本文主要是介绍Mac M1 安装Hadoop教程(安装包安装),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、引言
前面一期,我分享了通过homebrew方式安装Hadoop,本期我将通过安装包方式介绍下hadoop如何安装。
二、下载open jdk8
官方下载地址
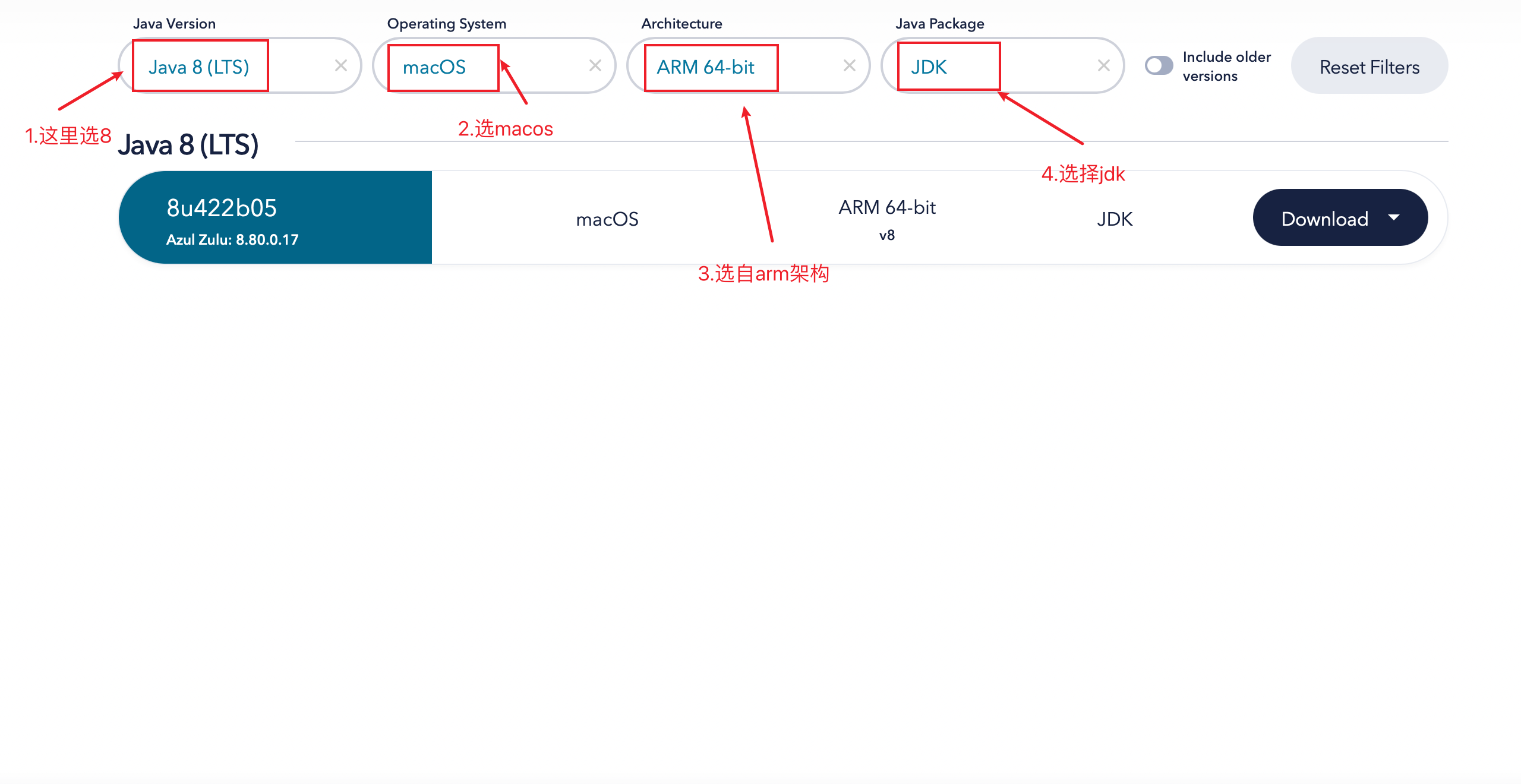
注意如果是x86架构的苹果电脑,Architecture选择x86 64-bit或者 x86-32bit。

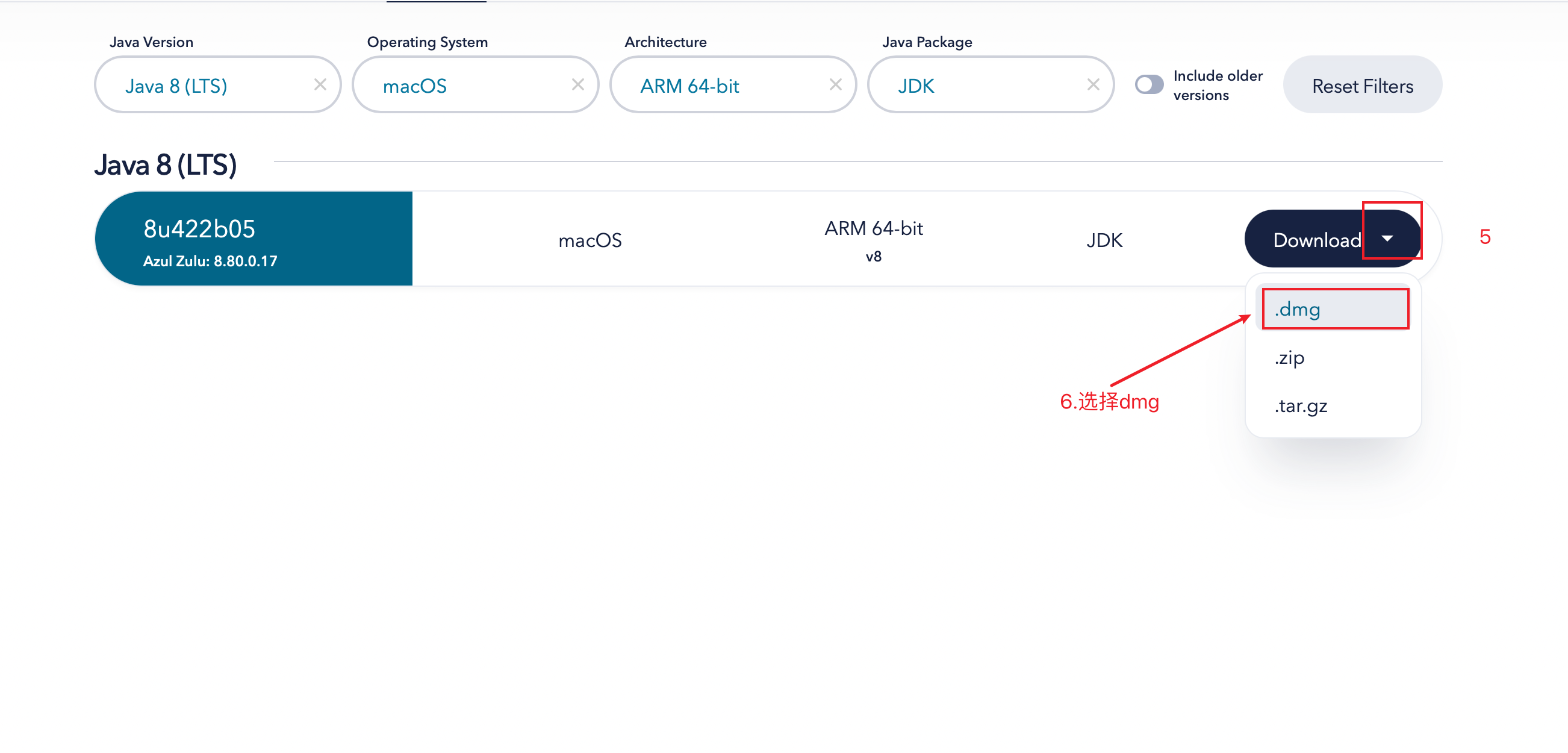
下载后,将得到下面这样一个软件包

三、安装open jdk8
 双击标红的部分,然后按照提示,一直默认安装即可。
双击标红的部分,然后按照提示,一直默认安装即可。
安装后的路径为:
/Library/Java/JavaVirtualMachines/zulu-8.jdk/Contents/Home
四、开启远程共享
选择电脑左上角的苹果🍎图标,打开系统设置,在搜索框中搜索共享,在共享中,打开远程登录和文件共享功能按钮。
五、配置SSH免密登录
1.打开Terminal终端,使用下面命令生成密钥:
ssh-keygen -t rsa
回车、y、回车、回车
2.授权访问
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys# 授予其访问权限(自己访问自己电脑免密)
chmod 600 ~/.ssh/authorized_keys
3.验证登录(不需要密码)
ssh localhost
出现如下提示,说明安装成功:

六、配置hosts
open -e /etc/hosts
在文件中添加如下内容:
127.0.0.1 localhost
并保存。
七、下载和解压Hadoop
1.下载方法参考
2.下载好后,进行解压,将解压后的文件夹命名为hadoop-3.4.0,并将解压的hadoop文件夹放到资源库(这里你可以根据自己需要放到指定路径下,如果放到其它地方有些配置你需要做对应修改)。
八、配置Hadoop
使用VSCode打开Hadoop文件夹,对下面指定文件进行修改。
1.修改hadoop-env.sh
去掉 # export JAVA_HOME= 前的 # 注释;
将上面安装open-jdk的安装路径补充上去;
修改后如下图所示:

2.修改core-site.xml
<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property><property><name>hadoop.tmp.dir</name><value>/Library/hadoop-3.4.0/data</value></property><property><name>hadoop.proxyuser.mark.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.mark.groups</name><value>*</value></property>
</configuration>
新建存放数据的文件夹
mkdir /Library/hadoop-3.4.0/data
3.修改hdfs-site.xml
<configuration><property><name>dfs.replication</name><value>1</value></property>
</configuration>
4.修改mapped-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>
5.修改yarn-site.xml
<configuration><!-- Site specific YARN configuration properties --><property><name>yarn.resourcemanager.hostname</name><value>localhost</value></property> <property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property></configuration>
修改后,注意保存。
九.格式磁盘并启动Hadoop
1.打开终端Terminal,进入Hadoop文件夹
cd /Library/hadoop-3.4.0# 格式化磁盘
./bin/hdfs namenode -format
在打印的日志中,没有报错,且有下面提示表示格式化成功!

如果在执行过程中,发现权限不足,解决办法参考链接
2.启动Hadoop
./sbin/start-all.sh
发现权限不足,解决办法参考链接
3.查看后台进程
jps
出现下面说明启动成功。

十.浏览器访问HDFS和YARN
1.浏览器输入如下网址,查看HDFS
http://localhost:9870



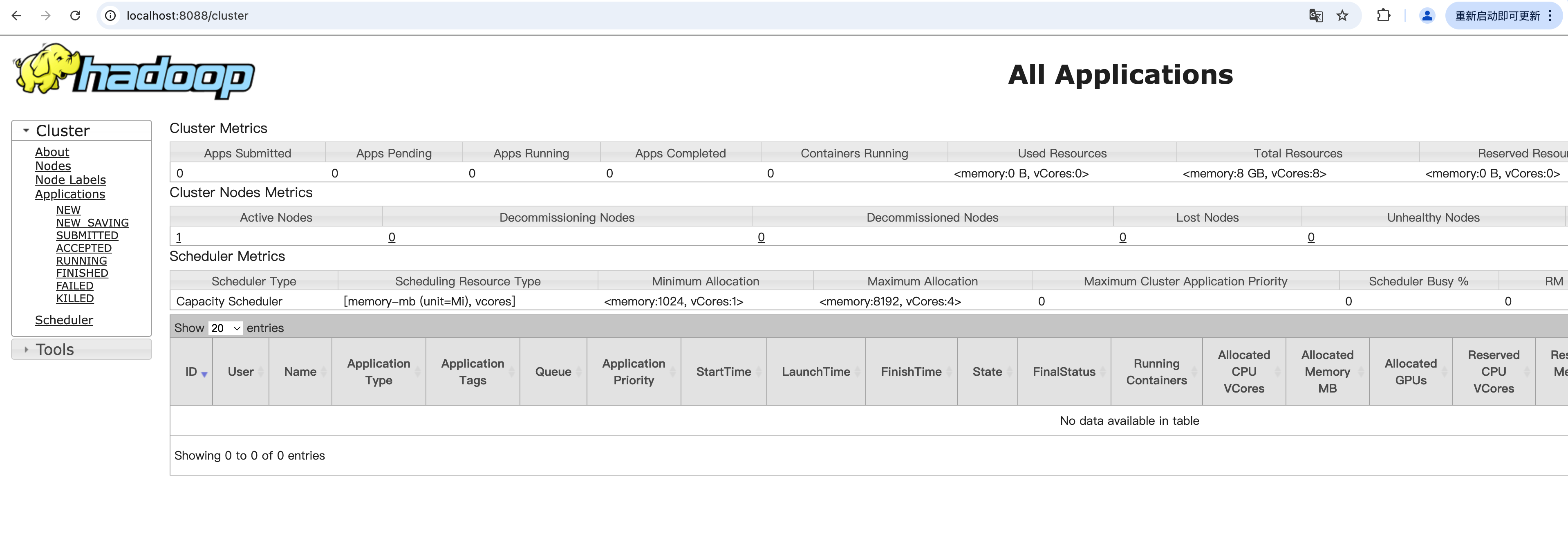
2.查看YARN,浏览器输入如下网址
http://localhost:8088
出现如下界面说明YARN启动成功,有1个节点可用。
这篇关于Mac M1 安装Hadoop教程(安装包安装)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









