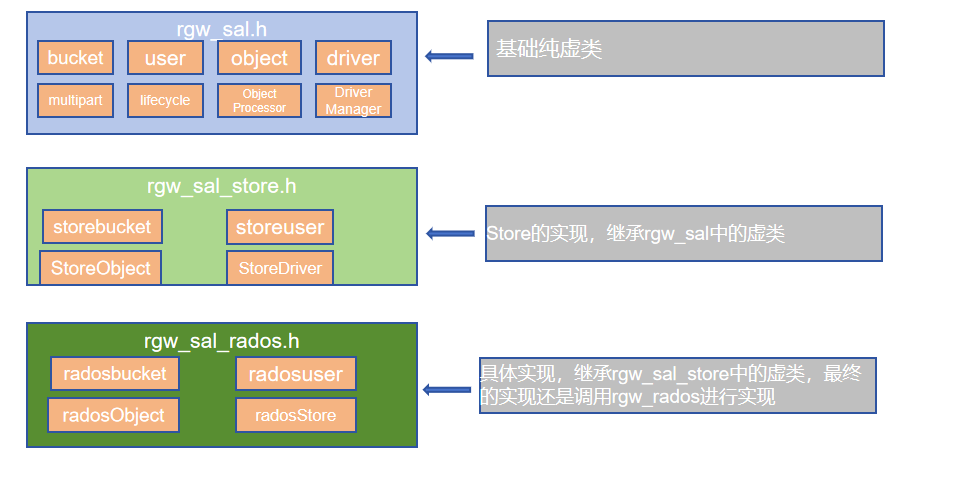
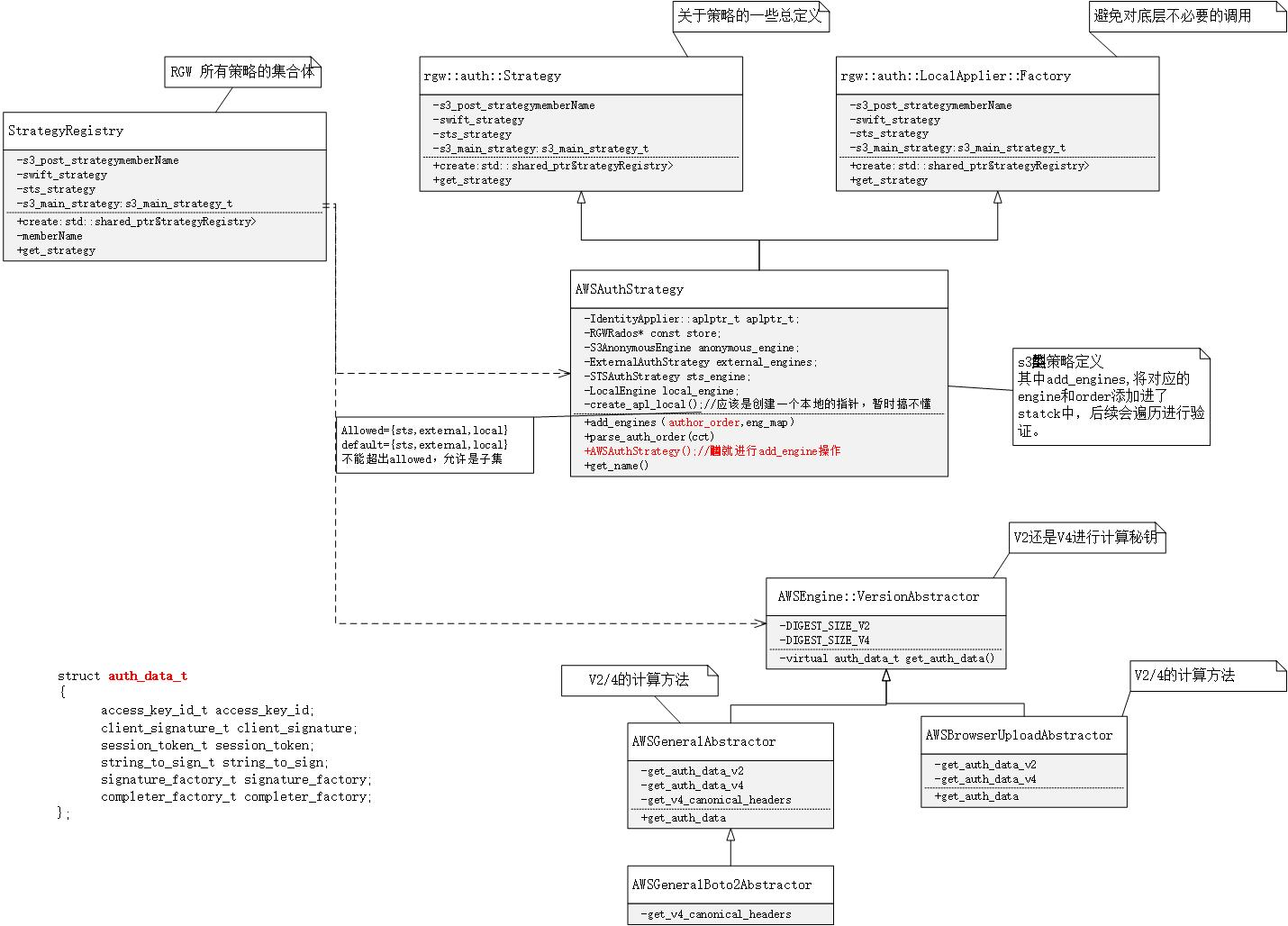
本文主要是介绍ceph rgw reshard (by quqi99),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:张华 发表于:2024-08-31
版权声明:可以任意转载,转载时请务必以超链接形式标明文章原始出处和作者信息及本版权声明(http://blog.csdn.net/quqi99)
问题
今天执班遇到一个ceph问题,一个osd device坏了,导致整个client中断。后来这个就解决了,也顺序学习了一下。
原因
bucket里的object太多了,导致它的metadata omap index太多(包含6 million+ keys, 比建议的多了60倍, objectcacher用于在客户端缓存omap - https://blog.csdn.net/quqi99/article/details/140525441), 进而造成超时,进而OSD之间无法发heartbean, 这些OSD报告失败,并且OSD反复down and up
#ceph-mon logs
2024-07-14T20:09:49.618+0000'OSD::osd_op_tp thread 0x7f7d25ec3640' had timed out after 15.000000954s
...
#slow op comes from the pool xxx.rgw.buckets.index (id=31)
2024-07-14T20:18:08.389+0000 7f7d26ec5640 0 bluestore(/var/lib/ceph/osd/ceph-131) log_latency_fn slow operation observed for _remove, latency = 373.801788330s, lat = 6m cid =31.7c_head oid =#31:3e20eb48:::.dir.255acf83-1053-45db-8646-a1f05dee5002.1125451.6.8:head#
...
2024-07-14T08:41:02.450403+0000 osd.181 (osd.181) 159371 : cluster [WRN] Large omap object found. Object: 31:ff7b6861:::.dir.255acf83-1053-45db-8646-a1f05dee5002.1125451.4.4:head PG: 31.8616deff (31.ff) Key count: 2407860 Size (bytes): 851728316
...
2024-07-14T20:53:51.562499+0000 osd.38 (osd.38) 21985 : cluster [WRN] 3 slow requests (by type [ 'delayed' : 3 ] most affected pool [ 'xxx.rgw.buckets.index' : 3 ])
这种情况应该做reshard让object在各个bucket中均匀分布,从L版支持自动reshard, 默认rgw dynamic resharding 是开启的。但是在开启了Multisite的情况下,一旦对bucket进行了reshard操作,则会破坏原有的元数据对应规则,导致对应的bucket无法进行数据同步。所以L 版在后面的一个pr 禁用了multisite 下自动的reshard1。multisite 对于omap 过大的问题,需要手动reshard,生产环境上有很大风险。(见:https://www.cnblogs.com/dengchj/p/11424644.html)。所以对此问题的处理办法是:
- 在 index pool上禁用deep-scrub - ceph osd pool set {pool-name} nodeep-scrub= 1
- 人工做reshard
- 升级ceph到reef版本,并打开multisite dynamic resharding特性今后自动做reshard
- 加硬件,对RGW metadata用nvme or ssd osds
人工做reshard的流程
1. On a node within the master zone of the master zone group, execute the following command:
# radosgw-admin bucket sync disable --bucket=BUCKET_NAME
Wait for sync status on all zones to report that data synchronization is up to date.2. Stop ALL ceph-radosgw daemons in ALL zones.3. On a node within the master zone of the master zone group, reshard the bucket.
# radosgw-admin bucket reshard --bucket=BUCKET_NAME --num-shards=NEW_SHARDS_NUMBER4. Start ceph-radosgw daemons in the master zone to restore the client services.//Important: Please do note that step 5 will delete the whole bucket on the secondary zone, make sure to confirm with the customer if they have any data that only exist in secondary zone, if so, sync them to primary zone first, otherwise there will be data loss.
5. On EACH secondary zone, execute the following:
# radosgw-admin bucket rm --purge-objects --bucket=BUCKET_NAME6. Start ceph-radosgw daemons in secondary zone.7. On a node within the master zone of the master zone group, execute the following command:
# radosgw-admin bucket sync enable --bucket=BUCKET_NAME
The metadata synchronization process will fetch the updated bucket entry point and bucket instance metadata. The data synchronization process will perform a full synchronization.
Upgrade ceph to reef
# Confirm source is set to distro
juju config ceph-mon source=distro
juju config ceph-osd source=distro
juju config ceph-radosgw source=distro
# Update monitors/managers to Reef channel
juju refresh ceph-mon --channel reef/stable
# Change to Reef installation source
juju config ceph-mon source=cloud:jammy-bobcat
# Monitors/managers will upgrade and restart one at a time.
# Set 'noout' on the cluster
juju ssh ceph-mon/leader "sudo ceph osd set noout"
# Update OSDs to Reef channel, OSD restarts are possible due to bug.
juju refresh ceph-osd --channel reef/stable
# Update OSDs to Reef
juju config ceph-osd source=cloud:jammy-bobcat
# OSDs will restart
# Unset 'noout'
juju ssh ceph-mon/leader "sudo ceph osd unset noout"
# Update RGWs, this will cause a service interruption.
juju refresh ceph-radosgw--channel reef/stable
juju config ceph-radosgw source=cloud:jammy-bobcat
# Restore and test the DNS bucket certs and configuration.
加硬件让RGW metadata用专门的nvme
0) Stop OSDs on host
systemctl stop ceph-osd.target1) Remove the caching devices from the bcache.
#!/bin/bash
# Disable the cache on each bcache
for i in $(ls -d /sys/block/sd*)
do
echo "Disabling caching on ${i}"
echo 1 > ${i}/bcache/detach
done#!/bin/bash
# Wait for cache to drain for each bcache
echo "Waiting for cache devices to drain."
for i in $(ls -d /sys/block/sd*)
do
while [ "$(cat ${i}/bcache/state)" != "no cache" ]
do
echo "Cache still dirty on ${i}."
sleep 5
done
done2) Unregister the caching devices
#!/bin/bash
# Unregister cache sets
for i in $(ls -d /sys/fs/bcache/*)
do
echo "Unregistering ${i}"
echo 1 > ${i}/unregister
done#!/bin/bash
# Double check with wipefs
for i in $(ls -d /sys/block/nvme0n1/nvme*)
do
dev=$(echo ${i} | cut -d '/' -f 5)
echo "Wiping ${dev}"
wipefs -a /dev/${dev}
done
for i in $(ls -d /sys/block/nvme1n1/nvme*)
do
dev=$(echo ${i} | cut -d '/' -f 5)
echo "Wiping ${dev}"
wipefs -a /dev/${dev}
doneecho "Wiping /dev/nvme0n1"
wipefs -a /dev/nvme0n1
echo "Wiping /dev/nvme1n1"
wipefs -a /dev/nvme1n1
echo "Ready to reformat!"3) Reformat NVMes to 4k blocks, which wipes them.
nvme format --lbaf=1 /dev/nvme0n1
nvme format --lbaf=1 /dev/nvme1n14) Leave OSDs "bcached" with no cache.
part 2 - CRUSH changes
0) Delete the ceph-benchmarking pool.
sudo ceph ceph config set mon mon_allow_pool_delete true
sudo ceph osd pool delete ceph-benchmarking --yes-i-really-really-mean-it
sudo ceph ceph config set mon mon_allow_pool_delete false1) Tweak CRUSH rules to target the HDDs to prevent NVMes from being used when added.
# EC
ceph osd erasure-code-profile set ssd-only k=5 m=3 crush-failure-domain=host crush-device-class=ssd
ceph osd crush rule create-erasure rgwdata ssd-only
ceph osd pool set default.rgw.buckets.data crush_rule rgwdata
ceph osd pool set xxx-backup.rgw.buckets.data crush_rule rgwdata
ceph osd pool set dev.rgw.buckets.data crush_rule rgwdata
ceph osd pool set velero.rgw.buckets.data crush_rule rgwdata2) Add /dev/nvme*n1 devices to Juju OSD disks.
juju run-action ceph-osd/X zap-disk osd-devices="/dev/nvme0n1"
juju run-action ceph-osd/X zap-disk osd-devices="/dev/nvme1n1"
juju run-action ceph-osd/X add-disk osd-devices="/dev/nvme0n1"
juju run-action ceph-osd/X add-disk osd-devices="/dev/nvme1n1"3) Confirm addition of NVMe OSDs as NVMe
ceph osd tree
ceph osd crush tree --show-shadow4) Alter CRUSH rules to map the metadata pools onto the NVMes.
ceph osd crush rule create-replicated replicated-nvme default host nvme# Replicated
ceph osd crush rule create-replicated replicated-nvme default host ssd
ceph osd pool set .mgr crush_rule replicated-nvme
ceph osd pool set default.rgw.control crush_rule replicated-nvme
ceph osd pool set default.rgw.data.root crush_rule replicated-nvme
ceph osd pool set default.rgw.gc crush_rule replicated-nvme
ceph osd pool set default.rgw.log crush_rule replicated-nvme
ceph osd pool set default.rgw.intent-log crush_rule replicated-nvme
ceph osd pool set default.rgw.meta crush_rule replicated-nvme
ceph osd pool set default.rgw.otp crush_rule replicated-nvme
ceph osd pool set default.rgw.usage crush_rule replicated-nvme
ceph osd pool set default.rgw.users.keys crush_rule replicated-nvme
ceph osd pool set default.rgw.users.email crush_rule replicated-nvme
ceph osd pool set default.rgw.users.swift crush_rule replicated-nvme
ceph osd pool set default.rgw.users.uid crush_rule replicated-nvme
ceph osd pool set default.rgw.buckets.extra crush_rule replicated-nvme
ceph osd pool set default.rgw.buckets.index crush_rule replicated-nvme
ceph osd pool set xxx-backup.rgw.control crush_rule replicated-nvme
ceph osd pool set xxx-backup.rgw.data.root crush_rule replicated-nvme
ceph osd pool set xxx-backup.rgw.gc crush_rule replicated-nvme
ceph osd pool set xxx-backup.rgw.log crush_rule replicated-nvme
ceph osd pool set xxx-backup.rgw.intent-log crush_rule replicated-nvme
ceph osd pool set xxx-backup.rgw.meta crush_rule replicated-nvme
ceph osd pool set xxx-backup.rgw.otp crush_rule replicated-nvme
ceph osd pool set xxx-backup.rgw.usage crush_rule replicated-nvme
ceph osd pool set xxx-backup.rgw.users.keys crush_rule replicated-nvme
ceph osd pool set xxx-backup.rgw.users.email crush_rule replicated-nvme
ceph osd pool set xxx-backup.rgw.users.swift crush_rule replicated-nvme
ceph osd pool set xxx-backup.rgw.users.uid crush_rule replicated-nvme
ceph osd pool set xxx-backup.rgw.buckets.extra crush_rule replicated-nvme
ceph osd pool set xxx-backup.rgw.buckets.index crush_rule replicated-nvme
ceph osd pool set ceph-benchmarking crush_rule replicated-nvme
ceph osd pool set .rgw.root crush_rule replicated-nvme
ceph osd pool set velero.rgw.log crush_rule replicated-nvme
ceph osd pool set velero.rgw.control crush_rule replicated-nvme
ceph osd pool set velero.rgw.meta crush_rule replicated-nvme
ceph osd pool set dev.rgw.log crush_rule replicated-nvme
ceph osd pool set dev.rgw.control crush_rule replicated-nvme
ceph osd pool set dev.rgw.meta crush_rule replicated-nvme
ceph osd pool set dev.rgw.data.root crush_rule replicated-nvme
ceph osd pool set dev.rgw.gc crush_rule replicated-nvme
ceph osd pool set dev.rgw.intent-log crush_rule replicated-nvme
ceph osd pool set dev.rgw.otp crush_rule replicated-nvme
ceph osd pool set dev.rgw.usage crush_rule replicated-nvme
ceph osd pool set dev.rgw.users.keys crush_rule replicated-nvme
ceph osd pool set dev.rgw.users.email crush_rule replicated-nvme
ceph osd pool set dev.rgw.users.swift crush_rule replicated-nvme
ceph osd pool set dev.rgw.users.uid crush_rule replicated-nvme
ceph osd pool set dev.rgw.buckets.extra crush_rule replicated-nvme
ceph osd pool set dev.rgw.buckets.index crush_rule replicated-nvme
ceph osd pool set velero.rgw.data.root crush_rule replicated-nvme
ceph osd pool set velero.rgw.gc crush_rule replicated-nvme
ceph osd pool set velero.rgw.intent-log crush_rule replicated-nvme
ceph osd pool set velero.rgw.otp crush_rule replicated-nvme
ceph osd pool set velero.rgw.usage crush_rule replicated-nvme
ceph osd pool set velero.rgw.users.keys crush_rule replicated-nvme
ceph osd pool set velero.rgw.users.email crush_rule replicated-nvme
ceph osd pool set velero.rgw.users.swift crush_rule replicated-nvme
ceph osd pool set velero.rgw.users.uid crush_rule replicated-nvme
ceph osd pool set velero.rgw.buckets.extra crush_rule replicated-nvme
ceph osd pool set velero.rgw.buckets.index crush_rule replicated-nvme
enable multisite resharding
radosgw-admin zonegroup modify --rgw-zonegroup=xxx --enable-feature=resharding
radosgw-admin period update --commit
radosgw-admin zone modify --rgw-zone=xxx --enable-feature=resharding
radosgw-admin period update --commit
radosgw-admin zone modify --rgw-zone=xxx-backup --enable-feature=resharding
radosgw-admin period update --commit
这篇关于ceph rgw reshard (by quqi99)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!