本文主要是介绍零拷贝并非万能解决方案:重新定义数据传输的效率极限,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
PageCache有什么作用?
在我们前面讲解零拷贝的内容时,我们了解到一个重要的概念,即内核缓冲区。那么,你可能会好奇内核缓冲区到底是什么?这个专有名词就是PageCache,也被称为磁盘高速缓存。也可以看下windows下的缓存区:如图所示:
零拷贝进一步提升性能的原因在于 PageCache 技术的使用。接下来,我们将详细探讨 PageCache 技术是如何实现这一目标的。
读写磁盘相比读写内存的速度慢太多了,但我们可以采取一种方法来改善这个问题,即将磁盘数据部分缓存到内核中,也就是将其存储在PageCache缓存区中。这个过程实际上是通过DMA(直接内存访问)控制器将磁盘数据拷贝到内核缓冲区中。
然而,需要注意的是,由于内存空间较磁盘空间有限,因此存在一系列算法来确保pageCache占用的内存空间不过大。我们在程序运行时都知道存在一种「局部性」,即刚刚被访问的数据在短时间内很可能再次被访问到,概率很高。因此,pageCache被用作缓存最近访问的数据。可以将pageCache看作是Redis,而磁盘则类似于MySQL。此外,pageCache还使用了内存淘汰机制,在内存空间不足时,会淘汰最近最久未被访问的缓存。
当在项目中使用 Redis 时,你一定知道如何使用它。和 Redis 类似, PageCache 的工作原理也是一样的。在进程需要访问数据时,它会首先检查 PageCache 是否已经存储了所需的数据。如果数据已经存在于 PageCache 中,内核会直接返回数据;如果数据未被缓存,则会从磁盘读取并将数据缓存到 PageCache 中,以备下次查询时使用。这种方式可以有效提高访问效率。
然而,pageCache还具有另一个优点,即预读功能。当访问并读取磁盘数据时,实际上需要定位磁盘中的位置。对于机械硬盘而言,这意味着磁头必须旋转到数据所在的扇区位置,然后开始顺序读取数据。然而,旋转磁头这种物理操作对计算机而言非常耗时。为了降低其影响,就出现了预读功能。通过预读功能,可以提前预读下一扇区的数据,减少等待磁头旋转的时间。
比如read方法需要读取32KB的字节的数据,使其在读取32KB字节数据后,继续读取后面的32-64KB,并将这一块数据一起缓存到pageCache缓冲区。这样做的好处在于,如果后续读取需要的数据在这块缓存中命中,那么读取成本会大幅降低。可以类比于redis中提前缓存一部分分布式唯一id用于插入数据库时的分配操作,这样就无需每次插入前都去获取一遍id。然而,一般情况下,为了避免可能出现的"毛刺"现象,我们通常会使用双缓存机制来处理。这个双缓存机制可以进一步优化读取操作的效果。
因此,PageCache的优点主要包括两个方面:首先,它能够将数据缓存到PageCache中;其次,它还利用了数据的预读功能。这两个操作极大地增强了读写磁盘时的性能。
但是,你可以想象一下如果你在传输大文件时比如好几个G的文件,如果还是使用零拷贝技术,内核还是会把他们放入pageCache缓存区,那这样不就产生问题了吗?你也可以想一下如果你往redis缓存中放了一个还几个G大小的value,而且还知道缓存了也没用,那不就相当于redis形同虚设了吗?把其他热点数据也弄没了,所以pageCache也有这样的一个问题,一是大文件抢占了pageCache的内存大小,这样做会导致其他热点数据无法存储在pageCache缓冲区中,从而降低磁盘的读写性能。此外,由于pageCache无法享受到缓存的好处,还会产生一个DMA数据拷贝的过程。
因此,最佳的优化方法是针对大文件传输时不使用pageCache,也就是不使用零拷贝技术。这是因为零拷贝技术会占用大量的内存空间,影响其他热点数据的访问优化。在高并发环境下,这几乎肯定会导致严重的性能问题。
大文件传输用什么方式实现?
那针对大文件的传输,我们应该使用什么方式呢?
让我们首先来观察最初的示例。当调用read方法读取文件时,进程实际上会被阻塞在read方法的调用处,因为它需要等待磁盘数据的返回。如下图所示:
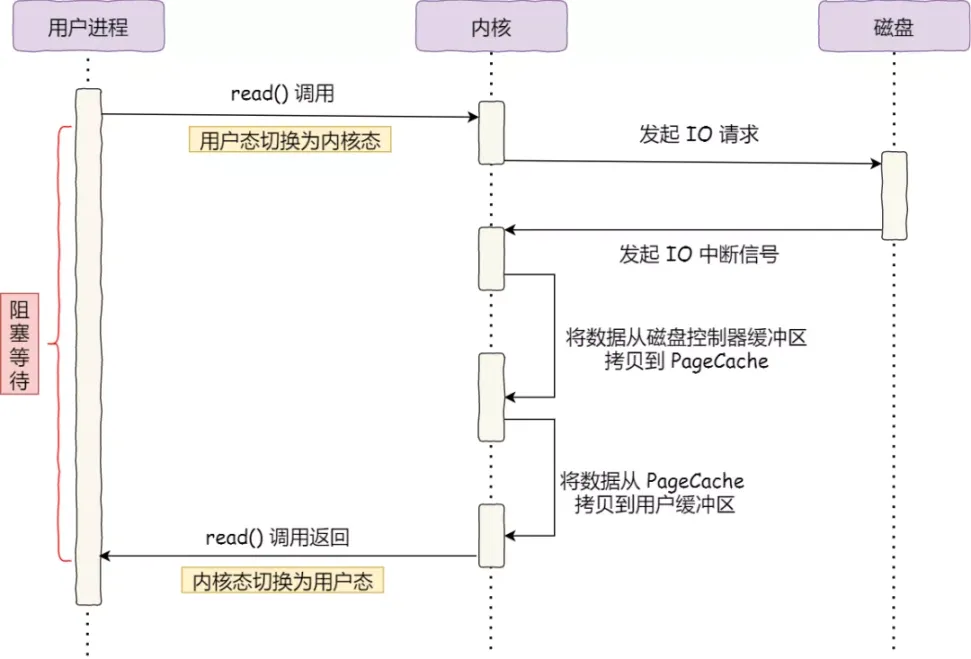
在没有使用零拷贝技术的情况下,我们的用户进程使用同步IO的方式,它会一直阻塞等待系统调用返回数据。让我们回顾一下之前的具体流程:
- 应用程序发起read系统调用,用户进程开始进行阻塞等待结果返回。
- 此时内核会向磁盘发起I/O请求,磁盘收到请求后,开始寻址。当磁盘数据准备好后,就会向内核发起I/O中断,告知内核磁盘数据已经准备好。
- 内核收到中断信号后,将数据从磁盘控制器缓存区拷贝到pageCache缓冲区。
- 最后,内核会将pageCache中的数据再次拷贝到用户缓冲区,也就是用户态的内存中,然后read调用返回。
我们知道,既然有同步IO,就一定有异步IO来解决阻塞的问题。异步IO的工作方式如下图所示:
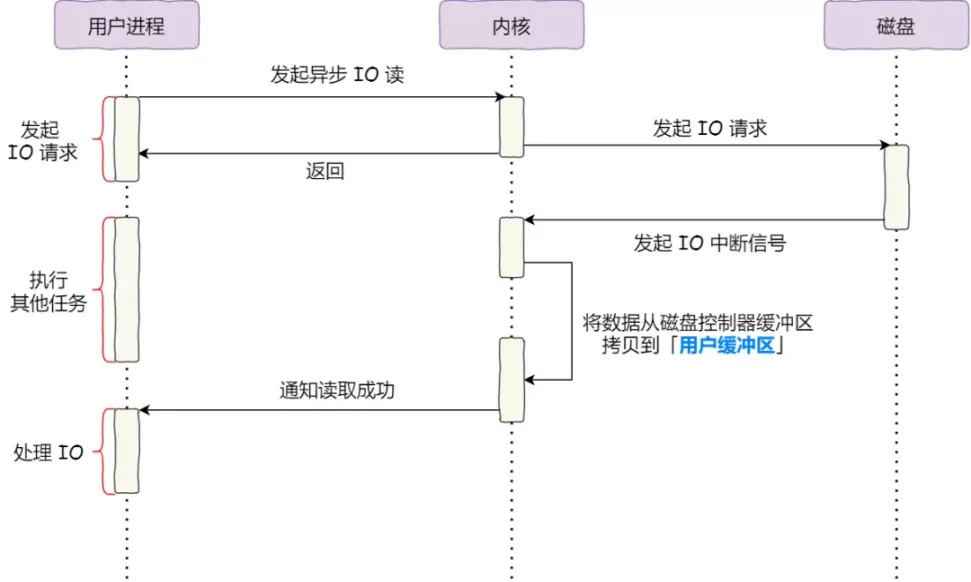
它将读操作分为两个部分:
- 第一部分是用户进程发起IO请求给内核,然后进程就不再关心该IO操作,而是继续处理其他任务。
- 第二部分是当内核接收到中断信号后,将数据直接拷贝到用户缓冲区,并通知用户进程操作成功。然后用户进程开始处理数据。
我们发现在这个过程中,并没有涉及到将数据拷贝到pageCache中,因此使用异步方式绕开了pageCache。直接IO是指绕过pageCache的IO请求,而缓存IO是指使用pageCache的IO请求。通常,对于磁盘而言,异步IO只支持直接IO。
正如前面所提到的,对于大文件的传输,不应该使用PageCache,因为这可能会导致PageCache被大文件占据,从而使得"热点"小文件无法充分利用PageCache的优势。
因此,在高并发的场景下,对于大文件传输,我们应该采用"异步I/O + 直接I/O"的方式来代替零拷贝技术。
直接I/O有两种常见的应用场景:
- 首先,如果应用程序已经实现了磁盘数据的缓存,就不需要再次使用PageCache进行缓存,这样可以减少额外的性能损耗。例如,在MySQL数据库中,可以通过参数设置来开启直接I/O,避免重复的缓存操作,默认情况下是不开启的。
- 其次,在传输大文件时,由于大文件很难命中PageCache的缓存,而且会占满PageCache导致"热点"文件无法充分利用缓存,增加了性能开销。因此,在这种情况下,应该使用直接I/O来绕过PageCache的缓存,以提高性能。
需要注意的是,直接I/O绕过了PageCache,因此无法享受内核的两项优化。
- 首先,内核的I/O调度算法会在PageCache中缓存尽可能多的I/O请求,然后将它们合并成一个更大的I/O请求发送给磁盘,以减少磁盘的寻址操作。
- 其次,内核会预读后续的I/O请求并将其放入PageCache中,同样是为了减少对磁盘的操作。这些优化在直接I/O中无法享受到。
于是,当我们需要传输大文件时,我们可以利用异步I/O和直接I/O的组合来实现无阻塞的文件读取。这种方式可以有效避免PageCache的影响,提高文件传输的效率。
因此,在文件传输过程中,我们可以根据文件的大小来选择不同的优化方式,以提高传输效率。对于大文件,使用异步I/O和直接I/O可以避免PageCache的影响;而对于小文件,则可以使用零拷贝技术来减少数据拷贝次数,提高传输速度。
在Nginx中,我们可以通过以下配置来根据文件的大小选择不同的优化方式:
location /video/ { sendfile on; aio on; directio 1024m;
}
在这个配置中,我们开启了sendfile选项,这允许Nginx使用零拷贝技术来传输文件。同时,我们也启用了aio选项,这使得Nginx可以使用异步I/O来提高文件传输的效率。
而通过设置directio参数为1024m,我们告诉Nginx当文件大小超过1024MB时,使用直接I/O来进行文件传输。这意味着在传输大文件时,Nginx将使用异步I/O和直接I/O的组合来实现无阻塞的文件读取,避免了PageCache的影响。而对于小文件,Nginx将继续使用零拷贝技术,以减少数据拷贝次数,提高传输速度。
总结
至此,我们的计算机基础专栏就结束了,不知道大家有没有发现,操作系统底层提供了丰富的解决方案来支持应用程序的复杂性和可扩展性。对于任何工作中遇到的问题,我们都可以从操作系统的角度寻找解决方法。
今天这一篇其实就是来打破零拷贝的方案神话的,没有一种技术是最好的,只有最合适的方法。我们需要根据具体的需求和情况来选择适合的解决方案,以提高应用程序的性能和可扩展性。谢谢大家的阅读和关注,希望这个专栏能对大家有所启发和帮助!
也请期待我的下一个专栏:【计算机网络篇】
我是努力的小雨,一名 Java 服务端码农,潜心研究着 AI 技术的奥秘。我热爱技术交流与分享,对开源社区充满热情。同时也是一位腾讯云创作之星、阿里云专家博主、华为云云享专家、掘金优秀作者。
💡 我将不吝分享我在技术道路上的个人探索与经验,希望能为你的学习与成长带来一些启发与帮助。
🌟 欢迎关注努力的小雨!🌟
这篇关于零拷贝并非万能解决方案:重新定义数据传输的效率极限的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








