本文主要是介绍关于Embedding的两种实现方式,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 言简意赅
- 方式一
- 方式二
- 以DNN为例两种方式全部demo代码
言简意赅
假设现在有一段话:“我爱你中国”,在训练入模的时候,常用的方法分别有:onehot、embedding、hash,如果词表很大、特征很多,那么onehot之后会极其稀疏,hash也会有一定的hash冲突,所以这其中emb是最常用的方法。
我们希望,通过一个向量去表征每一个词,以“我爱你中国”为例,将其映射成为一个二维矩阵,矩阵的维度即(词表大小,emb维度)。

对于结构化数据而言,假设我们现在有2个特征分别为“性别”、“设备品牌”,这里规范下概念方便代码实现,如下图:
一个类别特征对应一个Field,但是对应多个Feature:
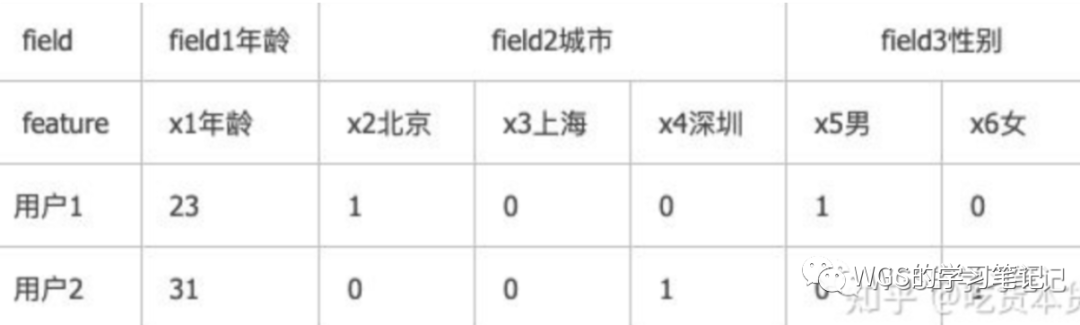
所以按照上面的例子,field有两个,分别为“性别”、“设备品牌”,假设性别有男女2个,设备品牌有3个,它们则分别对应着feature,即特征值。按照emb的方式,我们需要对每一个feature都去学习一个向量表征。
下面方法均以此例为基础讲解
- x1、x2分别代表“性别”、“设备品牌”,为特征域field
- 经过编码后特征值分别为2个、3个,即0 1、0 1 2
- batch_size = 3
- emb_dim = 10

方式一
推荐使用方式二
思路:对于每一个特征field定义一个emb向量,然后进行拼接。
- 1.定义每个特征field的词表大小,即有多少个特征值;
- 2.为每一个特征field定义一个emb向量;
- 3.拼接每个特征的emb向量。
''' 用于 spare field embedding '''
def sparseFeature(feat, vocabulary_size, embed_dim):return {'spare': feat, 'vocabulary_size': vocabulary_size, 'embed_dim': embed_dim}# 每个特征field的词表大小,即有多少个特征值
spare_feature_columns = [sparseFeature(x, data[x].max() + 1, emb_dim) for x in ['x1', 'x2']]
print('spare_feature_columns: ', spare_feature_columns)# 为每一个特征field定义一个emb向量
embedding_layer = nn.ModuleDict({'embed_layer{}'.format(i): nn.Embedding(feat['vocabulary_size'], feat['embed_dim'])for i, feat in enumerate(spare_feature_columns)})
# 初始化权重
for i in range(len(spare_feature_columns)):torch.nn.init.xavier_uniform_(embedding_layer['embed_layer{}'.format(i)].weight.data)print('embedding_layer: ', embedding_layer) tensor = tensor.long() # 转成long类型才能作为nn.embedding的输入
# 拼接每个特征的emb向量
sparse_emb = torch.cat([embedding_layer['embed_layer{}'.format(i)](tensor[:, i])for i in range(tensor.shape[1])], dim=1)
print(sparse_emb.shape)
print(sparse_emb)
'''
spare_feature_columns: [{'spare': 'x1', 'vocabulary_size': 2, 'embed_dim': 10}, {'spare': 'x2', 'vocabulary_size': 3, 'embed_dim': 10}]embedding_layer: ModuleDict((embed_layer0): Embedding(2, 10) (embed_layer1): Embedding(3, 10)
)torch.Size([3, 20])tensor([[ 0.4941, 0.3774, -0.5872, -0.5937, 0.6413, -0.6516, 0.6855, -0.2272, 0.3905, -0.5630, -0.0726, 0.6481, 0.0143, 0.0614, 0.0460, -0.2215, -0.6515, 0.0103, -0.4000, 0.5353], [ 0.4941, 0.3774, -0.5872, -0.5937, 0.6413, -0.6516, 0.6855, -0.2272, 0.3905, -0.5630, 0.5236, 0.3958, -0.1983, 0.4128, -0.0349, -0.5609, 0.4050, -0.4603, 0.3048, -0.6483], [-0.2146, -0.4806, 0.2180, 0.3497, 0.1291, -0.4531, -0.6532, 0.2385, 0.3290, -0.7043, 0.1372, -0.1554, 0.0272, -0.4285, -0.2797, -0.0988, 0.2602, 0.6084, 0.0169, 0.0712]])
'''
方式二
这个是比较推荐的方式,并且经过实践这个方式比第一种方式效果还要好。
我们引入一个offset的概念,它的作用就是给每列特征的label加入之前特征的类别总和,来达到所有特征的label。以上述为例来理解下:
feature_fields = [2, 3],它代表“性别”、“设备品牌”各有几个特征值。
offsets = [0 2],它其实就代表着look up table。
即实际look up table中:
- 0 - 1 行,对应特征性别,它的取值为0、1,所以dim为2,即feature_fields[0];
- 2 - 4 行,对应特征设备品牌,它的取值为0、1、2,所以dim为3,即feature_fields[1];
但实际特征取值 forward(self, x) 的x大小 只在自身词表内取值:
- 比如性别取值为1的时候,对应embedding内行数就是 offsets[性别] + 性别 = 0 + 1 = 1,也就是当x_性别取值为1的时候,对应emb的行数为1,注意是索引;
- 再比如设备品牌取值为1的时候,对应embedding内行数就是 offsets[设备品牌] + 设备品牌 = 2 + 1 = 3;
所以offsets的作用其实就是找到每个特征值的emb向量。
所以思路为:获取每个特征的特征值,创建对应的offsets,再将两者相加,然后emb
- 1.获取每个特征的特征值;
- 2.定义offsets;
- 3.创建emb。



以DNN为例两种方式全部demo代码
https://wangguisen.blog.csdn.net/article/details/125928623
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。
这篇关于关于Embedding的两种实现方式的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




