本文主要是介绍黑马程序员——Java语言--集合框架,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
String类
String类是开发中非常最常用甚至不可缺少的好东西,用它可以做很多有趣的事情。
特点
- 字符串是一个特殊的对象
- 字符串一旦初始化就不可以被改变
小问题
String str = "abc";
String str1 = new String("abc");
这两个字符串的创建有何区别?
结合代码来解释:
class StringDemo
{public static void main(String[] args) {stringDemo1();stringDemo2();}public static void stringDemo1(){/** String类的特点:* 字符串对象一旦被初始化就不会被改变。*/// abc是一个对象,存储在字符串常量池中,abc这个本身不能被改变String s1 = "abc"; String s2 = "abc";System.out.println(s1==s2); // true/** 为什么输出的是 true呢?因为 首先==比较的是地址值* "abc" 存储在字符串常量池中,当要赋值给s2时,要去字符串常量池中查找是否有"abc"* 若有,则把"abc"的地址值赋给s2,其实字符串常量池是共享数据的,所以true*/}public static void stringDemo2(){String s1 = "abc"; // 创建了一个对象"abc",在字符串常量池中String s2 = new String("abc"); // 创建两个对象("abc",new String("abc")),在堆内存中System.out.println(s1==s2); // false// 地址不同,所以就是falseSystem.out.println(s1.equals(s2)); // true// String的equals方法覆盖了Object的equals方法,用于判断字符串对象是否相同的依据// 其实就是比较字符串的内容。}}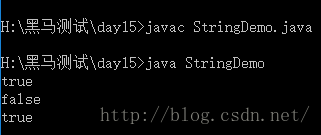
构造函数
class StringConstructorDemo
{public static void main(String[] args) {stringConstructorDemo_1();stringConstructorDemo_2();}public static void stringConstructorDemo_1(){// String s = new String(); // 等效于 String s = "";// 将字节数组通过String构造函数进行转换成字符串byte[] arr = {65, 78, 79, 83, 90};String s1 = new String(arr);System.out.println("s1="+s1); // s1=ANOSZ// why?首先byte编程字符串的话,byte元素要变成字符,因为字符是字符串的单元(字符组成字符串)}public static void stringConstructorDemo_2(){char[] chs = {'a','b','f','j','h','x','l'};//将字符数组通过String构造函数进行转换成字符串String s = new String(chs);System.out.println("s="+s); // abfjhxl// 还可以指定获取char数组中的某一部分转换成字符串// 从chs数组的角标为3开始取,往后取4个String s1 = new String(chs,3,4); // jhxlSystem.out.println("s1="+s1);}}
常用方法
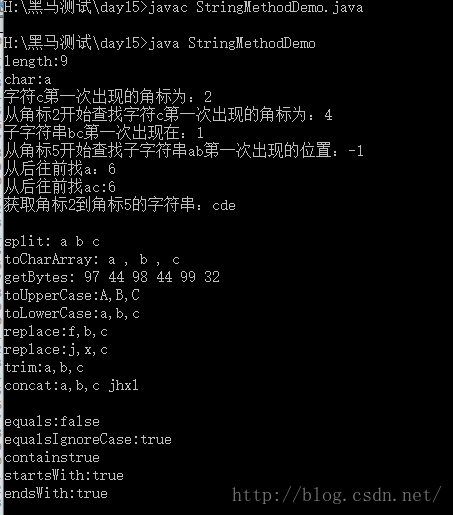
class StringMethodDemo
{public static void main(String[] args) {stringMethodDemo_1();System.out.println();stringMethodDemo_2();System.out.println();stringMethodDemo_3();}public static void stringMethodDemo_1(){/** 1.获取* 1.1 获取字符串中的字符的个数(长度)* int length()* 1.2 获取字符串中指定位置的字符* char charAt(int index)* 1.3 获取字符串中指定字符第一次出现的位置* int indexOf(int ch)* int indexOf(int ch, int fromIndex) // 指定从哪个位置开始查找* 1.4 获取字符串中指定的子字符串第一次出现的位置* int indexOf(String str)* int indexOf(String str, int fromIndex) // 指定从哪个位置开始查找* 1.5 获取字符串中指定的字符或者子字符串最后一次出现的位置* int lastIndexOf(int ch)* int lastIndexOf(int ch, int fromIndex)* int lastIndexOf(String str)* int lastIndexOf(String str, int fromIndex)* 1.6 获取字符串中一部分字符串,也叫子串。* String subString(int beginIndex) // 从beginIndex到最后都是* String substring(int beginIndex, int endIndex) // 包含beginIndex,不包含endIndex*/String s = "abcdefacg";System.out.println("length:" + s.length()); // 字符串长度System.out.println("char:" + s.charAt(0)); // 获取字符串角标为0的字符System.out.println("字符c第一次出现的角标为:" + s.indexOf('c'));System.out.println("从角标2开始查找字符c第一次出现的角标为:" + s.indexOf('e',2));System.out.println("子字符串bc第一次出现在:" + s.indexOf("bc"));System.out.println("从角标5开始查找子字符串ab第一次出现的位置:" + s.indexOf("ab",5));System.out.println("从后往前找a:" + s.lastIndexOf('a'));System.out.println("从后往前找ac:" + s.lastIndexOf("ac"));System.out.println("获取角标2到角标5的字符串:" + s.substring(2,5));}public static void stringMethodDemo_2(){/** 2.转换* 2.1 将字符串转换成字符串数组(字符串的切割,大菜刀)* String[] split(String regex):设计到正则表达式* 2.2 将字符串转换成字符数组(大锤子)* char[] toCharArray();* 2.3 将字符串转换成字节数组* byte[] getBytes[];* 2.4 将字符串的字母转成大小写* String toUpperCase(); 大写* String toLowerCase(); 小写* 2.5 将字符串中的内容进行替换* String replace(char oldch, char newch);* String replace(String oldstr, String newstr);* 2.6 将字符串两端的空格去除* String trim();* 2.7 将字符串进行连接* String concat(String str)*/// 演示一下String s = "a,b,c ";String[] splitResult = s.split(",");System.out.print("split: ");for(int x=0; x<splitResult.length; x++)System.out.print(splitResult[x]+" ");System.out.println();char[] chs = s.toCharArray();System.out.print("toCharArray: ");for(int x=0; x<chs.length; x++)System.out.print(chs[x]+" ");System.out.println();byte[] arr = s.getBytes();System.out.print("getBytes: ");for(int x=0; x<arr.length; x++)System.out.print(arr[x]+" ");System.out.println();System.out.println("toUpperCase:"+s.toUpperCase());System.out.println("toLowerCase:"+s.toLowerCase());System.out.println("replace:" + s.replace('a','f'));System.out.println("replace:" + s.replace("a,b","j,x"));System.out.println("trim:" + s.trim());System.out.println("concat:"+ s.concat("jhxl"));}public static void stringMethodDemo_3(){/** 3.判断* 3.1 判断两个字符串的内容是否相同。* boolean equals(Object obj);* boolean equalsIgnoreCase(String str); // 忽略大小写比较字符串内容* 3.2 判断一个字符串是否包含指定的字符串* boolean contains(String str)* 3.3 判断字符串是否以指定字符串开头,或者是以指定字符串为结尾。* boolean startsWith(String str)* boolean endsWith(String str)*/String s = "abC";System.out.println("equals:"+s.equals("abc"));System.out.println("equalsIgnoreCase:"+s.equalsIgnoreCase("ABC"));System.out.println("contains"+s.contains("ab"));System.out.println("startsWith:"+s.startsWith("ab"));System.out.println("endsWith:"+s.endsWith("bC"));}
}
字符串的练习
字符串数组的排序代码演示
/** 需求:字符串数组 进行排序* 思路:可以使用冒泡排序,但是以往排的都是数据类型的,用的运算符是比较运算符,* 现在要比较的是字符串,那么需要使用compareTo来进行字符串之间的大小比较。*/class StringSortDemo
{public static void main(String[] args) {String[] arr = {"angle","abc","zero","two","one","haha","okok","a","xl","h"};printArray(arr); // 排序前sortArray(arr); // 排序printArray(arr); // 排序后}// 排序public static void sortArray(String[] arr){for(int i=0;i<arr.length-1; i++){for(int j=i+1; j<arr.length; j++){if(arr[i].compareTo(arr[j]) > 0){swap(arr,i,j);}}}}// 交换位置public static void swap(String[] arr, int i, int j){String temp = arr[i];arr[i] = arr[j];arr[j] = temp;}// 打印public static void printArray(String[] arr){for(int x=0; x<arr.length-1; x++)System.out.print(arr[x]+",");System.out.println(arr[arr.length-1]);}
}
子串在整串中的出现次数
/** 需求,求一个子串在整串中出现的次数。* 思路:比如 abcdefabcfffabcabcxlxlh 当中出现abc多少次* 步骤:1、首先使用indexOf查找出第一个abc的位置,累计+1* 2、从第一个abc出现位置加上abc长度的位置开始往后使用indexOf查找abc,相当defabcfffabcabcxlxlh里边找abc* 3、不断重复上面的两个步骤,直到找不到,返回-1为止,即可。*/class SubStringCountDemo
{public static void main(String[] args) {String str = "abcdefabcfffabcabcxlxlh";String key = "abc";System.out.println(getSubStringCounts_2(str, key));}// 这方法并不是特别好,因为会产生很多个字符串对象,有点浪费内存public static int getSubStringCounts_1(String str, String key){int count = 0; // 累计子串次数int index = 0; // 每一次通过indexOf查找返回的结果值// 当返回的不是-1,就说明找到了,还可以继续往后尝试while((index=str.indexOf(key))!=-1){str = str.substring(index+key.length());count++;}return count;}public static int getSubStringCounts_2(String str, String key){int count = 0;int index = 0;// 指定从index位置往后查找while((index=str.indexOf(key,index))!=-1){index = index + key.length();count++;}return count;}
}
两个字符串中最长的相同的子串
/*** 需求:求出两个字符串中最长的相同的子串。* 思路:* 1、首先取较短的字符串,判断该字符串是不是较长字符串的子串,若是,则最长。* 2、若不是,那么对较短的字符串进行长度逐一递减的截取,再判断是不是较长的字符串的子串。* 3、不断循环以上两个步骤,直到找到为止,跳出。*/class BiggestSubStringDemo
{public static void main(String[] args) {String str = "aabcdefffah";String key = "abcd";System.out.println(getBiggestSubString(str,key));System.out.println(getMaxSubString(str,key));}// 方法一public static String getBiggestSubString(String strone,String strtwo){int maxlen = strtwo.length(); // 原本的长度int len = strtwo.length(); // 子串的长度int index = 0; // 截取子串的开始位置String temp = strtwo;while(!strone.contains(temp)){if(index <= maxlen - len)temp = strtwo.substring(index++, len); // 从index位置开始不断往后截取子串尝试else{// 如果len长度的没有,那么试试len-1的len = strtwo.length() - 1;index = 0;}}return temp;}// 方法二public static String getMaxSubString(String strone,String strtwo){// 分辨最长最短字符串String max = "", min = "";if(strone.length()>strtwo.length()){max = strone;min = strtwo;}else{min = strone;max = strtwo;}// 枚举较短字符串的子串进行与较长字符串的匹配for(int i=0; i<min.length()-1 ; i++){// 截取min字符串的角标j到k的长度for(int j=0,k=min.length()-i; k!=min.length()+1;j++,k++){String temp = min.substring(j, k);if(max.contains(temp))return temp;}}return "";}
}StringBuffer
什么是StringBuffer?
StringBuffer:就是字符串缓冲区。
用于存储数据的容器。
特点
- 长度是可变的。
- 可以存储不同类型的数据。
- 最终要转成字符串进行使用。
- 可以对字符串进行修改。
代码演示功能
class StringBufferDemo
{public static void main(String[] args) {bufferMethodDemo_1();}public static void bufferMethodDemo_1(){/** 1、添加* StringBuffer append(data); // 追加数据* StringBuffer insert(index, data); // 指定位置插入数据* 2、删除* StringBuffer delete(int start, int end); // 包含头,不包含尾* StringBuffer deleteCharAt(int index); // 删除指定位置的元素* 3、查找* char charAt(int index);* int indexOf(String str);* int lastIndexIf(String str);* 4、修改* StringBuffer replace(int start, int end, String str);* void setCharAt(int index, char ch);*/// 添加StringBuffer sb = new StringBuffer();sb.append(1).append("2").append('3').append(true).append(5l);System.out.println("append:"+sb); // 123true5sb.insert(2,false); System.out.println("insert:"+sb); // 12false3true5// 删除sb.delete(2,7);System.out.println(sb);// 清除缓冲区// sb.delete(0, sb.length());// 查找System.out.println("charAt:"+sb.charAt(1));System.out.println("indexOf:"+sb.indexOf("true"));System.out.println("lastIndexOf:"+sb.lastIndexOf("5"));// 修改System.out.println("replace:"+sb.replace(0,2,"hahha"));sb.setCharAt(0,'a');System.out.println("setCharAt:"+sb);}}

StringBuilder和StringBuffer的区别
jdk1.5以后出现了功能和StringBuffer一模一样的对象,就是StringBuilder。
不同的是:
- StringBuffer是线程同步的,通常用于多线程。
- StringBuilder是线程不同步的,通常用于单线程。它的出现提高效率。
基本数据类型对象包装类
作用:
为了方便操作基本数据类型值,将其封装成了对象,在对象中定义了属性和行为丰富了该数据的操作。
用于描述该对象的类就称为基本数据类型对象包装类。
byte Byte , shrot Short , int Integer , long Long , float Float , double Double , char Character , boolean Boolean
基本数据类型和字符串之间的转换
1、基本类型 ---> 字符串
- 基本数据类型+""
- 用String类中的静态方法valueOf(基本类型数值)
2、字符串 ---> 数据类型
- 使用包装类中的静态方法 xxx parseXxx("xxx类型的字符串"),只有Character包装类没有parse方法
- 如果字符串被Integer进行对象的封装,可以使用另一个非静态的方法,intValue()
进制的转换
1. 十进制 ---> 其他进制
toBinaryString
toOctalString
toHexString
2. 其他进制 ---> 十进制
parseInt("string", radix)
JDK1.5自动装箱拆箱
Integer i = 4; // i = new Integer(4); 自动装箱,简化书写
i = i + 6; // i = new Integer(i.intValue() + 6) ; // i.intValue(); 自动拆箱
Integer a = new Integer(128);
Integer b = new Integer(128);
System.out.println(a==b); // false
System.out.println(a.equals(b)); // true
Integer x = 129; // jdk1.5以后,自动装箱,如果装箱的是一个字节,那么该数据会共享不会重新开辟空间
Integer y = 129;
System.out.println(x==y);
System.out.println(x.equals(y)); // true
集合框架由来
对象用于封装特有数据,对象多了需要存储,如果对象的个数不确定,就是用集合容器进行存储。
集合容器因为内部的数据结构不同,所以有多种具体容器,不断地向上抽取,就形成了集合框架体系。
特点
- 是用于存储对象的容器。
- 集合的长度是可变的。
- 集合中不可以存储基本数据类型值。
Collectuib接口
Collection接口是集合框架的顶层接口。
常见方法:
1,添加。
boolean add(Object obj); // 添加元素
boolean addAll(Collection coll); // 将集合coll里的所有元素添加到当前对象集合
2,删除。
boolean remove(Object obj); // 删除元素
boolean removeAll(Collection coll); // coll和当前集合的交集部分,是当前集合的删除内容
void clear(); // 清空集合里的所有元素
3,判断。
boolean contains(Object obj); // 是否包含指定元素
boolean containsAll(Collection coll); // coll是否是子集合
boolean isEmpty(); // 判断集合是否有元素
4,获取。
int size(); // 集合元素个数
Iterator iterator(); // 取出元素的方式:迭代器
该对象ixu依赖于具体容器,因为每一种容器的数据结构都不同。
所以该迭代器对象是在容器中进行内部实现的。
对于使用容器者而言,具体的实现不重要,只要通过容器获取到该实现的迭代器的对象即可,也就是iterator();。
Iterator接口就是对所有的Collection容器进行元素取出的公共接口。
5,其他。
boolean retainAll(Collection coll); // 取交集
Object[ ] toArray(); // 将集合转成数组。
Demo
import java.util.Collection;
import java.util.ArrayList;
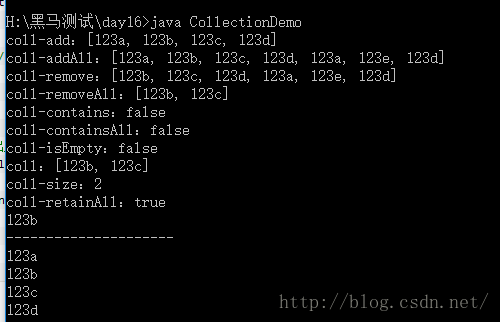
import java.util.Iterator;class CollectionDemo
{public static void main(String[] args) {// Collection 是一个接口,所以...collectionMethodShow(new ArrayList());System.out.println("---------------------");collectionIterator(new ArrayList());}public static void collectionMethodShow(Collection coll){// 添加coll.add("123a"); // 添加元素coll.add("123b");coll.add("123c");coll.add("123d");System.out.println("coll-add:"+coll);Collection collTemp = new ArrayList();collTemp.add("123a");collTemp.add("123e");collTemp.add("123d");coll.addAll(collTemp); // 将集合coll里的所有元素添加到当前对象集合System.out.println("coll-addAll:"+coll);// 删除coll.remove("123a"); // 删除元素System.out.println("coll-remove:"+coll);coll.removeAll(collTemp); // coll和当前集合的交集部分,是当前集合的删除内容System.out.println("coll-removeAll:"+coll);// coll.clear(); // 清空集合// 判断System.out.println("coll-contains:"+coll.contains("123a")); // 是否包含指定元素collTemp.remove("123e");System.out.println("coll-containsAll:"+coll.containsAll(collTemp)); // collTemp是否是子集合System.out.println("coll-isEmpty:"+coll.isEmpty()); // 判断集合是否有元素// 获取System.out.println("coll:"+coll);System.out.println("coll-size:"+coll.size()); // 集合元素个数// 其他collTemp.add("123b");System.out.println("coll-retainAll:"+coll.retainAll(collTemp)); // 取交集Object[] arr = coll.toArray(); // // 将集合转成数组。// 遍历数组for(int i=0; i<arr.length-1; i++)System.out.print(arr[i]+",");System.out.println(arr[arr.length-1]);}// 遍历获取集合元素,并输出public static void collectionIterator(Collection coll){// 添加coll.add("123a"); // 添加元素coll.add("123b");coll.add("123c");coll.add("123d");// 通过迭代器迭代,枚举出所有数据,it.hasNext():判断是否拥有下一个元素for(Iterator it = coll.iterator(); it.hasNext();){System.out.println(it.next());}}
}
List和Set的特点
List:有序(存入和取出的顺序一致),元素都有索引(角标),并且元素可以重复。
Set:无序,元素不可以重复。
List特有的常见方法:
与Collection不同的是,List可以操作角标,并且还有修改元素的功能。所以,List是可以完成对元素的增删改查的。
1,添加。
void add(index, element); // 往指定位置添加一个元素
void add(index,collection); // 往指定位置添加一个集合里的所有元素
2,删除。
Object remove(index); // 删除指定位置的元素
3,修改。
Object set(index,element); // 修改指定位置的元素
4,获取。
Object get(index); // 获取指定位置的元素
int indexOf(Object); // 获取指定元素的角标位置
int lastIndexOf(Object); // 同上,只不过是从后边开始找
List subList(from, to); // 获取指定部分的元素(子列表),包含头,不包含尾
Demo
import java.util.List;
import java.util.ArrayList;
class ListDemo
{public static void main(String[] args) {List list = new ArrayList();showListMethod(list);}public static void showListMethod(List list){// 添加元素。list.add("abc1");list.add("abc1"); // 可以重复元素list.add("abc2"); list.add("abc3"); System.out.println("list-add(obj) : " + list);// 插入元素。list.add(1,"abc8"); // 往角标为1的位置添加一个指定的元素"abc8"System.out.println("list-add(index,obj): " + list);// 删除元素。System.out.println("list-remove(index):" + list.remove(2));System.out.println("list:" + list);// 修改元素。list.set(1,"abc18"); // 修改角标为1的元素System.out.println("list-set(index,obj):"+list);// 获取元素System.out.print("list-get(index):");for(int i=0; i<list.size()-1; i++)System.out.print(list.get(i)+" ");System.out.println(list.get(list.size()-1));System.out.println("list-indexOf:"+list.indexOf("abc2"));System.out.println("list-lastIndexOf:"+list.lastIndexOf("abc2"));System.out.println("list-subList(from,to):"+list.subList(0,2));}
}

迭代器使用注意事项
集合可以使用迭代器进行元素的迭代输出,但是在迭代过程中最好不要对集合进行操作,因为容易出现异常。
比如,通过集合对象调用了iterator()方法来获取了迭代器对象了,然后要迭代,此时迭代器是明确了集合的元素个数的,如果在迭代过程中,需要往集合添加元素的话,这样迭代器是不知道的,但是集合的长度发生了变化,新添加的元素不知道是否迭代获取还是怎么样,所以此时会抛出并发异常,所以建议使用Iterator的过程中不要对集合进行操作。
当然,对于List来说也有解决的方法,在List中有一个方法:listIterator();返回的类型是ListIterator,它可以解决上面的问题。但是并不是说在迭代过程中可以用集合操作,而是使用迭代器对象进行操作,使用迭代器进行元素的增删改查,作用于集合上。
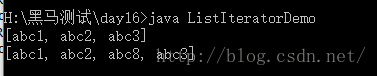
ListIterator迭代器的演示
import java.util.List;
import java.util.ArrayList;
import java.util.ListIterator;class ListIteratorDemo
{public static void main(String[] args) {List list = new ArrayList();list.add("abc1");list.add("abc2");list.add("abc3");System.out.println(list);ListIterator it = list.listIterator();while(it.hasNext()){Object obj = it.next();if(obj.equals("abc2")){it.add("abc8");}}System.out.println(list);}
}
List常用的子类
Vector:内部是数组数据结构,是同步的。增删,查询都很慢。
ArrayList:内部是数据数据结构,是不同步的。替代了Vector。查询的速度快。
增删慢,因为每增加或者删除一个元素,都会让很多元素进行移位。
LinkedList:内部是链表数据结构,是不同步的。增删元素的速度很快。
演示LinkedList
import java.util.LinkedList;class LinkedListDemo
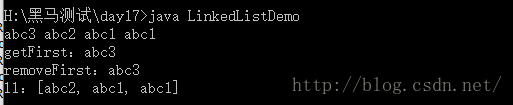
{public static void main(String[] args) {LinkedList ll = new LinkedList();ll.addFirst("abc1"); // 往头添加ll.addFirst("abc1");ll.addFirst("abc2");ll.addFirst("abc3");for(int i=0; i<ll.size(); i++)System.out.print(ll.get(i)+" "); // abc3 abc2 abc1 abc1System.out.println();System.out.println("getFirst:"+ll.getFirst()); // 获取第一个System.out.println("removeFirst:"+ll.removeFirst()); // 删除第一个System.out.println("ll:"+ll);}
}
使用LinkedList实现队列的数据结构
import java.util.LinkedList;class DuiLie
{private LinkedList ll ;DuiLie(){ll = new LinkedList();}public void myAdd(Object obj){ll.addLast(obj); }public Object myGet(){return ll.removeFirst();}public boolean isNull(){return ll.isEmpty();}}class LinkedListTest
{public static void main(String[] args) {DuiLie dl = new DuiLie();dl.myAdd("android01");dl.myAdd("android02");dl.myAdd("android03");dl.myAdd("android04");dl.myAdd("android05");while(!dl.isNull()){System.out.println(dl.myGet());}}
}
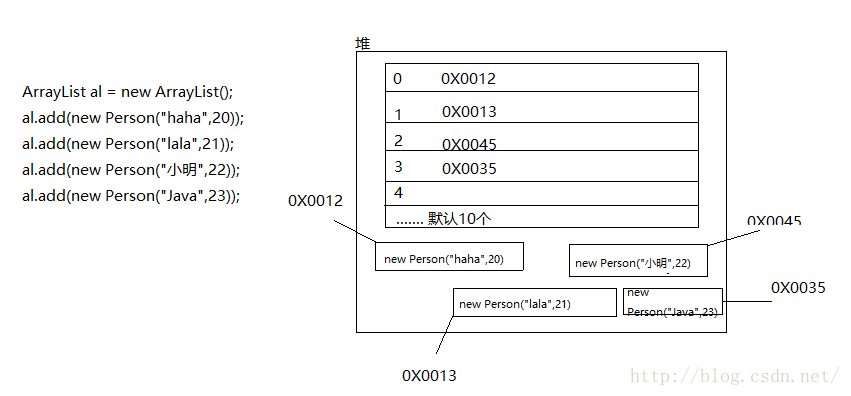
演示ArrayList存储自定义对象
import java.util.ArrayList;
import java.util.Iterator;/* 需求:演示ArrayList集合存储自定对象 */class Person
{private String name;private int age;public Person(){}public Person(String name, int age){this.name = name;this.age = age;}public void setName(String name){this.name = name;}public String getName(){return name;}public void setAge(int age){this.age = age;}public int getAge(){return age;}
}class ArrayListDemo
{public static void main(String[] args) {// 演示ArrayList集合存储自定对象 ArrayList al = new ArrayList();al.add(new Person("haha",20));al.add(new Person("lala",21));al.add(new Person("小明",22));al.add(new Person("Java",23));// 迭代for(Iterator it = al.iterator(); it.hasNext();){Person p = (Person)it.next();System.out.println(p.getName()+"--"+p.getAge());}}
}
ArrayList存储内存图解
ArrayList去重元素
import java.util.ArrayList;
import java.util.Iterator;/*** 需求:将集合中重复对象进行去重处理。*/class Person
{private String name;private int age;public Person(){}public Person(String name, int age){this.name = name;this.age = age;}// 比较两个对象的内容,如果相同则返回true,表明集合里有该对象public boolean equals(Object obj){// 如果是同一个对象if(this==obj)return true;// 必须是人与人比if(!(obj instanceof Person))throw new ClassCastException("类型不对!");Person p = (Person)obj;// System.out.println(this.name+"...equlas..."+p.name);return this.name.equals(p.name) && this.age == p.age;}public void setName(String name){this.name = name;}public String getName(){return name;}public void setAge(int age){this.age = age;}public int getAge(){return age;}// 覆写toString方法public String toString(){return this.name+"..."+this.age;}}class ArrayListTest2
{public static void main(String[] args) {ArrayList al = new ArrayList();al.add(new Person("haha",21));al.add(new Person("okok",22));al.add(new Person("haha",21));al.add(new Person("Java",23));al.add(new Person("lalllala",24));System.out.println(al);al = getSingleElements(al);System.out.println(al);}// 去重public static ArrayList getSingleElements(ArrayList al){ArrayList temp = new ArrayList();for(Iterator it = al.iterator();it.hasNext();){Person p = (Person)it.next();// 如果集合中没有该元素就将其添加到集合中if(!temp.contains(p)){temp.add(p);}}return temp;}
}

Set接口
元素不可以重复,是无序的。
Set接口中的方法和Collection中的方法一致。
有两个常用的子类:
- HashSet:内部数据结构是哈希表,是不同步的。
- TreeSet:
HashSet简单演示
import java.util.HashSet;
import java.util.Iterator;class HashSetDemo
{public static void main(String[] args) {HashSet hs = new HashSet();hs.add("lala");hs.add("haha");hs.add("lala");hs.add("xixi");hs.add("java");for(Iterator it = hs.iterator();it.hasNext();){System.out.println(it.next());}}
}

HashSet存储原理
HashSet比List的内部结构复杂些,HashSet内部使用的数据结构是哈希表。
在添加元素的时候,通过哈希算法(以及元素自身的特点)算出该元素的位置,然后把该元素存储到算出的位置,但是如果当前位置已有元素占有,
那么,有多种处理方式, 可以顺延,也就是往后判断是否为空位,是的话,就存储在该位置。
具体步骤:
哈希表确定元素是否相同
- 判断的是两个元素的哈希值是否相同。如果相同,再判断两个对象的内容是否相同。
- 判断哈希值相同,其实就是判断对象的hashCode的方法。判断内容是否相同,用的是equals方法。
注意:如果哈希值不同,是不需要判断equals的。
HashSet存储自定义对象
import java.util.HashSet;
import java.util.Iterator;/*** 需求:演示HashSet存储自定义对象,如果姓名和年龄相同,那么视为同一个人。 */class Person
{private String name;private int age;public Person(){}public Person(String name, int age){this.name = name;this.age = age;}// 尽可能的让哈希值唯一public int hashCode(){// 因为姓名是字符串,字符串也有自己的哈希值return this.name.hashCode() + this.age * 38;}// 如果两个对象的哈希值相同,那么比较两个对象的内容public boolean equals(Object obj){// 如果是同一个对象if(this==obj)return true;// 必须是人与人比if(!(obj instanceof Person))throw new ClassCastException("类型不对!");Person p = (Person)obj;// System.out.println(this.name+"...equlas..."+p.name);return this.name.equals(p.name) && this.age == p.age;}public void setName(String name){this.name = name;}public String getName(){return name;}public void setAge(int age){this.age = age;}public int getAge(){return age;}
}class HashSetTest
{public static void main(String[] args) {HashSet hs = new HashSet();hs.add(new Person("haha",21));hs.add(new Person("okok",22));hs.add(new Person("haha",21));hs.add(new Person("Java",23));hs.add(new Person("lalllala",24));for(Iterator it = hs.iterator();it.hasNext();){Person p = (Person)it.next();System.out.println(p.getName()+"..."+p.getAge());}}
}

简单介绍一下LinkedHashSet集合
具有可预知迭代顺序的 Set 接口的哈希表和链接列表实现。
跟HashSet的用法一样,只不过HashSet是无序的,而它是有序的,当然也是元素唯一的。
如果仅需要唯一的话,用HashSet即可解决。
TreeSet
可以对Set集合中的元素进行排序,是不同步的。
如果存储的是字符串对象的话,默认是以字典序排序的。
判断元素唯一性的方式:就是根据比较方法的返回结果是不是0,是0的话,那就视为相同元素,不存入集合。
TreeSet对元素进行排序的方式一:
让元素自身具有比较的功能,元素就需要实现Comparable接口,并覆盖compareTo方法,自定义自己的比较方法。
如果不要按照对象中具备的自然顺序进行排序。如果对象中不具备自然排序,怎么办呢?
TreeSet对元素进行排序的方式二:
可以让TreeSet集合自身具备比较功能。
TreeSet存储对象并自定义排序
import java.util.TreeSet;
import java.util.Iterator;class Person implements Comparable
{private String name;private int age;public Person(){}public Person(String name, int age){this.name = name;this.age = age;}// 实现了Comparable就要覆盖CompareTo方法public int compareTo(Object obj){Person p = (Person)obj;// 先判断年龄是否相等,如果想到那么判断姓名int temp = this.age - p.age;return temp == 0?this.name.compareTo(p.name) : temp;}public void setName(String name){this.name = name;}public String getName(){return name;}public void setAge(int age){this.age = age;}public int getAge(){return age;}// 覆写toString方法public String toString(){return this.name+"..."+this.age;}
}class TreeSetDemo
{public static void main(String[] args) {TreeSet ts = new TreeSet();ts.add(new Person("haha",21));ts.add(new Person("okok",22));ts.add(new Person("haha",21));ts.add(new Person("hahahahha",21));ts.add(new Person("Java",23));ts.add(new Person("lalllala",24));for(Iterator it = ts.iterator();it.hasNext();){Person p = (Person)it.next();System.out.println(p.getName()+"..."+p.getAge());}}
}

Comparator比较器
自定义一个比较器,实现Comparator接口,覆盖compare方法,自定义排序。在实例化集合的时候,new一个比较器作为参数来构建集合对象,使其拥有比较功能。
import java.util.TreeSet;
import java.util.Iterator;
import java.util.Comparator;class Person
{private String name;private int age;public Person(){}public Person(String name, int age){this.name = name;this.age = age;}public void setName(String name){this.name = name;}public String getName(){return name;}public void setAge(int age){this.age = age;}public int getAge(){return age;}// 覆写toString方法public String toString(){return this.name+"..."+this.age;}
}// 自定义比较器
class MyComparator implements Comparator/*比较器*/
{public int compare(Object o1, Object o2){Person p1 = (Person)o1;Person p2 = (Person)o2;// 主条件int temp = p1.getName().compareTo(p2.getName());return temp == 0 ? p1.getAge() - p2.getAge() : temp;}
}class TreeSetTest
{public static void main(String[] args) {TreeSet ts = new TreeSet(new MyComparator());ts.add(new Person("haha",21));ts.add(new Person("okok",22));ts.add(new Person("haha",21));ts.add(new Person("hahahahha",21));ts.add(new Person("Java",23));ts.add(new Person("lalllala",24));for(Iterator it = ts.iterator();it.hasNext();){Person p = (Person)it.next();System.out.println(p.getName()+"..."+p.getAge());}}
}
泛型
泛型:jdk1.5出现的安全机制。
好处:
- 将运行时期的问题ClassCastException转到了编译时期。
- 避免了强制转换的麻烦。
何时使用?
当操作的引用数据类型不确定的时候,就使用<>,其实就是靠我们程序员主观判断的啦。将要操作的引用数据类型传入即可。其实<>就是一个用于接收具体引用数据类型的参数范围。
在程序中,只要用到了带有<>的类或者接口,就要明确传入的具体引用数据类型。
Demo
import java.util.ArrayList;
import java.util.Iterator;class GenericDemo
{public static void main(String[] args) {// <Integer> 泛型,指明这个集合存入的数据类型ArrayList<Integer> al = new ArrayList<Integer>();al.add(1); // 自动装箱al.add(2);al.add(3);al.add(8); Iterator<Integer> it = al.iterator();while(it.hasNext()){System.out.println(it.next());}}
}
泛型技术是给编译器使用的技术,用于编译时期,确保了类型的安全。
运行时,会将泛型去掉,生成的class文件中是不带泛型的,这个称为泛型的擦除。
为什么要擦除呢?因为为了兼容运行的类加载器。
泛型的补偿:在运行时,通过获取元素的类型进行转换动作。不用使用者再强制转换了。
泛型在集合中的应用
import java.util.TreeSet;
import java.util.Comparator;
import java.util.Iterator;class Person
{private String name;private int age;Person(){}Person(String name, int age){this.name = name;this.age = age;}public void setName(String name){this.name = name;}public String getName(){return name;}public void setAge(int age){this.age = age;}public int getAge(){return age;}
}class ComparatorByName implements Comparator<Person>
{public int compare(Person p1, Person p2){int temp = p1.getName().compareTo(p2.getName());return temp == 0 ? p1.getAge() - p2.getAge() : temp;}}class GenericDemo2
{public static void main(String[] args) {TreeSet<Person> ts = new TreeSet<Person>(new ComparatorByName());ts.add(new Person("abc",25));ts.add(new Person("adc",22));ts.add(new Person("abe",20));ts.add(new Person("abcde",23));ts.add(new Person("jhxl",21));Iterator<Person> it = ts.iterator();while(it.hasNext()){Person p = it.next();System.out.println(p.getName()+" ... "+p.getAge());}}
}泛型类
在jdk1.5后,使用泛型来接收类中要操作的引用数据类型,称之为泛型类。
什么时候使用呢?当类中操作的引用数据类型不确定的时候,就使用泛型来表示。
class Tool<T>
{private T t;public void setT(T t){this.t = t;}public T getT(){return t;}
}class GenericClassDemo
{public static void main(String[] args) {// 指定要操作的引用数据类型Tool<String> tool = new Tool<String>();tool.setT("abc"); // 编译时期不报错// tool.setT(4); // 编译时期报错System.out.println(tool.getT());}
}
泛型方法
class Tool<T>
{private T t;public void setT(T t){this.t = t;}public T getT(){return t;}// 将泛型定义在方法上.public <W> void show(W w){System.out.println("show:"+w);}public void print(T t){System.out.println("print:"+t);}/*** 当方法静态时,不能访问类上定义的泛型。如果静态方法使用泛型,只能将泛型定义在方法上。*/// 泛型定义在修饰符后面 , 返回值类型的前面public static <Y> void method(Y y){System.out.println("metohd:"+y);}}class GenericMethodDemo
{public static void main(String[] args) {Tool<String> tool = new Tool<String>();tool.show(new Integer(8)); // 可以传入任意引用数据类型,因为泛型定义在方法上tool.print("abc"); // 只能是字符串类型的,因为是传入类指定的泛型类型Tool.method(new Integer(9));Tool.method("hahahha");}
}
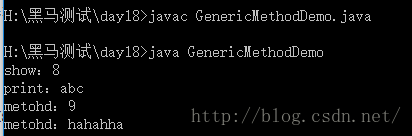
泛型接口
interface Inter<T>
{public void show(T t);
}class InterImpl <A> implements Inter<A>
{public void show(A a){System.out.println("show:"+a);}
}class GenericInterfaceDemo
{public static void main(String[] args) {// 在实例化的时候,才明确类型InterImpl<Integer> ii = new InterImpl<Integer>();ii.show(new Integer(111));}
}
泛型限定
可以对类型进行限定。
? extends E:接收E类型或者E的子类型对象。上限。
? super E :接收E类型或者E的父类型对象。下限。
一般在存储元素的时候都是用上限的,因为这样取出都是按照上限类型运算的。不会出现类型安全隐患。其实上限用的比较多一些。
什么时候用下限?通常对集合中的元素进行取出操作时,可以使用下限。
在这里演示一下上限,那么下限自然也就明白了!
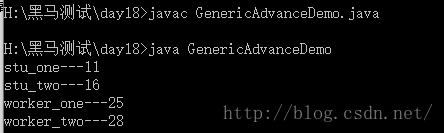
import java.util.ArrayList;
import java.util.Iterator;class Person
{private String name; // 名字private int age; // 年龄Person(){}Person(String name, int age){this.name = name;this.age = age;}public void setName(String name){this.name = name;}public String getName(){return name;}public void setAge(int age){this.age = age;}public int getAge(){return age;}
}// 学生类
class Student extends Person
{Student(){}Student(String name, int age){super(name, age);}
}// 工人类
class Worker extends Person
{Worker(){}Worker(String name, int age){super(name, age);}}class GenericAdvanceDemo
{public static void main(String[] args) {// 指定泛型,该集合只存Student类型的元素ArrayList<Student> al1 = new ArrayList<Student>();al1.add(new Student("stu_one", 11));al1.add(new Student("stu_two", 16));// 指定泛型,该集合只存Worker类型的元素ArrayList<Worker> al2 = new ArrayList<Worker>();al2.add(new Worker("worker_one", 25));al2.add(new Worker("worker_two", 28));advanceDemo(al1);advanceDemo(al2);}/*** <? extends Person> 泛型限定,高级货,其实写单写“?”也可以的,但是为了避免传错类型* 比如传入了String的话,就会存在出错的可能,所以,指定是Person或者其子类可以* ?:就是一个通配符*/public static void advanceDemo(ArrayList<? extends Person> al){Iterator<? extends Person> it = al.iterator();while(it.hasNext()){Person p = it.next();System.out.println(p.getName()+"---"+p.getAge());}}
}
Map集合
一次添加一对元素。Collection一次添加一个元素。
Map也称为双列集合,Collection集合称为单列集合。
其实map集合中存储的就是键值对。map集合中必须保证键的唯一性。
常用方法
1,添加。
value put(key, value); 返回前一个和key关联的值,如果没有,则返回null
2,删除。
void clear(); 清空map集合
value remove(key); 根据指定的key删除这个键值对。
3,判断。
boolean containsKey(key); 根据指定的key判断是否存在这个key
boolean containsValue(value); 根据指定的value判断是否存在这个value
boolean isEmpty(); 判断map集合是否为null
4,获取。
value get(key); 根据key获取值,如果没有该键,则返回null
int size(); 获取键值对有多少对
import java.util.Map;
import java.util.Set;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Collection;class MapDemo
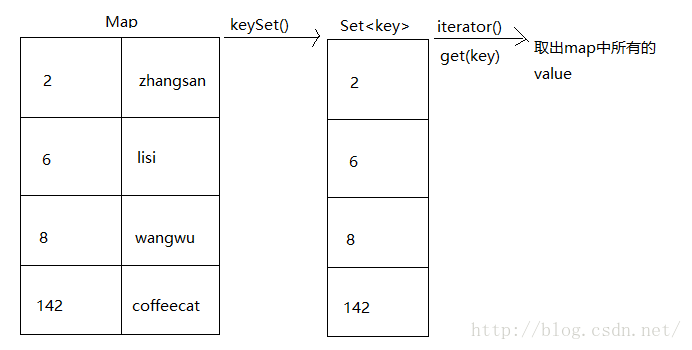
{public static void main(String[] args) {showMapMethod(new HashMap<Integer,String>());}public static void showMapMethod(Map<Integer,String> map){// put方法,返回原来的值System.out.println("put:"+map.put(6,"haha")); // nullSystem.out.println("put:"+map.put(6,"xixi")); // hahamap.put(2,"xiaoming");map.put(8,"xiaoming");map.put(142,"coffeecat");// 删除System.out.println("remove:"+map.remove(2)); // xiaomingSystem.out.println("map:"+map); //{6=xixi, 142=coffeecat, 8=xiaoming}// 判断System.out.println("containsKey:"+map.containsKey(8)); // true// 获取System.out.println("get:"+map.get(142)); // coffeecatSystem.out.println("map:"+map);//{6=xixi, 142=coffeecat, 8=xiaoming}/** 通过Map转成Set可以迭代。* 使用keySet方法,可以获取key的set集合,迭代该集合,就可以取出map中的所有元素。*/Set<Integer> keySet = map.keySet();Iterator<Integer> it = keySet.iterator();while(it.hasNext()){int key = it.next();String value = map.get(key);System.out.println("key="+key+", value="+value);}/** 将Map转成set,还有方法entrySet<Map.Entry<K,V>>;* 该方法将键和值的映射关系作为对象存储到了Set集合中,而这个映射关系的类型就是Map.Entry<K,V>。*/Set<Map.Entry<Integer,String>> entrySet = map.entrySet();Iterator<Map.Entry<Integer,String>> it2 = entrySet.iterator();while(it2.hasNext()){Map.Entry<Integer,String> me = it2.next();System.out.println(me.getKey()+"..."+me.getValue());}Collection<String> values = map.values();Iterator<String> it3 = values.iterator();while(it3.hasNext()){System.out.println(it3.next());}}
}
Map常用的子类:
|-- HashTable:内部结构是哈希表,是同步的。不允许null作为键,null作为值。
|--Properties:用来存储键值对型的配置文件的信息,可以和IO技术相结合。
|--HashMap:内部结构是哈希表,不是同步的。允许null作为键值。
|--TreeMap:内部结构是二叉树,不是同步的。可以对Map集合中的键进行排序。
TreeMap的演示
import java.util.Map;
import java.util.TreeMap;
import java.util.Iterator;class Student implements Comparable
{private String name;private int age;Student(){}Student(String name, int age){this.name = name;this.age = age;}// 覆盖compareTo方法public int compareTo(Object obj){Student stu = (Student)obj;// 优先根据姓名的字典序比较int temp = this.name.compareTo(stu.name);return temp==0?this.age-stu.age:temp;}public String toString(){return name+"..."+age;}
}class TreeMapDemo
{public static void main(String[] args) {TreeMap<Student,String> tm = new TreeMap<Student,String>();method(tm);}public static void method(TreeMap<Student,String> tm){tm.put(new Student("haha",25),"北京");tm.put(new Student("hazy",21),"珠海");tm.put(new Student("coffeecat",22),"上海");tm.put(new Student("aaa",20),"广州");// 迭代Iterator<Map.Entry<Student,String>> it = tm.entrySet().iterator();while(it.hasNext()){Map.Entry<Student,String> me = it.next();Student key = me.getKey();String value = me.getValue();System.out.println(key+"::"+value);}}
}
LinkedHashMap演示
LinkedHashMap,是有序,就是存入的顺序和取出的顺序一致。
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Iterator;class LinkedHashMapDemo
{public static void main(String[] args) {method(new LinkedHashMap<Integer,String>());}public static void method(LinkedHashMap<Integer,String> lhm){lhm.put(5,"Coffee");lhm.put(3,"Cat");lhm.put(6,"Hazy");lhm.put(8,"Color");Iterator<Map.Entry<Integer,String>> it = lhm.entrySet().iterator();while(it.hasNext()){Map.Entry<Integer,String> me = it.next();Integer key = me.getKey();String value = me.getValue();System.out.println(key+"..."+value);}}
}
集合框架工具类——Collections
import java.util.ArrayList;
import java.util.Collections;
import java.util.TreeSet;class CollectionsDemo
{public static void main(String[] args) {sortMethod();System.out.println();mySortMethod();System.out.println();reverseOrderMethod();System.out.println();binarySearchMethod();System.out.println();methodMaxMin();System.out.println();replaceMethod();System.out.println();otherMethod();}// 排序public static void sortMethod(){ArrayList<String> al = new ArrayList<String>();al.add("Hazy");al.add("Coffee");al.add("Hui");al.add("Color");// 排序前System.out.println("排序前:"+al);// 排序Collections.sort(al);// 排序后System.out.println("排序后:"+al);}// 自定义排序public static void mySortMethod(){ArrayList<String> al = new ArrayList<String>();al.add("Hazy");al.add("Coffee");al.add("Hui");al.add("Color");// 排序前System.out.println("排序前:"+al);// 排序for(int i=0; i<al.size()-1; i++){for(int j=i+1; j<al.size(); j++){if(al.get(i).compareTo(al.get(j))>0){// 方式一String temp = al.get(i);al.set(i,al.get(j));al.set(j,temp);// 方式二,指定集合和该集合中两个需要交换位置的元素角标// Collections.swap(al,i,j);}}}// 排序后System.out.println("排序后:"+al);}// 反转集合public static void reverseOrderMethod(){// TreeSet默认以字典序排序,指定Collections.reverseOrder()后,集合将被反转TreeSet<String> ts = new TreeSet<String>(Collections.reverseOrder());ts.add("Hazy");ts.add("Coffee");ts.add("Hui");ts.add("Color");System.out.println(ts);}// 获取最大值和最小值public static void methodMaxMin(){ArrayList<Integer> al = new ArrayList<Integer>();al.add(12);al.add(1);al.add(45);al.add(88);al.add(68);int max = Collections.max(al);int min = Collections.min(al);System.out.println(al);System.out.println("max:"+max+"...min:"+min);}// 折半查找元素public static void binarySearchMethod(){ArrayList<String> al = new ArrayList<String>();al.add("Hazy");al.add("Coffee");al.add("Hui");al.add("Color");Collections.sort(al);// 折半查找字符串"Hui",返回角标int index = Collections.binarySearch(al,"Hui");System.out.println("Hui的角标:"+index);}public static void replaceMethod(){ArrayList<String> al = new ArrayList<String>();al.add("Hazy");al.add("Coffee");al.add("Hui");al.add("Color");al.add("good");System.out.println("替换前:"+al);Collections.replaceAll(al,"good","Best");System.out.println("替换后:"+al);}public static void otherMethod(){ArrayList<String> al = new ArrayList<String>();al.add("Hazy");al.add("Coffee");al.add("Hui");al.add("Color");System.out.println(al);Collections.shuffle(al); // 打乱顺序System.out.println(al);}
}
foreach语句
格式:
for(类型 变量 : Collection集合|数组)
{
}
传统for和高级for的区别?
传统for可以完成对语句执行很多次,因为可以定义控制循环的增量和条件。
高级for是一种简化形式。它必须有被遍历的目标,该目标要么是数组,要么是Collection单例集合。
对数组的遍历如果仅仅是获取数组中的元素,可以使用高级for。
如果要对数组的角标进行操作,建议使用传统for。
import java.util.List;
import java.util.Arrays;class ForeachDemo
{public static void main(String[] args) {String arr[] = {"abc","abcd","abcde"};for(String str : arr){System.out.println(str);}System.out.println();List<String> list = Arrays.asList(arr); // 将数组转成集合for(String str : list){System.out.println(str);}}
}
函数的可变参数和静态导入
import static java.lang.System.*; // 静态导入class ParamterDemo
{public static void main(String[] args) {int sum = add(3,14,4,5,6,2,1);out.println("sum="+sum);}/* * 传入的参数个数不确定* 函数的可变参数。* 其实就是一个数组,但是接受的是数组的元素。* 自动将这些元素封装成数组,简化了调用者的书写。*/public static int add(int... arr){int sum = 0;for(int i : arr){sum += i;}return sum;}
}
这篇关于黑马程序员——Java语言--集合框架的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





