本文主要是介绍五种情况,不加GAP锁,只加行锁,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大家好,我是大都督周瑜,最近在整理MySQL源码的笔记,这里分享一篇出来,想看其他的可以关注我的公众号:IT周瑜。
在源码中有这么一段:
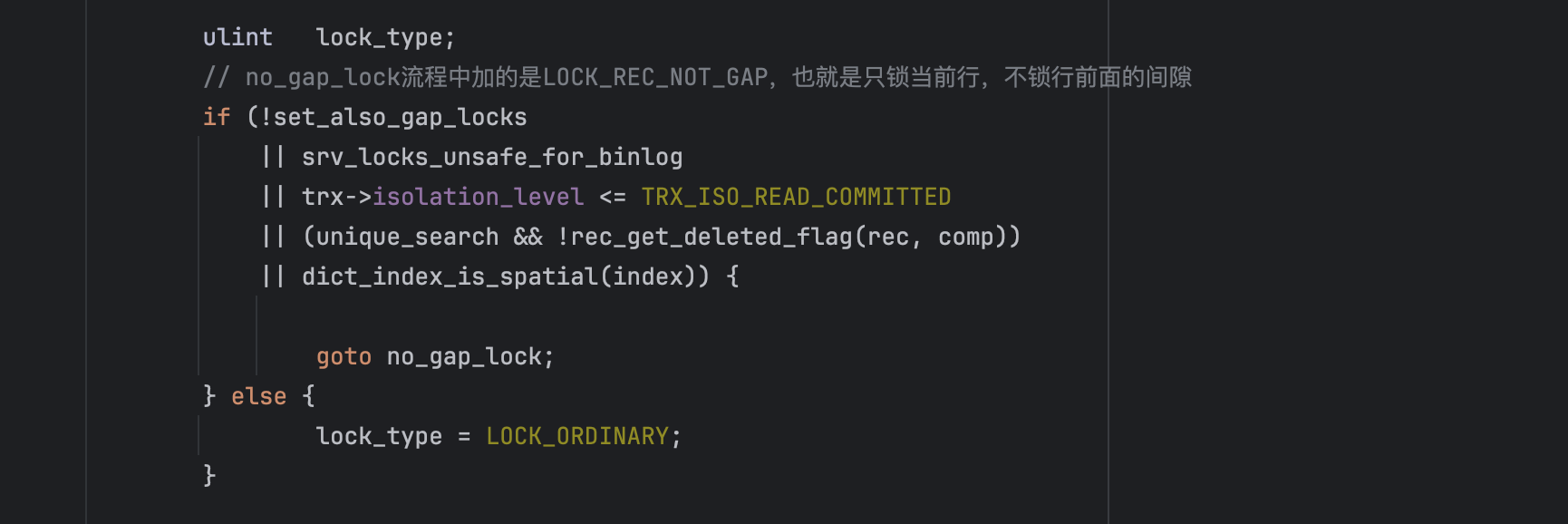
goto no_gap_lock表示加的锁类型为:LOCK_REC_NOT_GAP,也就是我们通常所理解的行锁,只锁记录行本身,不说记录前面的间隙。
上面代码中,如果进入else分支,那么锁的类型是LOCK_ORDINARY,它表示既锁记录本身,也锁记录前面的间隙,也就是我们常说的next-key锁,因此大家能猜到,那有没有一种锁类型只锁记录前面的间隙而不锁记录本身呢,当然有啦,那就是LOCK_GAP,对应源码为:
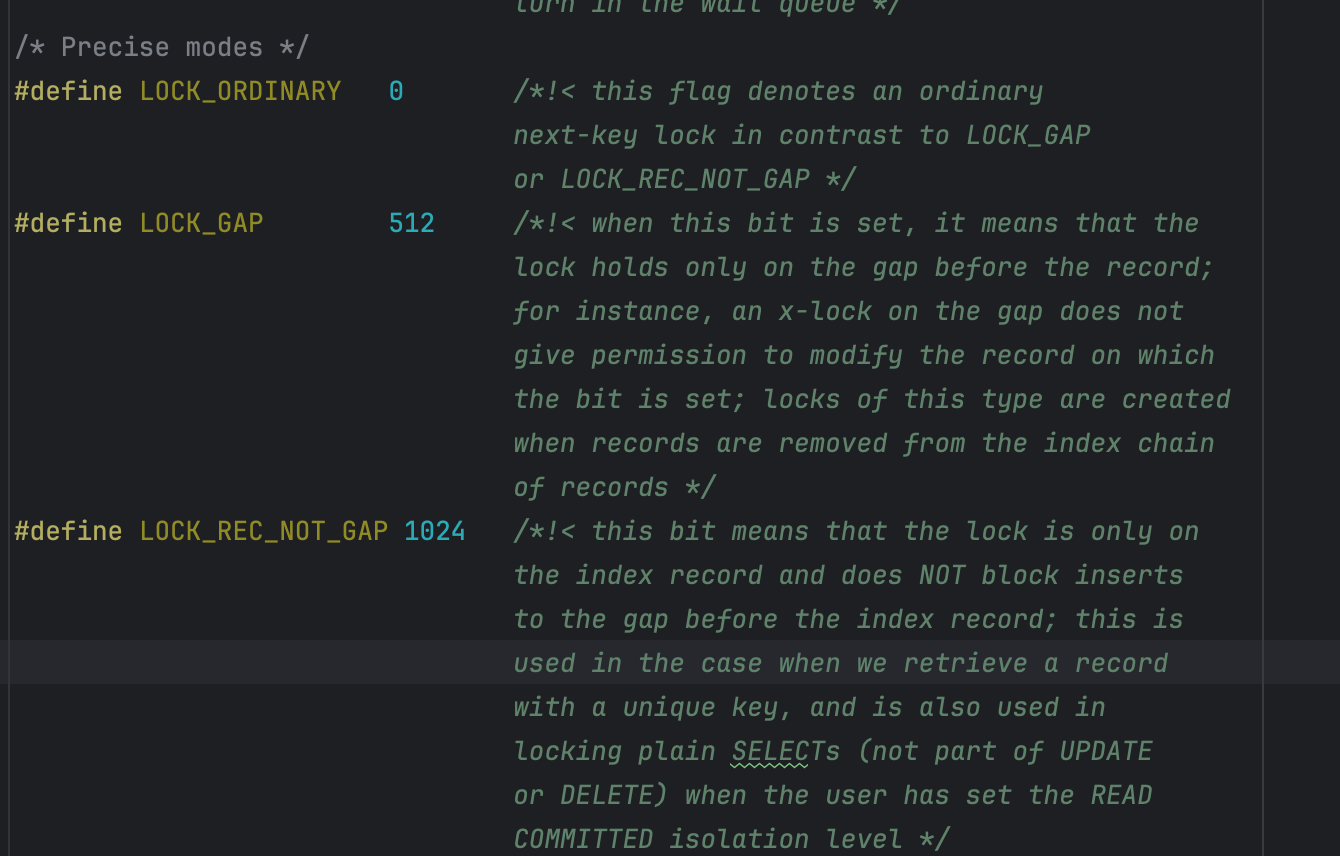
扯远了,我们还是回答本文的主题:什么时候不加GAP锁,只加行锁?
第一种情况
再看看前面的源码:
因此,只要符合if条件,进入no_gap_lock流程就是我们要的答案,由于if中都是或条件,因此我们只需要一个个条件进行分析就能得到答案。
首先,set_also_gap_locks为false,在源码中set_also_gap_locks默认为true,只在一个地方进行了赋值,赋值代码为:
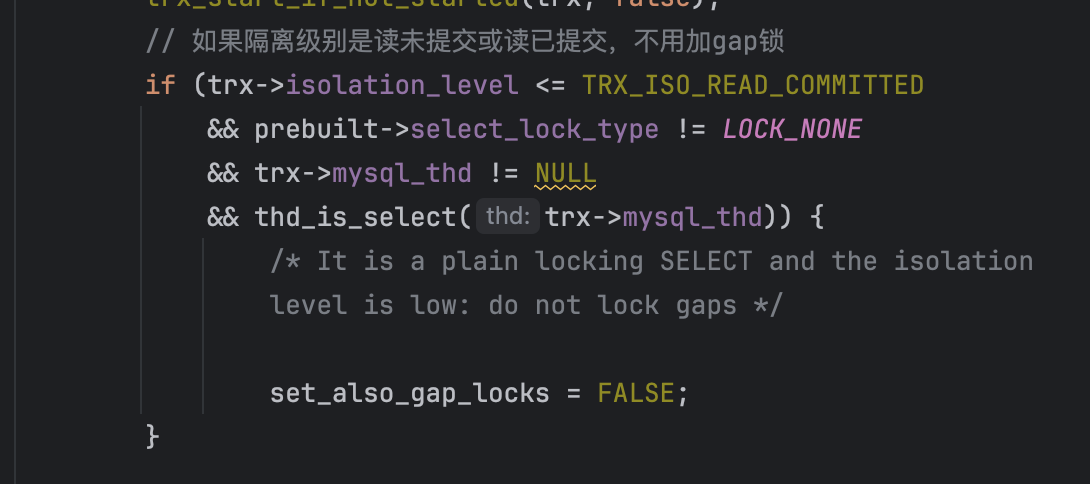
第三个条件不用管,其他条件为:
- trx->isolation_level <= TRX_ISO_READ_COMMITTED:表示隔离级别是读未提交或读已提交
- prebuilt->select_lock_type != LOCK_NONE:表示当前SQL需要加锁
- thd_is_select(trx->mysql_thd)):当前SQL是select查询
其实很好理解,首先当前SQL得是查询并且想要加锁,也就是SELECT ... FOR UPDATE和 SELECT... LOCK IN SHARE MODE两种情况,但是如果隔离级别是读未提交或读已提交,那么就不需要加GAP锁。
反过来理解就是如果当前SQL是查询并且想要加锁,但是如果隔离级别是可重复读或串行读,才需要加GAP锁。
因此,我们要理解GAP锁的作用是什么,GAP锁的作用就是:在一个事务中多次查询得到的结果得是一样的,特别是两次查询之间其他事务插入了新记录,第二次查询的时候也不能把新记录查出来,对应的隔离级别就是可重复读和串行读,所以当隔离级别是读未提交和读已提交时不需要加GAP锁。
第二种情况
srv_locks_unsafe_for_binlog是用在主从复制过程中的,这块暂时还没研究,AI给的答案是:
当 srv_locks_unsafe_for_binlog 参数设置为 ON 时,InnoDB 存储引擎会使用一种不太安全的锁定策略,这种策略可能会导致某些事务在从库上执行时产生不同的结果。这种锁定策略可能会提高性能,因为它减少了锁定等待时间,但可能会导致复制问题。
相反,当 srv_locks_unsafe_for_binlog 参数设置为 OFF(默认值)时,InnoDB 存储引擎会使用更安全的锁定策略,以确保事务的可重复性,从而保证在复制环境中数据的一致性。这种策略可能会降低性能,因为它可能会增加锁定等待时间,但可以确保主从数据的一致性。
在大多数情况下,特别是在生产环境中,应该将 srv_locks_unsafe_for_binlog 设置为 OFF,以确保数据的一致性和事务的完整性。只有在非常特殊的情况下,并且对可能产生的复制问题有充分的了解和接受时,才应该考虑将其设置为 ON。
第三种情况
第三个条件是trx->isolation_level <= TRX_ISO_READ_COMMITTED,和前面set_also_gap_locks的判断类似,对于隔离级别是读未提交或读已提交则不需要加GAP锁。
第四种情况
第四个条件为(unique_search && !rec_get_deleted_flag(rec, comp)):
- unique_search表示当前查询是唯一搜索,表示只会搜索出一条记录
- !rec_get_deleted_flag(rec, comp)表示搜索出来的记录delete mark为false,表示记录没有被删除,实际上InnoDB中的删除记录只是将delete mark设置为true
也就是说,当前SQL已经查到了一条记录,并且可以判断出当前SQL只有可能查出一条数据,那么就不需要对查出来的记录加GAP锁了,因为只有可能查出一条记录,因此这里的重点是:什么是unique_search?
如何理解unique_search?
上代码:
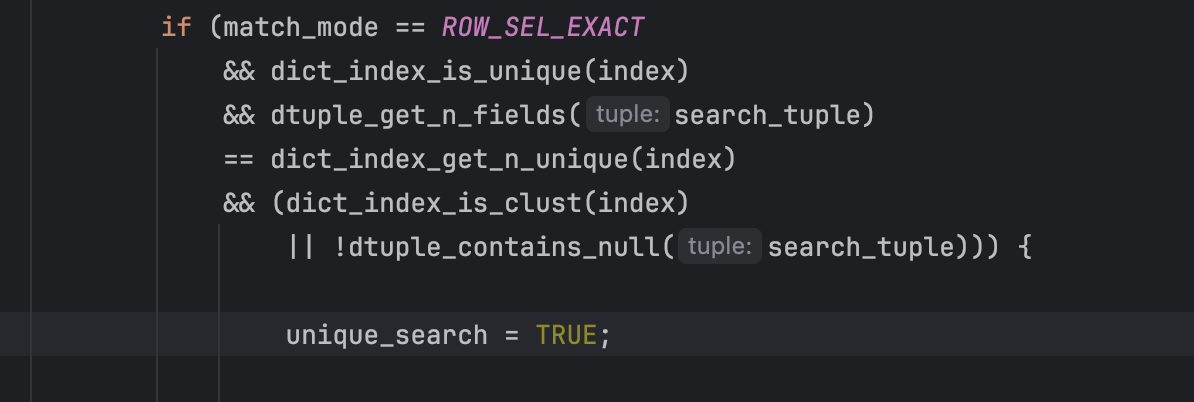
match_mode == ROW_SEL_EXACT:当前查询是等值查询dict_index_is_unique(index):当前索引是唯一索引dtuple_get_n_fields(search_tuple) == dict_index_get_n_unique(index):查询条件能覆盖索引的全部字段,比如a,b,c组成的联合唯一索引,那么查询条件中必须包含a,b,c三个字段(dict_index_is_clust(index) || !dtuple_contains_null(search_tuple)):以上三条件还不足以保证只会查出一条数据,因为唯一索引有可能允许字段为null,因此要么索引是聚集索引(字段不能为NULL),或者查询条件中不包含等于null的查询(只针对索引的字段)
以上四个条件全部成立就表示本次查询是unique_search。
当然还需要注意,就算是unique_search,如果当前SQL没有查询到记录,比如表里只有id=1、id=2、id=3三条记录,此时查询id=4,那么此时是会加GAP锁的,准确一点加的是LOCK_ORDINARY锁,也就是next-key锁。
那是给哪条记录加的锁呢:

页里面的最大记录,锁最大记录之前的间隙,这样就不会允许其他事务插入id=4的记录了。
第五种情况
dict_index_is_spatial(index),表示当前索引是空间索引,不需要管。
谢谢大家的点赞和关注,欢迎在评论区留言讨论,也可以关注我的公众号:IT周瑜,谢谢。
这篇关于五种情况,不加GAP锁,只加行锁的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





