取对应的环境变量
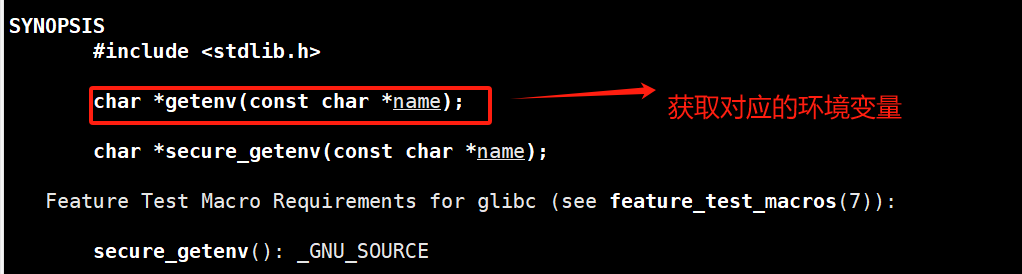
#include <stdio.h>
#include<stdlib.h>
int main(int argc, char *argv[], char *env[])
{printf("%s\n",getenv("PATH"));//获取对应的环境变量return 0;
}

3. 程序地址空间
相信大家对这幅图并不陌生了,这是我们的常说的内存布局分布图:
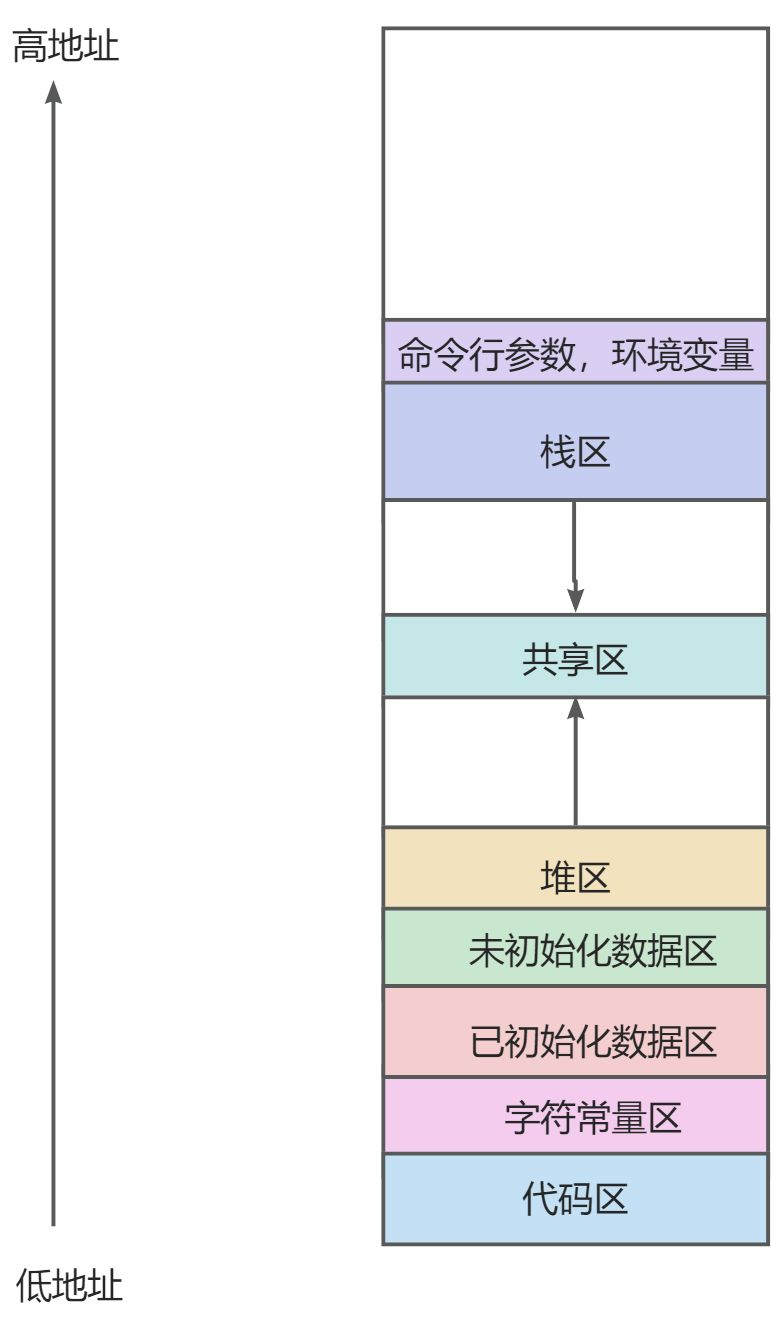
其中堆栈相对而生,栈向下生长(在栈上的变量先定义的地址更大),堆向上生长(在堆上的变量先定义的地址更小)。
我们可以通过以下代码来验证:
#include<stdio.h>
#include<stdlib.h>
int g_unval;
int g_val = 100;
int main(int argc,char* argv[],char* env[])
{const char* str = "hello world";printf("code addr:%p\n",main);//main函数就在代码区printf("string rdonly addr:%p\n",str);//字符常量区printf("init addr:%p\n",&g_val);//已初始化全局数据区printf("uninit addr:%p\n",&g_unval);//未初始化全局数据//堆区char* heap1 = (char*)malloc(10);char* heap2 = (char*)malloc(10); char* heap3 = (char*)malloc(10); char* heap4 = (char*)malloc(10); printf("heap1 addr:%p\n",heap1); printf("heap2 addr:%p\n",heap2); printf("heap3 addr:%p\n",heap3); printf("heap4 addr:%p\n",heap4); //栈区int a = 10; int b = 20; printf("stack addr:%p\n",&a); printf("stack addr:%p\n",&b); //命令行参数int i = 0;for( i = 0; argv[i]; i++) { printf("argv[%d]:%p\n", i, argv[i]); }//环境变量for(i = 0; env[i]; i++){printf("env[%d]:%p\n", i, env[i]);}return 0;
}

最后让我们再来看看这一段代码:
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
int g_val=100;
int main()
{pid_t id=fork();//创建子进程if(id==0){//childg_val=200;printf("child PID:%d,PPID:%d,g_val:%d,&g_val:%p\n",getpid(),getppid(),g_val,&g_val);}else if(id>0){//fatherprintf("father PID:%d,PPID:%d,g_val:%d,&g_val:%p\n",getpid(),getppid(),g_val,&g_val);}else{// fork error}return 0;
}

我们惊讶地发现,当数据发生修改的时,在父子进程当中的同一个变量,地址是相同的,但是值却是不同的,这明显不符合我们的认知,因为同一个地址的值怎么可能不同呢。
前面我们学习进度时已经知道,当fork创建子进程时,父子默认情况共享数据。然而修改数据时,为了维护进程独立性,会发生写时拷贝,所以父子进程的值不同,但是地址为什么会不变呢?
如果我们是在同一个物理地址处获取的值,那必定值是相同的,而现在在同一个地址处获取到的值却不同,这只能证明我们打印出的地址并不是物理地址。
实际上,我们在语言层面上打印出来的地址都不是物理地址,而是一种虚拟地址。物理地址用户一概是看不到的,是由操作系统统一进行管理的,所以即使父子进程打印的地址相同,但是物理地址可能是不同的,这也就解释了为什么地址相同,而值却不同的问题。
4. 进程地址空间
我们之前将那张布局图称为程序地址空间实际上是不准确的,那张布局图实际上应该叫做进程地址空间,进程地址空间本质是内存中的一种内核数据结构,在Linux当中进程地址空间具体由结构体mm_struct实现,其一般包含以下这些信息:
struct mm_struct
{//代码区unsigned int code_start; unsigned int code_end; //已初始化全局数据区unsigned int init_data_start;unsigned int init_data_end;//未初始化全局数据区unsigned int uninit_data_start;unsigned int uninit_data_end;//....栈区unsigned int stack_start;unsigned int stack_end;
};
在结构体mm_struct当中,每一个的区域都代表一个虚拟地址,这些虚拟地址通过页表映射与物理内存建立联系。由于虚拟地址大小一般为4G,是由0x00000000到0xffffffff线性增长的,所以虚拟地址又叫做线性地址。
每个进程被创建时,其对应的进程控制块task_struct和进程地址空间mm_struct也随之被创建。而操作系统就可以通过进程的task_struct找到对应的mm_struct(因为task_struct有一个结构体指针指向的是mm_struct)。

然后我们就可以更加深入解释上面地址相同,值却不同的现象:首先父进程有自己的task_struct和mm_struct,该父进程创建的子进程也会有属于其自己的task_struct和mm_struct,父子进程的进程地址空间当中的各个虚拟地址分别通过页表映射到对应的物理内存,如下图:

此时若是子进程要将g_val改为200,此时为了维护进程的独立性,不影响父进程的数据,子进程就会发生写实拷贝。

- 问题一:为什么数据要进行写时拷贝?
进程间具有独立性。多进程运行,需要独享各种资源,运行期间互不干扰,不能让子进程的修改影响到父进程。
- 问题二:为什么不在创建子进程的时候就进行数据的拷贝?
子进程不一定会使用父进程的所有数据,并且在子进程不对数据进行写入的情况下,没有必要对数据进行拷贝,我们应该按需分配,在需要修改数据的时候再分配(延时分配),提高空间利用率。
- 问题三:代码会不会进行写时拷贝?
绝大数情况下是不会的,但这并不代表代码不能进行写时拷贝,例如在进行进程替换的时候,则需要进行代码的写时拷贝。
- 问题四:为什么要有进程地址空间?
- 通过添加一层软件层,实现对进程操作内存的风险管理(权限管理),本质是保护物理内存中各个进程的数据安全。
- 将内存申请和使用在时间上解耦,利用虚拟地址空间屏蔽底层申请内存过程,实现进程读写内存操作与操作系统内存管理在软件层面分离。
- 例如在堆上申请空间可能暂不全部使用甚至不用,从操作系统角度可在实际使用时再开辟空间建立映射关系,即基于缺页中断进行物理内存申请。
- 若物理内存已满而仍需申请,操作系统可执行内存管理算法,将某些进程闲置空间置换到磁盘,使进程仍能申请到内存,且用户在应用层无感知。
- 站在
CPU和应用层角度,进程统一使用4GB空间且各空间区域相对位置较确定。有了虚拟地址空间,CPU能以统一视角看待物理内存,不同进程通过各自页表映射到不同物理内存,同时程序代码和数据可加载到内存任意位置,大大减少内存管理负担。
这篇关于[Linux]:环境变量与进程地址空间的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







