本文主要是介绍医疗知识图谱工程研究记录,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
医疗诊断知识图谱
本项目是基于知识图谱的知识问答项目。过程为对问句进行解析,形成若干三元组及相关的操作条件,转换为查询语句,查询数据库返回结果。
KBQA方式的问答包括意图分析、标签(实体、操作符)识别、条件体与目标体识别、查询语句生成等几个关键步骤。
https://mp.weixin.qq.com/s/F-_qyHTsPtlrK77JgWidoA
1.意图分析
1)基于词典规则的意图分类
收集一下能明显区分问题类型的关键词集合,对输入的问句进行词语匹配或者设定规则。
如下医疗问题的分类,根据这些关键词分不同类型

2)基于学习模型的意图分类
通过预先对问句进行意图标注,形成一定规模的标注数据集,然后通过构造分类器进行训练,然后得到分类结果。可以用CNN或者LSTM做意图分类。分类包含单分类,也可能包含多标签分类。例如:我今天为啥会头痛,该怎么办,包含“发病原因 和治疗措施 两个意图,需要多标签分类任务来处理。
一 工程1
/work/myCode/KBQA/MedicalKG/QASystemOnMedicalKG-master
源代码来源: https://github.com/liuhuanyong/QASystemOnMedicalKG/tree/master/data
1.1 配置
python3 (mac本地,conda activate python3)
py2neo
pyahocorasick
1.2 用法
step0: neo4j start (启动neo4j)
step1:nohup python build_medicalgraph.py (将数据导入neo4j图数据库中,大约需要几小时)
step2:python chatbot_graph.py (启动知识图谱诊断应用)
数据库情况
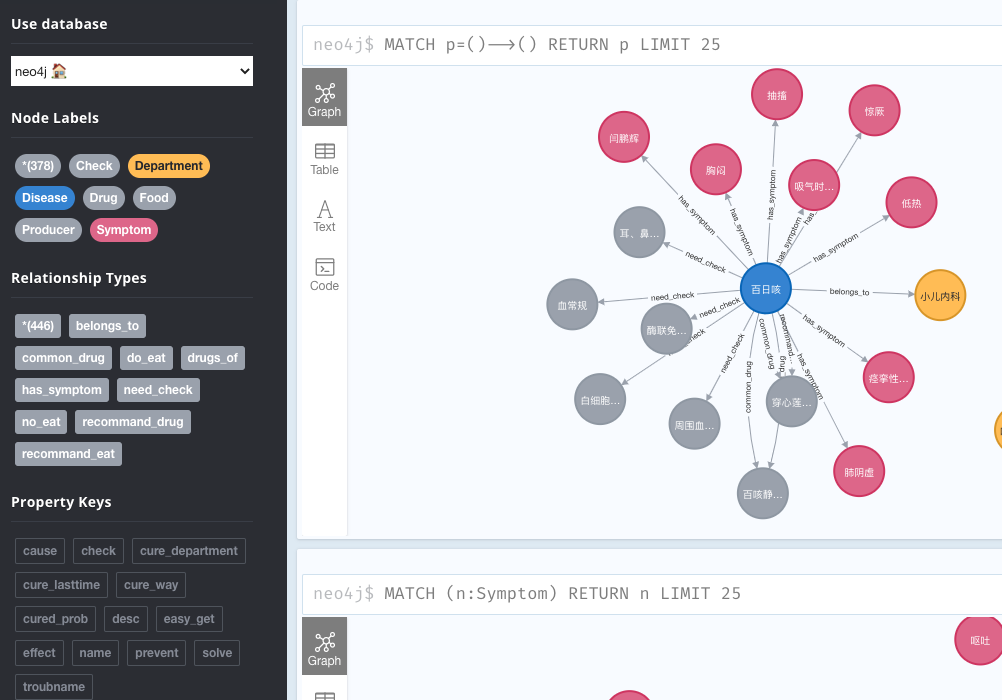
问答展示:

代码结构:

1.3 主要内容
1.对用户输入的query,做问题分类,分类主要靠关键词匹配,匹配到症状,原因,饮食,药物,预防。。等

2.对输入的query,根据问题关键词,将query转为查询语句sql

3.根据查询语句,从图数据库中查询出答案,并调用回复模板来返回。


1.4 存在的问题
1,不支持多轮问答,每轮问答都需要写明问的实体,“感冒怎么治疗” “感冒是什么,怎么治疗” 这种就不行。
2.实体链接不丰富,“头痛”可以支持,“头疼”就不行。
3.代码里写入了太多数据方面的定义,不好扩展到其他领域。
4.不能解决复合问句
二 工程2
/work/myCode/KBQA/MedicalKG/KBQA-for-Diagnosis-main
2.1 源码:
https://github.com/wangle1218/KBQA-for-Diagnosis
2.2 用法:
step0: neo4j start (启动neo4j)
step1:nohup python build_kg/build_kg_utils.py (将数据导入neo4j图数据库中,大约需要几小时)
step2:python start_app.py (启动知识图谱诊断应用)
2.3 主要内容:
-
将json格式的数据导入图数据库中,此处数据来源就是上一个工程,medical.json
build_kg/build_kg_utils.py 导入数据脚本 ./graph_data/medical.json 数据路径 -
使用分类模型,来判断输入query是闲聊类问题,还是医疗诊断问题。分类模型由sklearn 库中的逻辑回归和gdbt实现,两种模型的预测结果概率值做平均,以此来区分是否是闲聊,以及闲聊的类别
代码:nlu/sklearn_Classification 模型训练:train.py 模型预测:clf_model.py 函数:clf_model.predict(text)/nlu/sklearn_Classification/data/intent_recog_data.txt 中定义了闲聊类别:greet,goodbye,accept等 -
对诊断类问题,由意图识别模型判断是哪种意图。模型由bert训练
代码:nlu/bert_intent_recognition 模型训练:train.py 模型构建:bert_model.py 模型预测服务:app.py 基于flask的服务,可以单独运行 意图类别:label中,细分为:定义,病因,预防,传染性,治愈率,治疗时间等。意图识别是先搭建flask服务,再从端口获取意图结果

4.对诊断类问题,获取对应的slot


需要提前标注数据,训练slot模型。模型用bilstm+crf来训练
代码:knowledge_extraction/bilstm_crf
基于knowledge_extraction/bilstm_crf的slot模型训练
模型训练:train.py
服务:app.py
slot标签定义:knowledge_extraction/bilstm_crf/checkpoint/diseases.json
5.对诊断类问题,根据意图和slot,获取答案。此处根据意图置信度做了确认和拒绝回答的处理。
当意图置信度达到一定阈值时(>=0.8),可以查询该意图下的答案
当意图置信度较低时(0.4~0.8),按最高置信度的意图查找答案,询问用户是否问的这个问题
当意图置信度更低时(<0.4),拒绝回答
6.如果是确定的问题,根据slot获取对应的cql语句,然后进行数据库查询,返回答案
cql语句模板定义:config.py

根据组织好的cql语句,在数据库中查询

2.4 其他目录
entity_normalization 实体对齐目录,定义了同一病症不同的说法
faiss_index 一种检索方法,包含数据
knowledge_extraction 知识抽取目录,包含了bert服务部署,bilstm-crf做slot训练,CasRel (??)
nlu/slotgate_slu 基于slotgate的slot训练。包含数据
doc :一些论文介绍
2.5 一些报错:
1.错误1

解决:降低keras的版本
pip install keras==2.3.1
2.错误2

解决:
pip install 'h5py<3.0.0' -i https://pypi.tuna.tsinghua.edu.cn/simple
3.错误3:

解决:
该报错的文件中import部分,
import keras 改为 import tensorflow.keras
4.报错4

启动知识图谱服务时候报错,端口不支持
原因分析:
使用python连接neo4j数据库时出现了该问题, 原因是py2neo的版本太高。
解决:
下载低版本(如4.3.0)
pip install py2neo==4.3.0 -i https://pypi.douban.com/simple
5.报错5

原因:numpy版本较老,版本不匹配。
解决:
pip install numpy --upgrade --user
三 其他医疗知识图谱构建结构图
3.1 糖尿病知识图谱
数据:https://tianchi.aliyun.com/dataset/dataDetail?dataId=88836
比赛: https://tianchi.aliyun.com/forum?spm=5176.21852664.0.0.44f867963jprX7#raceId=231687
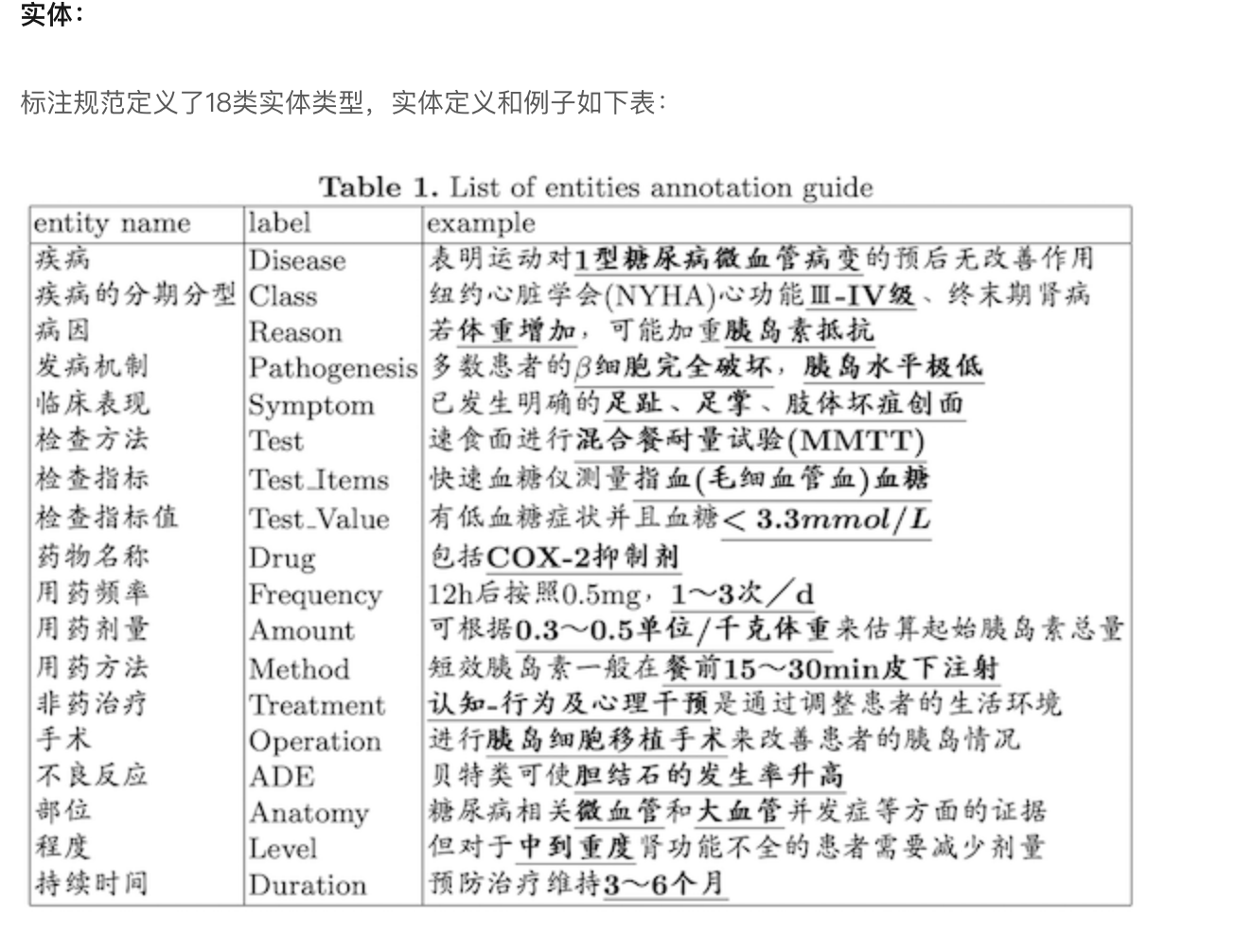

3.2 中文医疗知识图谱 https://tianchi.aliyun.com/dataset/dataDetail?spm=5176.12282016.0.0.681c6d92qv5NDw&dataId=954143.3 医疗知识图谱各个实体解析 https://schema.omaha.org.cn/class/ClinicalFinding 汇知医学知识图谱数据 http://wiki.omaha.org.cn/pages/viewpage.action?pageId=31424961病人事件图谱 https://luckyxuli.github.io/peg/#/**运维行车设备知识图谱 http://openkg.cn/dataset/qm-data** 中药说明书实体识别数据集 https://tianchi.aliyun.com/dataset/dataDetail?dataId=86819中医文献问题生成数据集 http://openkg.cn/dataset/tcm-qg数控机床故障诊断知识图谱 https://github.com/wangrenyisme/Shukongdashi在线故障诊断平台比赛 http://www.cnsoftbei.com/plus/view.php?aid=353基于故障诊断的问答系统 https://github.com/LiuYuhanMIO/QA机械故障数据集 https://github.com/hustcxl/Rotating-machine-fault-data-set
这篇关于医疗知识图谱工程研究记录的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







