本文主要是介绍Mysql8.0安装以及递归表达式使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
mysql安装
以centos7为例安装!
安装wget
yum install wget -y给CentOS添加rpm源,并且选择较新的源
官网地址
wget dev.mysql.com/get/mysql84-community-release-el7-1.noarch.rpm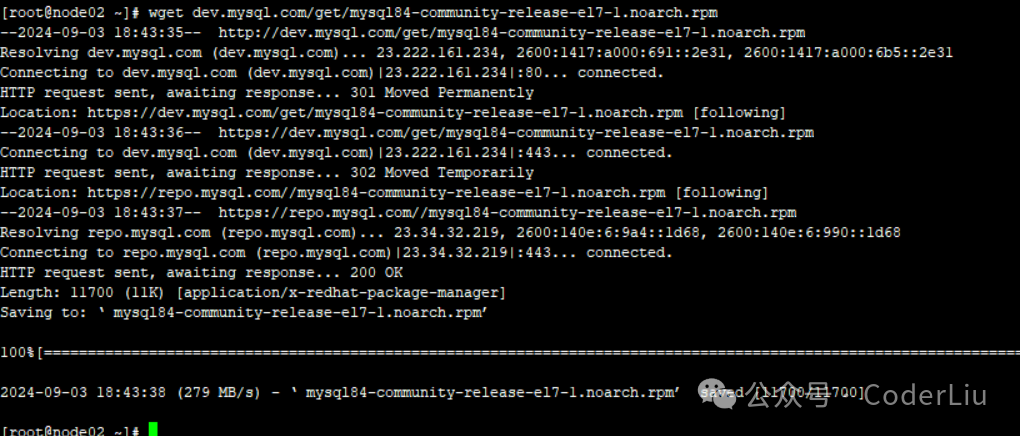
下载安装的rpm源文件
yum install mysql84-community-release-el7-1.noarch.rpm -y使用yum安装mysql
yum install mysql-community-server -ymysql相关的设置
启动服务以及开机自启
#启动mysql服务
service mysqld start
#设置mysql开机启动
chkconfig mysqld on修改密码
| 变量名 | 值 |
|---|---|
| validate_password.changed_characters_percentage | 0 |
| validate_password.check_user_name | on |
| validate_password.length | 8 |
| validate_password.mixed_case_count | 1 |
| validate_password.number_count | 1 |
| validate_password.policy | MEDIUM |
| validate_password.special_char_count | 1 |
##查看临时密码
grep "password" /var/log/mysqld.log
## 临时密码登录
mysql -uroot -p
##修改密码策略和密码
set global validate_password.policy=LOW;
set global validate_password.length=1;
set global validate_password.special_char_count=0;
set global validate_password.mixed_case_count=0 ;
set global validate_password.number_count =0;ALTER USER 'root'@'localhost' IDENTIFIED BY 'rootA@123456';授权 8.0有区别
#创建用户
create user 'echo'@'%' identified by '123456';
# 授权
grant all privileges on *.* to 'echo'@'%' with grant option;
# 刷新权限
FLUSH PRIVILEGES;递归表达式ETC
递归表达式是一种特殊的子查询,它能够引用其本身的查询结果。它包含两部分
SELECT ... -- return initial row set
UNION ALL
SELECT ... -- return additional row sets例如:
WITH RECURSIVE cte (n) AS
(SELECT 1UNION ALLSELECT n + 1 FROM cte WHERE n < 5
)
SELECT * FROM cte;
典型应用
斐波那契数列
WITH RECURSIVE fibonacci (n, fib_n, next_fib_n) AS
(SELECT 1, 0, 1UNION ALLSELECT n + 1, next_fib_n, fib_n + next_fib_nFROM fibonacci WHERE n < 10
)
SELECT * FROM fibonacci;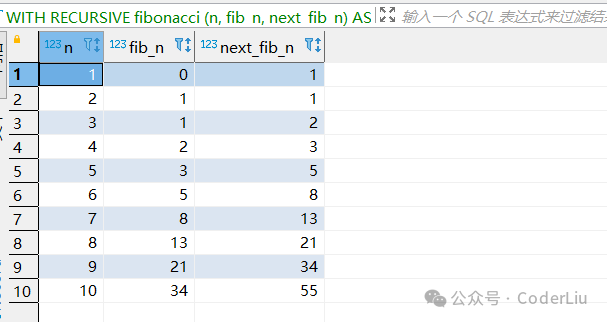
时间序列生成
WITH RECURSIVE dates (date) AS
(SELECT MIN(date) FROM salesUNION ALLSELECT date + INTERVAL 1 DAY FROM datesWHERE date + INTERVAL 1 DAY <= (SELECT MAX(date) FROM sales)
)
SELECT * FROM dates;层次结构遍历
以评论回复为例
WITH RECURSIVE CommentHierarchy AS (SELECT c.comment_id,c.post_id,c.user_id,c.parent_id,c.content,c.created_at,c.updated_at,0 AS levelsFROM Comments cWHERE c.parent_id IS NULLUNION ALLSELECT c.comment_id,c.post_id,c.user_id,c.parent_id,CONCAT(ch.content,'->',c.content) content,c.created_at,c.updated_at,ch.levels + 1 AS levelsFROM Comments cINNER JOIN CommentHierarchy ch ON c.parent_id = ch.comment_id
)
SELECT * FROM CommentHierarchy ORDER BY post_id, levels, created_at;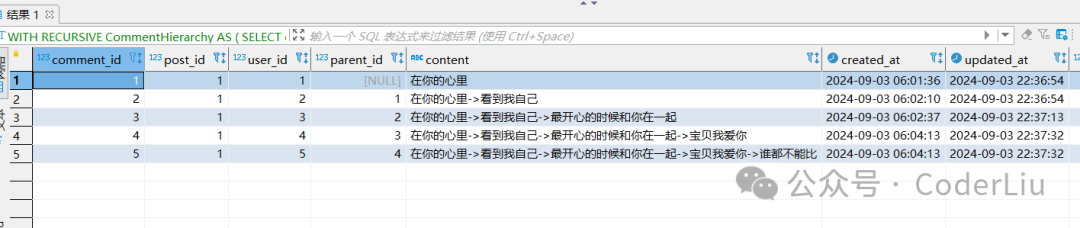
往期推荐
一文带你springai+ollama实现chat
大型语言模型(Large Language Model, LLM)了解一下?
常用的JVM参数与命令你知道吗?
推荐两款程序员高效工作神器
Git命令基操必须要会!
非常nice! IDEA远程Debug调试程序
DataX二次开发之达梦数据库插件
这篇关于Mysql8.0安装以及递归表达式使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





