本文主要是介绍AFM,NFM,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
推荐系统中使用ctr排序的f(x)的设计-dnn篇之AFM模型

图中的前三部分:sparse iput,embedding layer,pair-wise interaction layer,都和FM是一样的。而后面的两部分,则是AFM的创新所在。从比较宏观的角度理解,AFM就是通过一个attention net生成一个关于特征交叉项的权重,然后将FM原来的二次项直接累加,变成加权累加。
从宏观来看,AFM只是在FM的基础上添加了attention的机制,但是实际上,由于最后的加权累加,二次项并没有进行更深的网络去学习非线性交叉特征,所以它的上限和FFM很接近,没有完全发挥出dnn的优势。
推荐系统中使用ctr排序的f(x)的设计-dnn篇之NFM模型



Bi是Bi-linear的缩写,这一层其实是一个pooling层操作,它把很多个向量转换成一个向量,形式化如下:
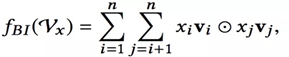
fbi的输入是整个的嵌入向量,xi ,xj是特征取值,vi, vj是特征对应的嵌入向量。中间的操作表示对应位置相乘。所以原始的嵌入向量任意两个都进行组合,对应位置相乘结果得到一个新向量;然后把这些新向量相加,就得到了Bi-Interaction的输出。这个输出只有一个向量。

这篇关于AFM,NFM的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




