本文主要是介绍内存管理篇-17解开页表的神秘面纱-下,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.页表初探遗留问题-页表的创建过程
- 使用MMU之前,页表要准备好,怎么准备的?如何把物理内存通过section映射构建页表
- 页表的创建过程分析:__create_page_tables--创建临时页表,然后在开启MMU
-
- 页表的大小和用途
- 页表在内存中的地址
- 页表的创建过程
- 内核在上电的时候,MMU还没有开启,此时运行在物理内存(前期都是一些汇编指令,这些指令和相对地址无关)。C语言的函数都是编译链接成虚拟地址,所以需要尽快打开MMU(在汇编阶段)。然后,在开启MMU之前,页表需要准备好。
- 处理器工作在实地址模式(real address mode)或物理地址模式(physical address mode)。在这种模式下,所有的内存访问都是直接基于物理地址的,这意味着CPU直接将程序中的内存地址解释为物理内存中的地址。在Linux内核启动的早期阶段,它也运行在实地址模式下。在这个阶段,内核需要初始化MMU并设置页表,以便能够切换到保护模式(protected mode),此时MMU开始工作,可以支持虚拟内存。汇编语言或其他底层编程语言编写的代码可以直接操作物理地址,因为没有MMU来进行地址转换。一旦MMU被启用并且设置了适当的页表之后,操作系统就可以使用虚拟地址,这些地址会被MMU自动映射到物理地址。
2.构建section页表的示例
背景:在特殊的场景下,配置的内核和用户是1:1,0x0 - 0x80000000-1是用户空间,0x80000000 - 0xffffffff是内核空间。并且dram上物理地址的起始是0x60000000 - xxxx。
在Linux内核中,初始化阶段会使用一些特殊的页表条目来映射关键的内存区域。这些条目可能覆盖整个内存范围,或者特定的大块区域,例如内核映像本身和其他重要的内存段。例如,在x86架构上,Linux内核可能会使用一些特殊的宏和函数来设置这些大的映射。这通常发生在内核的初始化代码中,例如在arch/x86/kernel/head.S文件中,可以看到初始化MMU的相关代码。当MMU被完全启用后,内核会逐步细化这些大页映射,将其分解为更小的页表条目,以便提供更精细的内存管理控制。
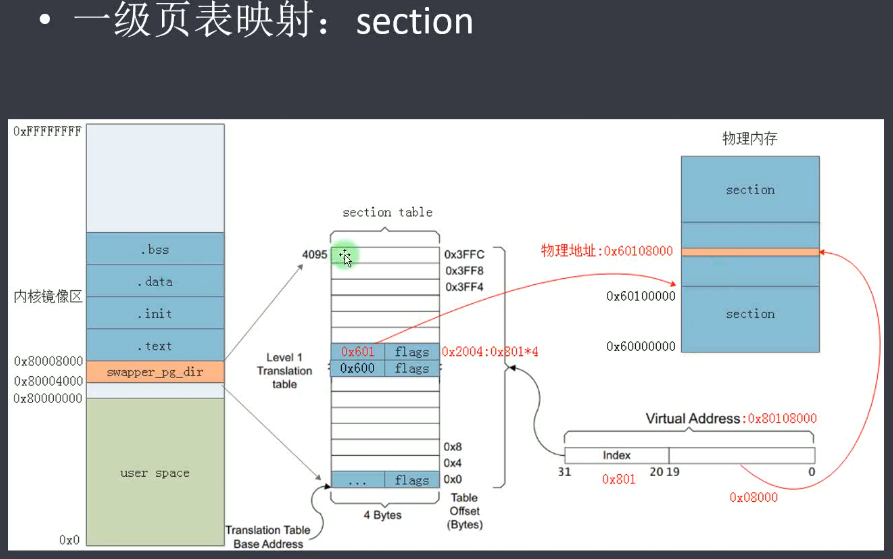
(1)页表最开始一般放在(内核起始空间偏移0x4000)起始地址0x80000000偏移0x4000的这个地方。-原因是啥?0x80004000-0x80008000之间,大小是16KB。并且当前物理平台的物理地址是从0x60000000开始,虚拟地址是从0x80000000开始(内核配置了用户和内核地址比例为1:1)
(2)接下来我们需要把我们的代码段,数据段,bss段等区域的页表创建好,并且映射到物理内存。建立好页表之后才能开启MMU。

(3)早期的映射是采用section映射方式(一级页表映射),1M位单位进行映射。前面已经说到,1MB大页进行映射,4GB需要4096个一级页表的entry,每个entry占用4字节,一共16KB的大小。需要把这个内容存放在物理内存上。
(4)以一个虚拟地址为0x80108000虚拟地址为例,转成物理地址。首先去掉后20位(1MB大页映射,页内偏移为 1MB)得到index为0x801,接着去page table找到第0x801项entry,(此时page table也是在内存上的一部分空间,是按照字节编址,但是每个单位是4字节,因此第0x801项就是0x801*4字节=0x2004的物理地址所在的地方。) 找到对应的entry后,查看物理PFN为0x601,因为物理地址的编制是0x60000000,所以直接找到0x601 << 20 + 0x08000就得到物理地址了。
3.源码分析-将内核.text - .bss映射
(5)代码分析:D:\open_project\linux-5.10.84\linux-5.10.84\arch\arm\kernel\head.S汇编中的__create_page_tables函数就是进行准备页表的过程。
- 在上电后不久就直接调用了 bl __create_page_tables函数;/*在ARM架构中,pgtbl 是一个伪指令,用于生成特定的内存映射条目,通常用于初始化页表。这个伪指令在编译时被展开成一系列实际的机器码指令,用于设置页表条目的值。pgtbl 通常用于在内核初始化阶段设置页表,以便正确地配置内存映射。pgtbl 伪指令的功能是将第二个寄存器(在你的例子中是 r8)的内容复制到第一个寄存器(在你的例子中是 r4)中,并且在复制过程中可能会进行一些特定的处理,如清零某些位。*/
/** Setup the initial page tables. We only setup the barest* amount which are required to get the kernel running, which* generally means mapping in the kernel code.** r8 = phys_offset, r9 = cpuid, r10 = procinfo** Returns:* r0, r3, r5-r7 corrupted* r4 = physical page table address*/
__create_page_tables:pgtbl r4, r8 @ page table address R4保存了页表的物理起始地址
/*在ARM架构中,pgtbl 是一个伪指令,用于生成特定的内存映射条目,通常用于初始化页表。这个伪指令在编译时被展开成一系列实际的机器码指令,用于设置页表条目的值。pgtbl 通常用于在内核初始化阶段设置页表,以便正确地配置内存映射。pgtbl 伪指令的功能是将第二个寄存器(在你的例子中是 r8)的内容复制到第一个寄存器(在你的例子中是 r4)中,并且在复制过程中可能会进行一些特定的处理,如清零某些位。*//** Clear the swapper page table*/mov r0, r4 @r0是内核页表的起始地址0x80004000mov r3, #0 @对16KB的临时页表进行清零r3 = 0add r6, r0, #PG_DIR_SIZE @内核页表的结束地址保存在r6里面 r6=0x80004000 + 16KB=0x80008000
1: str r3, [r0], #4str r3, [r0], #4str r3, [r0], #4str r3, [r0], #4teq r0, r6 @测试r0是否等于r6,清空这段空间bne 1b。。。。。。
。。。。。。/** Map our RAM from the start to the end of the kernel .bss section.* 将起始地址到bss段整个空间映射到物理内存上* (1)根据虚拟地址,找到页表中对应的entry* (2)然后是填充entry项,需要根据要映射的物理地址(这个物理地址是可以随便写,保证地址在真实的ddr空间即可),然后将物理地址右移20为,获取到section base addr,然后或上entry中后面的flags。base addr | flags; 此时就构成了完成的一个页表entry。最后,就是把所有的entry写到对应的内存上。*/add r0, r4, #PAGE_OFFSET >> (SECTION_SHIFT - PMD_ORDER) @r0保存了整个page table的起始地址,内核镜像的起始entryldr r6, =(_end - 1) @内核镜像末尾的虚拟地址orr r3, r8, r7 @R3 = phys_offset | MMU flags,即0x600 | flags。r7保存了flags,前面设置了。r8是物理地址起始地址,拼凑entryadd r6, r4, r6, lsr #(SECTION_SHIFT - PMD_ORDER) @end of kernek image page table. 内核镜像的结束entry/*@store命令,将页表项写到r0地址上,一开始就是第一个entry,0x8000000对应的section物理地址0x699填充到页表项中,r0=r0+4*/
1: str r3, [r0], #1 << PMD_ORDER add r3, r3, #1 << SECTION_SHIFTcmp r0, r6bls 1b
这段ARM汇编代码主要负责在系统启动阶段,将内核的虚拟地址空间映射到物理内存中,具体涉及从内核的开始地址一直到.bss段结束的整个范围。下面是对每条指令的详细中文解释:
1. add r0, r4, #PAGE_OFFSET >> (SECTION_SHIFT - PMD_ORDER)
这条指令计算出整个页表的起始地址,即将被映射的内核镜像的第一个页表项的地址。PAGE_OFFSET是一个常量,表示虚拟地址空间的偏移量,SECTION_SHIFT和PMD_ORDER是与页表层级和粒度相关的常量。通过这一计算,我们得到的是内核镜像在虚拟地址空间中的起始位置。
2. ldr r6, =(_end - 1)
加载内核镜像的最后一个地址(即_end符号所指向的地址减一)到寄存器r6中。这代表内核镜像在虚拟地址空间中的结束位置。
3. orr r3, r8, r7
使用逻辑或运算符将物理地址(存储在r8中)与MMU标志位(存储在r7中)合并,并将结果存入r3。这里的r8包含了要映射的物理地址起始点,而r7则包含了一组标志位,这些标志位控制着对物理内存的访问权限。
4. add r6, r4, r6, lsr #(SECTION_SHIFT - PMD_ORDER)
计算内核镜像在页表中的结束位置。通过将r6(内核镜像的虚拟地址结束位置)向右移位(lsr),并加上r4(页目录的基地址),得到内核镜像在页表中的最后一个条目的地址。
5. str r3, [r0], #1 << PMD_ORDER
这是一条循环内的指令,用于将r3中的值(即包含物理地址和标志位的页表项)存储到由r0指向的地址处。#1 << PMD_ORDER是一个偏移量,用于在每次迭代后更新r0,使其指向下一个页表项的位置。这是在初始化页表时实际写入页表项的过程。
6. add r3, r3, #1 << SECTION_SHIFT
增加r3中的物理地址值,准备下一次循环时使用。#1 << SECTION_SHIFT表示增加的大小,通常对应于一个section的大小,确保每次循环都能正确地映射到下一个section的物理地址。
7. cmp r0, r6
比较r0(当前处理的页表项地址)和r6(页表的结束地址)。这是为了检查是否已经到达了页表的末尾。
8. bls 1b
如果r0小于等于r6(即还没有达到页表的末尾),则跳转回标号1b继续执行循环。否则,循环结束,页表初始化完成。
总体而言,这段代码的主要功能是设置页表,以确保内核的虚拟地址可以正确地映射到物理内存中,从而支持后续的操作系统运行。
(6)对等映射,要保证开启MMU前后能平滑过渡
如何实现虚拟地址和物理地址相同?比如上面说到的,dram的物理起始是0x60000000,而内核虚拟地址是从0x80000000,此时内核镜像区所在的位置大概是0x80008000 - bss_end的区间,如果想要映射到相等的物理地址,只需要在section table中的物理页帧改成0x800即可。(因为整个页表的填充都是用户自己构建的,理论上想映射到哪里都行)。如果dram的地址是在0x60000000 - 0x70000000,此时应该如何处理呢?
这段代码的目的是创建一个对等映射(identity mapping),以便在启用MMU之前能够访问特定的内存区域。
对等映射是指虚拟地址和物理地址相同的映射关系,这对于某些关键代码段(例如用于启用MMU的代码)
来说非常重要,因为它确保这些代码段即使在MMU尚未完全初始化的情况下也能正确执行。/** Create identity mapping to cater for __enable_mmu.* This identity mapping will be removed by paging_init().*/adr r0, __turn_mmu_on_locldmia r0, {r3, r5, r6}sub r0, r0, r3 @ virt->phys offsetadd r5, r5, r0 @ phys __turn_mmu_onadd r6, r6, r0 @ phys __turn_mmu_on_endmov r5, r5, lsr #SECTION_SHIFTmov r6, r6, lsr #SECTION_SHIFT这篇关于内存管理篇-17解开页表的神秘面纱-下的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






