本文主要是介绍如何使用IDEA加载已有Spark项目,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景是这样的:手上有一个学长之前实现的Spark项目,使用到了GraphX,并且用的Scala编写,现在需要再次运行这个项目,但如果直接在IDEA中打开项目,则由于各种错误会导致运行失败,这里就记录一下该如何使用IDEA来加载老旧的Spark项目。
注意:默认你的机器已有Scala环境,项目使用IDEA打开,对Sbt不做要求,因为这里采用的是NoSbt方式添加依赖的。
确定项目的版本环境
这一步是非常重要的,很多情况下就是由于版本的不匹配导致代码解析出现错误,主要的环境版本包括:
- Java Version 1.8 必须
- scala-sdk-x.xx.x
- spark-assembly-x.x.x-hadoop.x.x.jar //注意这是在No-sbt模式下必须的,这个包很大,大概170M,导入后不用再添加其他依赖即可对Spark程序进行本地(Local)运行,其已包括GraphX模块。
Java的版本
这里由于要是用Scala所以必须使用 Version 1.8+,关于如何修改版本这里不赘述。
Scala的版本
这里可以通过右键项目名称,进入项目设置页面具体查看原项目使用的版本:
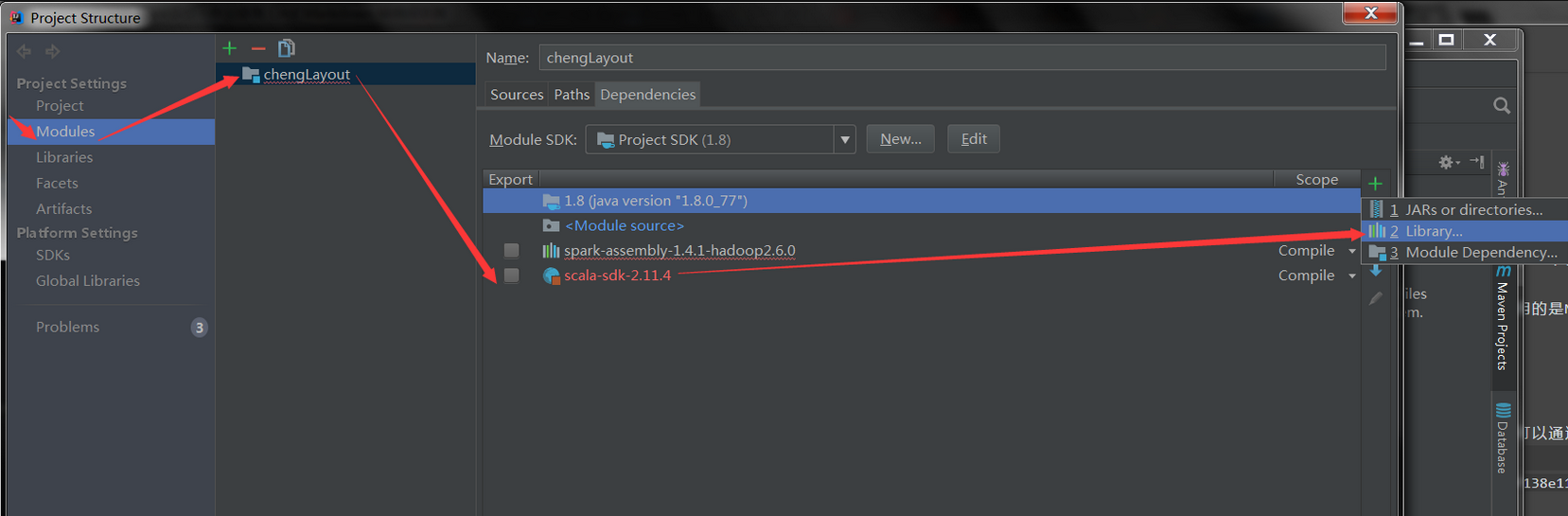
之后可以添加相应的Scala版本支持,比如假设这里需要 2.10.4 那么直接勾选即可,但是如果本机没有对应的版本,那么可以点击下方的New Liberay选择Scala SDK,进入如下页面:
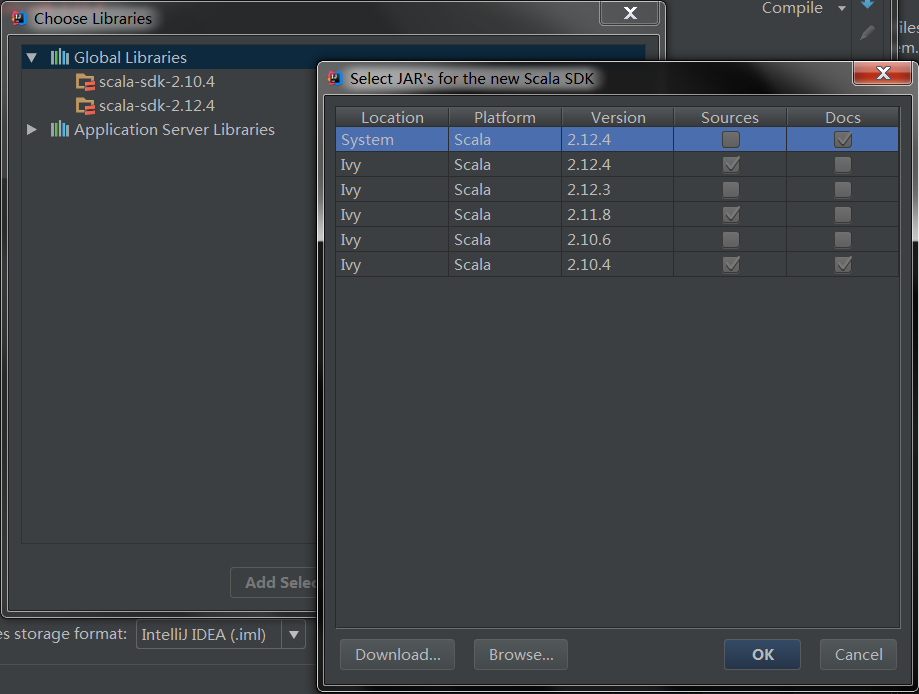
在上述页面中你可以选择更多版本的Scala环境,如果还是没有你需要的版本,那么点击下方的Download按钮,可以进一步选择你需要的版本(涵盖所有版本),这是在线下载的操作,所以可能时间会非常慢,非常慢!
Spark-assembly的版本
关于这个地方要特别注意版本的对应,老项目里有代码用到了 GraphX中 图的 mapReduceTriplets ,这应该在Spark-2.x.x以后被取消了,所以如果下次再在网上看到使用mapReduceTriplets的代码,复制到本地却无法识别时,不要慌张,那是他们使用了老版本的Spark-GraphX。
在这里,原项目使用的是 spark-assembly-1.4.1-hadoop2.6.0.jar 但是这个jar包早就不在项目文件中了,然后在网上也没有搜到完全匹配的Jar包,但上文已说到,找个spark-1.x 版本的即可,所以在网上找了一个 spark-assembly-1.5.1-hadoop2.6.0.jar,同样在 上图 中的右侧点击加号后选择JARS or direct..添加到项目依赖中即可。
确定项目代码的运行环境
在上一部分中对原项目的项目的所需依赖的版本进行了更正对应之后,可以发现原先满屏飘红的代码已经没有错误了,即这时IDEA已经具有了对于代码的完全的解析能力,这时我们写代码调方法都可以自动补全等等。
虽然代码无措,但是直接运行仍然是出不来结果的,因为原项目的代码有原来的运行环境,可能是集群环境或其他,另外,源代码的执行也有可能需要传入若干参数,贸然运行当然就不会得到预期结果。
这部分的修改要具体情况具体分析,但大致都有以下几步:
- 查看Main函数的传入参数,如果带参数的,要明确参数的具体意义,一个是参数类型,一个是参数意义。比如迭代次数,或是文件路径。如果偷懒,可以去掉传入参数,直接对相应变量赋值,这样就可以在IDE中直接运行调试了。
//诸如下面赋值内容要搞清楚具体意义
if(args.length!=5){
printf("Please input right parameters <vertex path> <edges path> <output path> <deep> <time> ")
return
}
//可以直接对变量赋值,而不用输入参数args(x)
val time=args(4).toInt
val vertexPath=args(0)
val edgesPath=args(1)
val outputPath=args(2)
val deep:Int=args(3).toInt
- 集群运行还是本地运行,这里比较好改:
val conf = new SparkConf().setAppName("Proj_SIG")
//如果是简单调试,直接改为本地运行即可
val conf = new SparkConf().setAppName("Proj_SIG").setMaster("local")
可能需要的Hadoop支持
如果出现错误:Failed to locate the winutils binary in the hadoop binary path 那么说明当前IDEA环境缺失hadoop的支持。
解决方案:
首先我们需要明白,hadoop只能运行在linux环境下,如果我们在windows下用idea开发spark的时候底层比方说文件系统这些方面调用hadoop的时候是没法调用的,这也就是为什么会提示这样的错误。
当我们有这样的错误的时候,其实还是可以使用spark计算框架的,不过当我们使用saveAsTextFile的时候会提示错误,这是因为spark使用了hadoop上hdfs那一段的程序,而我们windows环境下没有hadoop,怎么办?
第一步: 官网下载相应版本的hadoop。
第二步:解压到你想要安装的任何路径,解压过程会提示出现错误,不去管他,这是因为linux文件不支持windows。
第三步:设置环境变量,在系统变量中添加HADOOP_HOME,指向你解压的文件路径。然后再path中添加%HADOOP_HOME%bin和%HADOOP_HOME%sbin
第四步:找一找可以使用的重新编译的winutils兼容工具插件包,这个可以在这里下载:
第五步:下载完以后在我们hadoop文件夹中替换下载包中的两个目录。
回到idea会发现bug完美解决。
上述几步修改完成后,原先的代码基本就可以跑起来了,再次强调这里使用了NoSBT的模式,手动添加了一个assembly包,再就是对应Scala-SDK的版本,最后对代码内容上进行部分改动,使其可以在本地单机进行调试运行。
😒 留下您对该文章的评价 😄
这篇关于如何使用IDEA加载已有Spark项目的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






