本文主要是介绍dpdk解析报文协议-基于l2fwd,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
dpdk解析报文协议-基于l2fwd
0 前置条件
1、这里需要两台虚拟机,配置了相同的虚拟网络,可以通过tcpreplay在一台虚拟机回放报文,在另一台虚拟机通过tcpdump -i 网卡名 捕获到。
具体配置可参考https://www.jb51.net/server/2946942fw.htm
2、需要dpdk环境配置完成
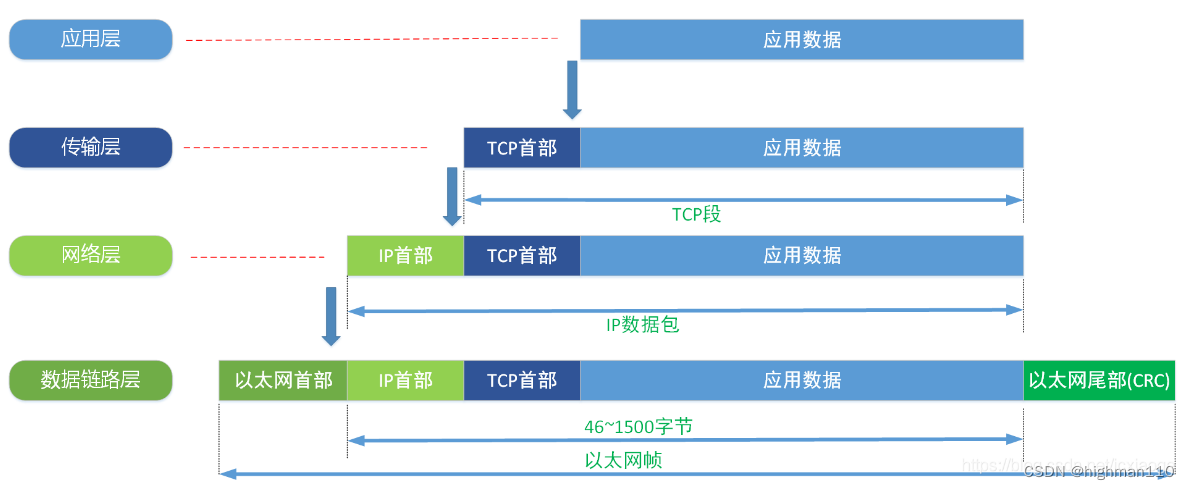
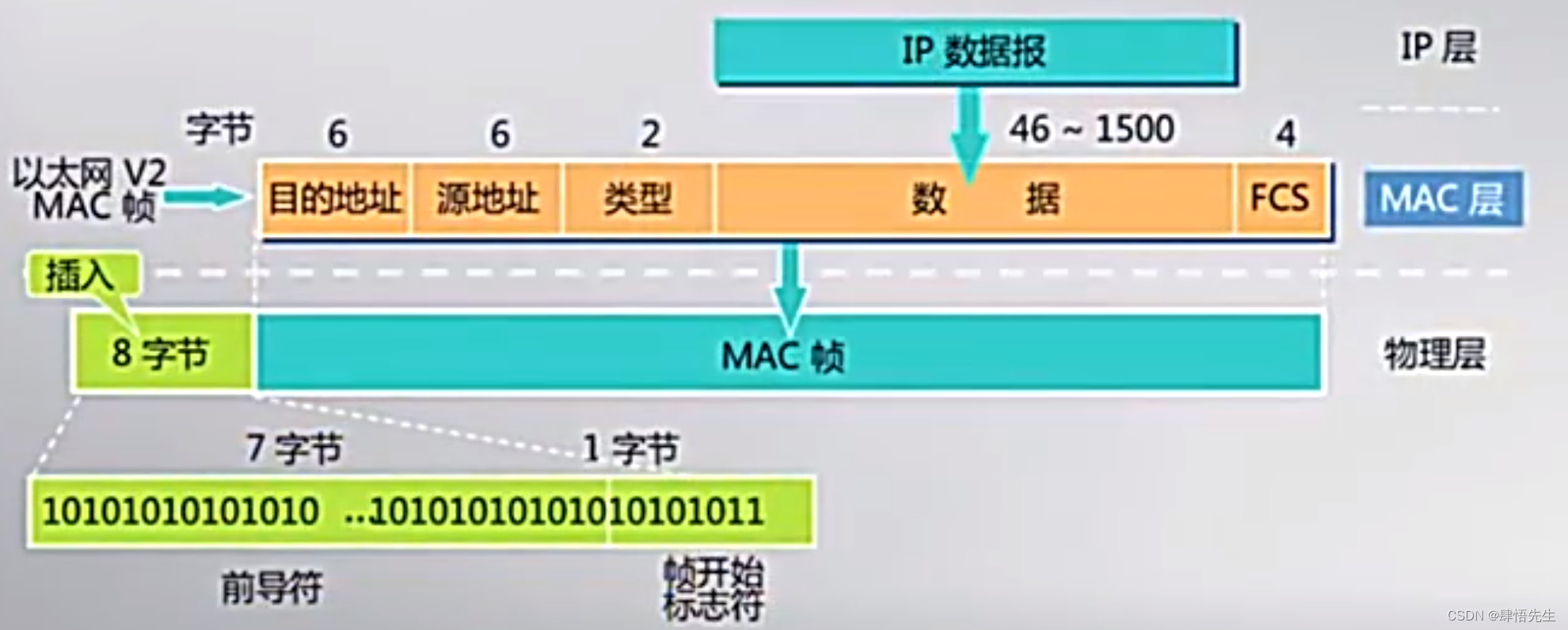
3、大致了解计算机网络的以太网层、ip层、tcp/udp层、应用层http等之间的关系,如下图所示
1 l2fwd运行
进入example中的l2fwd代码目录下,执行下列命令
export RTE_TARGET=x86_64-native-linuxapp-gcc
export RTE_SDK=/home/chen/code/dpdk/dpdk-stable-19.11.14
make# 运行
sudo ./build/l2fwd -l 0-1 -- -p 0x3 -T 1
如果一切正常,则应该输出下图,可以通过在另一台虚拟机回放相关报文,观察统计信息变化情况
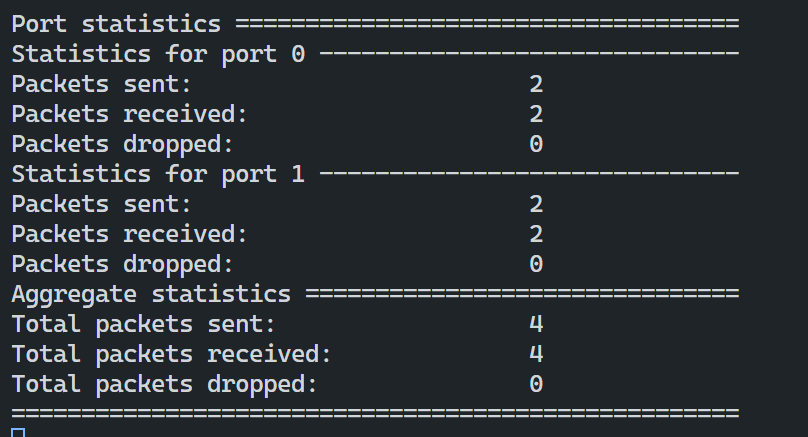
# 另一台虚拟机
sudo tcpreplay -i ens38 xxxx.pcap
在运行l2fwd的虚拟机上可以看到
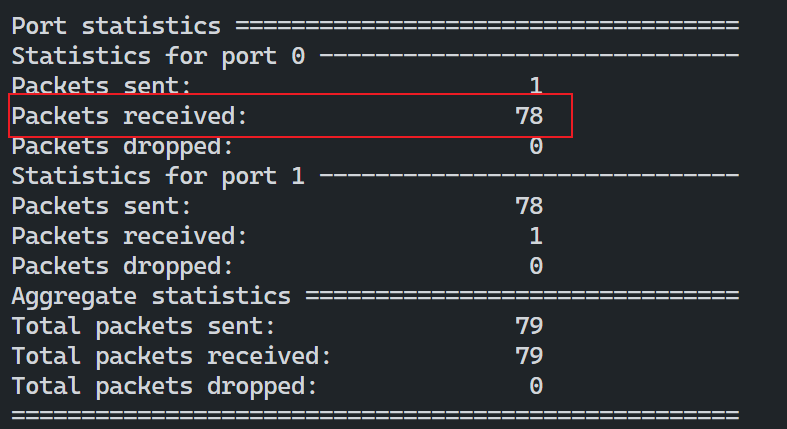
此时说明前面的没问题。
2 l2fwd 整体代码解析
目前浅显的理解可以认为其他部分在初始化,主循环为l2fwd_main_loop
3 l2fwd 修改
1、原先的l2fwd_simple_forward函数是负责修改mac地址并转发报文,那么我们也可以在l2fwd所在的那层循环中,去做解析报文。
// 遍历所有配置的接收端口for (i = 0; i < qconf->n_rx_port; i++) {// 从接收端口列表 qconf->rx_port_list 中获取当前迭代的端口 ID。portid = qconf->rx_port_list[i];// 调用 rte_eth_rx_burst 函数从指定的端口(portid)接收数据包nb_rx = rte_eth_rx_burst(portid, 0,pkts_burst, MAX_PKT_BURST);port_statistics[portid].rx += nb_rx;// printf("nb_rx: %d\n", nb_rx);for (j = 0; j < nb_rx; j++) {m = pkts_burst[j];rte_prefetch0(rte_pktmbuf_mtod(m, void *));parse_packet(m);// l2fwd_simple_forward(m, portid);}}
2、我们可以增加一个parse_packet函数,参照l2fwd_mac_updating中的处理流程,使用官方api rte_pktmbuf_mtod获得以太网头部信息,并存入rte_ether_hdr结构体。
void parse_packet(struct rte_mbuf *m) {struct rte_ether_hdr *eth_hdr;eth_hdr = rte_pktmbuf_mtod(m, struct rte_ether_hdr *);unsigned int total_length = rte_pktmbuf_pkt_len(mbuf); // 获取整个包的长度unsigned int ether_hdr_len = sizeof(struct rte_ether_hdr); // 以太网头部长度unsigned int data_len = total_length - ether_hdr_len; // 剩余数据长度(去除以太网头部)
}/*** Ethernet header: Contains the destination address, source address* and frame type.*/
struct rte_ether_hdr {struct rte_ether_addr d_addr; /**< Destination address. */struct rte_ether_addr s_addr; /**< Source address. */uint16_t ether_type; /**< Frame type. */
} __attribute__((aligned(2)));
此时可以得到原mac和目的mac,以及ip版本,和下图的MAC帧是对应的。
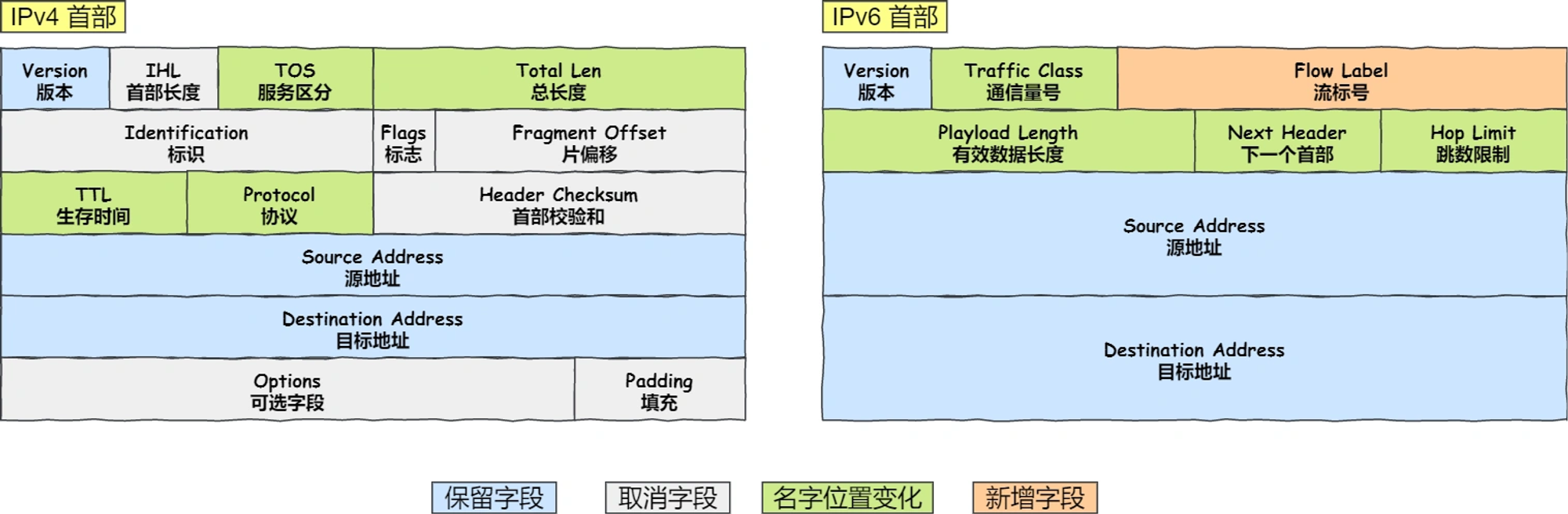
3、通过ip类型,判断是ipv4还是ipv6,进行不同的处理,这里面需要注意的是有大小端的转换(RTE_ETHER_TYPE_IPV4是大端),用rte_be_to_cpu_16。ip层相关的信息都保存在ipv4_hdr中
// 检查 IP 版本并获取 IP 头部if (eth_hdr->ether_type <span style="font-weight: bold;" class="mark"> rte_be_to_cpu_16(RTE_ETHER_TYPE_IPV4)) {parse_packet_ipv4((struct rte_ipv4_hdr *)(eth_hdr + 1), data_len); // 由于以太网头部长度固定,这里直接调过以太网头部字段,// 处理 IPv4 头部...} else if (eth_hdr->ether_type </span> rte_be_to_cpu_16(RTE_ETHER_TYPE_IPV6)) {printf("ipv6\n");// struct rte_ipv6_hdr *ipv6_hdr;}/*** IPv4 Header*/
struct rte_ipv4_hdr {uint8_t version_ihl; /**< version and header length */uint8_t type_of_service; /**< type of service */rte_be16_t total_length; /**< length of packet */rte_be16_t packet_id; /**< packet ID */rte_be16_t fragment_offset; /**< fragmentation offset */uint8_t time_to_live; /**< time to live */uint8_t next_proto_id; /**< protocol ID */rte_be16_t hdr_checksum; /**< header checksum */rte_be32_t src_addr; /**< source address */rte_be32_t dst_addr; /**< destination address */
} __attribute__((__packed__));
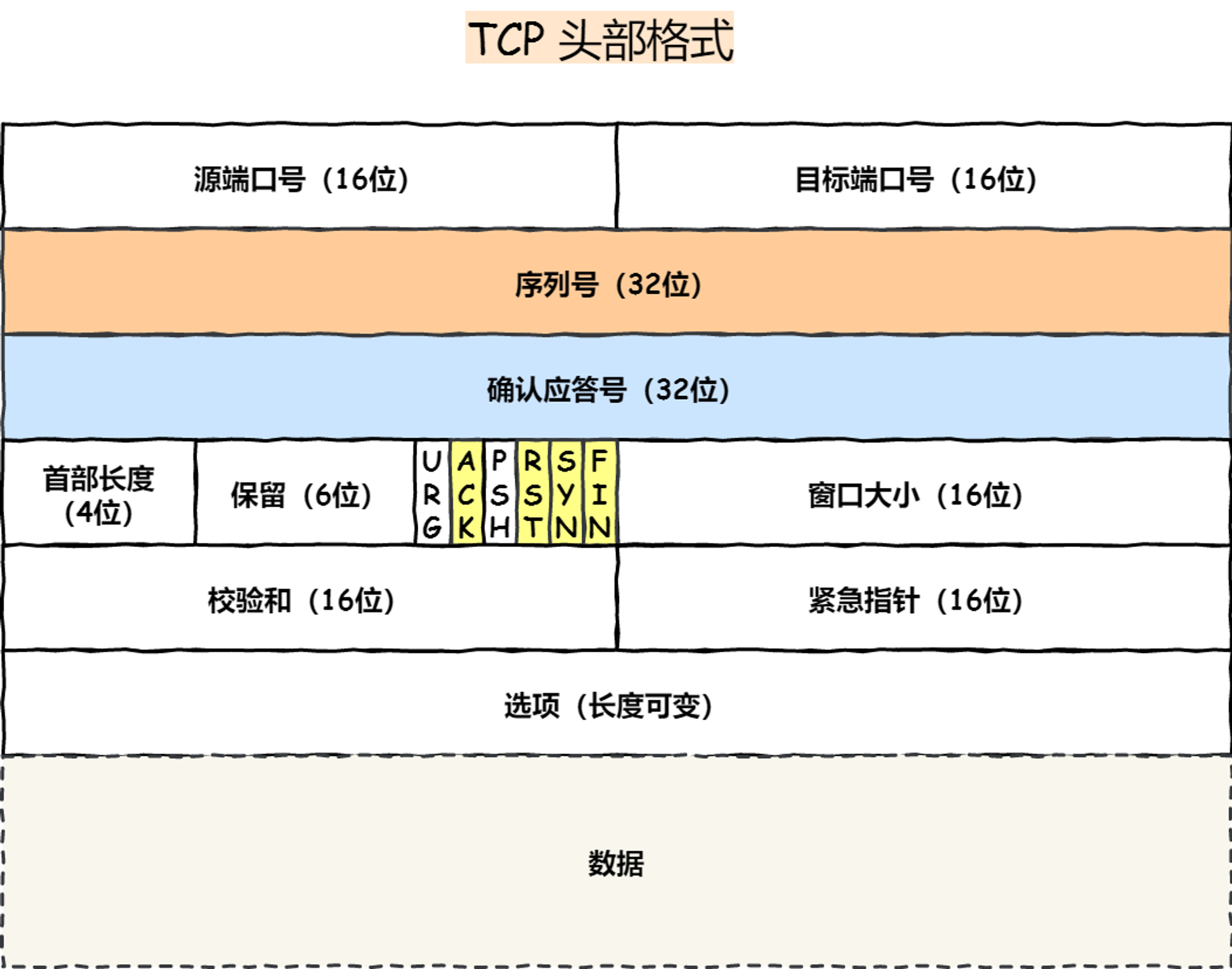
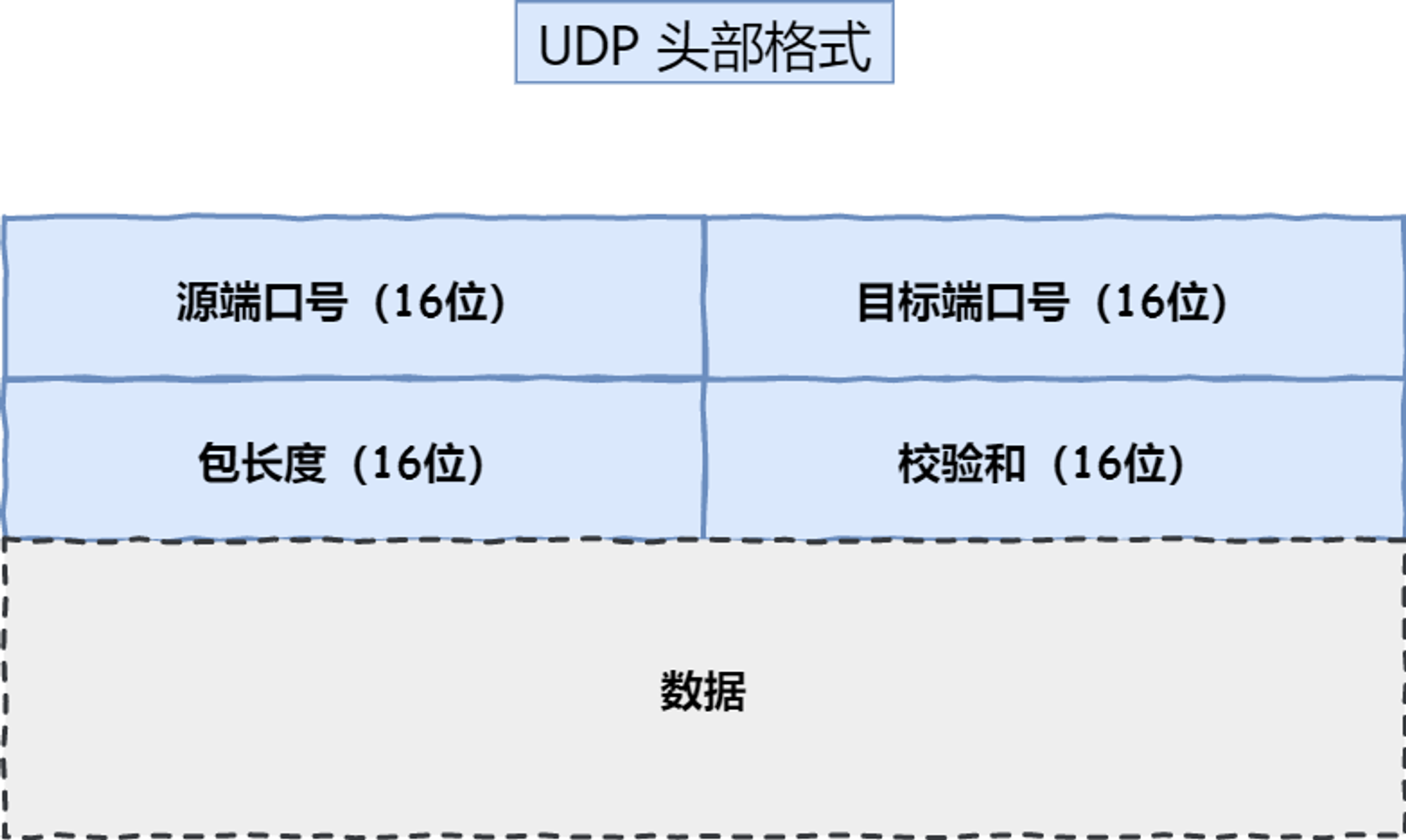
4、通过ip层协议标识next_proto_id判断是tcp还是udp
void parse_packet_ipv4(struct rte_ipv4_hdr *ipv4_hdr, unsigned int data_len) {print_ipv4_addr("ipv4_src_addr:", ipv4_hdr->src_addr);print_ipv4_addr("ipv4_dst_addr:", ipv4_hdr->dst_addr);unsigned int ipv4_hdr_len = (ipv4_hdr->version_ihl & 0x0F) * 4; // 头部长度以4字节为单位// 检查协议类型并获取 TCP/UDP 头部if (ipv4_hdr->next_proto_id <span style="font-weight: bold;" class="mark"> IPPROTO_TCP) {parse_packet_tcp((struct rte_tcp_hdr *)((unsigned char *)ipv4_hdr + ipv4_hdr_len), data_len - ipv4_hdr_len);// 处理 TCP 头部...} else if (ipv4_hdr->next_proto_id </span> IPPROTO_UDP) {parse_packet_udp((struct rte_udp_hdr *)((unsigned char *)ipv4_hdr + ipv4_hdr_len), data_len - ipv4_hdr_len);// 处理 UDP 头部...}
}struct rte_tcp_hdr {rte_be16_t src_port; /**< TCP source port. */rte_be16_t dst_port; /**< TCP destination port. */rte_be32_t sent_seq; /**< TX data sequence number. */rte_be32_t recv_ack; /**< RX data acknowledgment sequence number. */uint8_t data_off; /**< Data offset. */uint8_t tcp_flags; /**< TCP flags */rte_be16_t rx_win; /**< RX flow control window. */rte_be16_t cksum; /**< TCP checksum. */rte_be16_t tcp_urp; /**< TCP urgent pointer, if any. */
} __attribute__((__packed__));struct rte_udp_hdr {rte_be16_t src_port; /**< UDP source port. */rte_be16_t dst_port; /**< UDP destination port. */rte_be16_t dgram_len; /**< UDP datagram length */rte_be16_t dgram_cksum; /**< UDP datagram checksum */
} __attribute__((__packed__));
5、以tcp为例,判断是否是http(这里简单判断端口是否为80)
void parse_packet_tcp(struct rte_tcp_hdr *tcp_hdr, unsigned int data_len) {unsigned int tcp_hdr_len = ((tcp_hdr->data_off & 0xF0) >> 4) * 4; // 高 4 位表示 TCP 头部的长度unsigned char *tcp_payload = ((unsigned char *)tcp_hdr) + tcp_hdr_len;unsigned int tcp_payload_len = data_len - tcp_hdr_len; // TCP 负载长度// 将端口从网络字节序转换为主机字节序uint16_t port_host_order = rte_be_to_cpu_16(tcp_hdr->dst_port);if (port_host_order == 80) {parse_packet_http(tcp_payload, tcp_payload_len);}
}
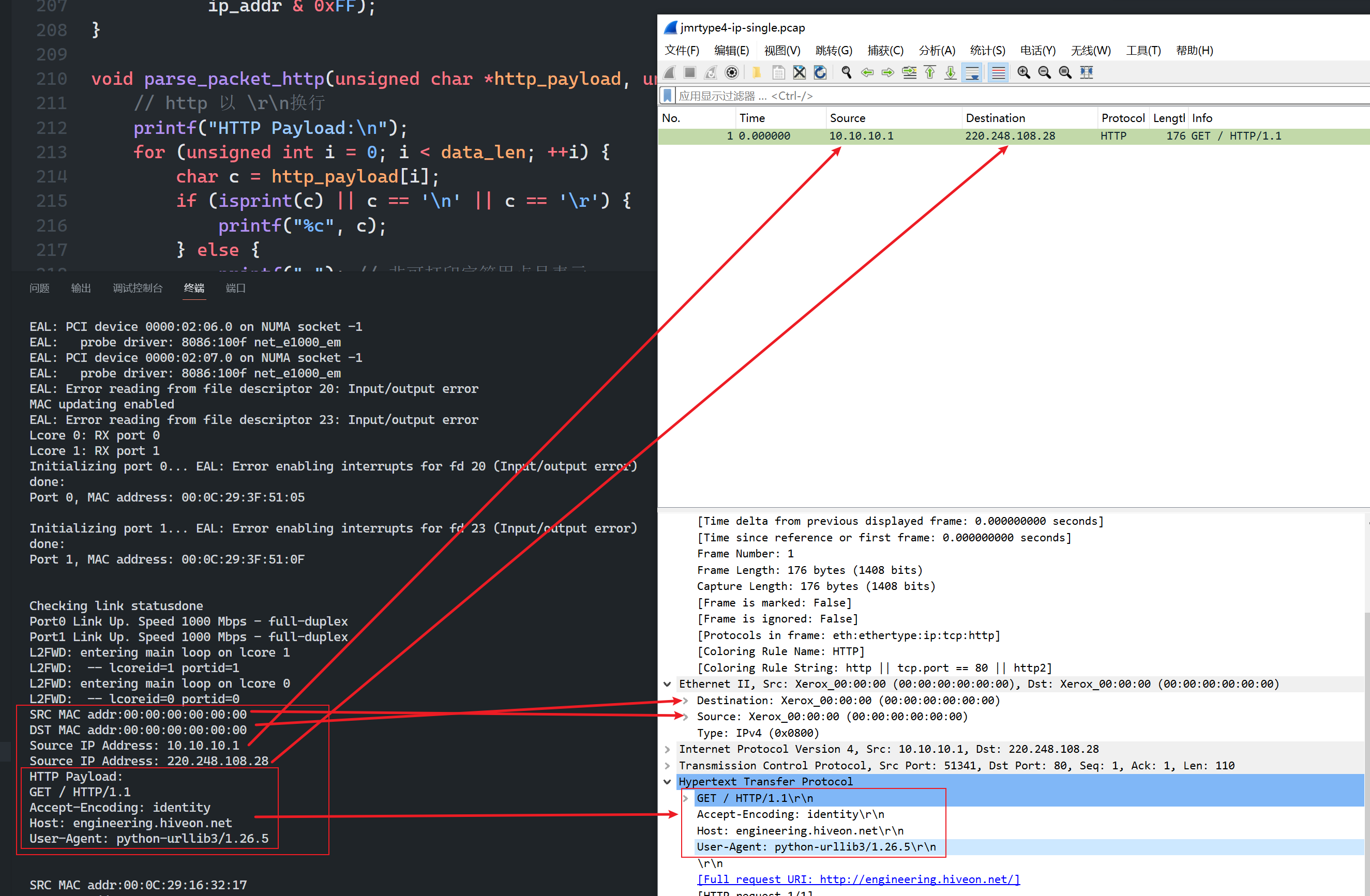
6、打印http负载,由于http负载的结束有很多种情况(ip是否分片,http流是否结束等),所以需要基于报文长度依次减去各部分的头部来确定http负载的长度
void parse_packet_http(unsigned char *http_payload, unsigned int data_len) {// http 以 \r\n换行printf("HTTP Payload:\n");for (unsigned int i = 0; i < data_len; ++i) {char c = http_payload[i];if (isprint(c) || c <span style="font-weight: bold;" class="mark"> '\n' || c </span> '\r') {printf("%c", c);} else {printf("."); // 非可打印字符用点号表示}}printf("\n");
}
这篇关于dpdk解析报文协议-基于l2fwd的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


