本文主要是介绍【Redis】Redis 主从复制,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1 前言
- 2 主从模式介绍
- 3 配置 Redis 主从结构
- 3.1 建立复制
- 3.2 断开复制
- 3.3 其他特性
- 3.4 拓扑结构
- 4 Redis 主从复制原理
- 4.1 复制过程
- 4.2 PSYNC 数据同步
- 4.3 PSYNC 运行流程
- 5 主从复制流程
- 5.1 全量复制流程
- 5.2 部分复制流程
- 5.3 实时复制流程
1 前言
分布式系统中存在一个非常关键的问题 – 单点问题;单点问题指服务器程序只有一个节点,即只使用一个物理服务器来部署服务。这会导致一些问题:
- 可用性问题:如果这个机器挂了,那么服务就中断了;甚至如果这个机器坏了,那么全部数据都会丢失。
- 性能问题:一个物理服务器所能支持的并发量是有限的。
为了解决单点问题,通常会把数据复制多个副本部署到其他服务器,以满足故障恢复和负载均衡等需求。其中,Redis 存在以下三种部署方式:主从模式、主从 + 哨兵模式 以及 集群模式。本节我们来学习 Redis 中主从模式的实现方式及其原理。
2 主从模式介绍
主从模式是指将 Redis 服务部署到多个物理服务器上,然后让其中的一个节点作为 “主节点”,让其他节点作为 “从节点”。其中主节点与从节点的关系如下:
- 从节点隶属于主节点,即从节点中的数据要跟随主节点变化,且从节点的数据要与主节点保持一致。
- 主节点只负责写入,即主节点只处理修改请求,并且需要将修改请求同步到从节点。
- 从节点只负责读取,从节点中的数据不允许修改,即从节点只处理查询请求。
通过主从复制的方式我们能够有效的解决单点问题:
- 可用性问题:如果从节点挂了,不影响客户端读写请求。当主节点挂了,只需要重启主节点或让某个从节点成为主节点即可,不影响客户端读写请求,也不会丢失数据。
- 性能问题:将读请求全部分摊给从节点去执行,大大降低了主节点的压力,因为实际业务中绝大部分请求都是读请求。
3 配置 Redis 主从结构
3.1 建立复制
要配置 Redis 主从结构,首先需要启动多个 Redis 服务,且这些 Redis 服务需要部署在不同服务器上,这样才能起到分布式的效果。但由于本人只有一台云服务器,因此在一台服务器上启动多个 redis-server 进程来模拟。
如下,服务器上启动了三个 redis-server:
[root@VM-8-13-centos redis]# pwd
/etc/redis
[root@VM-8-13-centos redis]# ll *.conf
-rw-r----- 1 redis root 61888 Aug 25 14:19 redis.conf
-rw-r----- 1 redis root 9837 Oct 25 2021 redis-sentinel.conf
-rw-r----- 1 root root 61888 Sep 1 14:42 redis_slave1.conf
-rw-r----- 1 root root 61888 Sep 1 14:43 redis_slave2.conf
[root@VM-8-13-centos redis]# redis-server redis.conf --port 6379
[root@VM-8-13-centos redis]# redis-server redis_slave1.conf --port 6380
[root@VM-8-13-centos redis]# redis-server redis_slave2.conf --port 6381
[root@VM-8-13-centos redis]# ps axj | grep redis1 6022 6022 6022 ? -1 Ssl 0 0:00 redis-server 0.0.0.0:63791 7521 7521 7521 ? -1 Ssl 0 0:00 redis-server 0.0.0.0:63801 7585 7585 7585 ? -1 Ssl 0 0:00 redis-server 0.0.0.0:63813429 7637 7636 3240 pts/0 7636 S+ 0 0:00 grep --color=auto redis
目前这几个节点并没有构成主从结构,而是三个独立的节点,而配置主从结构的方法有三种:
- 在配置文件中加入
slaveof {masterHost} {masterPort},此时配置随 Redis 启动生效。 - 在 redis-server 启动命令时加入
--slaveof {masterHost} {masterPort}生效。 - 直接使用 redis 命令:
slaveof {masterHost} {masterPort}生效。
其中,后面两种方法都是临时配置,即 redis-server 重启后需要重新执行 slaveof 命令,而第一种方式是永久生效的,不过修改配置文件后需要重启 redis-server 才能让配置生效。
下面我们演示第一种方法:
首先,修改配置文件 redis_slave1.conf 与 redis_slave2.conf,追加 salveof 配置。
# 主从复制
slaveof 127.0.0.1 6379
然后,重新启动端口号为 6380 与 6381 的节点,观察其与 6379 节点的关系:
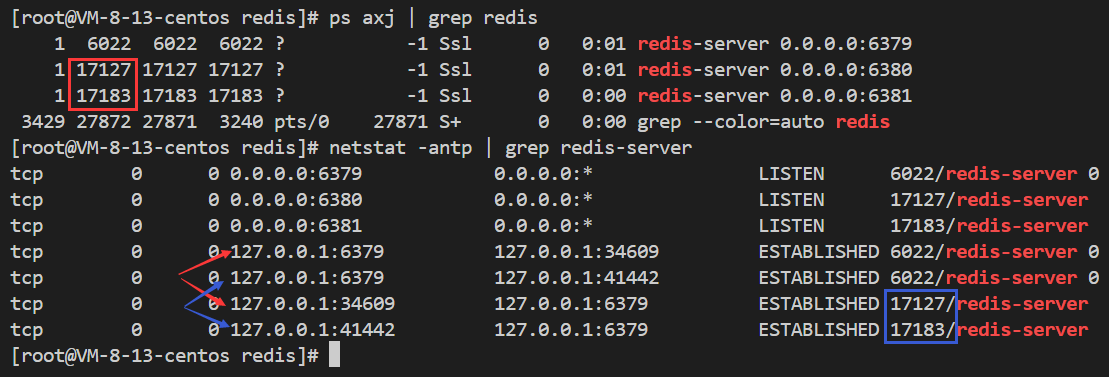
如上,Redis 子节点与从节点之间会建立两个 TCP 连接,一个用于接收主节点命令的命令连接(主节点将所有的写命令发送到这个连接,从节点接收这些命令并执行,以此来保证数据的一致性),一个用于支持发布/订阅功能的订阅连接。
此时,我们在主节点上进行的任何数据修改操作,从节点都会同步,且从节点不允许修改:
127.0.0.1:6380> set k1 111
(error) READONLY You can't write against a read only replica.
127.0.0.1:6380>
同时,我们可以通过 info replication 命令查看主节点与从节点的复制信息:
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=2954,lag=0
slave1:ip=127.0.0.1,port=6381,state=online,offset=2968,lag=0
master_replid:12acce366cb00f35ebb02447c42ce61af38b3528
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:2968
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:2968
127.0.0.1:6379>
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:8
master_sync_in_progress:0
slave_repl_offset:2982
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:12acce366cb00f35ebb02447c42ce61af38b3528
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:2982
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:2982
127.0.0.1:6380>
3.2 断开复制
对于已经建立好的主从复制关系,我们可以使用 slave no one 将其断开,此命令由从节点执行,执行后从节点将变成一个独立的节点,且无法再同步主节点修改的数据,但从节点中原有的数据并不会丢弃。
需要注意的是:在从节点中执行 slave no one 命令是临时性的,即从节点重启后仍然会复制主节点;想要永久生效需要删除或修改配置文件中的 slaveof 配置项。
另外,slave no one 命令配合 slaveof 命令使用可以实现切主效果,即将当前从节点的数据源切换到另一个主节点。切主操作的主要流程如下:
- 断开与旧主节点复制关系。
- 与新主节点建立复制关系。
- 删除从节点当前所有数据。
- 从新主节点进行复制操作。
3.3 其他特性
主从复制还有一些其他相关的特性,如下:
-
安全性:对于数据比较重要的节点,主节点会通过设置
requirepass参数进行密码验证,这时所有的客户端访问必须使用auth命令实行校验。从节点与主节点的复制连接是通过一个特殊标识的客户端来完成,因此需要配置从节点的masterauth参数与主节点密码保持一致,这样从节点才可以正确地连接到主节点并发起复制流程。 -
只读:默认情况下,从节点使用
slave-read-only yes配置为只读模式。由于复制只能从主节点到从节点,对于从节点的任何修改主节点都无法感知,因此修改从节点会造成主从数据不一致,所以不建议修改从节点的只读模式。 -
传输延迟:主从节点一般部署在不同机器上,复制时的网络延迟就成为需要考虑的问题。Redis 为我们提供了
repl-disable-tcp-nodelay参数用于控制是否关闭TCP_NODELAY,默认为no,即开启tcp-nodelay功能,说明如下 (TCP 内部的 nagle 算法):为 no 即不关闭
TCP_NODELAY时,主节点产生的命令数据无论大小都会及时地发送给从节点,这样主从之间延迟会变小,但增加了网络带宽的消耗。适用于主从之间的网络环境良好的场景,如 同机房部署。为 yes 即关闭
TCP_NODELAY时,主节点会合并较小的 TCP 数据包从而节省带宽。默认发送时间间隔取决于 Linux 的内核,一般默认为 40 毫秒。这种配置节省了带宽但增大主从之间的延迟。适用于主从网络环境复杂的场景,如跨机房部署。
3.4 拓扑结构
Redis 拓扑结构指 Redis 主从节点之间按照怎样的方式来组织连接。Redis 的复制拓扑结构可以支持单层或多层复制关系,根据拓扑复杂性可以分为以下三种:一主一从、一主多从、树状主从结构。
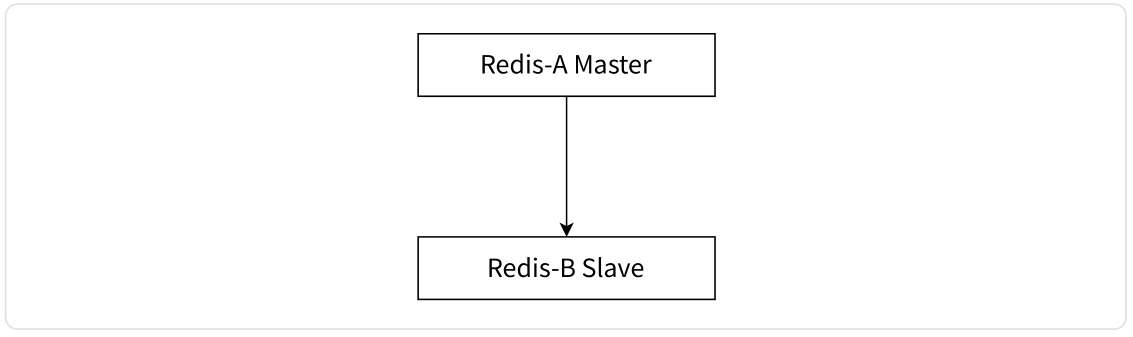
一主一从结构
一主一从结构是最简单的复制拓扑结构,用于主节点出现宕机时从节点提供故障转移支持。
如下图所示,当应用写命令并发量较高且需要持久化时,可以只在从节点上开启 AOF,这样保证数据安全性的同时也避免了持久化对主节点的性能干扰。但这种设定有一个严重缺陷,即主节点宕机后不能让其自动重启,而是需要先从从节点获取 AOF 文件,然后使用该 AOF 文件进行重启与数据恢复,否则会导致数据丢失。
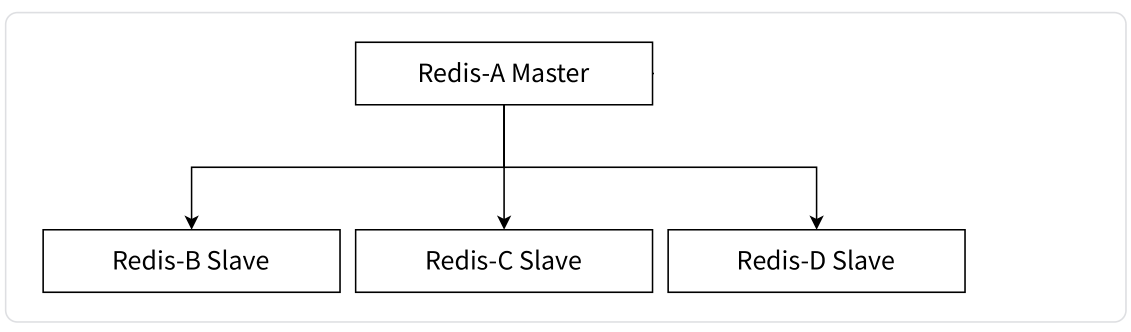
一主多从结构
一主多从结构使得应用端可以利用多个从节点实现读写分离,从而提高并发量。(实际开发中,一般读请求都要远多于写请求)
如下图所示,对于读比重较大的场景,可以把读命令负载均衡到不同的从节点上来分担压力,同时一些耗时的读命令可以指定一台专门的从节点执行,避免破坏整体的稳定性。但缺点在于,对于写并发量较高的场景,多个从节点 会导致主节点写命令的多次发送 从而加重主节点的负载。
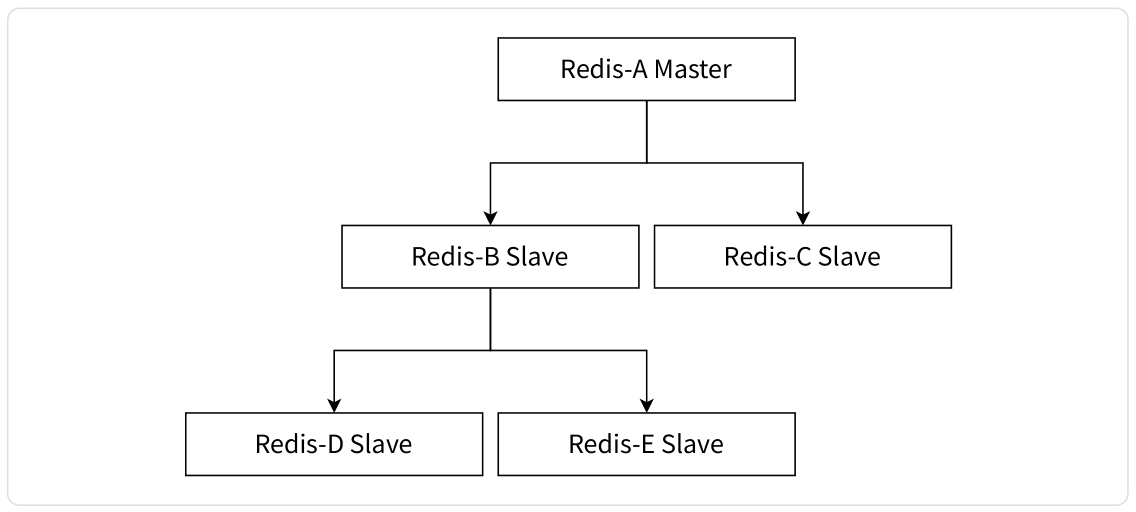
树状主从结构
树形主从结构使得从节点不但可以复制主节点数据,同时可以作为其他从节点的主机节点 (主机节点而不是主节点,其他从节点的主节点仍然是根节点) 继续向下层复制。通过引入复制中间层,可以有效降低主节点 “写” 负载和需要传送给从节点的数据量。
如下图所示,数据写入节点 A 之后会同步给 B 和 C 节点,B 节点进一步把数据同步给 D 和 E 节点。当主节点需要挂载多个从节点时为了避免对主节点的性能干扰,可以采用这种拓扑结构。但它的缺点在于,由于主节点数据需要逐层向下同步,因此同步的延时比较高。
4 Redis 主从复制原理
4.1 复制过程
Redis 复制建立以及运行的流程如下:
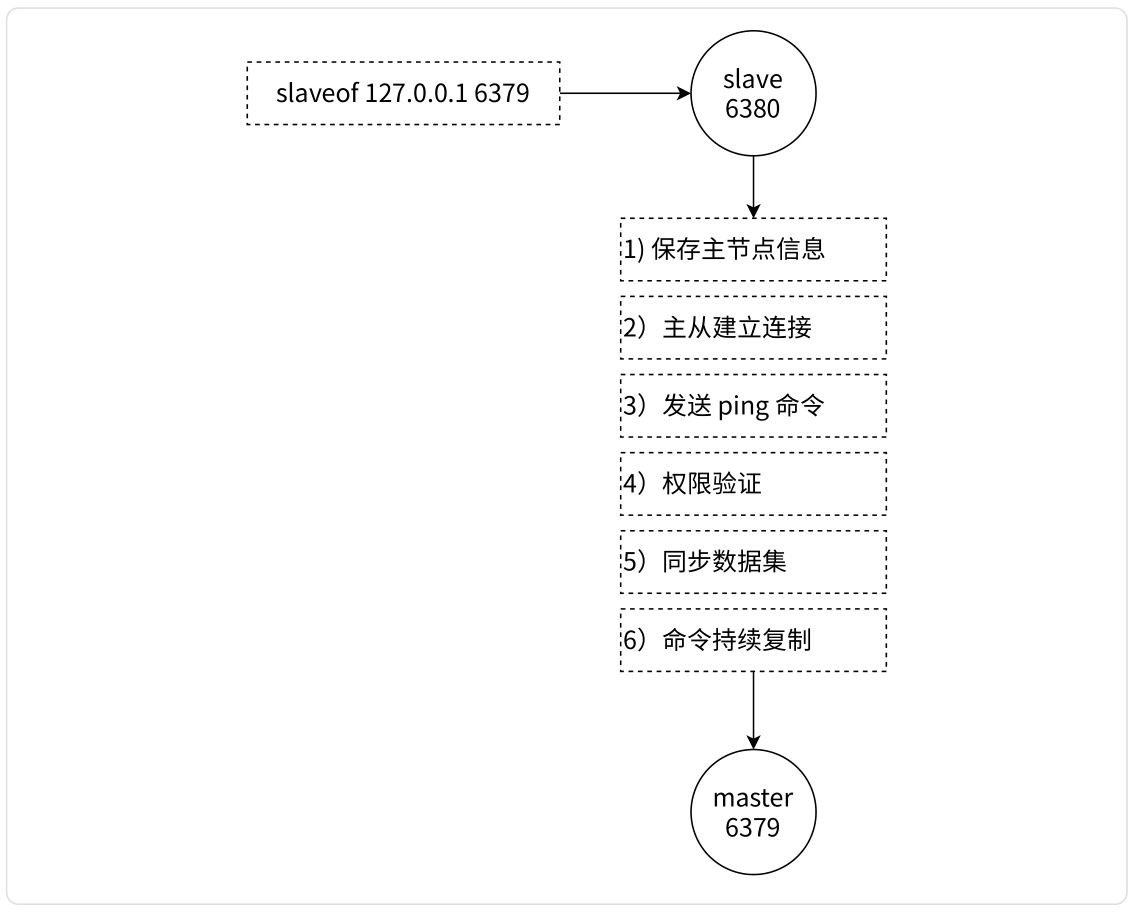
- 保存主节点信息:从节点保存主节点的 IP + PORT 信息。
- 主从建立连接:从节点向主节点发起三次握手,建立 TCP 连接。(在系统层面上验证双方通信信道是否正常)
- 发送 ping 命令:从节点向主节点发送
ping,主节点返回pong。(在应用层面上验证主节点能够正常工作) - 权限验证:如果主节点设置了
requirepass参数,需要进行密码验证。 - 同步数据集:对于首次建立复制的场景,主节点会把当前持有的所有数据全部发送给从节点,即全量同步;对于断开重连的从节点,会根据情况进行全量同步或部分同步。
- 命令持续复制:当从节点复制了主节点的所有数据之后,针对之后的修改命令,主节点会持续的把命令发送给从节点,从节点执行修改命令,保证主从数据的一致性。
4.2 PSYNC 数据同步
Redis 使用 psync 命令完成主从数据同步,同步分为全量复制和部分复制:
- 全量复制:一般用于初次复制场景,Redis 早期支持的复制功能只有全量复制,它会把主节点全部数据一次性发送给从节点,当数据量较大时,会对主从节点和网络造成很大的开销。
- 部分复制:用于处理在主从复制中因网络闪断等原因造成的数据丢失场景,当从节点再次连上主节点后,如果条件允许,主节点会补发数据给从节点。因为补发的数据远小于全量数据,可以有效避免全量复制的过高开销。
 从节点在与主节点建立好主从关系后会自动执行 psync 进行数据同步,不需要我们手动执行。
从节点在与主节点建立好主从关系后会自动执行 psync 进行数据同步,不需要我们手动执行。
psync 命令的语法如下:
PSYNC replicationid offset
- replicationid / replid (复制ID):这里的 replid 指的是主节点的复制 ID,主节点每次启动时都会生成一个 replid (同一节点每次重启其 replid 也会变化),从节点在与主节点建立连接时会保存主节点 replid,主节点根据从节点传递过来的 replid 的值进行对应的操作。
- offset (偏移量):参与复制的主从节点都会维护自身复制偏移量。主节点在处理完修改命令后,会把命令的字节长度做累加记录,统计信息在
info replication中的master_repl_offset指标中;从节点也会每秒钟上报自身的复制偏移量给主节点 (同步进度),并保存在 slave 行的offset字段中。 - replid 与 offset 共同描述了一个 “数据集”,如果发现两个节点的 replid 与 offset 都一样,则可以认为这两个节点中存储的数据时一样的。
- 初次复制时,replid 的值为
?,offset 的值为-1,此时表示进行全量复制。重连时,如果 replid 与 offset 为某个具体的值,则表示进行部分复制。
我们可以通过 info replication 命令查看主从节点相关的复制信息:
主节点:
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=114282,lag=1
slave1:ip=127.0.0.1,port=6381,state=online,offset=114282,lag=1
master_replid:12acce366cb00f35ebb02447c42ce61af38b3528
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:114282
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:114282
如上,主节点修改命令字节数 master_repl_offset 为 114282,从节点 slave0 和 slave1 的同步进度 offset 都为 114282,表示数据全部都已经同步了。
 关于
关于 master_replid 和 master_replid2:
从
info replication的输出可以看到,每个节点都记录了两组master_replid,这是为了预防网络抖动。考虑下面的场景:
比如当前有两个节点 A 和 B,A 为 master,B 为 slave。此时 B 就会记录 A 的
master_replid。如果网络出现抖动,B 以为 A 挂了,B 自己就会成为主节点。于是 B 给自己分配了新的
master_replid。此时就会使用master_replid2来保存之前 A 的master_replid。这样后续如果网络恢复了,B 就可以根据
master_replid2找回之前的主节点,然后进行数据的部分同步。续如果网络没有恢复,B 就按照新的master_replid自成一派,继续处理后续的数据。
4.3 PSYNC 运行流程
psync 命令的运行流程如下:
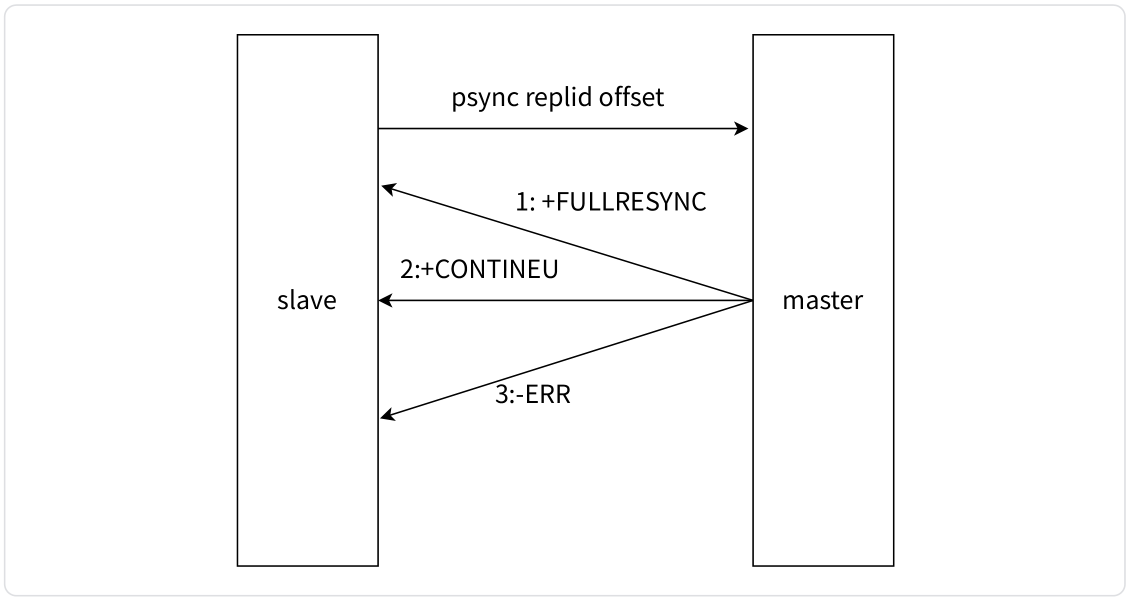
- 从节点发送
PSYNC命令给主节点,且replid和offset的默认值分别是?和-1。 - 主节点根据
PSYNC参数和自身数据情况决定响应结果:- 如果回复
+FULLRESYNC,则从节点需要进行全量复制流程。 - 如果回复
+CONTINUE,从节点进行部分复制流程。 - 如果回复
-ERR,说明 Redis 主节点版本过低,不支持PSYNC命令。从节点可以使用SYNC命令进行全量复制。(二者的区别在于,sync 会阻塞 redis-server,psync 则不会阻塞)
- 如果回复
5 主从复制流程
5.1 全量复制流程
全量复制流程如下:
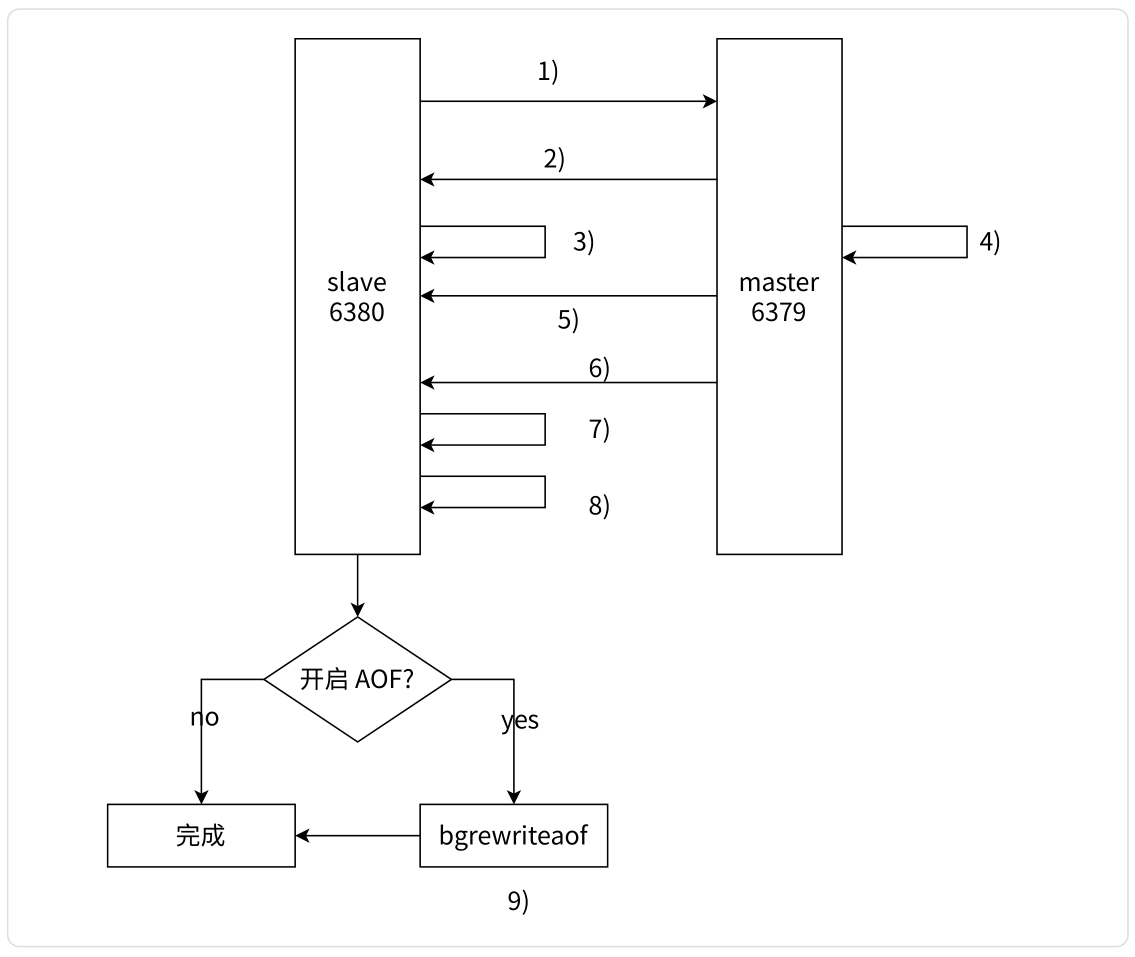
- 从节点发送
PSYNC命令给主节点进行数据同步,由于是第一次进行复制,从节点没有主节点的运行 ID 和复制偏移量,所以发送PSYNC ? -1。 - 主节点根据命令,解析出要进行全量复制,回复
+FULLRESYNC响应。 - 从节点接收主节点的运行信息进行保存,包括主节点的 replid 与当前的 offset。
- 主节点执行
BGSAVE进行 RDB 文件的持久化。 - 主节点发送 RDB 文件给从节点,从节点保存 RDB 数据到本地硬盘 (全量数据)。
- 主节点将 从生成 RDB 到接收完成期间执行的 写命令 写入缓冲区中,等从节点保存完 RDB 文件后,主节点再将缓冲区内的数据补发给从节点,补发的数据仍然按照 RDB 的二进制格式追加写入到收到的 RDB 文件中,保持主从一致性 (增量数据)。
- 从节点清空自身原有旧数据。
- 从节点加载 RDB 文件得到与主节点一致的数据。
- 如果从节点加载 RDB 完成之后,并且开启了 AOF 持久化功能,它会进行
BGREWRITE操作,得到最近的 AOF 文件。
 有磁盘复制 VS 无磁盘复制:
有磁盘复制 VS 无磁盘复制:
Redis 从 2.8.18 版本开始支持无磁盘复制。即主节点在执行 RDB 生成流程时,不会生成 RDB 文件到磁盘中,而是直接把生成的 RDB 数据通过网络发送给从节点,然后从节点直接直接将收到的 RDB 数据进行加载,这样就节省了一系列的写硬盘和读硬盘的操作开销。
但即使是这样,全量复制的开销也很大,因为要将所有的数据通过网络进行传输,而网络传输的代价比写磁盘要高很多。
5.2 部分复制流程
部分复制流程如下:
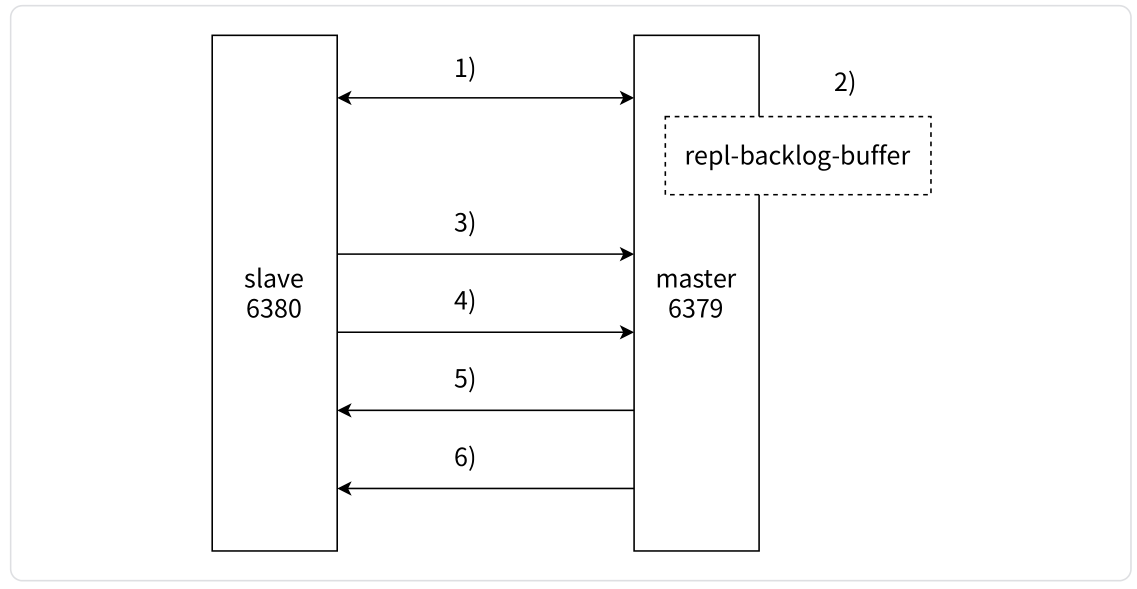
- 当主从节点之间出现网络中断时,如果超过
repl-timeout时间,主节点会认为从节点故障并终止复制连接。 - 主从连接中断期间主节点依然响应命令,但这些复制命令都因网络中断无法及时发送给从节点,所以暂时将这些命令滞留在复制积压缓冲区
repl-backlog-buffer中。 - 当主从节点网络恢复后,从节点再次连上主节点。
- 从节点将之前保存的
replicationId和复制偏移量作为PSYNC的参数发送给主节点,请求进行部分复制。 - 主节点接到
PSYNC请求后,进行必要的验证。然后根据offset去repl-backlog-buffer查找合适的数据,并响应+CONTINUE给从节点。 - 主节点将需要从节点同步的数据发送给从节点,最终完成一致性。
 特别注意:
特别注意:
- 关于复制积压缓冲区:复制积压缓冲区是保存在主节点上的一个固定长度的队列,默认大小为 1MB,当主节点有连接的从节点时被创建,这时主节点响应写命令时,不但会把命令发送给从节点,还会写入复制积压缓冲区。因此它能实现保存最近已复制数据的功能,可以用于部分复制和复制命令丢失的数据补救。
但由于缓冲区大小是固定的,因此如果从节点重连时需要的数据,已经超出了主节点的积压缓冲区的范围,则无法进行部分复制,只能全量复制了。
- 关于 replid 与 runid:如果大家在网上搜索 “Redis 主从复制” 相关的文章,会发现很多文章都会提到服务器运行ID (runid),文中提到由于服务器每次运行的 runid 都不同,因此从节点可以根据自己保存的 runid 与主节点现有的 runid 是否相同来判断重连的是否是之前的主节点,从而只进行部分复制。
但其实 runid 与主从复制并没有关系,主从复制时使用的是 replid。如果主节点与从节点之间发生网络抖动而断连,此时从节点master_replid2中会保存主节的 replid,然后自己成为主节点。当网络恢复二者重连时,从节点向主节点发送psync master_replid2 offset,主节点根据 replid 是否相同以及 offset 与复制积压缓冲区的情况来决定是否进行部分复制。
因此,在主从复制中起作用的是 replid,runid 作用于哨兵。
5.3 实时复制流程
主从节点在建立复制连接后,会进行实时复制 (实时数据同步)。主节点会把自己收到的修改命令,通过 TCP 长连接的方式,源源不断地传输给从节点 (注意发送的是命令而不是二进制数据)。从节点会根据这些请求来同时修改自身的数据,以保持和主节点数据的一致性。
另外,这样的长连接,需要通过心跳包的方式来维护连接状态:(这里的心跳是指应用层自己实现的心跳,而不是 TCP 自带的心跳)
- 主从节点彼此都有心跳检测机制,各自模拟成对方的客户端进行通信。
- 主节点默认每隔 10 秒对从节点发送 ping 命令,判断从节点的存活性和连接状态。
- 从节点默认每隔 1 秒向主节点发送
replconf ack {offset}命令,给主节点上报自身当前的复制偏移量。
如果主节点发现从节点通信延迟超过 repl-timeout 配置的值(默认 60 秒),则判定从节点下线,断开复制客户端连接。从节点恢复连接后,心跳机制继续进行。
这篇关于【Redis】Redis 主从复制的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





