本文主要是介绍Labelhot和OneHot的使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
对于一些特征工程方面,有时会用到LabelEncoder和OneHotEncoder。
比如kaggle中对于性别,sex,一般的属性值是male和female。两个值。那么不靠谱的方法直接用0表示male,用1表示female 了。上面说了这是不靠谱的。
所以要用one-hot编码。
首先我们需要用LabelEncoder把sex这个属性列里面的离散属性用数字来表示,就是上面的过程,把male,female这种不同的字符的属性值,用数字表示。
以titanic 里面的train数据集为例.

Step1和step2解决的就是先fit所有样本的Sex属性值,就知道有多少个不同的属性值,有male和female,就用0和1表示,假如有3个不同的值,就用0,1,2表示。step2中transform操作就是转为数字表示形式。
但是转换成这样还不行,上面说过了,这样直接用数字表示的话,是不合理的,至于为什么不合理,待会引入scikit learn 中的原文。所以再把这些数字转化为one-hot编码形式。
这里就用OneHotEncoder

两行代码就把数值型表示转为了one-hot编码形式。
下面引入scikit learn中的OneHotEncoder的介绍。
http://scikit-learn.org/stable/modules/preprocessing.html#preprocessing
具体内容看上面链接,下面转载这个博客对一些文字的翻译
http://blog.csdn.net/google19890102/article/details/44039761
一、One-Hot Encoding
One-Hot 编码,又称为一位有效编码,主要是采用 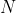 位状态寄存器来对 个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。
位状态寄存器来对 个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。
有如下三个特征属性:
二、One-Hot Encoding的处理方法
三、实际的Python代码
在实际的机器学习的应用任务中,特征有时候并不总是连续值,有可能是一些分类值,如性别可分为“ male ”和“ female ”。在机器学习任务中,对于这样的特征,通常我们需要对其进行特征数字化,如下面的例子:
- 性别:["male","female"]
- 地区:["Europe","US","Asia"]
- 浏览器:["Firefox","Chrome","Safari","Internet Explorer"]
对于某一个样本,如[" male "," US "," Internet Explorer "],我们需要将这个分类值的特征数字化,最直接的方法,我们可以采用序列化的方式:[0,1,3]。但是这样的特征处理并不能直接放入机器学习算法中。
对于上述的问题,性别的属性是二维的,同理,地区是三维的,浏览器则是思维的,这样,我们可以采用One-Hot编码的方式对上述的样本“ [" male "," US "," Internet Explorer "] ”编码,“ male ”则对应着[1,0],同理“ US ”对应着[0,1,0],“ Internet Explorer ”对应着[0,0,0,1]。则完整的特征数字化的结果为:[1,0,0,1,0,0,0,0,1]。这样导致的一个结果就是数据会变得非常的稀疏。
然后我主要介绍一下源文档的代码,
import numpy as np from sklearn.preprocessing
import OneHotEncoder
enc = OneHotEncoder()
enc.fit( [[0, 0, 3], [1, 1, 0], [0, 2, 1],[1, 0, 2]] )
print "enc.n_values_ is:" ,enc.n_values_
print "enc.feature_indices_ is:" ,enc.feature_indices_
print enc.transform( [[0, 1, 1]] ).toarray()
enc.n_values_ is: [ 2 3 4 ]
enc.feature_indices_ is: [ 0 2 5 9 ]
[[ 1. 0. 0. 1. 0. 0. 1. 0. 0.]]
这个代码很容易理解,简单解释一下没我一开始也没整明白。
首先由四个样本数据 [0, 0, 3], [1, 1, 0], [0, 2, 1],[1, 0, 2],共有三个属性特征,也就是三列。比如第一列,有0,1两个属性值,第二列有0,1,2三个值.....
那么 enc.n_values_就是每个属性列不同属性值的个数,所以分别是2,3,4
再看 enc.feature_indices_是对 enc.n_values_的一个累加。
再看 [0, 1, 1]这个样本是如何转换为基于上面四个数据下的one-hot编码的。
第一列:0->10
第二列:1->010
第三列:1->0100
简单解释一下,在第三列有,0,1,2,3四个值,分别对应1000,0100,0010,0001.
这篇关于Labelhot和OneHot的使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





