本文主要是介绍Linux系统使用Docker compose搭建开源文档系统Paperless-ngx,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 1. 部署Paperless-ngx
- 2. 本地访问Paperless-ngx
- 3. Linux安装Cpolar
- 4. 配置公网地址
- 5. 远程访问
- 6. 固定Cpolar公网地址
- 7. 固定地址访问
前言
本文主要介绍如何在Linux系统本地部署Paperless-ngx开源文档管理系统,并结合cpolar内网穿透工具解决本地部署后因为没有公网IP受到局域网访问限制,在异地也能随时远程访问的困扰。
Paperless-ngx是一个开源的文档管理系统,可以将物理文档转换成可搜索的在线档案,从而减少纸张的使用。它内置了OCR功能,可以自动对上传的扫描文档执行OCR,识别文档中的文字,并将其转换为可编辑和可搜索的文本格式。然后,系统会对文档进行分类和索引,以便用户可以随时搜索查阅。
cpolar是一款强大的内网穿透软件,它能够在多个操作系统上无缝运行,包括Windows、MacOS和Linux,因此无论您使用哪种操作系统,都可以轻松将本地内网服务器的HTTP、HTTPS、TCP协议端口映射为公网地址端口,使得公网用户可以轻松访问您的内网服务,无需部署至公网服务器.
本例采用Docker部署,首先设备需要提前安装好Docker 和Docker compose,如没有安装,可以参考下方教程进行安装:
在终端中执行下方命令安装docker:
sudo curl -fsSL https://github.com/tech-shrimp/docker_installer/releases/download/latest/linux.sh| bash -s docker --mirror Aliyun
如果上边命令中访问不了Github,可以使用Gitee的链接安装:
sudo curl -fsSL https://gitee.com/tech-shrimp/docker_installer/releases/download/latest/linux.sh| bash -s docker --mirror Aliyun
然后启动Docker
sudo systemctl start docker
下载docker-compose文件
sudo curl -L "https://github.com/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
给他一个执行权限
sudo chmod +x /usr/local/bin/docker-compose
Paperless-ngx 部署需要用到非常多外部服务,如数据库等,采用docker compose方式,可以一次性把所有的服务全部部署好,简化安装过程,下面开始进行安装。
1. 部署Paperless-ngx
在Linux 中创建一个文件夹,创建后进入该文件夹
mkdir -p /usr/local/ngx && cd /usr/local/ngx
在该文件夹下创建docker-compose.yml 文件
sudo vim /usr/local/ngx/docker-compose.yml
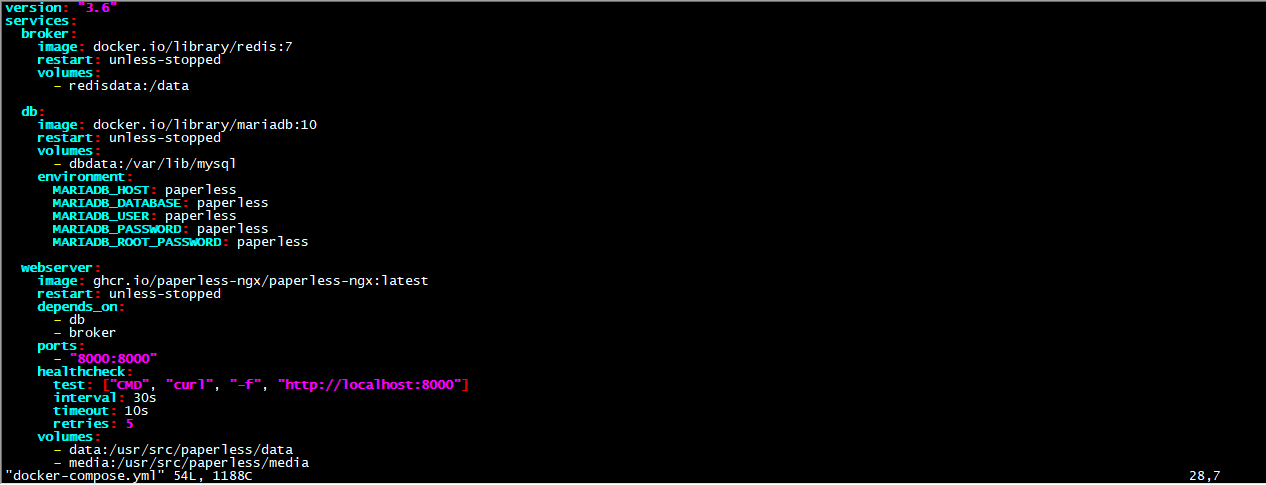
把下面参数复制进去docker-compose.yml 文件里面,
version: "3.6"
services:broker:image: docker.io/library/redis:7restart: unless-stoppedvolumes:- redisdata:/datadb:image: docker.io/library/mariadb:10restart: unless-stoppedvolumes:- dbdata:/var/lib/mysqlenvironment:MARIADB_HOST: paperlessMARIADB_DATABASE: paperlessMARIADB_USER: paperlessMARIADB_PASSWORD: paperlessMARIADB_ROOT_PASSWORD: paperlesswebserver:image: ghcr.io/paperless-ngx/paperless-ngx:latestrestart: unless-stoppeddepends_on:- db- brokerports:- "8000:8000"healthcheck:test: ["CMD", "curl", "-f", "http://localhost:8000"]interval: 30stimeout: 10sretries: 5volumes:- data:/usr/src/paperless/data- media:/usr/src/paperless/media- ./export:/usr/src/paperless/export- ./consume:/usr/src/paperless/consumeenvironment:PAPERLESS_REDIS: redis://broker:6379PAPERLESS_DBENGINE: mariadbPAPERLESS_DBHOST: dbPAPERLESS_DBUSER: paperless PAPERLESS_DBPASS: paperless PAPERLESS_DBPORT: 3306volumes:data:media:dbdata:redisdata:复制进去后记得保存
然后运行下面命令进行启动,执行后等待运行完成,如果卡顿或者卡主不动,可以ctrl+c 退出 重新执行下面命令
docker compose up -d
运行后,输入docker ps 命令,即可看到我们运行的Paperless-ngx服务,对外访问端口为8000

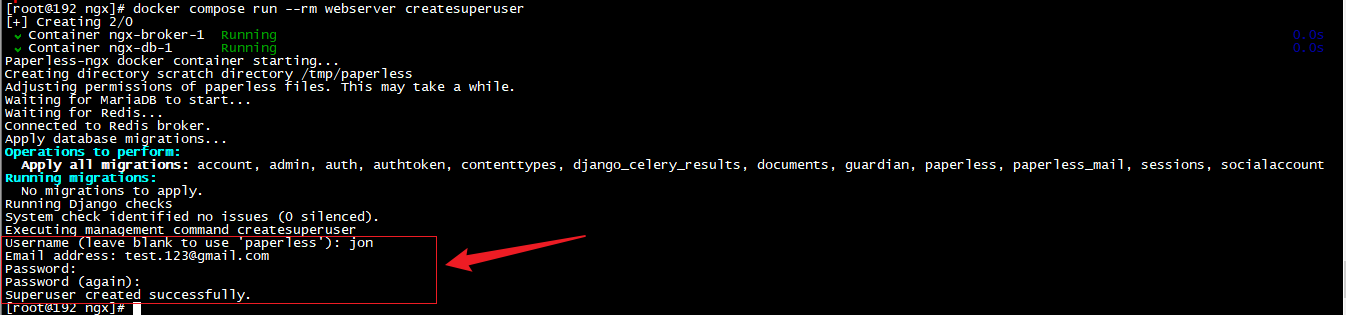
下面我们进行设置登录的用户名和密码,运行下面命令
docker compose run --rm webserver createsuperuser
然后按提示设置用户名,邮箱,密码,本例设置的用户名为jon,具体可以自己设置,然后按提示输入邮箱,和设置用户名对应的密码,设置后回车提示successful表示成功,下面我们进行访问
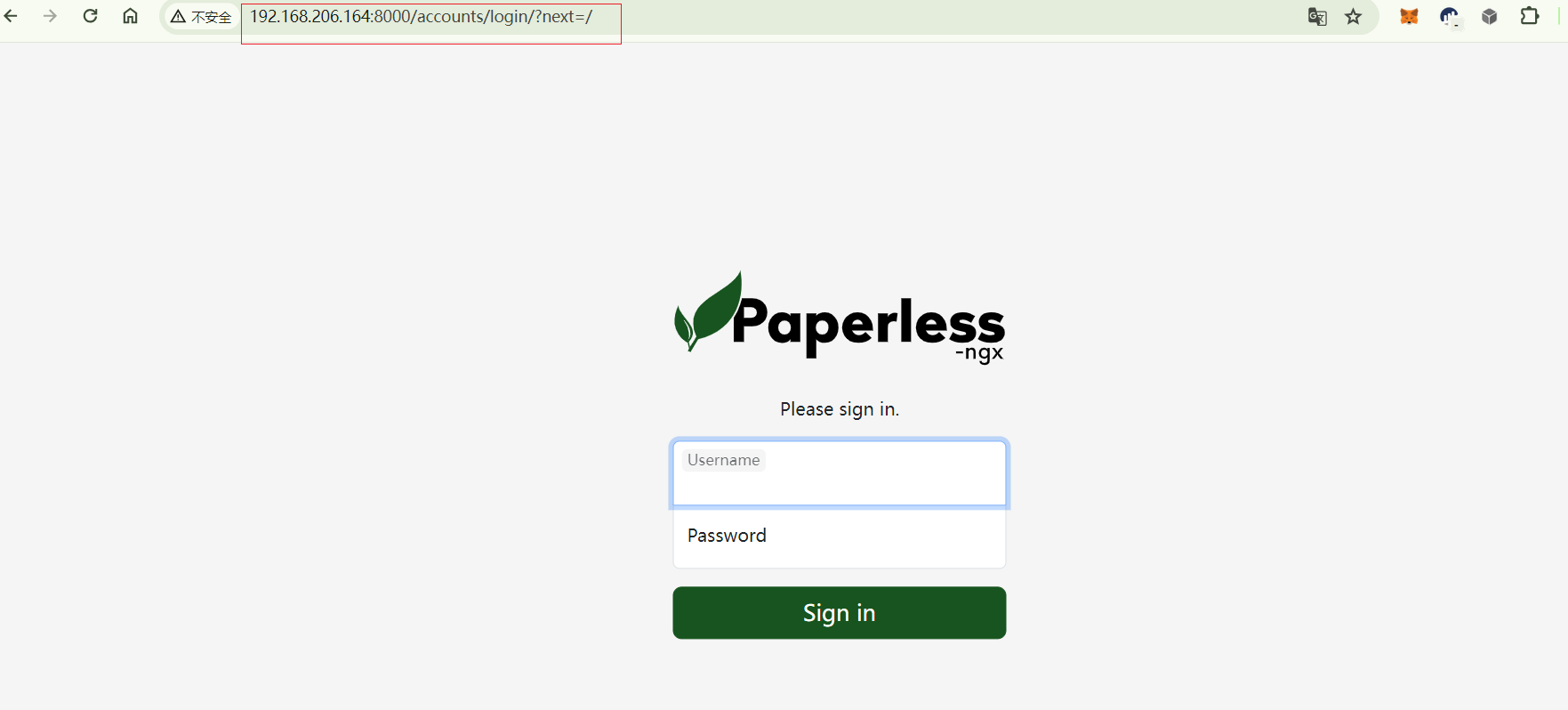
2. 本地访问Paperless-ngx
上面运行服务且设置好登录用户名密码后,我们使用Linux局域网IP加端口8000,即可看到Paperless-ngx登录界面
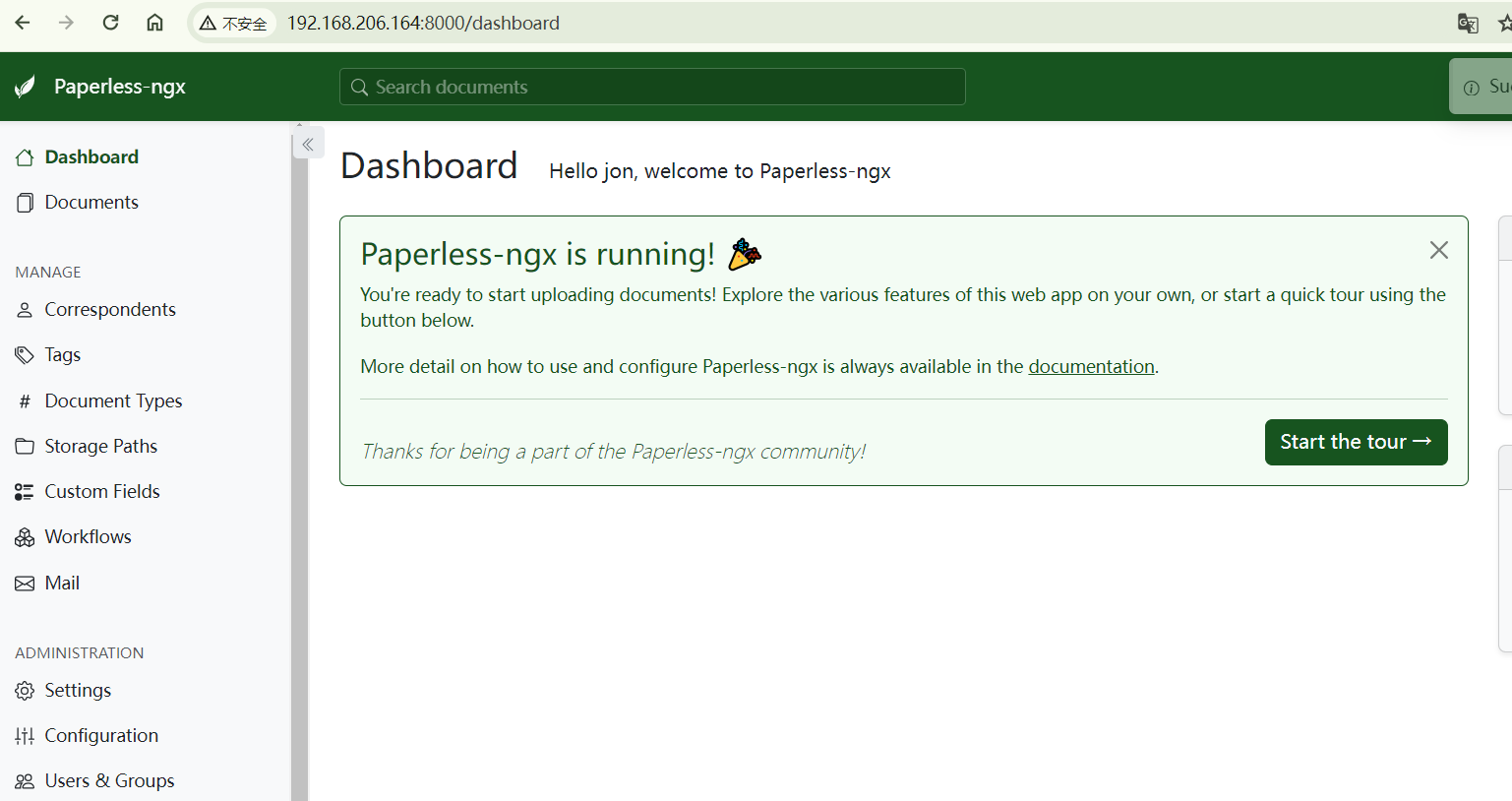
输入我们上面设置的用户名密码即可登录成功,本地访问成功了,下面我们安装cpolar内网穿透工具,实现远程也可以访问!
3. Linux安装Cpolar
上面在本地Docker中成功部署了Paperless-ngx服务,并局域网访问成功,下面我们在Linux安装Cpolar内网穿透工具,通过Cpolar 转发本地端口映射的http公网地址,我们可以很容易实现远程访问,而无需自己注册域名购买云服务器.下面是安装cpolar步骤
cpolar官网地址: https://www.cpolar.com
- 使用一键脚本安装命令
curl -L https://www.cpolar.com/static/downloads/install-release-cpolar.sh | sudo bash
- 安装完成后,可以通过如下方式来操作cpolar服务,首先执行加入系统服务设置开机启动,然后再启动服务
# 加入系统服务设置开机启动
sudo systemctl enable cpolar# 启动cpolar服务
sudo systemctl start cpolar# 重启cpolar服务
sudo systemctl restart cpolar# 查看cpolar服务状态
sudo systemctl status cpolar# 停止cpolar服务
sudo systemctl stop cpolarCpolar安装和成功启动服务后,内部或外部浏览器上通过局域网IP加9200端口即:【http://192.168.xxx.xxx:9200】访问Cpolar管理界面,使用Cpolar官网注册的账号登录,登录后即可看到cpolar web 配置界面,接下来在web 界面配置即可
4. 配置公网地址
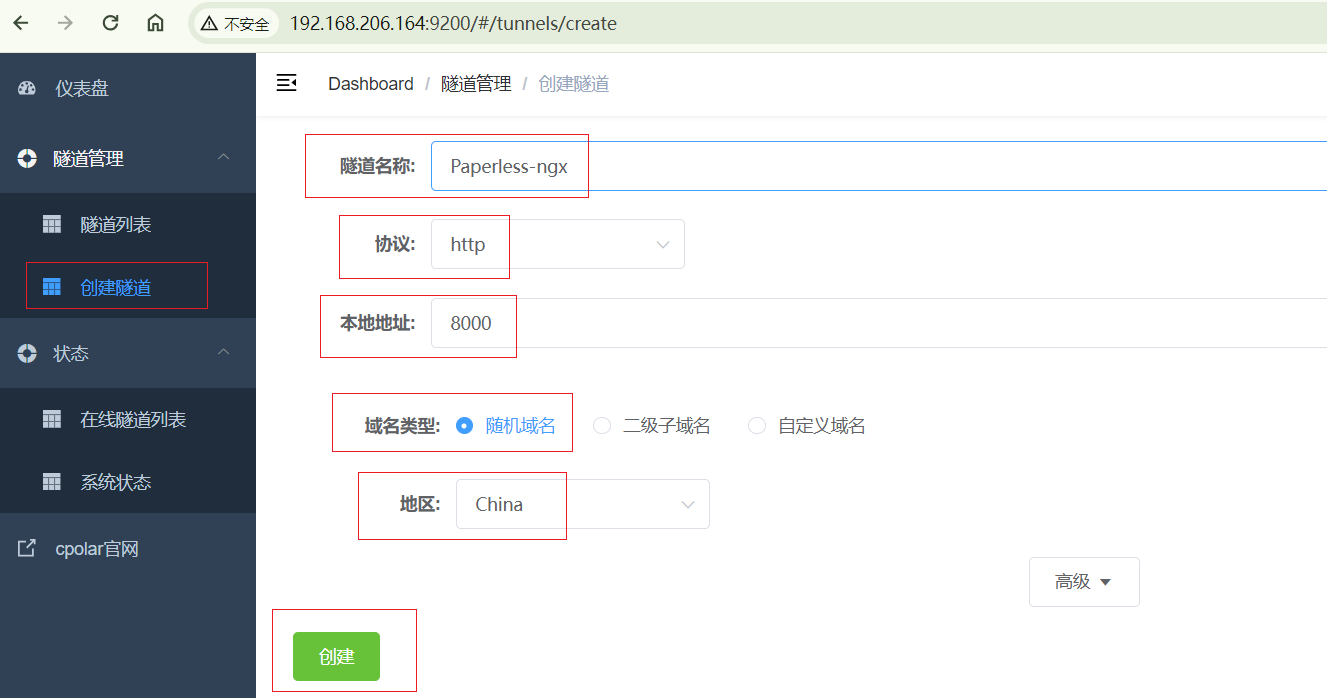
点击左侧仪表盘的隧道管理——创建隧道,创建一个paperless-ngx的公网http地址隧道!
- 隧道名称:可自定义命名,注意不要与已有的隧道名称重复
- 协议:选择http
- 本地地址:8000(本地访问的地址)
- 域名类型:免费选择随机域名
- 地区:选择China
点击创建
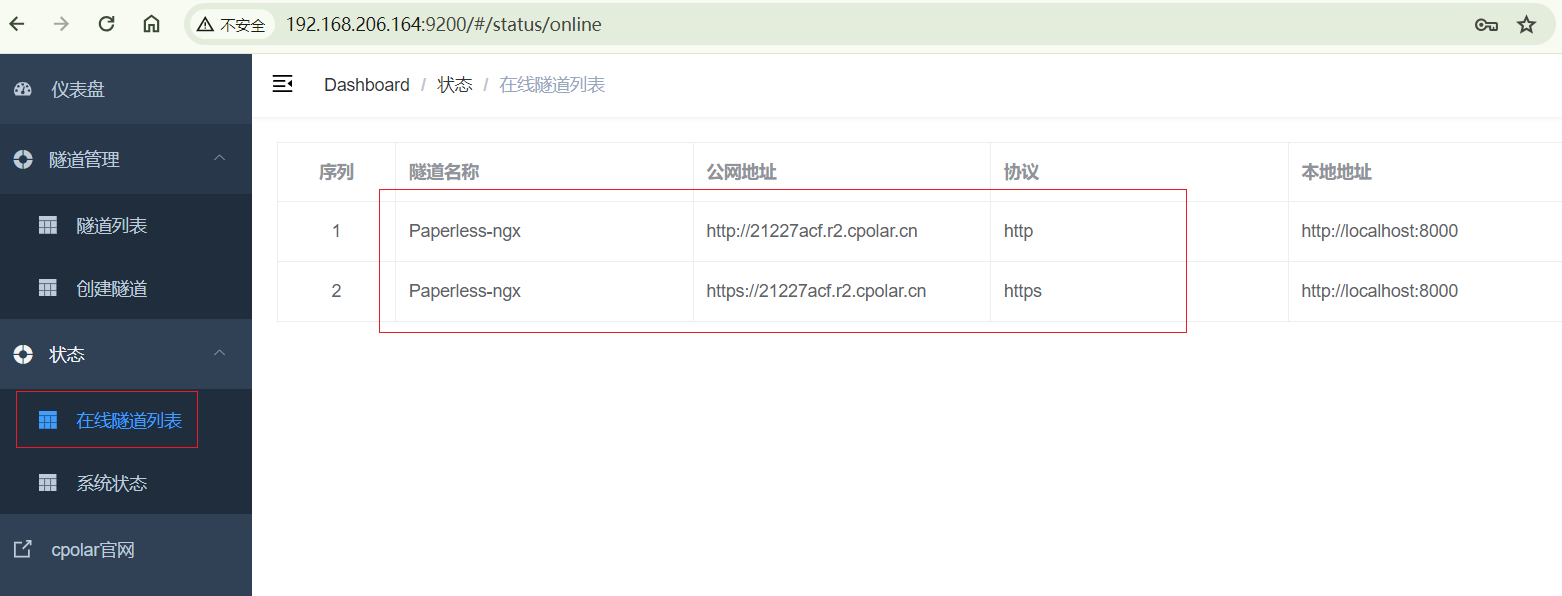
隧道创建成功后,点击左侧的状态——在线隧道列表,查看所生成的公网访问地址,有两种访问方式,一种是http 和https,下面进行远程访问
5. 远程访问
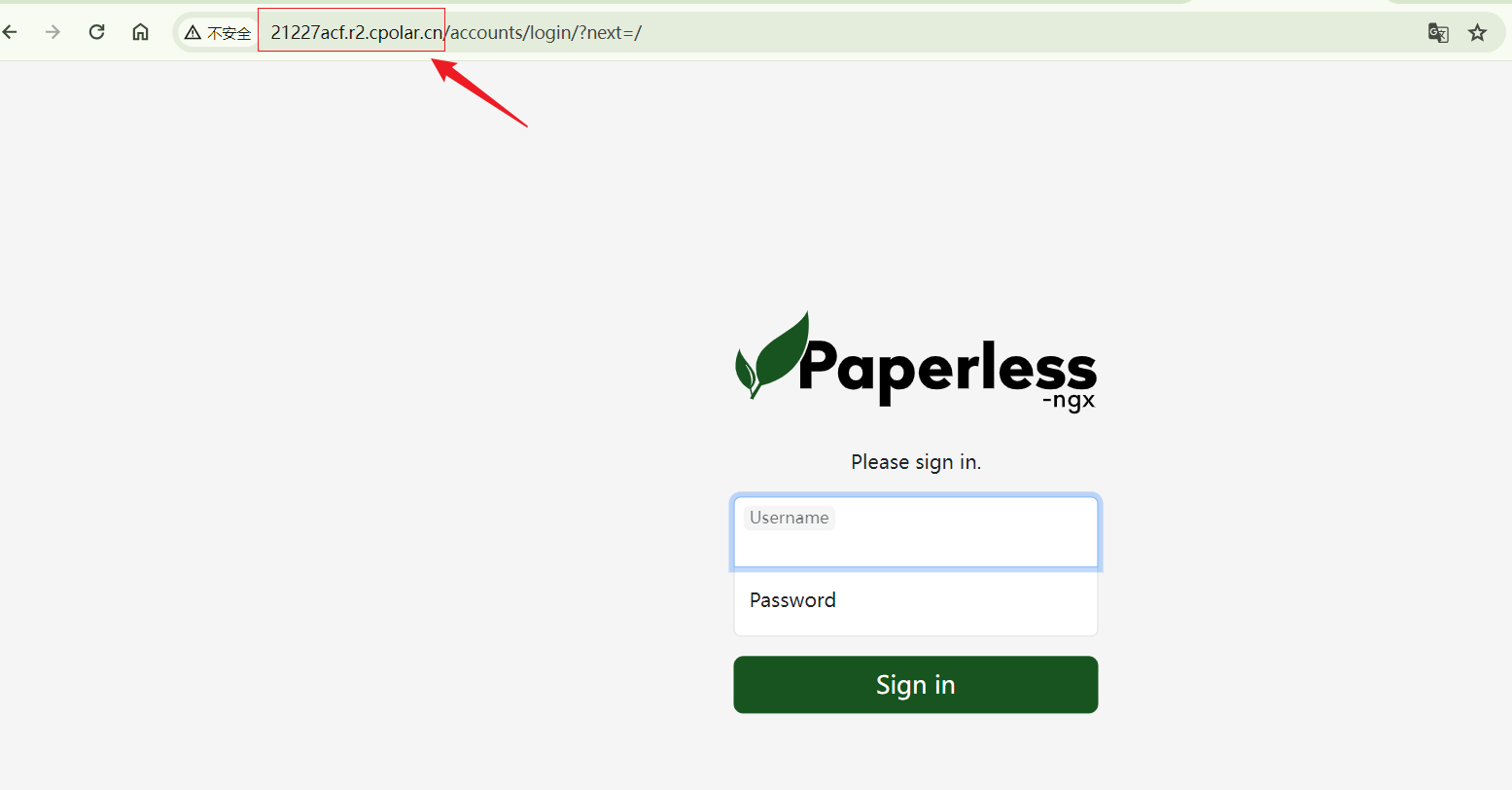
使用上面Cpolar生成的 http公网地址,在任意设备的浏览器进行访问,即可成功看到我们Paperless-ngx的界面,无需云服务器,无需公网IP即可实现远程访问!
小结
为了更好地演示,我们在前述过程中使用了cpolar生成的隧道,其公网地址是随机生成的。
这种随机地址的优势在于建立速度快,可以立即使用。然而,它的缺点是网址由随机字符生成,不太容易记忆(例如:3ad5da5.r10.cpolar.top)。另外,这个地址在24小时内会发生随机变化,更适合于临时使用。
我一般会使用固定二级子域名,原因是我希望将网址发送给同事或客户时,它是一个固定、易记的公网地址(例如:paperless-ngx.cpolar.cn),这样更显正式,便于流交协作。
6. 固定Cpolar公网地址
由于以上使用cpolar所创建的隧道使用的是随机公网地址,24小时内会随机变化,不利于长期远程访问。因此我们可以为其配置二级子域名,该地址为固定地址,不会随机变化【ps:cpolar.cn已备案】
注意需要将cpolar套餐升级至基础套餐或以上,且每个套餐对应的带宽不一样。【cpolar.cn已备案】
登录cpolar官网,点击左侧的预留,选择保留二级子域名,设置一个二级子域名名称,点击保留,保留成功后复制保留的二级子域名名称
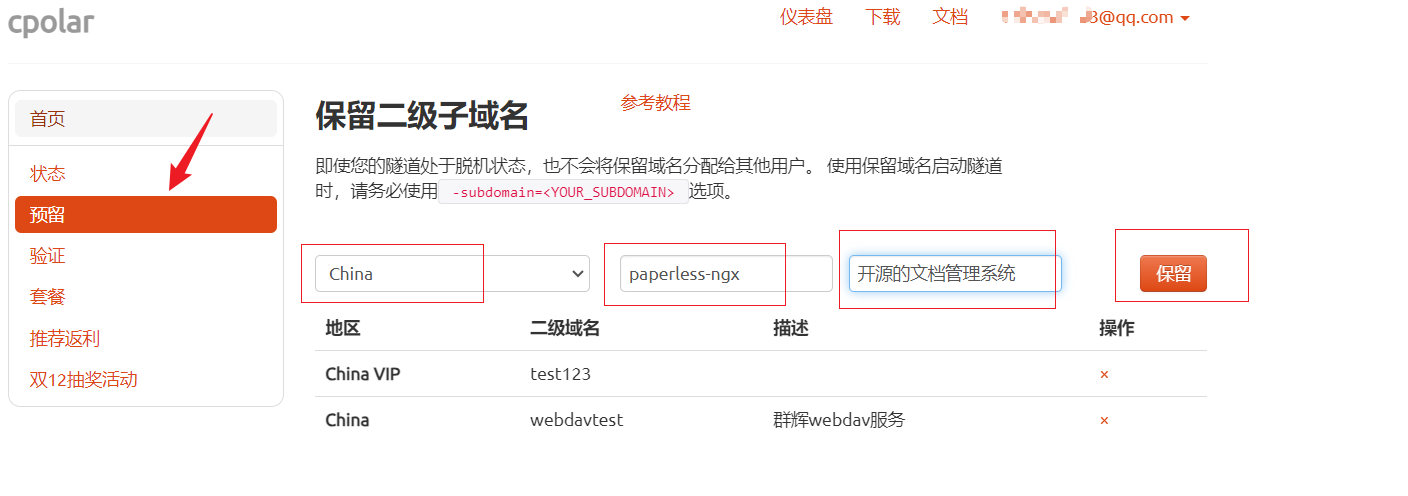
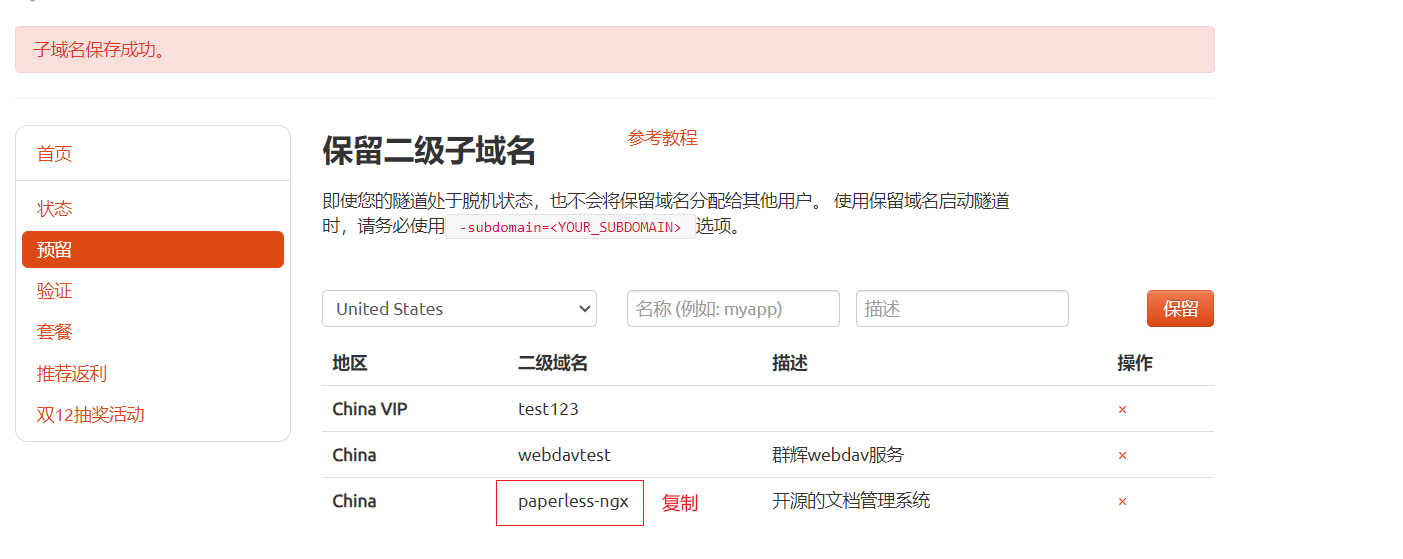
保留成功后复制保留成功的二级子域名的名称
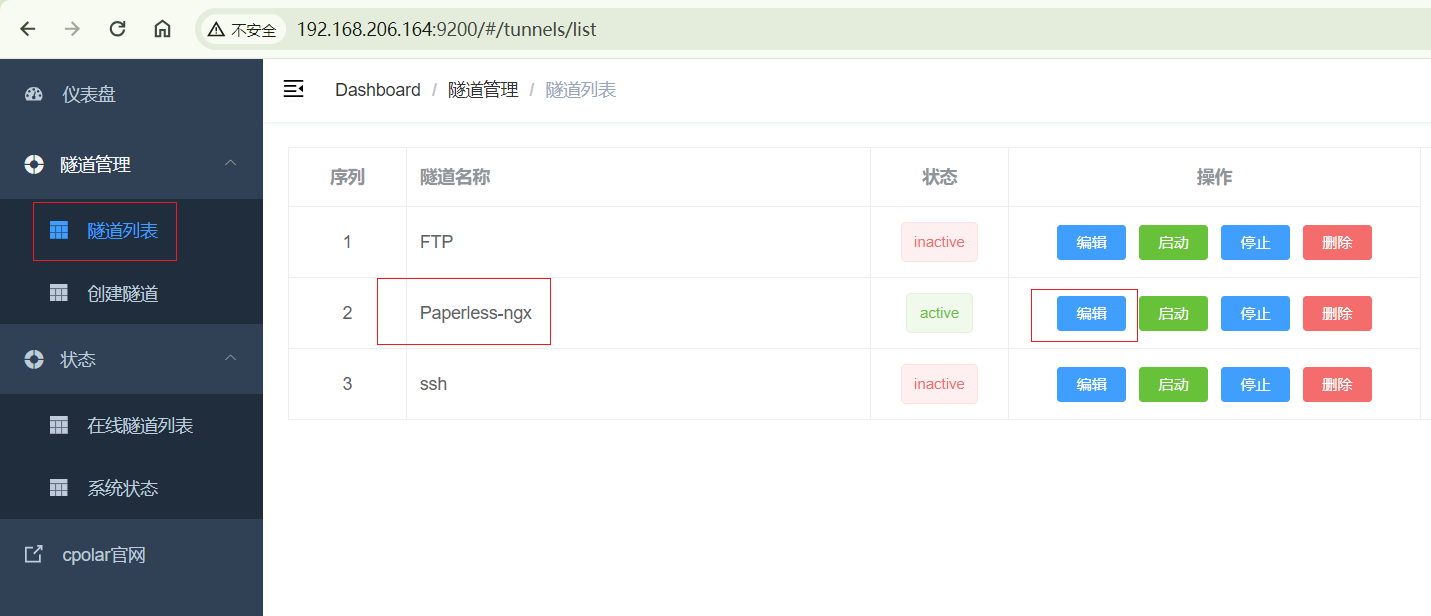
返回登录cpolar web UI管理界面,点击左侧仪表盘的隧道管理——隧道列表,找到所要配置的隧道,点击右侧的编辑
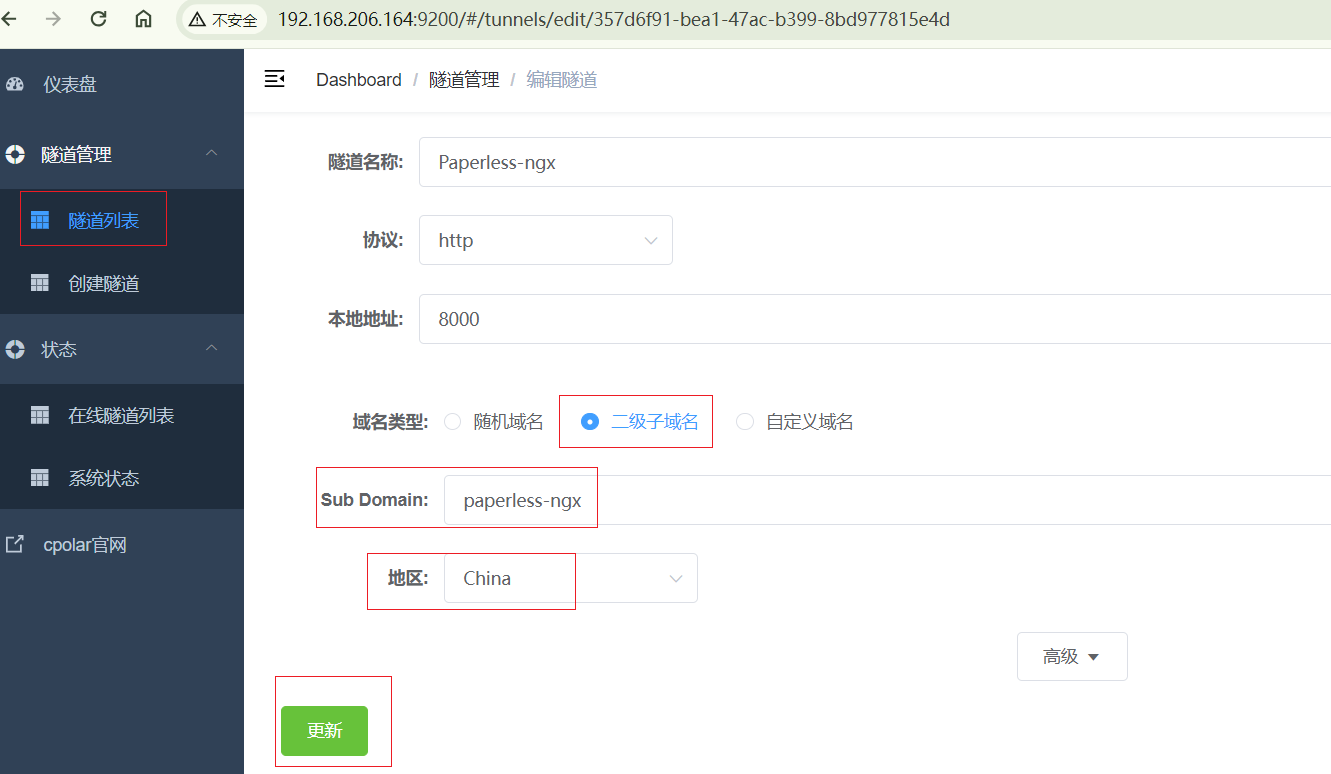
修改隧道信息,将保留成功的二级子域名配置到隧道中
- 域名类型:选择二级子域名
- Sub Domain:填写保留成功的二级子域名
点击更新(注意,点击一次更新即可,不需要重复提交)
更新完成后,打开在线隧道列表,此时可以看到公网地址已经发生变化,地址二级名称变成了我们自己设置的二级子域名名称
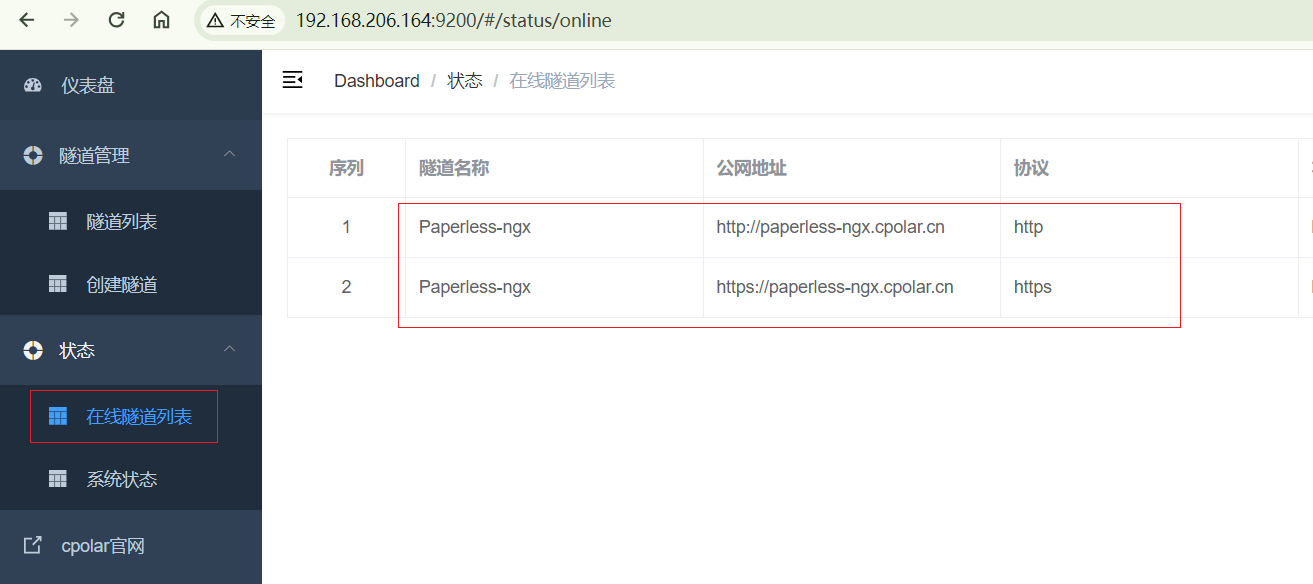
7. 固定地址访问
最后,我们使用固定的公网http地址访问,可以看到同样访问成功,这样一个固定且永久不变的公网地址就设置好了,随时随地都可以远程访问本地paperless-ngx服务,无需公网IP,无需云服务器!

这篇关于Linux系统使用Docker compose搭建开源文档系统Paperless-ngx的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





