本文主要是介绍C Linux 下简单实现单词统计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
/*
功能实现:
从文本文档里读取英文单词,可能含有中文字符,
实现英文单词,中文字符的数目统计
Author :贺荣伟
creat Time: 16:01 2015/7/10 星期五
#include <stdio.h>
#include <math.h>
#include <stdlib.h>
#include <string.h>
#include <ctype.h>const int str_len=1010;
char str[str_len];
bool vis[str_len];typedef long long LL;
typedef unsigned long long LLU;int word_count,hanzi_count;void is_word();
void is_hanzi();/*//fgets 方法:char *fgets(char *string, int n, FILE *stream)从文件stream中读取n-1个字符/一行(若一行不满n-1个),string接收字符串如果n <= 0,返回NULL如果n == 1,返回" ",也就是一个空串如果成功,返回值等于string, 也就是获得字符串的首地址//如果出错,或者读到FILE的结尾,返回NULL.FILE *textfile=fopen("text.txt","r");///打开一个文件while(fgets(str,str_len,textfile)!=NULL){str[strlen(str)-1]='\0';printf("%s \n",str);printf("the text size is %d\n",strlen(str));}fclose(textfile);
*/void is_word()
{char ch;bool flag=0;int word_count=0,length=0;FILE *fp=fopen("text.txt","r"); / *打开文件 */while((fp==NULL)) /*打开失败 */{puts("text.txt open failure");exit(0);}while(fgets(str,str_len,fp)!=NULL) /*fgets 的定向输入,获取输入流的长度 */{length=strlen(str);}fclose(fp);for(int i=0; i<length; ++i) /*判断单词 */{if(isalpha(str[i])&&flag==0){word_count++;flag=1;}if(!isalpha(str[i])){flag=0;}}/*while(!feof(fp)){ch=fgetc(fp);///if(isalpha(ch))if(ch>='a'&&ch<='z'||ch>='A'&&ch<='Z'){flag==0;}else if((flag==0)&&(ch!='-'&&ch!='/'&&ch!='\'')){word_count++;flag=1;}}fclose(fp);*/printf("单词个数为: %d 个\n",word_count);
}void is_hanzi()
{int ch,hanzi_count=0;FILE *fp=fopen("text.txt","r"); /*打开文件 */while((fp==NULL)){puts("text.txt open failure"); /*打开失败 */exit(0);}while(!feof(fp)){ch=fgetc(fp);///ASCII 最大127 /*判断汉字 */if(ch>127) {fgetc(fp);hanzi_count++;}}fclose(fp);printf("中文字符为: %d 个\n",hanzi_count);
}
int main()
{is_word(); /*调用 is_word() 函数*/is_hanzi(); /*调用 is_hanzi() 函数*/return 0;
}
测试:
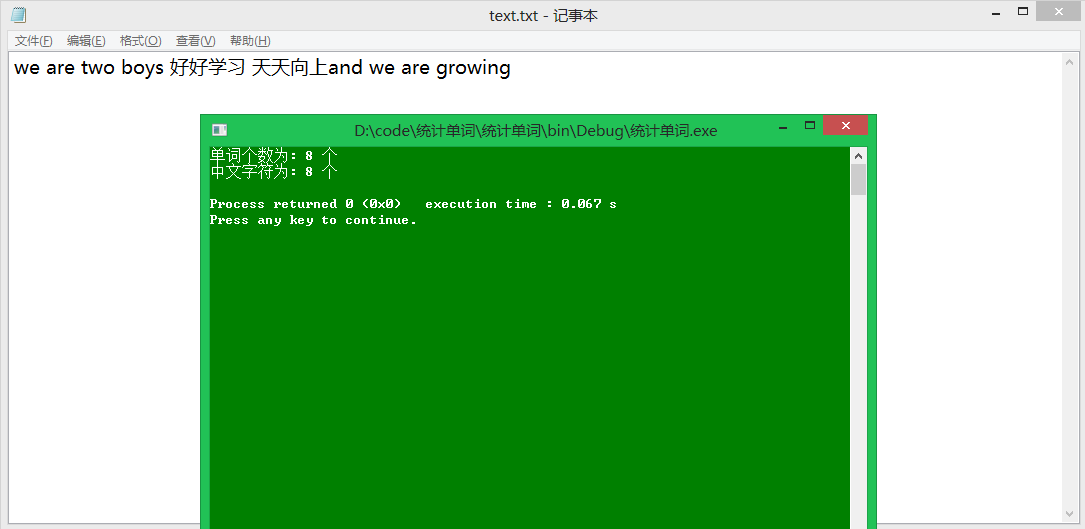
Linux系统命令行统计文本单词个数及出现频率:
参数:wc -w, text.txt
打印单词数(print the word counts)
测试:
文本内容:
We are two boy
结果 4
统计单词出现频率:
这个刚学shell,有些不懂,查找书籍资料和网上资源,知道是这样这样写:
命令行:
Cat text.txt |tr -cs "[a-z][A-Z]" "[\012*]"|tr A-Z a-z|sort|uniq -c|sort -k1nr -k2|head -10
简单分析:cat text.txt:表示创建一个文件。
|:表示重定向,即把上一个命令的结果传递给下一个命令。
tr 命令:tr是transform的缩写,该命令是著名的流处理命令sed的简化版,也是用来对文档进行转换的。
tr -cs “[a-z][A-Z]" "\n" -c表示取“[a-z][A-Z]"的补集(complement),-s 表示把连续的匹配压缩成一个”\012“,*号表示将集合2中的字符补全,与集合1的字符长度一致,所以整个命令就是把除了字母外的其他字符一律压缩成换行符,如果有连续的匹配,则只转换成一个换行符。
tr A-Z a-z 把大写统一转换成小写。
sort 排序 按字母顺序
uniq 去重 该命令必须对排序好的文档进行,-c 表示打印出字母的重复次数
然后再次 sort ,这次sort比较复杂,因为在uniq命令后 输出结果已经变成了 如下形式:
n word (单词的重复次数+空格+单词)
所以 -k1nr表示对第一列(-k1)的数字形式(-n)的变量进行逆序(-r 从大到小)排列 , -k2表示在前面的排序基础上对重复次数一致的单词进行按字母顺序的排列。
最后是head -n$1,表示只显示结果的前$1行。
文本内容:
We are to boy
结果:
1 are
1 boy
1 to
1 we(均出现一次)
这篇关于C Linux 下简单实现单词统计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








